 Linux内核中RCU的用法
Linux内核中RCU的用法

一、RCU的法
RCU最常用的目的是替换已有的机制,如下所示:
读写锁
受限制的引用计数机制
批量引用计数机制
穷人版的垃圾回收器
存在担保
类型安全的内存
等待事物结束
1.1 RCU是读写锁的替代者
在Linux内核中,RCU最常见的用途是替换读写锁。在20世纪90年代初期,Paul在实现通用RCU之前,实现了一种轻量级的读写锁。后来,为这个轻量级读写锁原型所设想的每个用途,最终都使用RCU来实现了。
RCU和读写锁最关键的相似之处,在于两者都有可以并行执行读端临界区。事实上,在某些情况下,完全可以用对应的读写锁API来替换RCU的API,反之亦然。
RCU的优点在于:性能、不会死锁,以及良好的实时延迟。当然RCU也有一点缺点,比如:读者与更新者并发执行,低优先级RCU读者也可以阻塞正等待优雅周期(Grace Period)结束的高优先级线程,优雅周期的延迟可能达到好几毫秒。
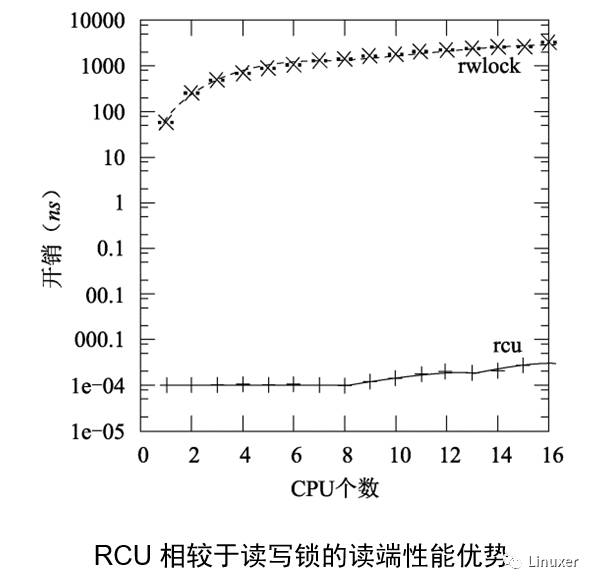
上图是不是略显奇怪,RCU读端延迟竟然小于一个CPU周期?这不是开玩笑,因为有某些实现中(例如,服务器Linux),RCU读端就完全是一个空操作。当然,在这样的实现中,它可能会包含一个编译屏障,因此也会对性能产生那么一点点影响。
请注意,在单个CPU上读写锁比RCU慢一个数量级,在16个CPU上读写锁比RCU几乎要慢两个数量级。随着CPU数量的增加,RCU的扩展性优势越来越突出。可以这么说,RCU几乎就是水平扩展,这可以在上图中看出来。
当内核配置了CONFIG_PREEMPT的时候,RCU仍然超过了读写锁一到三个数量级,如下图所示。请注意:读写锁在CPU数目很多时的陡峭曲线。
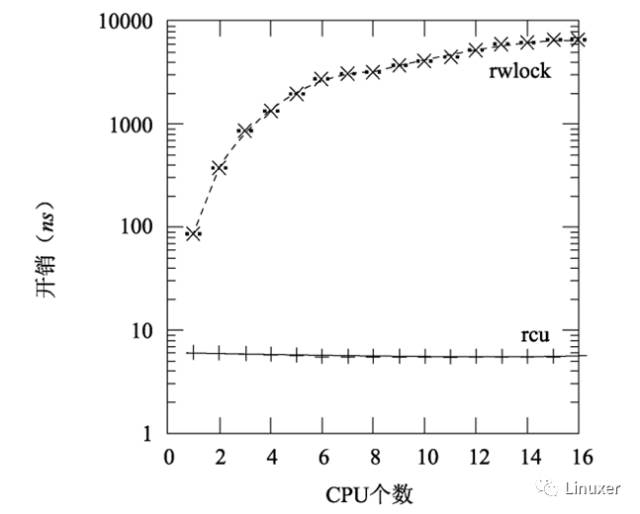
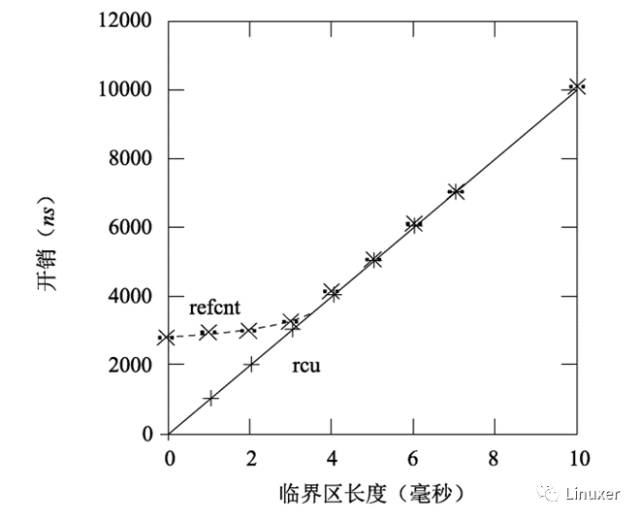
当然,上图中的临界区长度为0,这夸大了读写锁的性能劣势。随着临界区的加大,RCU的性能优势也不再显著。在下图中,有16个CPU,y轴代表读端原语的总开销,x轴代表临界区长度。
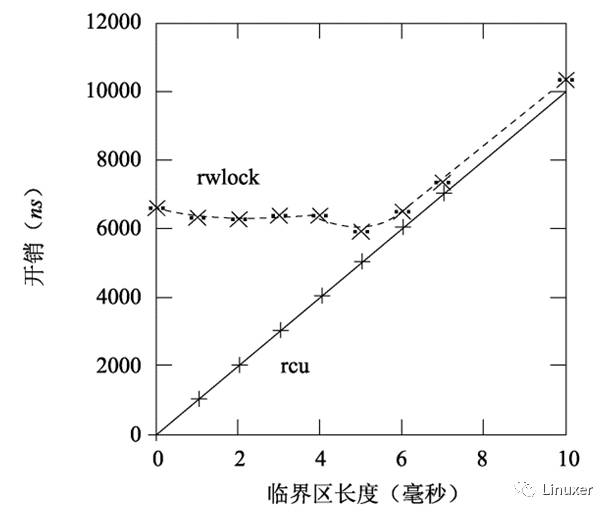
然而,一般说来,临界区都能在几个毫秒内完成,所以总的来说,在性能方面,测试结果对RCU是有利的。
另外,RCU读端原语基本上是不会死锁的。因为它本身就属于无锁编程的范畴。
这种免于死锁的能力来源于RCU的读端原语不阻塞、不自旋,甚至不存在向后跳转语句,所以RCU读端原语的执行时间是确定的。这使得RCU读端原语不可能形成死锁循环。
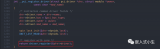
RCU读端免于死锁的能力带来了一个有趣的后果:RCU读者可以恣意地升级为RCU更新者。在读写锁中尝试这种升级则会有可能造成死锁。进行RCU读者到更新者升级的代码片段如下所示:
1 rcu_read_lock();
2 list_for_each_entry_rcu(p, &head, list_field) {
3 do_something_with(p);
4 if (need_update(p)) {
5 spin_lock(my_lock);
6 do_update(p);
7 spin_unlock(&my_lock);
8 }
9 }
10 rcu_read_unlock();
请注意,do_update()是在锁的保护下执行,也是在RCU读端的保护下执行。
RCU免于死锁的特性带来的另一个有趣后果是RCU不会受优先级反转问题影响。比如,低优先级的RCU读者无法阻止高优先级的RCU更新者获取更新端锁。类似地,低优先级的更新者也无法阻止高优先级的RCU读者进入RCU读端临界区。
另一方面,因为RCU读端原语既不自旋也不阻塞,所以这些原语有着极佳的实时延迟。而自旋锁或者读写锁都存在不确定的实时延迟。
但是,RCU还是会受到更隐晦的优先级反转问题影响,比如,在等待RCU优雅周期结束而阻塞的高优先级进程,会被-rt内核的低优先级RCU读者阻塞。这可以用RCU优先级提升来解决。
再一方面,因为RCU读者既不自旋也不阻塞,RCU更新者也没有任何类似回滚或者中止的语义,所以RCU读者和更新者可以并发执行。这意味着RCU读者有可能访问旧数据,还有可能发现数据不一致,无论这两个问题中的哪一个,都让读写锁有卷土重来的机会。
不过,令人吃惊的是,在大量情景中,数据不一致和旧数据都不是问题。网络路由表是一个经典例子。因为路由的更新可能要花相当长一段时间才能到达指定系统(几秒甚至几分钟),所以系统可能会在新数据到来后的一段时间内,仍然将报文发到错误的地址去。通常,在几毫秒内将报文发送到错误地址并不算什么问题。
简单地说,读写锁和RCU提供了不同的保证。在读写锁中,任何在写者之后开始的读者都“保证”能看到新值。与之相反,在RCU中,在更新者完成后才开始的读者都“保证”能看见新值,在更新者开始后才完成的读者有可能看见新值,也有可能看见旧值,这取决于具体的时机。
在实时RCU、SRCU或QRCU中,被抢占的读者将阻止正在进行中的优雅周期的完成,即使有高优先级的任务在等待优雅周期完成时也是如此。实时RCU可以通过用call_rcu()替换synchronize_rcu()来避免此问题,或者采用RCU优先级提升来避免。
除了那些“玩具”RCU实现,RCU优雅周期可能会延续好几个毫秒。这使得RCU更适于使用在读数据占多数的情景。
将读写锁转换成RCU非常简单,如下:



1.2 RCU是一种受限制的引用计数机制
因为优雅周期不能在RCU读端临界区进行时结束,所以RCU读端原语可以像受限的引用计数机制一样使用。比如考虑下面的代码片段:
1 rcu_read_lock(); /* acquire reference. */
2 p = rcu_dereference(head);
3 /* do something with p. */
4 rcu_read_unlock(); /* release reference. */
rcu_read_lock()原语可以看作是获取对p的引用,因为相应的优雅周期无法在配对的rcu_read_unlock()之前结束。这种引用计数机制是受限制的,因为我们不允许在RCU读端临界区中阻塞,也不允许将一个任务的RCU读端临界区传递给另一个任务。
不管上述的限制,下列代码可以安全地删除p:
1 spin_lock(&mylock);
2 p = head;
3 rcu_assign_pointer(head, NULL);
4 spin_unlock(&mylock);
5 /* Wait for all references to be released. */
6 synchronize_rcu();
7 kfree(p);
当然,RCU也可以与传统的引用计数结合。但是为什么不直接使用引用计数?部分原因是性能,如下图所示,图中显示了在16个3GHz CPU的Intel x86系统中采集的数据。
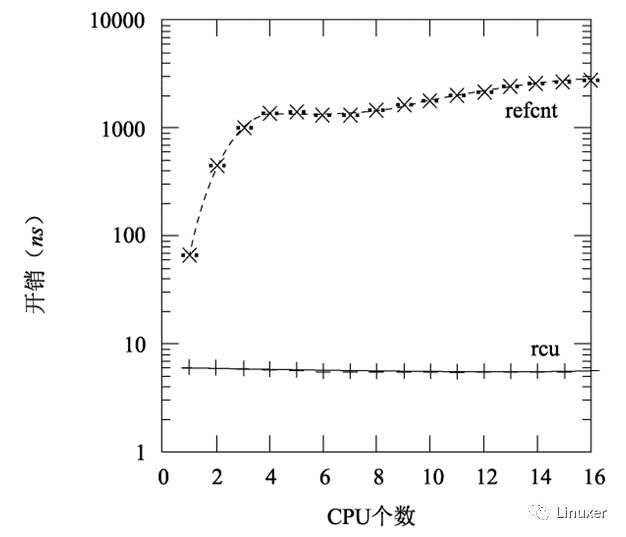
和读写锁一样,RCU的性能优势主要来源于较短的临界区,如下图所示。
1.3 RCU是一种可大规模使用的引用计数机制
如前所述,传统的引用计数通常与某种或者一组数据结构有联系。然而,维护一组数据结构的全局引用计数,通常会导致包含引用计数的缓存行来回“乒乓”。这种缓存行“乒乓”会严重影响系统性能。
相反,RCU的轻量级读端原语允许读端极其频繁地调用,却只带来微不足道的性能影响,这使得RCU可以作为一种几乎没有性能损失的“批量引用计数机制”。当某个任务需要在一大段代码中持有引用时,可以使用可睡眠RCU(SRCU)。但是,一个任务不能将引用锁引用传递给另一个任务。例如:在开始一次I/O时获取引用,然后当对应的I/O完成时在中断处理函数里释放该引用。
1.4 RCU是穷人版的垃圾回收器
当人们刚开始学习RCU时,有种比较少见的感叹是“RCU有点像垃圾回收器!”。这种感叹有一部分是对的,不过还是会给学习造成误导。
也许思考RCU与垃圾自动回收器(GC)之间关系的最好办法是,RCU类似自动决定回收时机的GC,但是RCU与GC有几点不同:(1)程序员必须手动指示何时可以回收指定数据结构,(2)程序员必须手动标出可以合法持有引用的RCU读端临界区。
尽管存在这些差异,两者的相似程度仍然相当高,至少有一篇理论分析RCU的文献曾经分析过两者的相似度。
1.5 RCU是一种提供存在担保的方法
通过锁来提供存在担保有其不利之处。与锁类似,如果任何受RCU保护的数据元素在RCU读端临界区中被访问,那么数据元素在RCU读端临界区持续期间保证存在。
1 int delete(int key)
2 {
3 struct element *p;
4 int b;
5 5
6 b = hashfunction(key);
7 rcu_read_lock();
8 p = rcu_dereference(hashtable[b]);
9 if (p == NULL || p->key != key) {
10 rcu_read_unlock();
11 return 0;
12 }
13 spin_lock(&p->lock);
14 if (hashtable[b] == p && p->key == key) {
15 rcu_read_unlock();
16 hashtable[b] = NULL;
17 spin_unlock(&p->lock);
18 synchronize_rcu();
19 kfree(p);
20 return 1;
21 }
22 spin_unlock(&p->lock);
23 rcu_read_unlock();
24 return 0;
25 }
上图展示了基于RCU的存在担保如何通过从哈希表删除元素的函数来实现每数据元素锁。第6行计算哈希函数,第7行进入RCU读端临界区。如果第9行发现哈希表对应的哈希项(bucket)为空,或者数据元素不是我们想要删除的那个,那么第10行退出RCU读端临界区,第11行返回错误。
如果第9行判断为false,第13行获取更新端的自旋锁,然后第14行检查元素是否还是我们想要的。如果是,第15行退出RCU读端临界区,第16行从哈希表中删除找到的元素,第17行释放锁,第18行等待所有之前已经存在的RCU读端临界区退出,第19行释放刚被删除的元素,最后第20行返回成功。如果14行的判断发现元素不再是我们想要的,那么第22行释放锁,第23行退出RCU读端临界区,第24行返回错误以删除该关键字。
1.6 RCU是一种提供类型安全内存的方法
很多无锁算法并不需要数据元素在被RCU读端临界区引用时保持完全一致,只要数据元素的类型不变就可以了。换句话说,只要数据结构类型不变,无锁算法可以允许某个数据元素在被其他对象引用时被释放并重新分配,但是决不允许类型上的改变。这种“保证”,在学术文献中被称为“类型安全的内存”,它比前一节提到的存在担保要弱一些,因此处理起来也要困难一些。类型安全的内存算法在Linux内核中的应用是slab缓存,被SLAB_DESTROY_BY_RCU标记专门标出来的缓存通过RCU将已释放的slab返回给系统内存。在任何已有的RCU读端临界区持续期间,使用RCU可以保证所有带有SLAB_DESTROY_BY_RCU标记且正在使用的slab元素仍然在该slab中,类型保持一致。
虽然基于类型安全的无锁算法在特定情景下非常有效,但是最好还是尽量使用存在担保。毕竟简单总是更好的。
1.7 RCU是一种等待事物结束的方式
RCU的一个强大之处,就是允许你在等待上千个不同事物结束的同时,又不用显式地去跟踪其中每一个事物,因此也就无需担心性能下降、扩展限制、复杂的死锁场景、内存泄露等显式跟踪机制本身的问题。
下面展示如何实现与不可屏蔽中断(NMI)处理函数的交互,如果用锁来实现,这将极其困难。步骤如下:
1.做出改变,比如,OS对一个NMI做出反应。在NMI中使用RCU读端原语。
2.等待所有已有的读端临界区完全退出(比如使用synchronize_sched()原语)。
3.扫尾工作,比如,返回表明改变成功完成的状态。
下面是一个Linux内核中的例子。在这个例子中,timer_stop()函数使用synchronize_sched()确保在释放相关资源之前,所有正在处理的NMI处理函数已经完成。
1 struct profile_buffer {
2 long size;
3 atomic_t entry[0];
4 };
5 static struct profile_buffer *buf = NULL;
6
7 void nmi_profile(unsigned long pcvalue)
8 {
9 struct profile_buffer *p =
rcu_dereference(buf);
10
11 if (p == NULL)
12 return;
13 if (pcvalue >= p->size)
14 return;
15 atomic_inc(&p->entry[pcvalue]);
16 }
17
18 void nmi_stop(void)
19 {
20 struct profile_buffer *p = buf;
21
22 if (p == NULL)
23 return;
24 rcu_assign_pointer(buf, NULL);
25 synchronize_sched();
26 kfree(p);
27 }
第1到4行定义了profile_buffer结构,包含一个大小和一个变长数组的入口。第5行定义了指向profile_buffer的指针,这里假设别处对该指针进行了初始化,指向内存的动态分配区。
第7至16行定义了nmi_profile()函数,供NMI中断处理函数调用。该函数不会被抢占,也不会被普通的中断处理函数打断,但是,该函数还是会受高速缓存未命中、ECC错误以及被同一个核的其他硬件线程抢占时钟周期等因素影响。第9行使用rcu_dereference()原语来获取指向profile_buffer的本地指针,这样做是为了确保在DECAlpha上的内存顺序执行,如果当前没有分配profile_buffer,第11行和12行退出,如果参数pcvalue超出范围,第13和14行退出。否则,第15行增加以参数pcvalue为下标的profile_buffer项的值。请注意,profile_buffer结构中的size保证了pcvalue不会超出缓冲区的范围,即使突然将较大的缓冲区替换成了较小的缓冲区也是如此。
第18至27行定义了nmi_stop()函数,由调用者负责互斥访问(比如持有正确的锁)。第20行获取profile_buffer的指针,如果缓冲区为空,第22和23行退出。否则,第24行将profile_buffer的指针置NULL(使用rcu_assign_pointer()原语在弱顺序的机器中保证内存顺序访问),第25行等待RCU Sched的优雅周期结束,尤其是等待所有不可抢占的代码——包括NMI中断处理函数——结束。一旦执行到第26行,我们就可以保证所有获取到指向旧缓冲区指针的nmi_profile()实例都已经返回了。现在可以安全释放缓冲区,这时使用kfree()原语。
简而言之,RCU让profile_buffer动态切换变得更简单,你可以试试原子操作,也可以用锁来折磨下自己。注意考虑到如下一点:在大多数CPU架构中,原子操作和锁都可能存在循环语句,在循环的过程中可能会被NMI中断。
二、RCU API
2.1 等待完成的API族
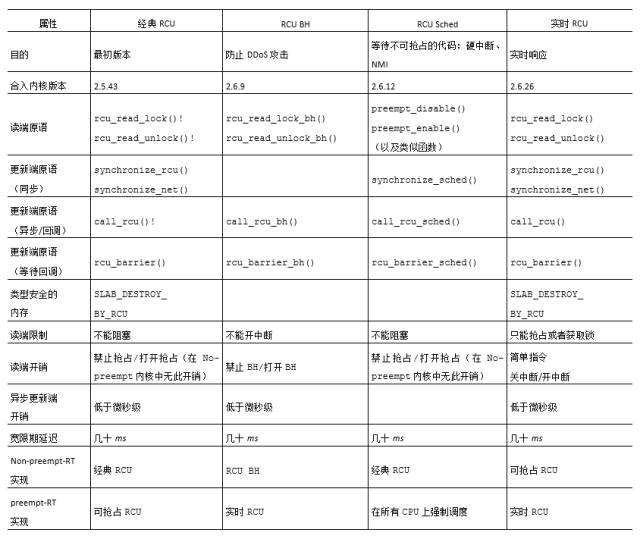
“RCU Classic”一列对应的是RCU的原始实现,rcu_read_lock()和rcu_read_unlock()原语标示出RCU读端临界区,可以嵌套使用。对应的同步的更新端原语synchronize_rcu()和synchronize_net()都是等待当前正在执行的RCU读端临界区退出。等待时间被称为“优雅周期”。异步的更新端原语call_rcu()在后续的优雅周期结束后调用由参数指定的函数。比如,call_rcu(p, f);在优雅周期结束后执行RCU回调f(p)。
想要利用基于RCU的类型安全的内存,要将SLAB_DESTROY_BY_RCU传递给kmem_cache_create()。有一点很重要,SLAB_DESTROY_BY_RCU不会阻止kmem_cache_alloc()立即重新分配刚被kmem_cache_free()释放的内存!事实上,由rcu_dereference返回的受SLAB_DESTROY_ BY_RCU标记保护的数据结构可能会释放——重新分配任意次,甚至在rcu_read_lock()保护下也是如此。但是,SLAB_DESTROY_BY_RCU可以阻止kmem_cache_free()在RCU优雅周期结束之前,它所返回数据结构的完全释放给SLAB。一句话,虽然数据元素可能被释放——重新分配N次,但是它的类型是保持不变的。
2.2 订阅和版本维护API
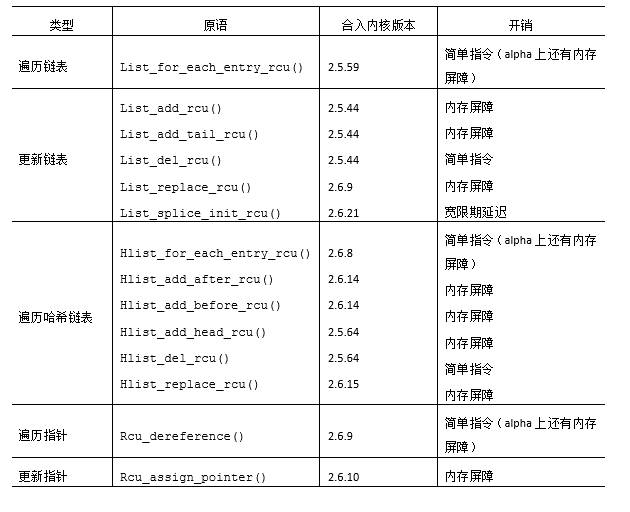
表中的第一类API作用于Linux的struct list_head循环双链表。list_for_each_ entry_rcu()原语以类型安全的方式遍历受RCU保护的链表。在非Alpha的平台上,该原语相较于list_for_each_entry()原语不产生或者只带来极低的性能惩罚。list_add_rcu()、list_add_tail_rcu()和list_replace_rcu()原语都是对非RCU版本的模拟,但是在弱顺序的机器上回带来额外的内存屏障开销。list_del_rcu()原语同样是非RCU版本的模拟,但是奇怪的是它要比非RCU版本快一点,这是由于list_del_rcu()只毒化prev指针,而list_del()会同时毒化prev和next指针。最后,list_splice_init_rcu()原语和它的非RCU版本类似,但是会带来一个完整的优雅周期的延迟。
表中的第二类API直接作用于Linux的struct hlist_head线性哈希表。struct hlist_head比structlist_head高级一点的地方是前者只需要一个单指针的链表头部,这在大型哈希表中将节省大量内存。表中的struct hlist_head原语与非RCU版本的关系同struct list_head原语的类似关系一样。
表中的最后一类API直接作用于指针,这对创建受RCU保护的非链表数据元素非常有用,比如受RCU保护的数组和树。rcu_assign_pointer()原语确保在弱序机器上,任何在给指针赋值之前进行的初始化都将按照顺序执行。同样,rcu_dereferece()原语确保后续指针解引用的代码可以在Alpha CPU上看见对应的rcu_assign_pointer()之前进行的初始化的结果。
-
内核
+关注
关注
4文章
1436浏览量
42480 -
Linux
+关注
关注
88文章
11627浏览量
217888 -
代码
+关注
关注
30文章
4940浏览量
73115 -
rcu
+关注
关注
0文章
21浏览量
5711
原文标题:谢宝友:深入理解RCU之四:用法
文章出处:【微信号:LinuxDev,微信公众号:Linux阅码场】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
谢宝友教你学Linux:深入理解Linux RCU之从硬件说起
深入理解Linux RCU:经典RCU实现概要
基于Linux内核源码的RCU实现方案
Linux内核RCU锁的原理与使用
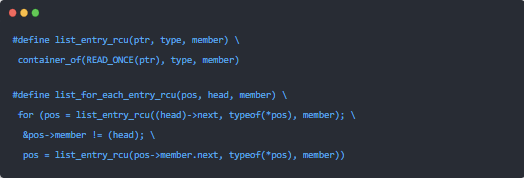
Linux内核配置系统详解
linux内核rcu机制详解
你知道Linux内核调试关键技术之一的printk?
可以了解并学习Linux 内核的同步机制
了解了解Linux内核中的RCU机制
Linux2.6.23 :sleepable RCU的实现
干货:Linux内核中等待队列的四个用法
linux内核中的driver_register介绍





 工商网监
工商网监
评论