 跨语言提示:改进跨语言零样本思维推理
跨语言提示:改进跨语言零样本思维推理
论文名称:Cross-lingual Prompting: Improving Zero-shot Chain-of-Thought Reasoning across Languages
论文作者:覃立波,陈麒光,车万翔等
原创作者:陈麒光
论文链接:https://arxiv.org/abs/2310.14799
出处:哈工大SCIR
最后一个名额:带你冲刺ACL2024
0. Take-away messages
•本文引入了简单有效的Cross-Lingual Prompting (CLP),其中包含cross-lingual alignment prompting (CAP) 和 task-specific solver prompting (TSP),它们能够帮助思维链(CoT)范式在不同语言间进行有效地对齐,共同改进了跨语言的零样本 CoT 推理。
•进一步地,提出了Cross-Lingual Self-consistent Prompting (CLSP),利用不同语言专家的知识和不同语言间更加多样的思考方式,集成了多个推理路径,显著地提高了self-consistency的跨语言性能。CLSP 都能够在CLP的基础上更进一步地有效提高零样本跨语言 CoT 性能。
•对多个基准的广泛评估表明,CLP 在各类任务上甚至取得了比机器翻译用户请求更加优异的性能(在各个多语言数据集上平均准确率至少提高了1.8%)。在此基础上,CLSP能够进一步地提高CLP的性能,在多个基准上都取得了超过6%的提升。
1. 背景与动机
1.1 背景
LLM能够在训练和测试过程中无需修改模型参数,实现零样本推理,受到越来越多的关注。具体来说,零样本思维链 (CoT) 只需要附加提示 Let's think step by step! ,就可以从大型语言模型中诱导强大的推理能力,并在各种任务上展示出惊人的性能,包括算术推理、常识推理甚至具身规划。

图 1:传统单语言CoT示例 以传统CoT为例,提供提示 Let's think step by step! 针对英文请求以进行分步推理。最终,LLM通过多步推理给出了相应的答案68 years。
1.2 动机
全世界有200多个国家和7000多种语言。随着全球化的加速,迫切需要将当前的CoT推广到不同的语言中。尽管零样本CoT取得了显著的成功,但其推理能力仍然难以推广到不同的语言。

图 2:跨语言CoT示例 与请求的语言和 CoT 输出相同的传统 CoT 场景不同,跨语言 CoT 要求 LLM 通过提供触发语句Let's think in English step by step!。 当前零样本跨语言推理仍处于一个非常早期的阶段,没有考虑跨语言间的显式对齐。为了更好地将CoT零样本地泛化到不同语言上,我们提出了cross-lingual-prompting (CLP),旨在有效地弥合不同语言之间的差距。具体来说,CLP 由两个部分组成:(1) cross-lingual alignment prompting (CAP) 和(2) task-specific solver prompting (TSP)。在第一步中,CLP首先要求模型逐步地理解英语任务,对齐了不同语言之间的表示。在第二步中,CLP要求模型根据上一步理解的内容逐步地完成最终的任务。此外,受self-consistency工作的启发,我们提出了Cross-Lingual Self-consistent Prompting (CLSP),使模型能够集成不同语言专家的不同推理路径。 总的来说,简单而有效的CLP和CLSP方法可以极大地增强跨语言场景的推理能力。
2. Prompting设计
2.1 CLP设计
为了激发LLM的跨语言推理能力,我们引入了跨语言提示(CLP)作为解决方案。具体来说,CLP 由两个部分组成:(1) cross-lingual alignment prompting (CAP) 和 (2) task-specific solver prompting (TSP)。

图 3:Cross-Lingual Prompting (CLP) 示意图
2.1.1 Cross-lingual Alignment Prompting (CAP)
跨语言对齐是跨语言迁移的核心挑战。因此,为了更好地捕获对齐信息,我们首先引入了cross-lingual alignment prompting。该prompt的表述如下:

图 4:跨语言对齐提示 (CAP) 示意图 具体来说,给定请求句子 X,我们首先要求 LLM 扮演 在多语言理解方面的专家,来理解跨语言问题。此外,对齐提示将从源语言 Ls 到目标语言 Lt 进行逐步地对齐。
2.1.2 Task-specific Solver Prompting (TSP)
实现跨语言对齐后,我们进一步提出task-specific solver prompting 以促进多语言环境中的多步推理。

图 5:Task-specific Solver Prompting (TSP) 示意图 具体来说,给定 目标语言 和从上一步获得的对齐文本 ,我们提示 LLM 参与解析目标任务。LLM尝试根据之前对齐的跨语言理解进行进一步的多步推理以确定最终结果。此外,我们提供了一个答案提取的指令来格式化模型的答案,其定义为:

图 6:答案提取指令示意图
2.2 CLSP设计
在我们的研究中,我们观察到LLM在不同语言中表现出不同的推理路径。受Self-consistency的启发,我们提出了一种Cross-lingual Self-consistent Prompting (CLSP) 来整合不同语言的推理知识(如图7所示)。
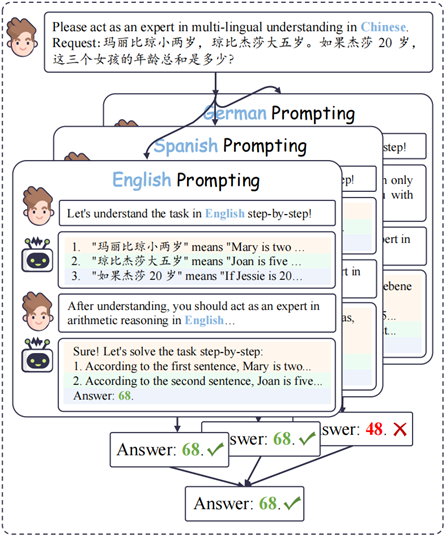
图 7:Cross-lingual Self-consistent Prompting (CLSP) 示意图 具体来说,对于推理过程中的每个步骤,我们要求LLM以不同的目标语言生成跨语言对齐的回复,并分别在各自目标语言上进行推理。我们通过投票机制保留在推断推理结果中表现出高度一致性的答案。然后将这些一致推断的答案视为最终结果。
3 主实验分析
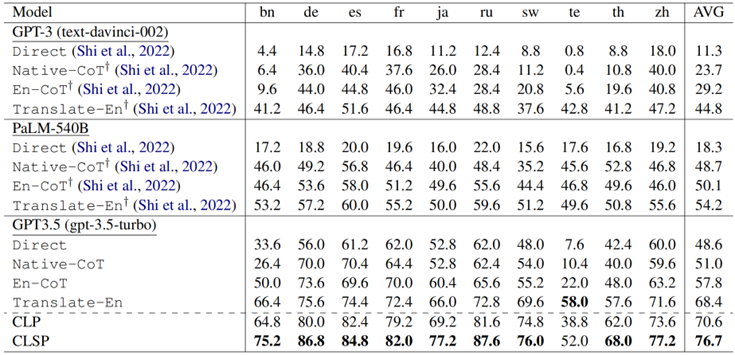
表 1:在MGSM基准上主实验的推理表现 从表1结果来看,我们有以下观察结果:
GPT-3.5 表现出显着的跨语言推理优势。在各种设置下,GPT-3.5 均大幅超越了 PaLM-540B 和 GPT-3 的少样本结果。具体来说,与少样本 PaLM-540B相比,零样本GPT-3.5实现了 30.3%、2.3%、7.7% 和 14.2%的改进。我们认为是多语言SFT 和 RLHF 技术带来了跨语言推理性能的显著提高。
CLP 实现了最先进的性能。CLP 超越了之前的所有基线,特别是优于少样本的PALM-540B(Translate-En),提高了 16.4%。这一改进不能仅仅归功于 GPT-3.5,因为CLP 的平均准确度甚至比拥有额外知识的高质量机器翻译(Translate-En) 高 2.2%。这些发现表明 CLP 超越了原始的文本翻译,提供了自己的理解,能够并进一步增强了模型固有的跨语言理解能力。
CLSP 进一步显著提高了性能。CLSP 在所有语言中都比 CLP 表现出显着的优越性(平均准确率提高了 6.1%)。这一观察结果表明,整合不同语言的知识和不同语言间的思考路径可以有效提高跨语言CoT的推理性能,验证了CLSP 的有效性。
4 CLP 分析
4.1 CLP能够拥有更好的推理质量
为了进一步研究CLP为何有效,我们采用Roscoe 框架来评估模型思想链中推理路径的质量。
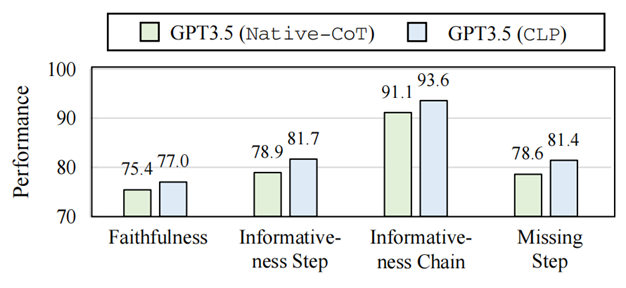
图 8:Native-CoT 和 CLP 的推理路径质量 如图8所示,我们发现CLP的推理路径表现出更高的忠实度,在推理过程中与关键步骤表现出更好的一致性。具体来说,CLP的推理路径优势可以总结为:
推理幻觉更少:CLP的推理路径的Faithfulness得分提高了 1.6%,表明模型更好地理解了问题陈述,并确保了清晰的推理链,而不会生成不相关或误用的信息,更加可信。
推理更有依据:此外,我们观察到“Step”和“Chain”的Informativeness指标分别提高了 2.8% 和 2.5%。它表明模型的推理在跨语言对齐之后可以提供更有根据的推理步骤。
逻辑链更完整:此外,CLP 在 Miss-step 指标中也增强了 2.8%,表明模型的推理可以包含完整的逻辑链,从而带来更好的性能。
4.2 二阶段交互式提示比单轮提示效果更好
由于之前CLP分为了两个阶段,本节将探讨两阶段交互式提示的有效性。
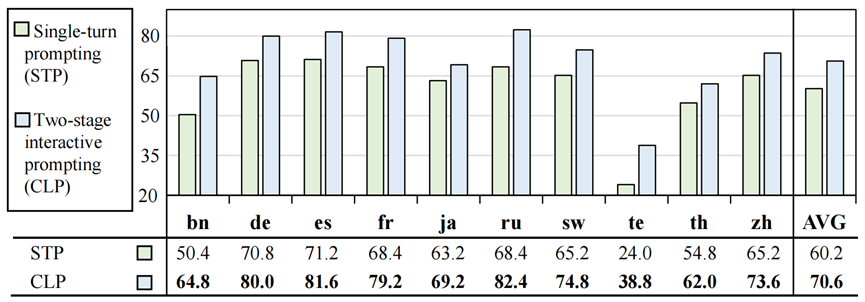
图 9:二阶段和单轮的CoT效果比较 与两阶段交互式提示(CLP)相比,我们观察到单轮提示性能平均显着下降 10.4%。我们认为两阶段的交互提示可以更好地引出LLM强大的对话交互能力,从而提高表现。
4.3 CLP 并不是简单的翻译
如表1 所示,我们可以发现CLP的平均准确率甚至比机器翻译请求高出2.2%,这表明CLP不是普通翻译,而是利用了语言之间的语义对齐。 为了进一步了解 CLP 为何比翻译效果更好,我们随机选择了 200 个来自不同语言的样本进行细粒度探索。首先,我们发现CLP会自动地采取7种不同的策略,大部分策略一定程度上都对最终的性能做出了贡献,这证明了CLP的有效性。
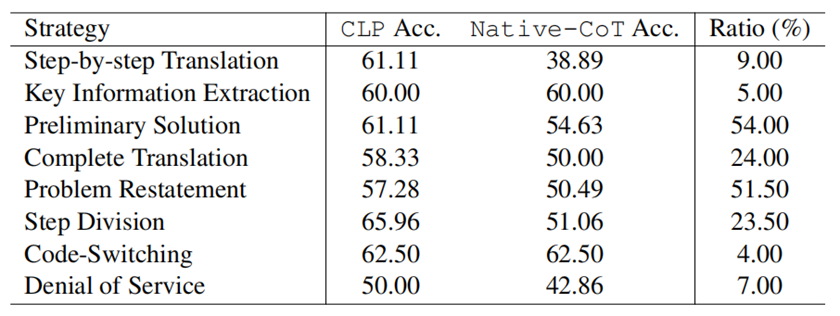
表 2:CLP自动使用的策略的占比以及性能影响 此外,我们发现进一步分解第一阶段有助于改进。将第 1 阶段的行动分解为 2-4 个策略可以显着提高性能(至少 6.45%)。例如,通过将对齐过程分解为“问题重述”和“解决初步解决”,就可以获得优异的性能,达到 64.71%(与 Native-CoT 相比提高了 11.77%)。
4.4 Prompt的选择如何影响CLP?
我们利用不同的表述的跨语言对齐提示以验证CLP零样本跨语言CoT的鲁棒性。表3说明了 4 种意思相同但表述不同的跨语言对齐提示的性能。
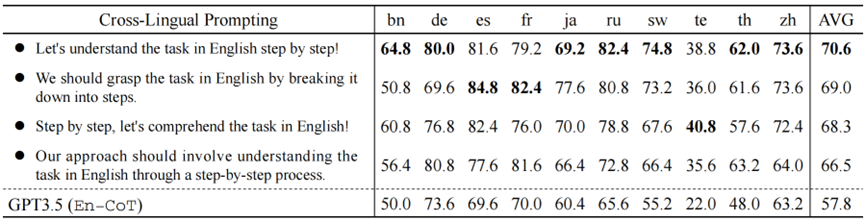
表 3:不同表述的CAP对CLP的影响分析 实验结果表明,虽然AVG Acc. 存在一定的波动(最大差异超过4%)。但所有跨语言对齐提示相比En-CoT仍然可以提高性能。这进一步验证了CLP的有效性。
4.5 CLP的泛化性分析
为了进一步研究我们工作的通用性,我们从两个方面验证CLP的泛化性:
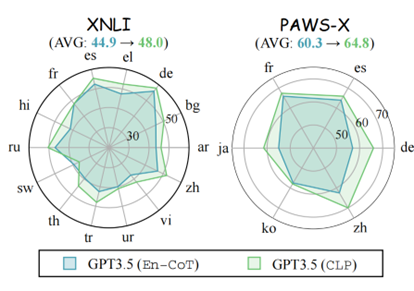
图 10:在其他多语言数据集上的准确率表现
CLP 在其他多语言基准上效果优异。我们在其他广泛使用的多语言推理数据集(即 XNLI 和 PAWS-X)上进行了实验。从表4中的结果来看,我们观察到 CLP 在大多数语言中都可以获得更好的性能。与En-CoT相比,我们观察到 XNLI 的平均改进为 3.1%,PAWS-X 的平均改进为 4.5%。
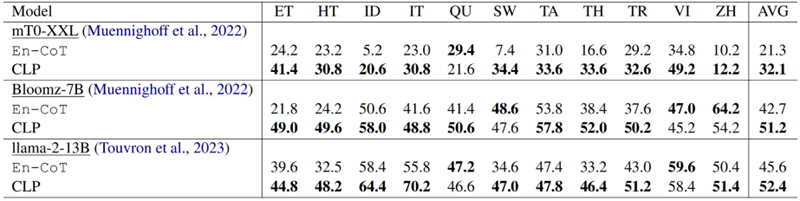
表 4:在其他开源/较小的LLM上的准确率表现
CLP 在其他 LLM 上表现优异。为了更好地理解模型泛化,我们在具有较小 LLM 的 XCOPA 上进行了实验。实验结果(如表X所示)表明,在较小的法学硕士上,CLP 与 En-CoT 相比至少实现了 6.8% 的改进。
4.6 CLP能够通过上下文学习策略进一步提升
近年来,上下文学习(ICL)取得了惊人的结果,为了进一步探索 CLP 在 ICL 框架内的效果,我们进行了一系列实验。对实证结果的后续分析得出以下观察结果(实验在1000条抽样结果上进行):

表 5:CLP各个阶段在ICL设置下的表现
在CAP中使用 ICL 可以显着提高推理性能。如表5所示,CLP 比 MGSM 上的零样本设置表现出显着的 6.9% 改进。这进一步强调了我们的方法作为即插即用模块的优势,与 ICL 方法正交,以提高性能。
在TSP中使用 ICL 可以进一步提高推理性能。如表5所示,结果显示,在 Task-specific Solver Prompting (TSP) 中结合 Complex-CoT时,性能额外提高了 1.1%。与其他 CoT 优化方法相比,这进一步巩固了我们的方法的独特性,强调了其适应性以及为下游 CoT 推理技术提供更广泛支持的能力。
CAP阶段的示例选择起着关键作用。我们对ICL策略的各种组合进行了实验。如表5所示,如果依赖单一策略,则模型的平均性能显着下降至63.5%,甚至远低于零样本的效果。相反,当在少样本示例中采用更多样化的策略时,模型的性能显示出显着的改进,达到 75.9%。它表明更多样化的策略样本可以带来更好的性能提升。

表 6:在示例中不同对齐策略数量对准确率的影响(策略按照表2中的占比从大到小选取)
5. CLSP Analysis
5.1 CLSP 超越了原始的Self-consistency
为了验证 CLSP 的有效性,我们对原始的Self-consistency(VSC)进行了实验。原始的Self-consistency 是指利用不同Temperature生成多条推理路径,并通过投票的方式确定最终的答案。如图11所示,与VSC相比,CLSP平均提高了大约 4.5%,验证了CLSP的有效性。
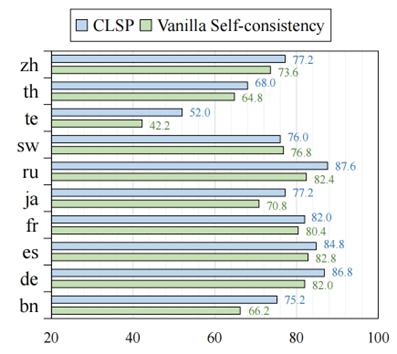
图 11:CLSP和VSC在MGSM上各个语言的准确率表现 此外,我们尝试探索 CLSP 为何有效。我们使用所有正确的预测结果和手动注释的 CoT 推理路径来评估跨语言 CoT 推理路径(包括 CLSP 和 VSC)之间的对齐分数。
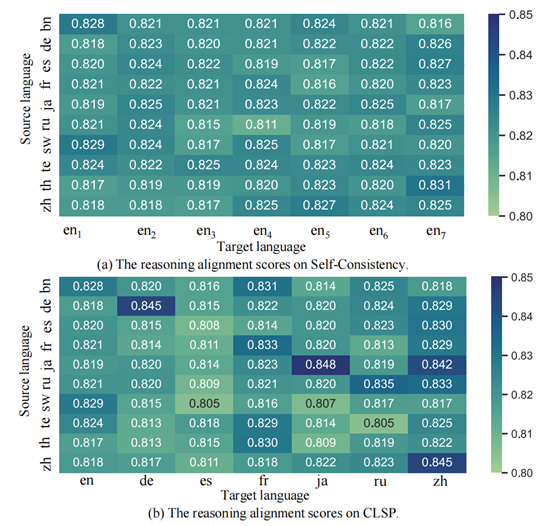
图 12:CLSP和VSC的不同的推理路径与标准推理路径的对齐分数 如图12所示,CLSP生成的对齐分数的方差明显高于VSC。它表明 CLSP 更好地集成了语言知识,从而提高了最终的跨语言 CoT 性能。
5.2 集成更多的语言并不能带来更多的提升
一个自然出现的问题是,“在CLSP中集成大量语言是否会带来更好的整体表现?”为了回答这个问题,我们探讨了CoT表现与集成的语言数量之间的关系。
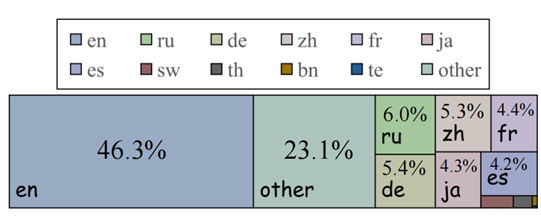
图 13:Common Crawl 2021数据集语言分布 一些研究表明LLM的表现与每种语言的预训练数据比例高度相关。因此,我们检查了广泛使用的多语言预训练数据集 Common Crawl 2021 中的语言分布(如图13所示)。
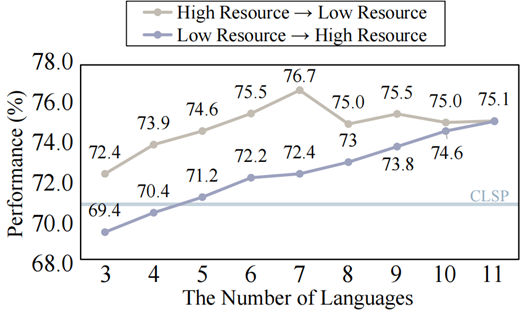
图 14:集成语言数量对最终性能的影响 根据比例,我们按照语言的降序和升序逐步整合每种语言。各自的比例。图14中的结果表明,在高资源设置中,随着添加更多语言,性能会提高。然而,当合并低资源语言时,性能会随着语言数量的增加而下降。 这些发现表明,语言整合的有效性不仅仅取决于整合的语言数量。每种语言的预训练数据量,尤其是高资源语言,起着至关重要的作用。考虑到可用资源和影响,平衡多种语言至关重要。
5.3 CLSP泛化性研究
为了进一步验证 CLSP 的有效性,我们在 XCOPA 数据集上进行了实验,这是一个广泛采用的基准,用于评估 11 种不同语言的常识推理技能。
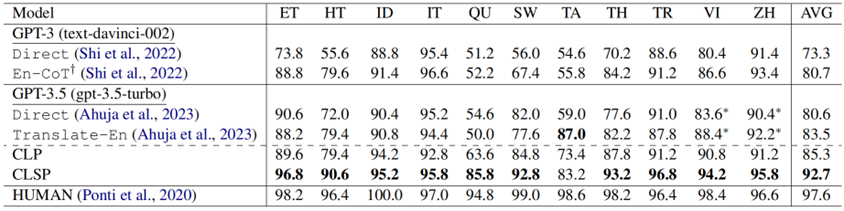
表 7:XCOPA上CLSP的表现 正如表7 中所示的结果所示,与基线相比,我们观察到 CLP 性能平均显着提高了 4.7%。此外,与 CLP 相比,CLSP 的性能进一步提高了 7.4%。这些结果表明,除了在数学推理方面表现出色之外,CLSP 在解决常识推理任务方面也表现出显着的有效性。
6. 结论
在这项工作中,我们引入了跨语言思维链的Cross-lingual Prompting (CLP)。具体来说,CLP 由 cross-lingual alignment prompting 和 task-specific solver prompting 组成,用于跨语言对齐表示并在跨语言设置中生成最终推理路径。
此外,我们提出了Cross-Lingual Self-consistent Prompting (CLSP)来有效利用跨语言的知识,这进一步提高了 CLP 的性能。
大量实验表明,CLP 和 CLSP 在跨语言 CoT 中都能取得良好的性能。
欢迎感兴趣的同学阅读我们的论文,对于cross-lingual alignment prompting中不同策略的思考,该问题对跨语言的相关研究是非常有价值的。
-
CLP
+关注
关注
0文章
5浏览量
7025 -
模型
+关注
关注
1文章
2704浏览量
47691 -
机器翻译
+关注
关注
0文章
138浏览量
14794
原文标题:6. 结论
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
前华为互连部技术老屌丝回忆之(四)----跨界思维
JAVA语言为什么能跨平台?
先进的创新教育:AI 思维+设计思维
c语言和汇编语言的区别 相关资料分享
什么是C语言。C语言入门 ?精选资料分享
单片机C语言和普通的C语言有什么区别
对跨平台的Qt调试作一个简单的介绍
解释型语言与编译型语言以及解释器与编译器之间的区别是什么
DevEco Studio新特性分享-跨语言调试,让调试更便捷高效
个体与群体思维状态下的AOP语言
基于改进PCFG的语言解释器模糊测试综述
一文速览大语言模型提示最新进展

小红书搜索团队研究新框架:负样本在大模型蒸馏中的重要性





 工商网监
工商网监
评论