 如何优化自然语言处理模型的性能
如何优化自然语言处理模型的性能

优化自然语言处理(NLP)模型的性能是一个多方面的任务,涉及数据预处理、特征工程、模型选择、模型调参、模型集成与融合等多个环节。以下是一些具体的优化策略:
一、数据预处理优化
- 文本清洗 :去除文本中的噪声和无关信息,如HTML标签、特殊字符、停用词等,使模型更专注于关键信息。
- 分词与词干化 :对于中文文本,需要进行准确的分词;对于英文文本,词干化有助于将不同词形还原为词干形式,减少词汇冗余。
- 数据增强 :通过同义词替换、随机插入、删除或交换句子中的单词等方式,生成新的训练样本,增加数据的多样性和丰富度。
二、特征工程优化
- 选择有效的特征 :根据具体任务选择合适的特征,如词袋模型、TF-IDF、词嵌入等。词嵌入技术能够捕捉词语之间的语义关系,对于提升模型性能尤为关键。
- 特征降维 :对于高维特征空间,可以考虑使用降维技术(如PCA、LDA等)来减少特征数量,降低模型复杂度,同时保持关键信息。
三、模型选择与优化
- 选择合适的模型 :根据任务类型和数据集特点选择合适的NLP模型,如朴素贝叶斯、支持向量机、逻辑回归、深度神经网络(如CNN、RNN、Transformer等)。
- 超参数调优 :通过交叉验证、网格搜索等方法对模型的超参数(如学习率、批大小、隐藏层大小等)进行优化,找到最佳参数组合。
- 正则化与早停 :使用正则化技术(如L1、L2正则化)和早停策略来防止模型过拟合,提高模型的泛化能力。
四、模型集成与融合
- 模型集成 :通过投票法、加权平均法、堆叠法等方法将多个模型的预测结果进行集成,提高模型的稳定性和准确性。
- 模型融合 :将不同模型的优点融合在一起,如混合模型、级联模型、串联模型等,进一步提升模型性能。
五、其他优化策略
- 使用预训练模型 :利用大规模语料库进行预训练的模型(如BERT、GPT等)已经学习了丰富的语言知识,可以作为解决特定任务的基础,通过微调即可获得较好的性能。
- 对抗性训练 :通过生成对抗样本并将其纳入训练过程,提高模型对微小扰动的鲁棒性。
- 多任务学习 :同时训练模型执行多个任务,可以促使模型学习到更通用的语言表示,提高模型的泛化能力。
- 持续学习 :在模型部署后,持续收集新数据并进行增量学习,使模型能够适应语言的变化和新出现的用法。
综上所述,优化NLP模型的性能需要从多个方面入手,包括数据预处理、特征工程、模型选择与优化、模型集成与融合以及其他优化策略。通过综合考虑这些因素并采取相应的措施,可以显著提升NLP模型的性能和准确性。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
模型
+关注
关注
1文章
3873浏览量
52337 -
数据预处理
+关注
关注
1文章
20浏览量
3012 -
自然语言处理
+关注
关注
1文章
630浏览量
14756
发布评论请先 登录
相关推荐
热点推荐
零基础手写大模型资料2026
token,模型会计算其与其他所有token的相似度(通过点积实现),生成注意力分数矩阵。例如处理\"自然语言处理\"这句话时,\"语言\"
发表于 05-01 17:44
人工智能多模态与视觉大模型开发实战 - 2026必会
的诊断建议。
未来展望:开启视觉智能新时代
随着技术的不断进步,视觉大模型将在更多领域发挥重要作用。未来,它有望与自然语言处理、机器人技术等领域深度融合,创造出更加智能、便捷的应用场景。
视觉大
发表于 04-15 16:06
解锁谷歌FunctionGemma模型的无限潜力
在智能体 AI 领域,工具调用能力是将自然语言转化为可执行软件操作的关键。此前,我们发布了专门针对函数调用而特别优化的 Gemma 3 270M 模型版本 FunctionGemma。该模型

自然语言处理NLP的概念和工作原理
自然语言处理 (NLP) 是人工智能 (AI) 的一个分支,它会教计算机如何理解口头和书面形式的人类语言。自然语言处理将计算

云知声论文入选自然语言处理顶会EMNLP 2025
近日,自然语言处理(NLP)领域国际权威会议 ——2025 年计算语言学与自然语言处理国际会议(EMNLP 2025)公布论文录用结果,云知

一文了解Mojo编程语言
Mojo 语言的具体介绍:
核心特点
Python 兼容性
Mojo 支持大部分 Python 语法和标准库,可直接调用 Python 生态系统中的库,降低了学习成本。
极致性能优化
通过静态编译
发表于 11-07 05:59
自动驾驶上常提的VLA与世界模型有什么区别?
自动驾驶中常提的VLA,全称是Vision-Language-Action,直译就是“视觉-语言-动作”。VLA的目标是把相机或传感器看到的画面、能理解和处理自然语言的大模型能力,和最
广和通发布端侧情感对话大模型FiboEmo-LLM
9月,广和通正式发布自主研发的端侧情感对话大模型FiboEmo-LLM。该模型专注于情感计算与自然语言交互融合,致力于为AI玩具、智能陪伴设备等终端场景提供“情感理解-情感响应”一体化能力,推动终端人工智能向更具人性化、情感化的
HarmonyOSAI编程自然语言代码生成
安装CodeGenie后,在下方对话框内,输入代码需求描述,将根据描述智能生成代码,生成内容可一键复制或一键插入至编辑区当前光标位置。
提问示例
使用ArkTs语言写一段代码,在页面中间部分
发表于 09-05 16:58
小白学大模型:国外主流大模型汇总
数据科学AttentionIsAllYouNeed(2017)https://arxiv.org/abs/1706.03762由GoogleBrain的团队撰写,它彻底改变了自然语言处理(NLP

【HZ-T536开发板免费体验】5- 无需死记 Linux 命令!用 CangjieMagic 在 HZ-T536 开发板上搭建 MCP 服务器,自然语言轻松控板
ifconfig、gpio write 1 1)。
工作流程 :
MCP客户端发送自然语言指令到 HZ-T536 的 MCP 服务器;
MCP 服务器利用DeepSeek的大语言模型能力,生成
发表于 08-23 13:10
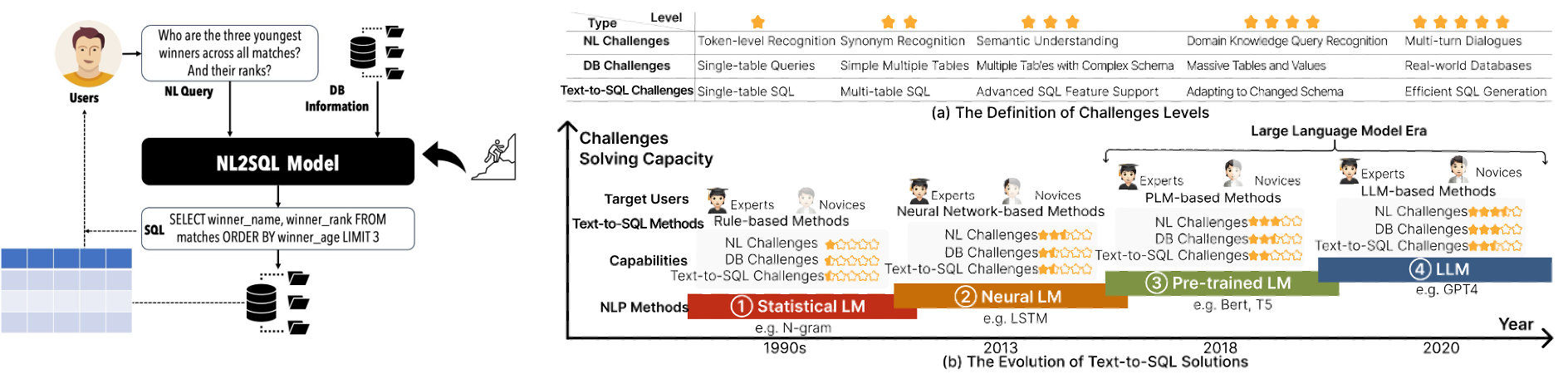
Text2SQL准确率暴涨22.6%!3大维度全拆
摘要 技术背景:Text2SQL 是将自然语言查询转为 SQL 的任务,经历了基于规则、神经网络、预训练语言模型、大语言模型四个阶段。当前面
欧洲借助NVIDIA Nemotron优化主权大语言模型
NVIDIA 正携手欧洲和中东的模型构建商与云提供商,共同优化主权大语言模型 (LLM),加速该地区各行业采用企业级 AI。
云知声四篇论文入选自然语言处理顶会ACL 2025
结果正式公布。云知声在此次国际学术盛会中表现卓越,共有4篇论文被接收,其中包括2篇主会论文(Main Paper)和2篇Findings。入选的4篇论文聚焦大语言模型知识溯源、图文音多模态大模型、大




评论