 在英特尔酷睿Ultra处理器上优化和部署YOLOv8模型
在英特尔酷睿Ultra处理器上优化和部署YOLOv8模型

英特尔 酷睿 Ultra处理器是英特尔公司推出的一个高端处理器品牌,其第一代产品基于Meteor Lake架构,使用Intel 4制程,单颗芯片封装了 CPU、GPU(Intel Arc Graphics)和 NPU(Intel AI Boost),具有卓越的AI性能。
本文将详细介绍使用OpenVINO工具套件在英特尔 酷睿Ultra处理器上实现对YOLOv8模型的INT8量化和部署。
1
第一步:环境搭建
首先,请下载并安装最新版的NPU和显卡驱动:
NPU 驱动:https://www.intel.cn/content/www/cn/zh/download/794734/intel-npu-driver-windows.html
显卡驱动:
https://www.intel.cn/content/www/cn/zh/download/785597/intel-arc-iris-xe-graphics-windows.html
然后,请下载并安装Anaconda,然后创建并激活名为npu的虚拟环境:(下载链接:https://www.anaconda.com/download)
conda create -n npu python=3.11 #创建虚拟环境 conda activate npu #激活虚拟环境 python -m pip install --upgrade pip #升级pip到最新版本
最后,请安装openvino、nncf、onnx和ultralytics:
pip install openvino nncf onnx ultralytics
2
第二步:导出yolov8s模型并实现INT8量化
使用yolo命令导出yolov8s.onnx模型:
yolo export model=yolov8s.pt format=onnx
使用ovc命令导出OpenVINO格式,FP16精度的yolov8s模型
ovc yolov8s.onnx

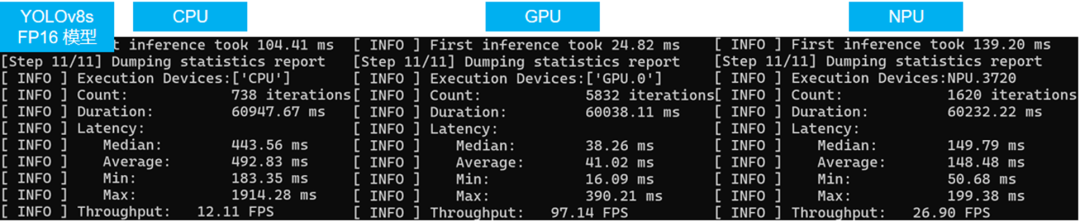
使用benchmark_app程序依次测试FP16精度的yolov8s模型在CPU,GPU和NPU上的AI推理性能,结果如下图所示:
benchmark_app -m yolov8s.xml -d CPU #此处依次换为GPU,NPU
用NNCF实现yolov8s模型的INT8量化
NNCF全称Neural Network Compression Framework,是一个实现神经网络训练后量化(post-training quantization)和训练期间压缩(Training-Time Compression)的开源工具包,如下图所示,通过对神经网络权重的量化和压缩以最低精度损失的方式实现推理计算的优化和加速。
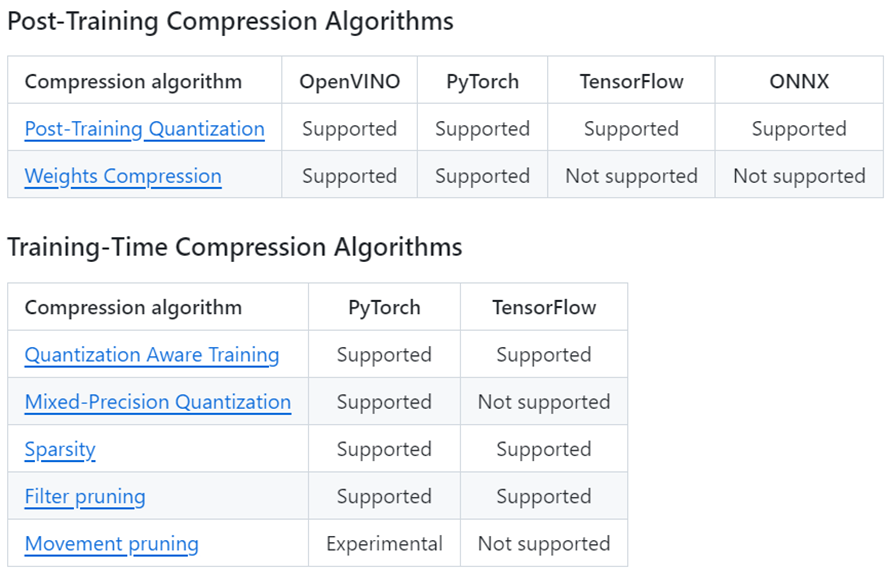
NNCF提供的量化和压缩算法
在上述量化和压缩算法中,训练后INT8量化(Post-Training INT8 Quantization)是在工程实践中应用最广泛的,它无需重新训练或微调模型,就能实现模型权重的INT8量化,在获得显著的性能提升的同时,仅有极低的精度损失,而且使用简便。
用NNCF实现YOLOv8s模型INT8量化的范例代码yolov8_PTQ_INT8.py,如下所示:
import torch, nncf import openvino as ov from torchvision import datasets, transforms # Specify the path of model and dataset model_dir = r"yolov8s.xml" dataset = r"val_dataset" # Instantiate your uncompressed model model = ov.Core().read_model(model_dir) # Provide validation part of the dataset to collect statistics needed for the compression algorithm val_dataset = datasets.ImageFolder(dataset, transform=transforms.Compose([transforms.ToTensor(),transforms.Resize([640, 640])])) dataset_loader = torch.utils.data.DataLoader(val_dataset, batch_size=1) # Step 1: Initialize transformation function def transform_fn(data_item): images, _ = data_item return images.numpy() # Step 2: Initialize NNCF Dataset calibration_dataset = nncf.Dataset(dataset_loader, transform_fn) # Step 3: Run the quantization pipeline quantized_model = nncf.quantize(model, calibration_dataset) # Step 4: Save the INT8 quantized model ov.save_model(quantized_model, "yolov8s_int8.xml")
运行yolov8_PTQ_INT8.py,执行结果如下所示:
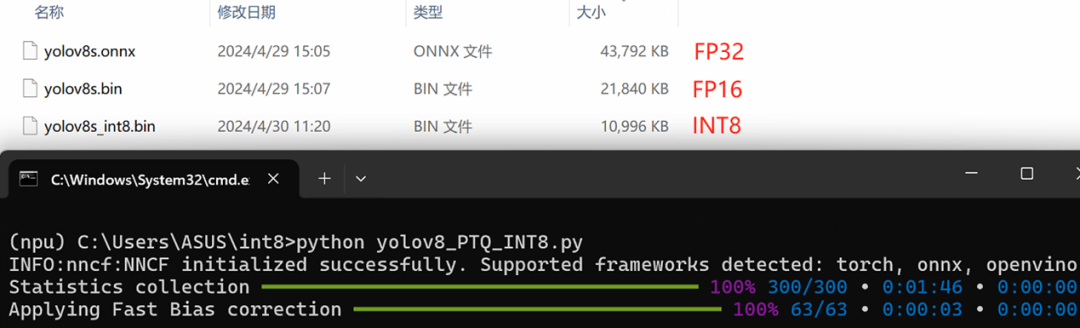
使用benchmark_app程序依次测试INT8精度的yolov8s模型在CPU,GPU和NPU上的AI推理性能,结果如下图所示:
benchmark_app -m yolov8s_int8.xml -d CPU #此处依次换为GPU,NPU
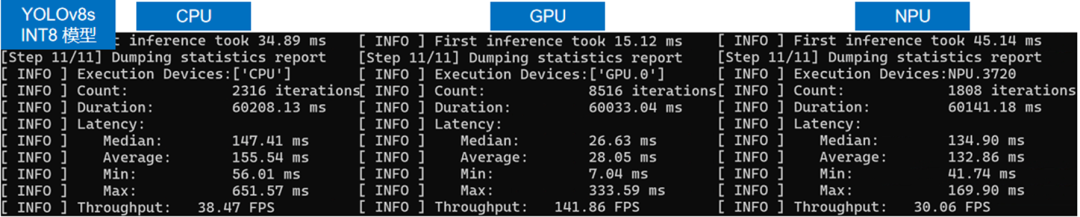
从上图可以看出,yolov8s模型经过INT8量化后,相比FP16精度模型,无论在Latency还是Throughput上,都有明显提升。
3
第三步:编写YOLOv8推理程序
yolov8目标检测模型使用letterbox算法对输入图像进行保持原始宽高比的放缩,据此,yolov8目标检测模型的预处理函数实现,如下所示:
from ultralytics.data.augment import LetterBox # 实例化LetterBox letterbox = LetterBox() # 预处理函数 def preprocess_image(image: np.ndarray, target_size=(640, 640))->np.ndarray: image = letterbox(image) #YOLOv8用letterbox按保持图像原始宽高比方式放缩图像 blob = cv2.dnn.blobFromImage(image, scalefactor=1 / 255, size=target_size, swapRB=True) return blob
yolov8目标检测模型的后处理函数首先用非极大值抑制non_max_suppression()算法去除冗余候选框,然后根据letterbox的放缩方式,用scale_boxes()函数将检测框的坐标点还原到原始图像上,如下所示:
# 后处理函数: 从推理结果[1,84,8400]的张量中拆解出:检测框,置信度和类别
def postprocess(pred_boxes, input_hw, orig_img, min_conf_threshold = 0.25,
nms_iou_threshold = 0.7, agnosting_nms = False, max_detections = 300):
# 用非极大值抑制non_max_suppression()算法去除冗余候选框
nms_kwargs = {"agnostic": agnosting_nms, "max_det":max_detections}
pred = ops.non_max_suppression(
torch.from_numpy(pred_boxes),
min_conf_threshold,
nms_iou_threshold,
nc=80,
**nms_kwargs
)[0]
# 用scale_boxes()函数将检测框的坐标点还原到原始图像上
shape = orig_img.shape
pred[:, :4] = ops.scale_boxes(input_hw, pred[:, :4], shape).round()
return pred
完整代码详细参见:yolov8_infer_ov.py,其运行结果如下所示:

4
总结
英特尔 酷睿 Ultra处理器内置了CPU、GPU和NPU,相比之前,无论是能耗比、显卡性能还是AI性能,都有显著提升;通过OpenVINO和NNCF,可以方便快捷实现AI模型的优化和INT量化,以及本地化部署,获得非常不错的端侧AI推理性能。
审核编辑:刘清
-
处理器
+关注
关注
68文章
20149浏览量
247169 -
英特尔
+关注
关注
61文章
10275浏览量
179311 -
GPU芯片
+关注
关注
1文章
306浏览量
6399 -
OpenVINO
+关注
关注
0文章
117浏览量
716
原文标题:在英特尔® 酷睿™ Ultra处理器上优化和部署YOLOv8模型 | 开发者实战
文章出处:【微信号:英特尔物联网,微信公众号:英特尔物联网】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
使用ROCm™优化并部署YOLOv8模型
英特尔酷睿Ultra 200HX游戏本发布
在英特尔酷睿Ultra AI PC上部署多种图像生成模型

英特尔酷睿Ultra处理器助力亦心AI闪绘本地功能上线
微星携英特尔为玩家打造非凡游戏体验,两款泰坦家族新品均搭载全新英特尔酷睿Ultra HX处理器
为什么在Ubuntu20.04上使用YOLOv3比Yocto操作系统上的推理快?
在英特尔酷睿Ultra AI PC上用NPU部署YOLOv11与YOLOv12

英特尔酷睿 Ultra 9 275HX 成为 PassMark 上最快的笔记本处理器





 工商网监
工商网监
评论