 谷歌推出能一次生成完整视频的扩散模型
谷歌推出能一次生成完整视频的扩散模型

谷歌研究院近日发布了一款名为Lumiere的文生视频扩散模型,基于自家研发的Space-Time U-Net基础架构,独立生成具有高效、完整且动作连贯性的视频效果。
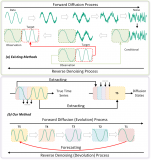
该公司指出,当前众多文生视频模型普遍存在无法生成长时、高品质及动作连贯的问题。这些模型往往采用“分段生成视频”策略,即先生成少量关键帧,再借助时间超级分辨率(TSM)技术生成其间的视频文件。尽管此策略可减缓RAM负担,但难以生成理想的连续视频效果。
针对此问题,谷歌的Lumiere模型创新地引入了新型Space-Time U-Net基础架构,这种架构能在空间和时间两个维度同时降低信号采样率,使其具备更高的计算效率,进而实现生成更具持续性、动作连贯的视频效果。
此外,开发者们特别说明,Lumiere每次可生成80帧视频(在16FPS模式下相当于5秒视频,或在24FPS模式下为约3.34秒视频)。尽管这一时光貌似短暂,然而他们强调,事实上,这段5秒视频所包含的镜头时长已超出大多数媒体作品中单一镜头的平均时长。
除运用架构创新以外,作为AI构建基础的预训练文生图像模型也得到了谷歌团队的特别关注。该模型首次生成简单像素草稿作为视频分帧,然后借助空间超分辨率(SRM)模型,逐步提高分帧分辨率,同时引入通用生成框架Multi-Diffusion以增强模型稳定性,从而确保最终输出的视频效果一致且连续。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
谷歌
+关注
关注
27文章
6245浏览量
110264 -
RAM
+关注
关注
8文章
1398浏览量
119831 -
AI
+关注
关注
89文章
38135浏览量
296732 -
模型
+关注
关注
1文章
3649浏览量
51716
发布评论请先 登录
相关推荐
热点推荐
一种基于扩散模型的视频生成框架RoboTransfer
在机器人操作领域,模仿学习是推动具身智能发展的关键路径,但高度依赖大规模、高质量的真实演示数据,面临高昂采集成本与效率瓶颈。仿真器虽提供了低成本数据生成方案,但显著的“模拟到现实”(Sim2Real)鸿沟,制约了仿真数据训练策略的泛化能力与落地应用。

谷歌新一代生成式AI媒体模型登陆Vertex AI平台
我们在 Vertex AI 上推出新一代生成式 AI 媒体模型: Imagen 4、Veo 3 和 Lyria 2。
4K、多模态、长视频:AI视频生成的下一个战场,谁在领跑?
电子发烧友网报道(文/李弯弯) 6月11日,豆包App上线视频生成模型豆包Seedance 1.0 pro。这是字节跳动最新视频模型,支持文字与图片输入,可
一次消谐装置与二次消谐装置区别、一次消谐器与二次消谐器的区别
一次消谐器与二次消谐器是电力系统中用于抑制谐振过电压的不同装置,主要区别如下:
安装位置:一次消谐器串联于电压互感器(PT)一次侧中性点与地之间,直接承受高电压;二

字节跳动即将推出多模态视频生成模型OmniHuman
一条完整的AI视频。 据即梦AI相关负责人透露,OmniHuman模型在研发过程中融入了前沿的人工智能技术,通过复杂的算法和深度学习机制,实现了图片与音频的精准匹配和
谷歌 Gemini 2.0 Flash 系列 AI 模型上新
谷歌旗下 AI 大模型 Gemini 系列全面上新,正式版 Gemini 2.0 Flash、Gemini 2.0 Flash-Lite 以及新一代旗舰大模型 Gemini 2.0 P
一次性锂电池为什么不能充电?一文讲清!
一次性锂电池不能充电,是由它的正负极材料、电解液等决定的。虽然它不能充电,但在某些场景下,还是有着不可替代的作用。希望通过这篇文章,能让大家对一次性锂电池有更深入的了解,以后在生活中使用的时候,也能更安全、更环保。

阿里云通义万相2.1视频生成模型震撼发布
近日,阿里云旗下的通义万相迎来了重要升级,正式推出了全新的万相2.1视频生成模型。这一创新成果标志着阿里云在视频生成技术领域的又
基于移动自回归的时序扩散预测模型
回归取得了比传统基于噪声的扩散模型更好的生成效果,并且获得了人工智能顶级会议 NeurIPS 2024 的 best paper。 然而在时间序列预测领域,当前主流的扩散方法还是传统的
借助谷歌Gemini和Imagen模型生成高质量图像
在快速发展的生成式 AI 领域,结合不同模型的优势可以带来显著的成果。通过利用谷歌的 Gemini 模型来制作详细且富有创意的提示,然后使用 Imagen 3

Google两款先进生成式AI模型登陆Vertex AI平台
新的 AI 模型,包括最先进的视频生成模型Veo以及最高品质的图像生成模型Imagen 3。近日,我们在 Google Cloud 上进
OpenAI暂不推出Sora视频生成模型API
OpenAI近日宣布,目前暂无推出其视频生成模型Sora的应用程序接口(API)的计划。Sora模型能够基于文本和图像生成
Lightricks与Shutterstock携手,推动开源LTXV视频人工智能生成式视频模型发展
,Lightricks将能够利用高质量HD和4K视频素材,进一步训练其开源视频生成模型——LTX Video(LTXV)。 Lightricks成为首个在Shutterstock行业首

OpenAI推出AI视频生成模型Sora
近日,备受期待的OpenAI再次推出了其创新之作——AI视频生成模型Sora。这一新品的发布,无疑为AI技术注入了新的活力。 据悉,Sora与OpenAI旗下的AI工具DALL-E有着
OpenAI开放Sora视频生成模型
升级,准备迎接广大用户的深入探索与广泛应用。 据官方公告介绍,Sora Turbo作为Sora的升级版本,具备强大的视频生成能力。它能够根据用户的文本提示,快速创建出最长达20秒的高清视频片段。更令人惊喜的是,Sora Turbo还能针对同





 工商网监
工商网监
评论