 搜索出生的百川智能大模型RAG爬坑之路总结
搜索出生的百川智能大模型RAG爬坑之路总结

今天对百川的RAG方法进行解读,百川智能具有深厚的搜索背景,来看看他们是怎么爬RAG的坑的吧~
总的来说,百川通过长上下文模型(192k)+搜索增强结合的方法来解决知识更新,降低模型幻觉的问题,使得其在5000万tokens的数据集中取得95%的精度。其主要在以下几个方面做优化:
1) Query拓展:这是我自己取的名字,可能不太准确,其主要参考Meta的CoVe[1]以及百川自研的Think Step-Further方法对原始用户输入的复杂问题进行拆解、拓展,挖掘用户更深层次的子问题,借助子问题检索效果更高的特点来解决复杂问题检索质量偏差的问题。
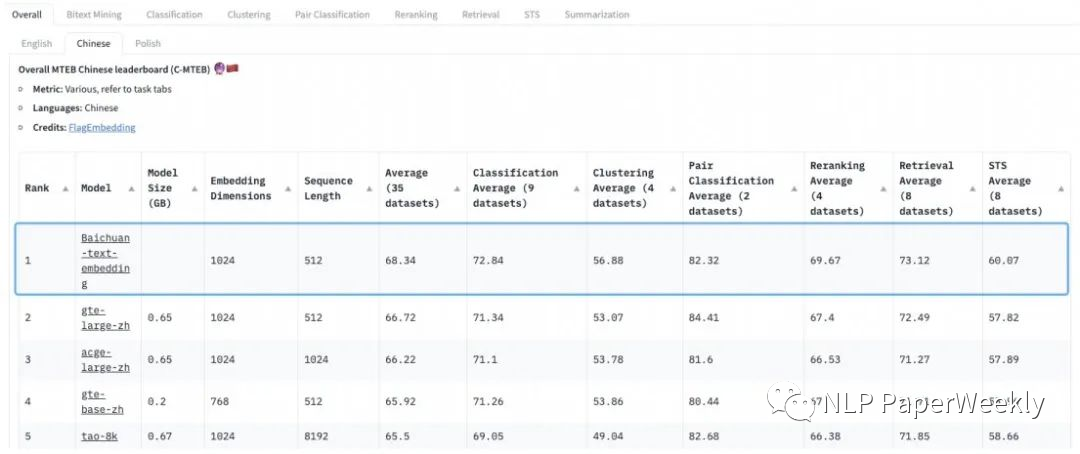
2) 优化检索链路:采用稀疏检索+向量检索+Rerank结合的方法,来提高检索的召回率和准确率。并且其自研的Baichuan-Text-Embedding向量模型也登顶了C-MTEB语义向量评测标准。
3) 自我反省机制:百川智能通过self-Critique大模型自省机制来筛选更优质、知识密度更高的内容。
一、概述
1Motivation
1.1 当前检索增强RAG方法痛点
成本高、召回偏低:扩展上下文窗口+引入向量数据库能以非常低的成本提高模型对新知识的接入能力,但是扩展上下文窗口容量有限(128k最多容纳23万汉字,相当于658kb文档),成本比较高,性能下降明显。向量数据库也存在召回率偏低、开发门槛高等缺点。
用户输入变复杂:与传统关键词或者短语搜索逻辑不太一致,用户输入问题不再是词或者短句,而是转变成自然对话声知识多轮对话数据,问题形式更加多元,紧密关联上下文,输入风格更加口语化。
1.2 RAG是当前大模型落地降低幻觉、更新数据的有效方法之一
行业大模型解决方案有后训练(Post-Train)和有监督微调(SFT),但是仍然无法解决大模型落地的幻觉和实效性问题。
后训练(Post-Train)和有监督微调(SFT)每次需要更新数据,重新训练,还可能会带来其他问题,成本比较大。
2Methods
省流版总结:
百川将长窗口与搜索/RAG(检索增强生成)相结合,形成长窗口模型+搜索的完整技术栈。
百川RAG方案总结:Query 扩展(参考Meta CoVe + 自研Think Step-Further) + 自研Baichuan-Text-Embedding向量模型 + 稀疏检索(BM25、ES) + rerank模型 + 自研Self-Critique技术(过滤检索结果)。
2.1 Query扩展
背景:与传统关键词或者短语搜索逻辑不太一致,用户输入问题不再是词或者短句,而是转变成自然对话声知识多轮对话数据,问题形式更加多元,紧密关联上下文,输入风格更加口语化。
目的:拆解复杂的prompt,检索相关子问题,并深度挖掘用于口语化表达中深层次含义,借助子问题检索效果更高的特点来解决复杂问题检索质量偏差的问题。
方法:参考Meta CoVe[1]以及Think Step-Further的方法,对用户原始的Query进行扩展,拓展出多个相关问题,然后通过相关问题去检索相关内容,提高召回率。
百川Query扩展方案:
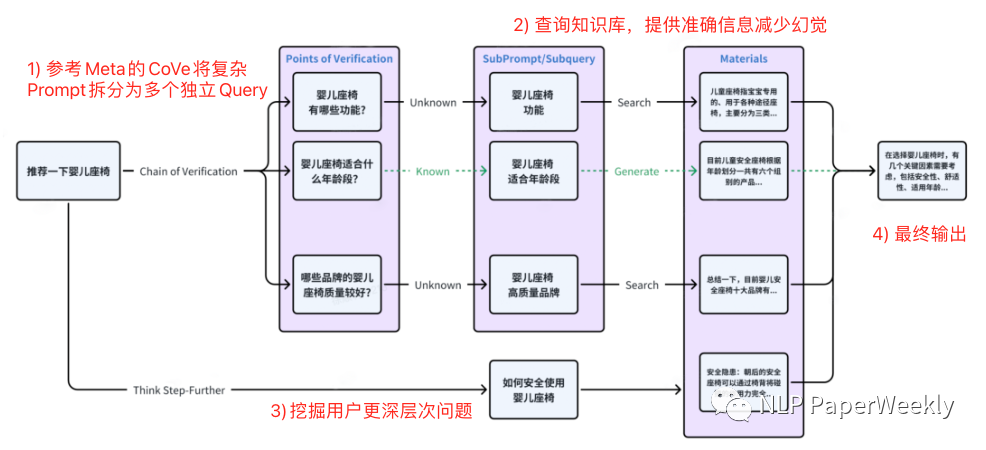
Meta CoVe方案:

2.2 自研Embedding模型
数据:在超过1.5T tokens(看着训练百川模型的数据都来训embedding模型了?)。
方法:采用无监督方法(估计类似SimCSE[2]系列),通过自研损失函数解决对比学习方式依赖batchsize问题。
效果:登顶C-MTEB,在分类、聚类、排序、检索和文本相似度5个任务评分取得领先。
2.3 多路召回+rerank
方法:稀疏检索+向量检索 + rerank模型。其中稀疏检索应该是指BM25、ES等传统检索的方法,rerank模型百川没有提到,不确定是用大模型来做rerank还是直接训练相关rerank模型来对检索结果排序。
效果:召回率95%,对比其他开源向量模型召回率低于80%。
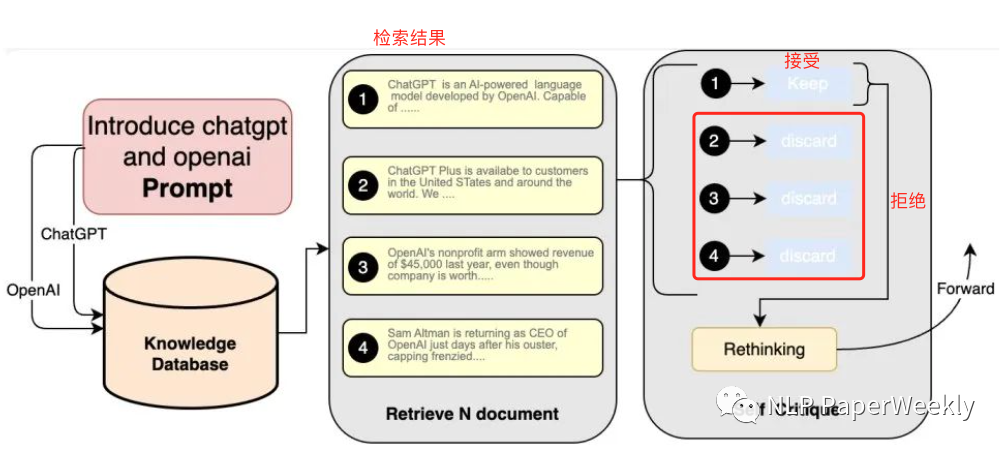
2.4 self-Critique
方法:让大模型基于 Prompt、从相关性和可用性等角度对检索回来的内容自省,进行二次查看,从中筛选出与 Prompt 最匹配、最优质的候选内容。
目的:提升检索结果的知识密度和广度,降低检索结果中的知识噪声。
3 Conclusion
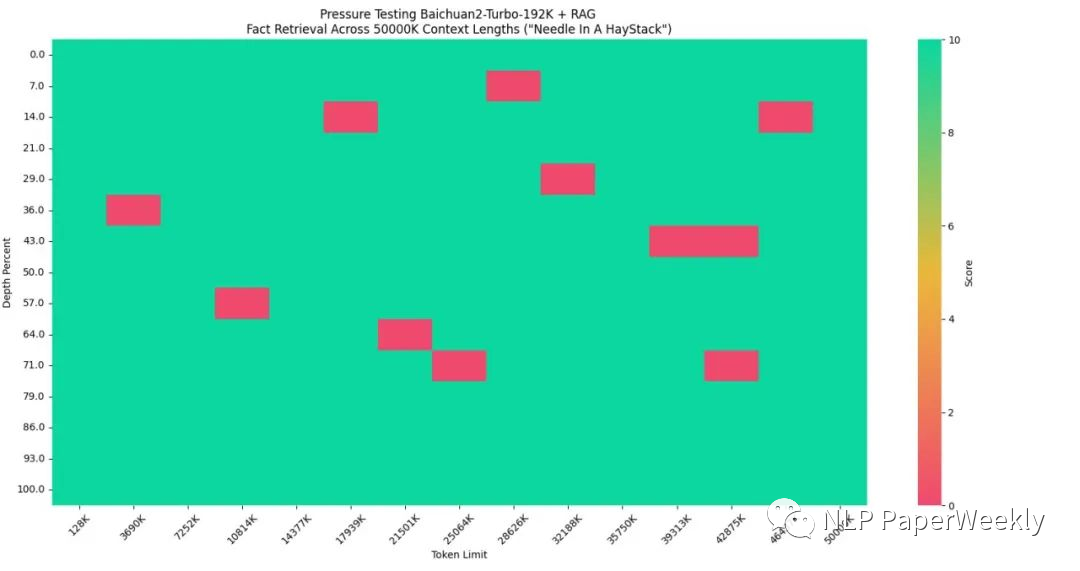
百川192K上下文模型表现不错,实现了100%的回答精度。
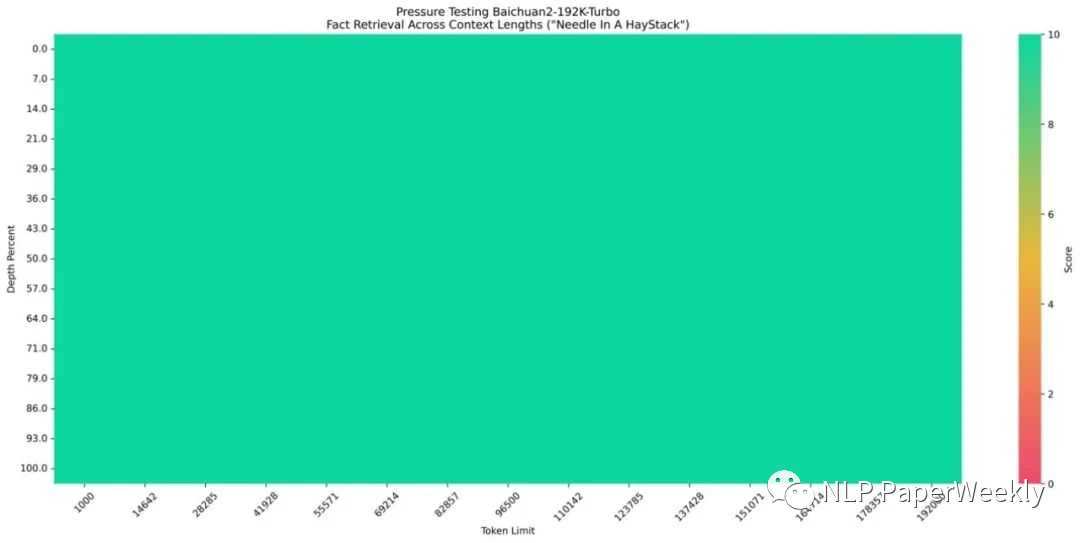
长上下文窗口模型+搜索增强技术使5000万Tokens数据集达到95%的回答精度。
二、总结
多轮问答等场景的召回和传统搜索引擎的召回分布还不太一样。百川借助子问题检索效果更高的特点,对原始复杂问题进行拆解、拓展来解决复杂问题检索质量偏差的问题。
对于没见过的语料直接用向量检索的结果可能不太理想。百川在大量语料上利用无监督方法训练embedding模型来优化效果。而行业大模型更倾向于私有的数据,要提升私有数据的训练效果还得继续在私有化数据上训练效果会更佳。
Query拓展 + 多路召回 + Rerank + self-Critique可能是现阶段比较好的一种RAG方式,但是其也会带来更多成本。总体思路有点像ReAct[3]系列的进阶版本,其在搜索侧和答案修正侧都做了更多的一些工作来优化实际效果。其缺点是需要多次调用大模型,会带来额外的成本,真实线上是否采用这种策略还有待验证。
审核编辑:刘清
-
SFT
+关注
关注
0文章
9浏览量
7056 -
百川智能
+关注
关注
0文章
18浏览量
192
原文标题:百川智能RAG方案总结:搜索出生的百川智能大模型RAG爬坑之路
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
白海科技与百川智能顺势而为、携手共进,助力领域大模型应用快速落地
百川的大模型KnowHow介绍
百川智能获阿里腾讯小米等3亿美元投资
百川智能发布Baichuan2 Turbo系列API,或将替代行业大模型
百川智能发布超千亿大模型Baichuan 3
数势联动百川,发布首批大模型联合解决方案,推动中国大模型价值落地
百川智能与北京大学将共建通用人工智能联合实验室
百川智能发布Baichuan 4大模型及首款AI助手“百小应”
亚马逊云科技接入百川智能和零一万物基础模型
大模型厂商“输血”不断,百川智能完成50亿元A轮融资!



评论