 高效打包边缘人工智能神经网络模型
高效打包边缘人工智能神经网络模型

在嵌入式设计中常常需要将应用程序打包到有限的片上内存中,现在,将人工智能神经网络模型压缩到有限的存储器中也是如此。对于传统软件,就某些方面而言,做到这一点可谓更具挑战,因为基于神经网络的系统中的工作内存都是“内部循环”的,要求换出到DDR内存,可能会降低性能。另外,在推理过程中重复访问DDR也会增加边缘设备的典型低功耗预算,这一点也同样很难令人满意。更大的片上存储器是解决问题方法之一,但是会增加产品成本。综上所述,最佳解决方案是尽可能高效地将模型打包到可用内存中。
众所周知,在编译人工智能神经网络模型以便在边缘设备上运行时,有一些量化技术可以缩小此模型的大小,如将浮点数据和权重值转换为定点,然后进一步缩小为INT8或更小的值。想象一下,如果还能更进一步会怎样。在本文中,我将介绍几种图优化技术,助您在2MB的二级缓存中安装更多量化模型,但仅仅量化是无法完成安装的。
优化人工智能神经网络图中的缓冲区分配
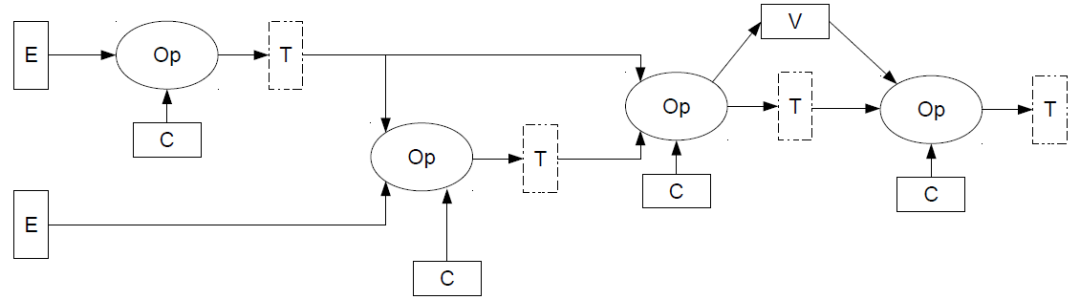
▲图1.一个简单的人工智能图
(Op代表运算符;E代表外部输入;
C代表常数(权重);V代表变量;T代表张量)
人工智能神经网络模型表示为图形并作为图形来管理,其中的运算是通过缓冲区相互连接的节点进行的。这些缓冲区固定分配在内存中,大小在编译图时确定,用于保存图中的中间计算结果或输入和输出。在所有图中,流水关系图是最基本的一种,但更典型的简单图如图1所示。
我们的目标是让编译器优化缓冲区内存总需求。想想简单的人工智能神经网络图中可能的分配序列(图2中的左图)。首先要明白,图中的不同运算需要不同大小的缓冲区,并且在进行下一波处理之前,将不再需要已完成运算的输入缓冲区。读取缓冲区A(此处分配有800K字节),就可以在后续运算中重复使用了,缓冲区B也是如此,依此类推。在左图出现分支时,先将缓冲区A和B分配给了右侧分支,之后则必须为左侧分支分配一个新的缓冲区C。
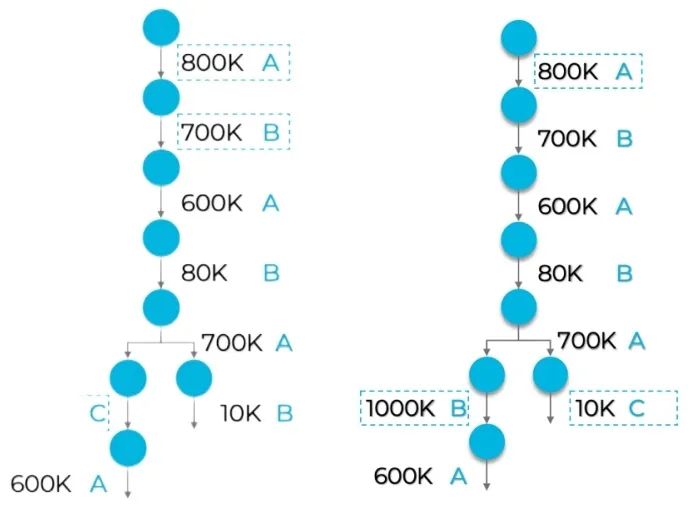
▲图2.说明缓冲区分配的简单图
(右图在左图的基础上,将缓冲区B和C互换
并增加了缓冲区B的大小,得到了改善)
从这个例子中不难看出,一开始就将缓冲区B的大小增加到1000K,稍后再在左侧分支中重复使用B的全部大小,右侧分支中缓冲区C就只需要额外10K内存,如右图所示。左/右内存需求差异明显。左图需要2.5MB (800K+700K+1000K),而修改顺序后的右图只需要 1.81MB(800K+1000K+10K)。
在一般人工智能神经网络图中找出最优排序就是众所周知的0-1背包问题。我们展开了初步测试,研究这种优化如何改善打包到固定大小L2缓存的效果。即使是当下初步阶段,结果也相当不错。我们测试了几种常见网络在2MB和4MB L2缓存中的安装效果。优化前,只有13%的模型可以安装在2MB内存中,38%的模型可以安装在4MB内存中。优化后,66%的模型可以安装在2MB内存中,83%的模型可以安装在4MB内存中。仅这一项优化就值得我们努力,我们的目标是确保更多模型可以完全在片上内存中运行。
通过合并缓冲区优化人工智能神经网络模型
在卷积人工智能神经网络模型中,经过前几层处理后,缓冲区大小通常会缩小。这种结果表明,一开始分配的大缓冲区可以通过与稍后需要的较小缓冲区共享空间得到更高效的利用。图3说明了这种可能性。
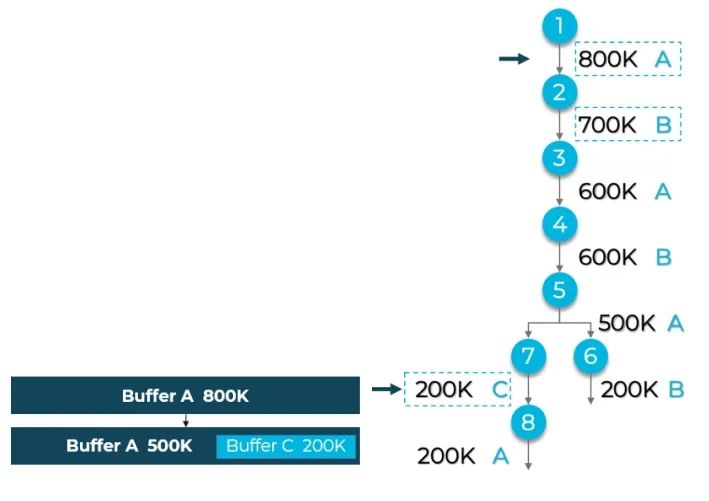
▲图3.不同的简单图
(最初为缓冲区A分配的大小可以稍后由左右分支共享,
此处的C缓冲区源自最初的A缓冲区)
我们试着进行优化,看看这种合并对内存总需求有何影响。在一系列无比熟悉的网络中,我们发现缓冲区总大小减小了15%到35%。再次重申一遍,这些改进非常具有吸引力。
✦
要点
✦
我们通过这些优化,运行各种主流卷积人工智能神经网络模型,从检测到分类到细分,再到RNN模型不一而足。大多数情况下,模型完全迁移至了4MB二级缓存,某些情况下,模型迁移至了二级缓存中,只有一部分还留在DDR内存中。几乎所有模型都在打包方面呈现出巨大改进。
即使你的人工智能神经网络模型无法安装在片上内存,也并非无法优化。在人工智能编译器阶段可以对缓冲区进行优化,大幅压缩模型总大小。在CEVA,我们很乐意与你讨论以上问题和其他想法,以便进一步优化人工智能神经网络模型的内存使用。
识别右侧二维码
立即了解CEVA
更多信息

本文作者:Rami Drucker, Machine Learning SW Architect, CEVA
-
CEVA
+关注
关注
1文章
201浏览量
77346
原文标题:高效打包边缘人工智能神经网络模型
文章出处:【微信号:CEVA-IP,微信公众号:CEVA】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
TDK推出SensorGPT以加速边缘人工智能开发

人工智能多模态与视觉大模型开发实战 - 2026必会
NMSIS神经网络库使用介绍
在Ubuntu20.04系统中训练神经网络模型的一些经验
人工智能工程师高频面试题汇总:循环神经网络篇(题目+答案)
神经网络的并行计算与加速技术

利用超微型 Neuton ML 模型解锁 SoC 边缘人工智能
AI 边缘计算网关:开启智能新时代的钥匙—龙兴物联
超小型Neuton机器学习模型, 在任何系统级芯片(SoC)上解锁边缘人工智能应用.
最新人工智能硬件培训AI 基础入门学习课程参考2025版(大模型篇)
Nordic 收购 Neuton.AI # Neuton ML 模型解锁 SoC 边缘人工智能



评论