 hadoop云存储解决方案
hadoop云存储解决方案

Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
基于Hadoop的校园云存储系统
服务器使用Linux操作系统,采用MapReduce编程算法实现并行处理。
HDFS(Hadoop Distributed File System)是一个运行在普通硬件之上的分布式文件系统。HDFS系统采用Master/Slave框架,一个HDFS集群系统是由一个Master和多个Slaver构成。前者叫做名字节点(NameNode),是一个中心服务器负责元数据的管理工作,主要包括文件系统的名字空间管理和客户机对文件的访问操作。后者叫做数据节点(DataNode),在集群系统中一般一个节点是由一个DataNode构成的,主要负责对节点上它们附带的存储进行管理。
HDFS系统中文件的目录结构独立存储在NameNode上,对于具体的文件数据来说,一个文件数据其实被拆分成若干block,这些block冗余存储在DataNode集合数据里。NameNode负责执行文件系统的Namespace管理工作,主要包括关闭,打开和重命名数据文件和目录等操作,同时负责建立block和DataNode节点的映射关系。客户机的读写需求是由DataNode节点响应完成的,同时DataNode节点在NameNode的统一指挥下进行Block的创建,删除和复制等操作。
MapReduce编程模型是一种编程模型,是云计算的核心计算模式,用于大规模数据集的并行计算。MapReduce借用了函数式编程的思想,把海量数据集的常见操作抽象为Map(映射)和Reduce(化简)两种集合操作。通过Map函数将被分割后数据映射成不同的区块,然后由计算机集群对分配的数据进行分布式运算处理,再由Reduce函数对数据结果进行统一汇整,最后输出用户想要的数据结果。MapReduce的软件实现是指定一个Map函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(化简)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
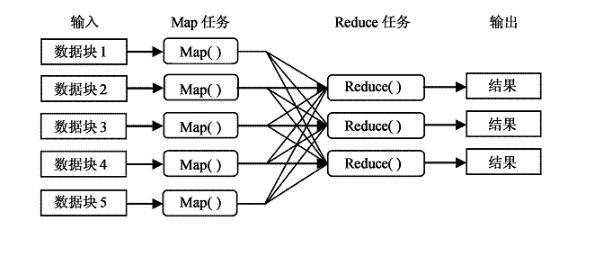
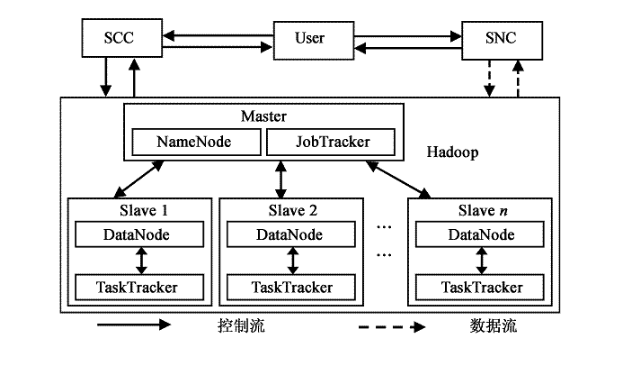
Master包括NameNode和JobTracker,Slaves包括DataNodes和TaskTrackers.HDFS的工作主要由NameNode和DataNodes共同完成,MapReduce的工作主要由JobTracker和TaskTrackers共同完成。模型工作流程:服务控制集群SCC(Service Controller Cluster)主要负责对用户应用请求进行接收,并根据用户的请求完成应答工作。存储节点集群SNC(Storage Node Cluster)主要负责处理数据资源的存取工作。JobTracker可以运行在集群系统中的每一台计算机上,主要完成管理和调度其它计算机上的TaskTracker。
不同的是TaskTracker必须运行在数据存储节点的DataNode上,主要完成执行任务工作。JobTracker负责将每一个Map和Reduce任务分配给空闲的TaskTracker处理,完成对每个数据文件并行计算处理任务,同时将每个任务运行完成的情况进行监控。当其中一个TaskTracker发生故障时,JobTracker会主动将其负责的任务转交给另外一个空闲的TaskTracker重新执行完成这个任务。用户本身不直接通过Hadoop架构进行读写数据,这由可以避免大量的读写操作造成的系统拥塞。当用户通过Hadoop架构把信息传给SCC后,将直接与存储节点进行交互,同时完成数据读取操作。
系统采用Hadoop软件,7台PC,其中一台为Master,namenode(集群主节点);另外六台为Slave, datanode(从节点)。
集群部署步骤:
(1)。 集群配置SSH,实现机器间免密码登陆。在每台机器上生成ssh密钥,然后交换公钥,将namenode的公钥拷贝到每台datanode,这样互相访问就不需要密码了。
(2)。 在每台机器上安装JDK,配置java环境。
(3)。 安装配置hadoop。
(4)。 启动hadoop服务。
(5)。 安装eclipse,搭建集成开发环境。
基于Hadoop平台的云存储
云计算(Cloud Computing)是一种基于因特网的超级计算模式,在远程的数据中心里,成千上万台电脑和服务器连接成一片电脑云。用户通过电脑、笔记本、手机等方式接人数据中心,按自己的需求进行运算。目前,对于云计算仍没有普遍一致的定义。结合上述定义,可以总结出云计算的一些本质特征,即分布式计算和存储特性、高扩展性、用户友好性、良好的管理性。
1云存储架构图
橘色的作为存储节点(Storage Node)负责存放文件,蓝色作为控制节点((Control Node)则是负责文件索引,并负责监控存储节点间容量及负载的均衡,这两个部分合起来便组成一个云存储。存储节点与控制节点都是单纯的服务器,只是存储节点的硬盘多一些,存储节点服务器不需要具备RAID的功能,只要能安装Linux即可,控制节点为了保护数据,需要有简单的RAID level O1的功能。
云存储不是要取代现有的盘阵,而是为了应付高速成长的数据量与带宽而产生的新形态存储系统,因此云存储在设计时通常会考虑以下三点:
(1)容量、带宽的扩容是否简便
扩容是不能停机,会自动将新的存储节点容量纳入原来的存储池。不需要做繁复的设定。
图1云存储架构图
(2)带宽是否线形增长
使用云存储的客户,很多是考虑未来带宽的增长,因此云存储产品设计的好坏会产生很大的差异,有些十几个节点便达到饱和,这样对未来带宽的扩容就有不利的影响,这一点要事先弄清楚,否则等到发现不符合需求时,已经买了几百TB,后悔就来不及了。
(3)管理是否容易。
2云存储关键技术
云存储必须具备九大要素:①性能;②安全性;③自动ILM存储;④存储访问模式;⑤可用性;⑥主数据保护;⑦次级数据保护;⑧存储的灵活;⑨存储报表。
云计算的发展离不开虚拟化、并行计算、分布式计算等核心技术的发展成熟。下面对其介绍如下:
(1)集群技术、网格技术和分布式文件系统
云存储系统是一个多存储设备、多应用、多服务协同工作的集合体,任何一个单点的存储系统都不是云存储。
既然是由多个存储设备构成的,不同存储设备之间就需要通过集群技术、分布式文件系统和网格计算等技术,实现多个存储设备之间的协同工作,使多个的存 储设备可以对外提供同一种服务,并提供更大更强更好的数据访问性能。如果没有这些技术的存在,云存储就不可能真正实现,所谓的云存储只能是一个一个的独立 系统,不能形成云状结构。
(2)CDN内容分发、P2P技术、数据压缩技术、重复数据删除技术、数据加密技术
CDN内容分发系统、数据加密技术保证云存储中的数据不会被未授权的用户所访问,同时,通过各种数据备份和容灾技术保证云存储中的数据不会丢失,保证云存储自身的安全和稳定。如果云存储中的数据安全得不到保证,也没有人敢用云存储了。
(3)存储虚拟化技术、存储网络化管理技术
云存储中的存储设备数量庞大且分布多在不同地域,如何实现不同厂商、不同型号甚至于不同类型(例如FC存储和IP存储)的多台设备之间的逻辑卷管 理、存储虚拟化管理和多链路冗余管理将会是一个巨大的难题,这个问题得不到解决,存储设备就会是整个云存储系统的性能瓶颈,结构上也无法形成一个整体,而 且还会带来后期容量和性能扩展难等问题。
3部署Hadoop
从历史上看,数据分析软件面对当今的海量数据已显得力不从心,这种局面正在悄然转变。新的海量数据分析引擎已经出现。例如Apache的Hadoop,实践证明,Hadoop在数据处理方面是做得最好的且是开源的平台之一。
云存储中心是由大量服务器构成Hadoop的数据节点((DataNodes),负责保存文件的内容,实现文件的分布式存储、负载平衡以及文件的容错控制。
下面将利用Hadoop作为实验平台,一步一步演示如何部署一个三个节点的集群,并测试一下MapRe-dace分布式处理的强大功能,在Hadoop分布式文件系统(HDFS)中存人两个文件,并采用MapReduce计算出两个namelist文件中各个名字出现的次数,程序架构设计如图2所示。
图2 3个节点的Hadoop集群
其中NameNode主节点和DataNode从节点的分布情况如下:
表1
(1)启动Hadoop集群
只需要在NameNode主节点上执行start-all.sh命令即可,同时Master节点可以通过ssh登录到各,lave节点去启动其他相关进程。
(2) MapRudce测试
在NameNode和DataNode两个结点都运行正常的时候,也就是Hadoop部署成功了之后,我们在NameNode主节点上准备两个名单文件。名单文件的内容如下:
4运行实验及结果
5结语
结果跟我们预期的一样,这样在以Hadoop为平台进行了对HDFS的文件存储,并且统计了文件中数据的数量,然后显示出来。
-
云存储
+关注
关注
7文章
779浏览量
47246 -
Hadoop
+关注
关注
1文章
90浏览量
16821
发布评论请先 登录

从零开始学习hadoop?hadoop快速入门
hadoop和spark的区别
如何用MRAM和NVMe SSD构建未来的云存储的解决方案
用Linux和Apache Hadoop进行云计算







 工商网监
工商网监
评论