 Blaze: 用Rust重写Spark执行层,平均提升30%算力
Blaze: 用Rust重写Spark执行层,平均提升30%算力

大家好,我是Tim。
前一段时间,快手数据架构团队开源了Blaze项目,它是一个利用本机矢量化执行来加速SparkSQL查询处理的插件。
用通俗的话讲就是通过使用Rust重写Spark物理执行层来达到性能提升的目的。
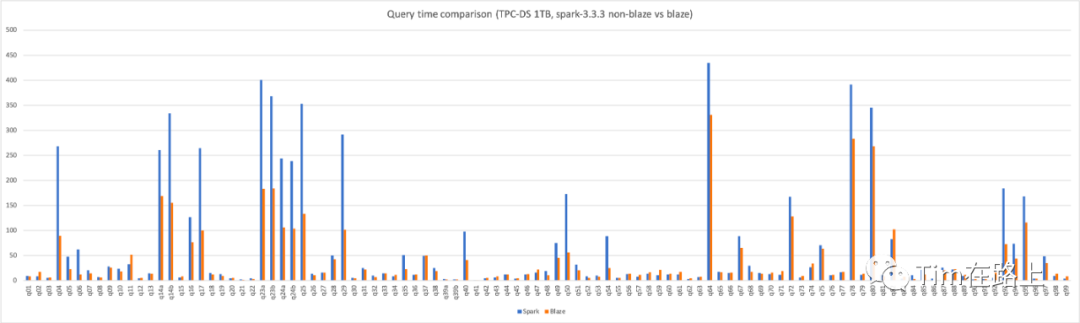
并且在TPC-DS 1TB的所有测试中,Blaze相比Spark3.3减少了40%的计算时间,降低了近一半的集群资源开销。
此外,在快手内部上线的数仓生产作业也观测到了平均30%的算力提升,实现了较大的降本增效。
今天我们就来聊一聊这个Blaze,以及近来重写Spark执行层进行提效的诸多项目。
Spark填补了一个空白
在大数据建设的初期,单台机器的 RAM 是有限且昂贵的,所以在进行集群规模计算时唯一可行选择是基于 MapReduce 的 Hadoop,它可以在诸多廉价的普通主机上进行集群计算。
众所周知,MapReduce 对磁盘 IO 的负担非常重,而且并没有真正发挥所有 RAM 的价值。
随着机器硬件的发展,RAM的价格也大幅降低,这时Spark提出了弹性分布式数据集(RDD),这是一种分布式内存抽象,可以让程序员以容错的方式在大型集群上执行内存计算。
Spark 完美地填补了这个空白。突然间,许多大数据处理都可以非常高效地完成。
为什么要重写Spark执行层?
而随着硬件技术的继续发展,Spark也需要进行相应的优化,来充分的发挥出底层硬件提供的能力。
以查询计划执行为例。原有的Spark引擎执行一个查询计划,往往采用火山模型的方式。
这种上层算子递归调用下层算子获取并处理元组的方式,存在虚函数调用次数较多、指令或数据cache miss率高的缺陷,并且这种一次处理一个元组的方式无法使用CPU的SIMD指令进行优化,从而造成查询执行效率低下的问题。
向量化执行就是解决上述问题的一种有效手段。
然而,我们都知道Spark是使用Scala写的,和JAVA类似是运行在JVM上的。
在Java中,与C++或Rust相比,没有直接的手动向量化特性,实现向量化都是由JVM自动控制的。
例如,JVM会对循环进行分析,判断是否有类似于向量化的优化机会。
如果JVM发现某个循环中其计算次数大于一定量级,且指令可以被SIMD指令集所支持,那么它会将循环展开为并行操作,从而实现向量化执行。
publicstaticvoidvectorAdd(float[]a,float[]b,float[]result){
for(inti=0;i< 200;i++){
result[i]=a[i]+b[i];
}
}
如上面的代码所示,其有可能会被JVM转换为向量化执行。
即使循环符合向量化的条件,JVM也不能保证一定会自动实现向量化执行。在某些情况下,JVM可能会选择跳过向量化执行。
所以,到目前为止,Spark中的性能杀手Shuffle等操作依然采用了行式数据处理。
不过对于读写列式文件的算子,如Parquet、Orc等,已经实现了向量化的批量操作。
除此以外,Scala、Java实现的Spark还会带来垃圾收集(GC)开销,这也是JAVA系语言的通病。
如果垃圾回收的时间太长,会严重影响任务执行的稳定性,甚至会被误识别为节点失联。
最后,Java还存在较高的内存消耗和无法进行低级别的系统优化等问题,这都迫使人们一直在尝试重写Spark执行层算子。
一直没有开源的Photon
其实对于重写Spark执行层算子,Spark的母公司Databricks早已进行了尝试,并已经为其付费用户提供了向量化的执行引擎Photon。
Photon已经被应用多年,其被定位为适用于 Lakehouse 环境的矢量化查询引擎。在Databricks的内部数据上,Photon 已将一些客户工作负载加速了 10 倍以上。
业界也一直有向量化执行引擎出现,例如velox、gluten(gluten可以支持velox或ck作为后端)。
velox就是一个单机/单节点的c++的向量化query runtime实现。
当然velox目标不只是Spark, 它希望统一替换大数据计算引擎的单节点runtime,包括Spark、Presto、Pytorch,以取得加速效果。
其对接Spark就是通过gluten项目进行对接的,velox目前也已基本在Meta公司内部落地。
但其开源社区一直不温不火,甚至凉凉。
Blaze 借助Arrow DataFusion实现向量化执行引擎
Blaze的实现原理和Velox、Photon都是大同小异。
即在运行时尝试使用向量化算子计算,如果不支持则回退回Spark原来的计算算子。
不过需要注意的是,Blaze是将Spark运行时物理运算符转换为 Rust DataFusion的向量化实现。
关于DataFusion是什么,可以参考这篇文章:Apache Arrow DataFusion到底是什么?
目前Blaze可能还不支持聚合运算符,UDF 或 RDD API,这显然会影响 TPC-DS 查询的整体运行时间。不过,在快手内部据传Blaze中已经添加了对聚合运算符的支持。
在开源的Blaze已支持Spark3.0和Spark3.3版本,其使用方式和gluten类似,通过在Spark环境中添加相应的Jar包实现功能扩展。
目前从其跑的TPC-DS 查询性能测试上可以看出,Blaze平均提升30%的性能,节约了40%的集群资源。
然而其问题也和Velox一样。
一方面需要在Spark集群环境中安装特定版本的Rust/C++,而且Rust/C++在庞大的集群机器中可能会存在各种环境问题。
另一方面,其不支持UDF(当然Photon也不支持),在真实的计算任务中可能会存在各种兼容性问题,而导致需要回退到原始的Spark执行引擎上,可能会造成原始任务的性能倒退。
说白了,即不可能全局开启Blaze性能优化,目前也只能针对特定任务特点用户进行开启优化。
Blaze引擎优化定位只是针对Spark引擎,而且在向量化的实现上又是基于DataFusion开源项目,相比Velox引擎其未来开源的路可能会比较好走一点,毕竟目标没那么大嘛。
当然Blaze的出现还有一个作用,也许会迫使Databricks开源他们藏掖已久的Photon,这当然是一件好事。
就像当年Iceberg迫使Databricks开源其收费的数据湖存储引擎Delta Lake一样。
总结
Spark执行算子的向量化是未来必须要走的路,Blaze项目通过将Spark物理执行层算子转换为Rust Arrow DataFusion向量化算子来提升性能,目前已在快手内部部分业务上线,并实现30%的性能提升。
在快手内部的成功,并不一定可以在开源社区获得成功。
一方面,Spark社区并不会允许其并入Spark项目来获得更大关注,另一方面这种优化实现方式在真实重要的业务场景,必然存在很多自定义的函数或算子,这给其在其他公司数据团队上的落地造成了困难。
这可能需要数据团队具有不破不立的精神,否则其并不能带来全平台的性能收益,而这显然会使得使用Blaze项目所需的成本项异常显眼。
最后,希望Blaze项目可以成功,至少可以迫使Databricks开源其Photon,也希望更多native引擎开源来提升Spark任务执行性能。
-
磁盘
+关注
关注
1文章
394浏览量
26293 -
SPARK
+关注
关注
1文章
108浏览量
21113 -
Rust
+关注
关注
1文章
240浏览量
7481
原文标题:Blaze: 用Rust重写Spark执行层,平均提升30%算力
文章出处:【微信号:Rust语言中文社区,微信公众号:Rust语言中文社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
“算力”的分层定义-初级算力
华为发布AI容器技术Flex:ai,算力平均利用率提升30%



rx580算力,rx580显卡算力,rx588算力,rx588显卡算力 精选资料分享
Cloudflare用Rust重写Nginx C模块,构建没有Nginx的未来
Rust重写的LSP:KCL IDE 插件的功能介绍与设计解析
Windows 11初尝Rust,36000行内核代码已重写!
存算一体+Chiplet能否应对AI大算力和高能耗的挑战?
算力网络的概念及整体架构

一次Rust重写基础软件的实践
从CPU、GPU到NPU,美格智能持续优化异构算力计算效能






 工商网监
工商网监
评论