 gprofng如何帮助我们深入研究Java应用程序的动态行为?
gprofng如何帮助我们深入研究Java应用程序的动态行为?

首先,编写一个矩阵乘法程序(matrix multiplication program)。我写了一个完整的矩阵乘法程序,这比矩阵向量乘法(matrix-times-vector)要简单。主要有三种操作:
1
计算最内层乘加操作(the inner-most multiply-add)
2
将乘加操作合并为结果中的单个元素
3
对最终结果的每个元素进行迭代计算
我将矩阵乘法的计算过程放入一个简单的框架中,以便能够重复地计算矩阵乘积,从而确保测量是可多次重复的(见附注 1)。该程序会在每次矩阵相乘开始时(相对于 Java 虚拟机的启动时间)打印出信息,包括每次矩阵相乘所需的时间。我还运行了一个测试,将两个 8000x8000 的矩阵相乘,该框架会重复计算 11 次,并为了使后续不同行为的特征更突出,在每次重复之间设置休眠 920 毫秒:
$ numactl --cpunodebind=0 --membind=0 -- java -XX:+UseParallelGC -Xms31g -Xmx31g -Xlog:gc -XX:-UsePerfData MxV -m 8000 -n 8000 -r 11 -s 920
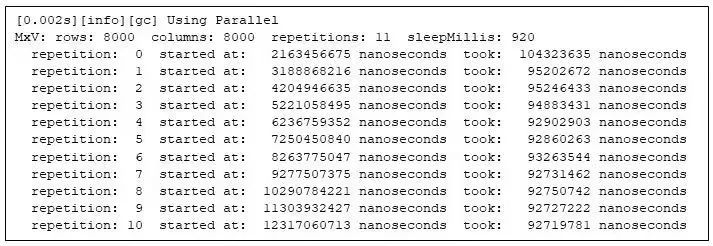
图 1:矩阵乘法程序的运行情况
第二次重复运行的用时是第一次的 92%;到最后一次重复运行时,用时仅为第一次的 89%。执行时间的变化证明了Java 程序需要一段预热的时间。
那么问题来了:能否用 gprofng 来分析第一次与最后一次重复运行之间的差异,从而促进性能提升?
为了回答这个问题,我们可以运行程序并让 gprofng 收集有关运行的信息。方法非常简单,只需在命令行中添加 gprofng 命令前缀,即可收集 gprofng 称之为 “experiment” 的信息。
$ numactl --cpunodebind=0 --membind=0 --
gprofng collect app
java -XX:+UseParallelGC -Xms31g -Xmx31g -Xlog:gc --XX:-UsePerfData
MxV -m 8000 -n 8000 -r 11 -s 920
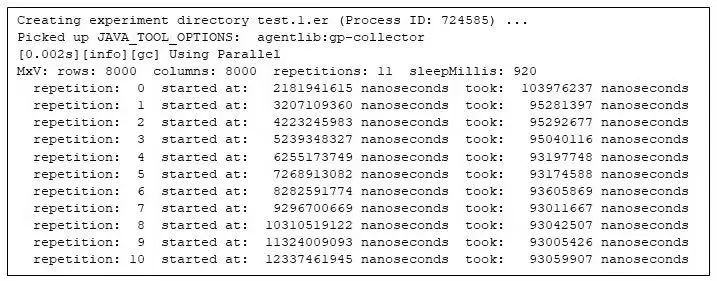
图 2:在 gprofng 下运行矩阵乘法程序
首先需要注意的是,与其它 profiling 工具一样,gprofng 在收集 profiling 信息时也会为应用程序带来开销(overhead),好消息是,与不加 profiling 信息运行相比,gprofng 所带来的开销看起来并不显著。
随后,可以通过 gprofng 深入了解整个应用程序的时间消耗情况(见附注 2)。对于整个运行过程,gprofng 显示了24 个最耗时的函数调用,具体如下:
$ gprofng display text test.1.er -viewmode expert -limit 24 -functions
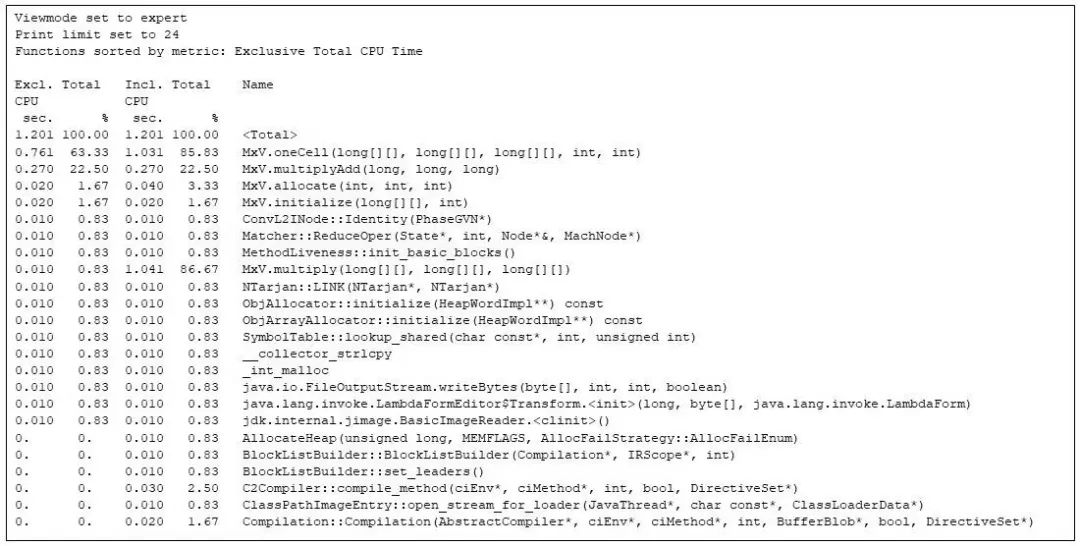
图 3:Gprofng 展示了 24 个最耗时的函数调用
上面的函数视图展示了每种方法的独占 CPU 时间和总体 CPU 时间,均以秒为单位,并以总 CPU 时间的百分比表示。被命名的的函数是由 gprofng 生成的伪函数(pseudo function),其值为各种指标的总和。从数据中可以看出,整个应用程序消耗的总 CPU 时间为 1.201 秒。
其中,应用程序中属于 Matrix times Vector(MxV)类的方法占用了大部分 CPU 时间,但除此之外还有其它方法,如 JVM 的运行时编译器(Compilation::Compilation)和不属于矩阵乘法的其他函数。此外,图表在展示整体程序执行情况的同时,还捕捉到了分配(MxV.allocate)和初始化(MxV.initialize)的代码。不过,我对这些代码不太感兴趣,因为它们是测试框架的一部分,仅在启动期间使用,与矩阵乘法本身关联不大。
gprofng 可以让我专注在感兴趣的应用程序部分上。它有一个奇妙之处是,在收集实验之后,我可以使用过滤器来处理收集到的数据。例如,查看在特定时间间隔内发生了什么,或者查看特定方法在调用栈(call stack)上的情况。为了演示和方便进行过滤,我在程序中添加了 Thread.sleep(ms)的策略性调用,这样可以更容易地基于相隔一秒的程序阶段编写过滤器。这就是为什么在图 1 的程序输出中,即使每个矩阵相乘只花费约 0.1 秒,但每次重复之间仍相隔约 1 秒的原因。
gprofng 支持编写脚本。我用它编写了一个脚本,用于从 gprofng 实验中提取不同秒数的数据。第一秒主要与 Java 虚拟机的启动相关:
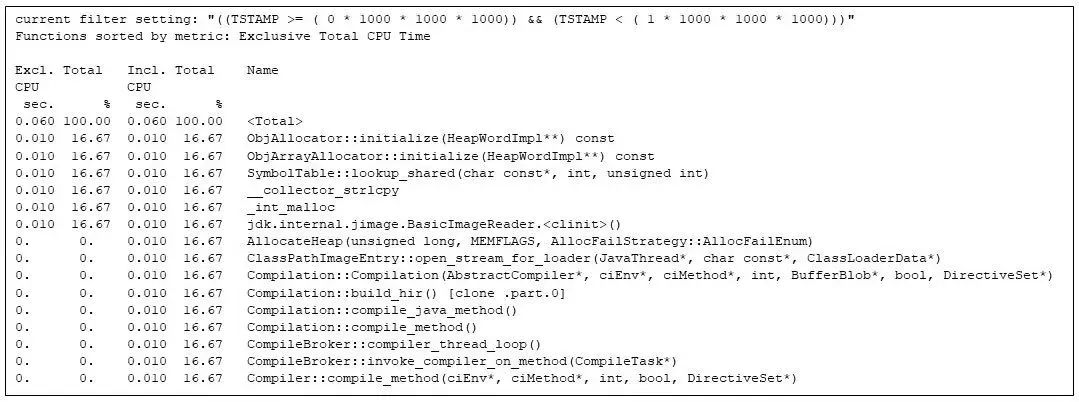
图 4:筛选出第 1 秒内最耗时的函数调用。为了能够清楚地展示 JVM 的启动过程,我特意在矩阵乘法上制造了一些延迟。
即使应用程序中的所有函数调用都尚未开始运行,运行时编译器(例如 Compilation::compile_java_method,占用了约 16% 的 CPU 时间)就已经启动。(由于我插入了 sleep 调用,矩阵乘法调用被延迟了。)
第 1 秒之后,第 2 秒主要是分配函数和初始化函数的运行,以及各种 JVM 函数的执行。但此时,矩阵乘法的任何代码都尚未开始执行:
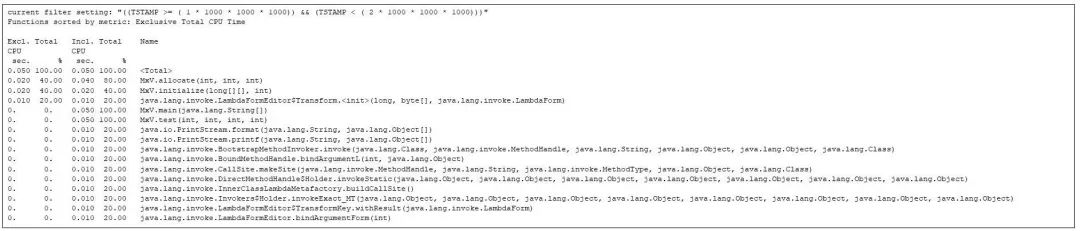
图 5:展示了第 2 秒内最耗时的函数。矩阵的分配和初始化与 JVM 的启动互相竞争。
此时 JVM 启动以及数组的分配和初始化已完成。如图 6 所示,第 3 秒是矩阵乘法代码的第一次重复。但请注意,矩阵乘法代码正在与 Java 运行时编译器争夺机器资源(例如,图 6 中的CompileBroker::invoke_compiler_on_method 占比 8%),这是由于矩阵乘法代码耗时较多,这时仍在进行编译。
即便如此,矩阵乘法代码(例如,在 MxV.main 方法中的“包含”时间占比 91%)占用了大部分 CPU 时间。包含时间显示矩阵乘法(如 MxV.multiply)需要 0.100 CPU 秒,这与图 2 中应用程序报告的墙上时钟一致。(收集和报告墙上时钟需要一定的时间,但这不包括 gprofng 计算 MxV.multiply 方法所占用的 CPU 时间)。
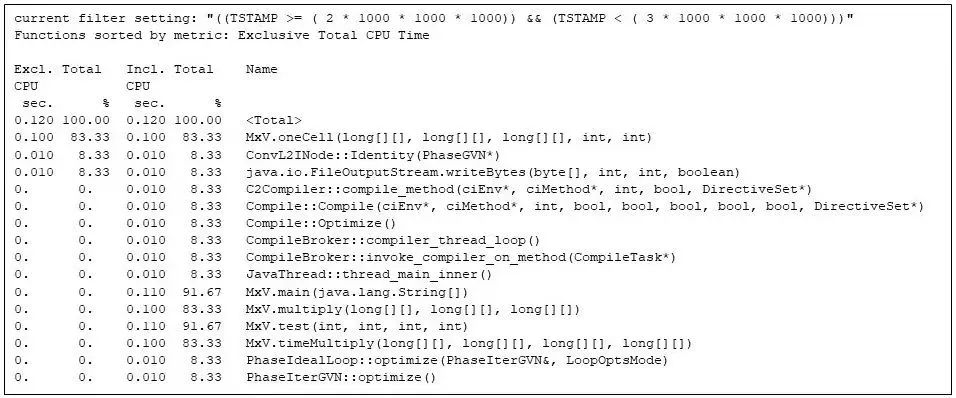
图 6:第 3 秒内最耗时的函数,显示了运行时编译器与矩阵乘法方法之间的资源竞争。
在这个特定的示例中,矩阵乘法实际上并没有参与争夺 CPU 时间,因为测试是在具有大量空闲周期的多处理器系统上运行,而运行时编译器则作为单独的线程运行。在某些特定的、受到限制的情况下,例如在负载较重的共享机器上,运行时编译器占用 8% 的时间可能会对整体性能造成影响。但另一方面,在运行时编译器上花费时间会使得方法能够更高效地执行,因此,如果要计算多个矩阵乘法,我比较倾向于采取这种方法。
到第 5 秒时,矩阵乘法代码就独占了 Java 虚拟机的执行时间:
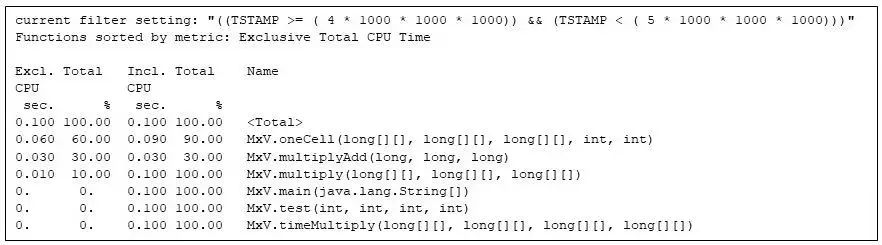
图 7:在第 5 秒内运行的所有函数,只有矩阵乘法函数是活跃的。
请注意,MxV.oneCell、MxV.multiplyAdd 和 MxV.multiply 之间独占 CPU 秒数的占比分别为60%、30% 和 10%。MxV.multiplyAdd 方法仅计算乘法和加法,但它是矩阵乘法中最内层的方法。MxV.oneCell 方法有一个调用 MxV.multiplyAdd 的循环,循环的开销和调用(评估条件和控制转移)比 MxV.multiplyAdd 中的直接算术更加繁重(这种差异反映在两者的独占时间中,MxV.oneCell 为 0.060 CPU 秒,而 MxV.multiplyAdd 为 0.030 CPU 秒)。MxV.multiply 中的外层循环执行频率不够高,以至于运行时编译器尚未对其进行编译,但该方法仅用了 0.010 CPU 秒。
矩阵乘法持续进行到第 9 秒,此时 JVM 运行时编译器再次启动,我们发现 MxV.multiply 已频繁执行,占用了较多的执行时间:
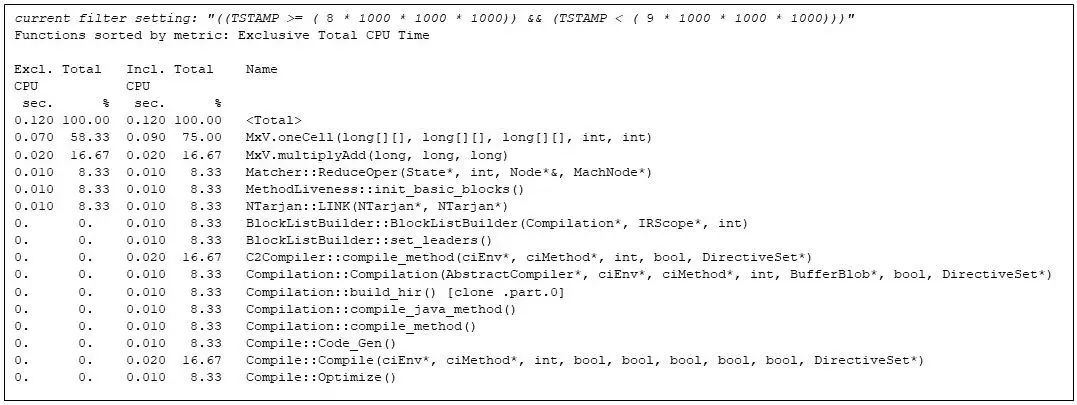
图 8:第 9 秒内最耗时的函数,显示运行时编译器已再次启动。
到最后一次重复之前,矩阵乘法代码完全占用了Java 虚拟机的执行资源:
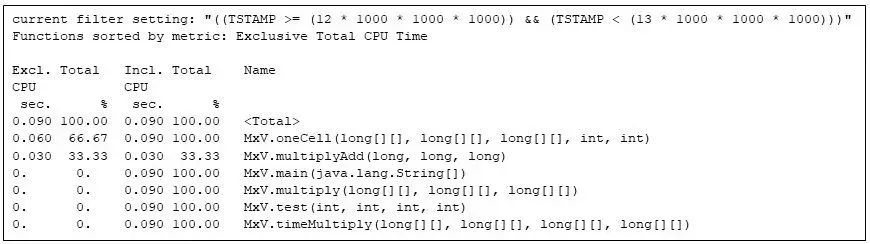
图 9:矩阵相乘程序的最后一次重复,展示了代码在整个程序执行结束时的最终配置。
结 论
我通过对运行时的 Java 程序使用 gprong 进行深入分析了解到了它的易用性。利用 gprofng 的过滤功能,我可以进行时间片段检查实验,从而专注于自己感兴趣的程序阶段。例如,通过排除应用程序的分配和初始化阶段,并在运行时编译器工作时仅显示一次程序重复,我能够清晰地观察到热代码在编译过程中性能不断提升的情况。
附注
①程序命令行的各个组成部分的原因解释:
(1) numactl --cpunodebind=0 --membind=0 --
将 Java 虚拟机使用的内存限制为一个 NUMA 节点的内核和内存。将 JVM 限制在一个节点,可以减少程序在运行过程中的变化,使程序在运行中的表现更加稳定。
(2) java
所使用的是适用于 aarch64 架构的 OpenJDK 版本 jdk-17.0.4.1。
(3)-XX:+UseParallelGC
启用并行垃圾回收器(parallel garbage collector),它在所有可用回收器中执行的后台工作最少。
(4)-Xms31g -Xmx31g
提供足够的 Java 对象内存溢出(heap space),以确保不需要进行垃圾回收。
(5)-Xlog:gc
记录 GC 活动,以核实确实不需要进行收集。(正如那句名言所说:“信任是必须的,但核实也是必要的。”)
(6)-XX:-UsePerfData
降低 Java 虚拟机的开销。
②gprofng 选项的原因:
(1) limit 24
仅显示占用 CPU 时间最多的 24 个函数(并按独占 CPU 时间进行排序)。这使我能够了解哪些函数几乎不花费时间,从而集中关注那些在程序执行期间占用最多 CPU 时间的函数。后续,我还将在某些情况下使用 limit 16,以便掌握哪些函数占用极少 CPU 时间。有时 gprofng 工具本身也可能限制显示的数量,因为并不是所有的函数都能累计出大量的时间。
(2) viewmode expert
显示所有累计 CPU 时间的函数,而不仅仅是 Java 函数,还包括 JVM 本身固有的函数,使用此标记可以让我查看运行时编译器函数等。
审核编辑:刘清
-
多处理器
+关注
关注
0文章
22浏览量
9195 -
JAVA
+关注
关注
20文章
2997浏览量
115692 -
JVM
+关注
关注
0文章
161浏览量
12957 -
虚拟机
+关注
关注
1文章
968浏览量
30178
原文标题:技术文章 | Java 虚拟机的一天
文章出处:【微信号:AmpereComputing,微信公众号:安晟培半导体】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
[分享]超级经典的JAVA基础视频推荐,还有很多牛人写的学习感受!值得深入研究
【Landzo C1试用体验】+第六篇 超声波之深入研究
使用Eclipse WTP开发Java Web应用程序
深入研究USBType-C技术的细节
深入研究彻底掌握设备树
你能用任何测试代码或其他步骤来帮助我测试我的应用程序软件吗?
java小应用,java小应用程序下载
模式匹配算法的深入研究
深入研究Servlet线程安全性问题
如何用Java代码来创建iOS和Android应用程序
1.6设备树的引进与体验——只想使用设备树不想深入研究怎么办






 工商网监
工商网监
评论