 日志设计开发过程中的常见问题
日志设计开发过程中的常见问题

阿里妹导读
日志是系统中熵增最快的一个模块,它承载了业务野蛮生长过程中的所有副产品。本文介绍了一个日志治理案例,围绕降本和提效两大主题,取得一定成效,分享给所有渴望造物乐趣的同学。
前言
履约管理是一个面向物流商家的OMS工作台,自从初代目把架子搭起来之后,就没有继续投入了,后来一直是合作伙伴同学在负责日常维护和需求支撑。经过几年的野蛮生长,系统已经杂草丛生,乱象百出。再后来,甚至一度成为一块无主之地,走行业共建的方式来支持。对于一个不支持行业隔离的系统,行业共建意味这个系统将快速腐化。
两年前我开始接管履约管理,来到这片广阔的蛮荒之地,正如所有那些渴望造物乐趣并且手里刚好有锤子镰刀的人,我就像一匹脱缰的野马,脑子里经常会产生很多大胆且新奇的想法,希望借此把履约管理打造成一个完美的系统。只可惜真正能够付诸实践的少之又少,本篇就是为数不多得以落地,并且有相当实用价值idea中的一个,整理出来分享给有需要的同学做参考。
日志乱象
日志是日常开发中最有可能被忽视,最容易被滥用的一个模块。被忽视是因为打日志实在是一个再简单不过的事,前人设计好了一个logback.xml,后面只需要依样画葫芦定义一个logger,随手一个info调用就搞定,他甚至不确定这条日志能不能打出来,也不知道会打在哪个文件,反正先跑一次试试,不行就换error。被滥用是因为不同场景日志的格式内容千差万别,或者说日志打法太灵活,太随意了,风格太多样化了,以至于几乎每个人一言不合就要自己写一个LogUtil,我见过最夸张的,一个系统中用于打日志的工具类,有二三十个之多,后人纠结该用哪个工具可能就要做半个小时的思想斗争,完美诠释了什么叫破窗效应。
最好的学习方式就是通过反面教材吸取教训,下面我们列举一些最常见的日志设计开发过程中的问题。
分类之乱
一般来说,一个系统必然需要设计多个日志文件以区分不同业务或场景,不可能所有的日志都打到一个文件里。但是怎么进行分类,没人告诉我们,于是就有了各种各样的分类。
按系统模块分。这种分类应该是最基础的一种分类,也是最有层次感的分类。比如履约服务中枢的系统分层。基本上每一层对应一个日志文件。 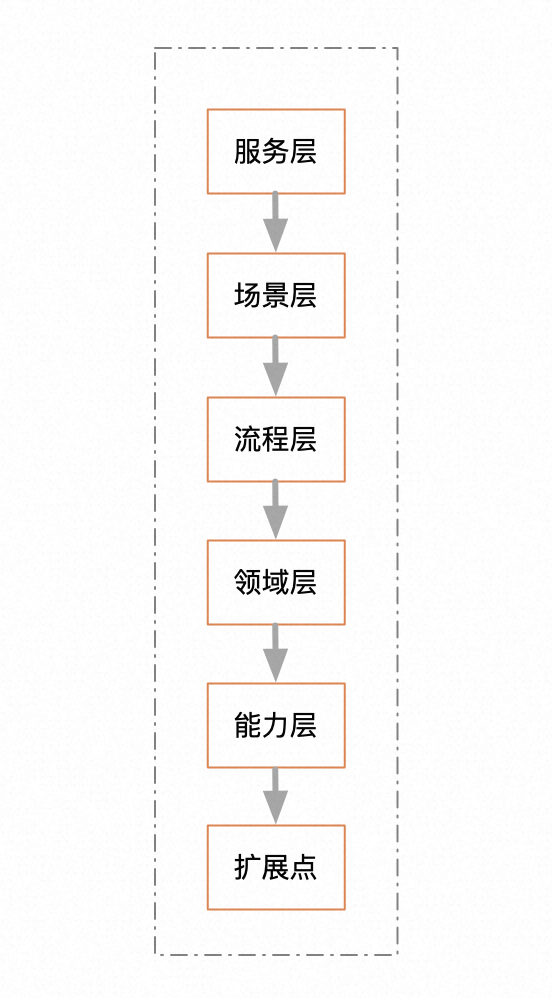
按租户身份分。
一般中台系统都会支持多个租户(行业),每一个租户单独对应一个日志文件。这种分类一般不会单独使用,除非你要做完全意义上的租户隔离。
意识流分类法。
不符合MECE法则,没有清晰统一的分类逻辑,按业务分,按系统模块分,按接口能力分,按新老链路分,各种分法的影子都能看到,结果就是分出来几十个文件,打日志的人根本就不知道这一行的日志会打进哪个文件。
以上说的各种分类方式,都不是绝对纯粹的,因为无论哪一种,无论一开始设计的多么边界清晰,随着时间的推进,最后都会演变为一个大杂烩。
某人希望单独监控某个类产生的日志,新增日志文件;
新增了一个业务,比如一盘货,想单独监控,新增日志文件;
发起了一场服务化战役,针对服务化链路单独监控,新增日志文件;
某个业务想采集用户行为,又不想全接日志消息,新增日志文件;
资损敞口的场景,需要特别关注,新增日志文件;
特殊时期内产生的日志,比如大促,新增日志文件;
凡此种种,不一而足。发现没有,总有那么一瞬间能让人产生新增日志文件的神经冲动,他们的诉求和场景也不可谓不合理,尽管这些日志的维度完全不相关,然而没有什么能阻止这种冲动。最开始的那一套日志设计,就像一个濒临死亡的大象,不断地被不同的利益方从身上扯下一块分去。
格式之乱
对于日志需要有一定的格式这点相信没有人会有异议,格式的乱象主要体现在两个方面,一个是格式的设计上,有些系统设计了非常复杂的格式,用多种分隔符组合,支持日志内容的分组,用关键词定位的方式代替固定位置的格式,同时支持格式扩展,这对人脑和计算机去解析都是一种负担。第二个是同一个日志文件,还能出现不同格式的内容,堆栈和正常业务日志混杂。
来看一个例子,我不给任何提示,你能在大脑里很快分析出这个日志的结构吗?
requestParam$&trace@2150435916867358634668899ebccf&scene@test&logTime@2023-06-14 17:44:23&+skuPromiseInfo$&itemId@1234567:1&skuId@8888:1&buyerId@777:1&itemTags@,123:1,2049:1,249:1,&sellerId@6294:1&toCode@371621:1&toTownCode@371621003:1&skuBizCode@TMALL_TAOBAO:1&skuSubBizCode@TMALL_DEFAULT:1&fromCode@DZ_001:1+orderCommonInfo$&orderId@4a04c79734652f6bd7a8876379399777&orderBizCode@TMALL_TAOBAO&orderSubBizCode@TMALL_DEFAULT&toCode@371621&toTownCode@371621003&+
工具之乱
有时候甚至会出现,同一个类,同一个方法中,两行不同的日志埋点,打出来的日志格式不一样,落的日志文件也不一样。为什么会出现这种情况?就是因为用了不同的日志工具。要究其根源,我们需要分析一下不同的工具究竟是在做什么。可以发现,很多工具之间的差别就是支持的参数类型不一样,有些是打印订单对象的,有些是打印消息的,有些是打印调度日志的。还有一些差别是面向不同业务场景的,比如一盘货专用工具,负卖专用工具。还有一些差异是面向不同的异常封装的,有些是打印ExceptionA,有些是打印ExceptionB的。人间离奇事,莫过于此,或许只能用存在即合理去解释了。
日志分层
我一直信奉极简的设计原则,简单意味着牢不可破。上面提到,一套日志系统最终的结局一定是走向混乱,既然这种趋势无法避免,那么我们在最初设计的时候就只能确保一件事,保证原始的分类尽量简单,且不重叠。其实通用的分类方式无非就两种,一种按职能水平拆分,一种按业务垂直拆分。一般来说,一级分类,应该采用水平拆分。因为业务的边界一般是很难划清的,边界相对模糊,职能的边界就相对清晰稳定很多,职能其实反映的是工作流,工作流一经形成,基本不会产生太大的结构性变化。基于这种思路,我设计了如下的日志分层。 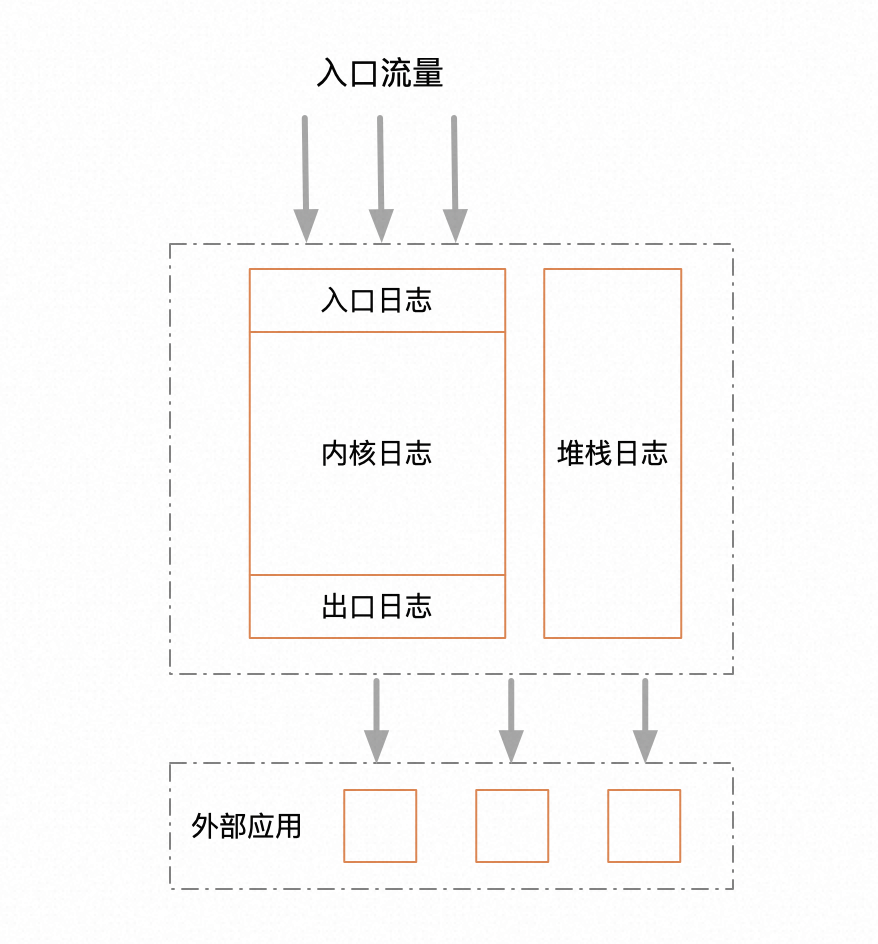
从层次上来看,其实只有三层,入口,内核,出口。入口日志只负责打印流量入口的出入参,比如HSF,controller。出口日志负责打印所有第三方服务调用的出入参。内核日志,负责打印所有中间执行过程中的业务日志。就三层足矣,足够简单,不重不漏。另外把堆栈日志单独拎出来,堆栈相比业务日志有很大的特殊性,本文标题所指出的日志存储降低优化,也只是针对堆栈日志做的优化,这个后面再讲。
格式设计
日志的格式设计也有一些讲究。首先日志的设计是面向人可读的,这个无需多言。另外也非常重要的一个点,要面向可监控的设计,这是容易被很多人忽视的一个点。基于这两个原则,说一下我在格式设计上的一些思路。
首先要做维度抽象。既然是面向监控,监控一般需要支持多个维护,比如行业维度,服务维度,商家维度等等,那么我们就需要把所有的维度因子抽出来。那么这些维度实际打印的时候怎么传给logger呢?建议是把他们存到ThreadLocal中,打的时候从上下文中取。这样做还有一个好处是,日志打印工具设计的时候就会很优雅,只需要传很少的参数。
格式尽量简单,采用约定大于配置的原则,每一个维度占据一个固定的位置,用逗号分割。切忌设计一个大而全的模型,然后直接整个的序列化为一个JSON字符串。
也不要被所谓的扩展性给诱惑,给使用方轻易开出一个能够自定义格式的口子,即便你能轻而易举的提供这种能力。根据我的经验,这种扩展性一定会被滥用,到最后连设计者也不知道实际的格式究竟是怎样的。当然这个需要设计者有较高的视野和远见,不过这不是难点,难的还是克制自己炫技的欲望。
在内容上,尽量打印可以自解释的文本,做到见名知义。举个例子,我们要打印退款标,退款标原本是用1, 2, 4, 8这种二进制位存储的,打印的时候不要直接打印存储值,翻译成一个能描述它含义的英文code。 格式示例
timeStamp|threadName logLevel loggerName|sourceAppName,flowId,traceId,sceneCode,identityCode,loginUserId,scpCode,rpcId,isYace,ip||businessCode,isSuccess||parameters||returnResult||内容示例
2023-08-14 14:37:12.919|http-nio-7001-exec-10 INFO c.a.u.m.s.a.LogAspect|default,c04e4b7ccc2a421995308b3b33503dda,0bb6d59616183822328322237e84cc,queryOrderStatus,XIAODIAN,5000000000014,123456,0.1.1.8,null,255.255.255.255||queryOrderStatus,success||{"@type":"com.alibaba.common.model.queryorder.req.QueryOrderListReq","currentUserDTO":{"bizGroup":888,"shopIdList":[123456],"supplierIdList":[1234,100000000001,100000000002,100000000004]},"extendFields":{"@type":"java.util.HashMap"},"invokeInfoDTO":{"appName":"uop-portal","operatorId":"1110","operatorName":"account_ANXRKY8NfqFjXvQ"},"orderQueryDTO":{"extendFields":{"@type":"java.util.HashMap"},"logisTypeList":[0,1],"pageSize":20,"pageStart":1},"routeRuleParam":{"@type":"java.util.HashMap","bizGroup":199000},"rule":{"$ref":"$.routeRuleParam"}}||{"@type":"com.alibaba.common.model.ResultDTO","idempotent":false,"needRetry":false,"result":{"@type":"com.alibaba.common.model.queryorderstatus.QueryOrderStatusResp","extendFields":{"@type":"java.util.HashMap"}},"success":true}||
堆栈倒打
本文的重点来啦,这个设计就是开头提到的奇思妙想。堆栈倒打源于我在排查另一个系统问题过程中感受到的几个痛点,首先来看一个堆栈示例。 
这么长的堆栈,这密密麻麻的字母,即使是天天跟它打交道的开发,相信第一眼看上去也会头皮发麻。回想一下我们看堆栈,真正想得到的是什么信息。
所以我感受到的痛点核心有两个。第一个是,SLS(阿里云日志产品系统)上搜出来的日志,默认是折叠的。对于堆栈,我们应该都知道,传统异常堆栈的特征是,最顶层的异常,是最接近流量入口的异常,这种异常我们一般情况下不太关心。最底层的异常,才是引起系列错误的源头,我们日常排查问题的时候,往往最关心的是错误源头。所以对于堆栈日志,我们无法通过摘要一眼看出问题出在哪行代码,必须点开,拉到最下面,看最后一个堆栈才能确定源头。
我写了一个错误示例来说明这个问题。常规的堆栈结构其实分两部分,我称之为,异常原因栈,和错误堆栈。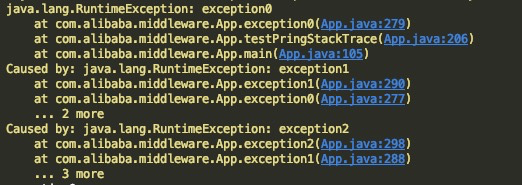
如上,一个堆栈包含有三组异常,每一个RuntimeException是一个异常,这三个异常连起来,我们称为一个异常原因栈。
每一个RuntimeException内部的堆栈,我们称为错误堆栈。
说明一下,这两个名词是我杜撰的,没有看到有人对二者做区分,我们一般都统称为堆栈。读者能理解我想表达的就行,不用太纠结名词。
第二个痛点是,这种堆栈存储成本太高,有效信息承载率很低。老实说这一点可能大多数一线开发并没有太强烈的体感,但在这个降本增效的大环境下,我们每个人应该把这点作为自己的OKR去践行,变被动为主动,否则在机器成本和人力成本之间,公司只好做选择题了。
现在目标很明确了,那我们就开始对症下药。核心思路有两个。
针对堆栈折叠的问题,采用堆栈倒打。倒打之后,最底层的异常放在了最上面,甚至不用点开,瞟一眼就能知道原因。 
同时我们也支持异常原因栈层数配置化,以及错误堆栈的层数配置化。解这个问题,本质上就是这样一个简单的算法题:倒序打印堆栈的最后N个元素。核心代码如下。
/**
* 递归逆向打印堆栈及cause(即从最底层的异常开始往上打)
* @param t 原始异常
* @param causeDepth 需要递归打印的cause的最大深度
* @param counter 当前打印的cause的深度计数器(这里必须用引用类型,如果用基本数据类型,你对计数器的修改只能对当前栈帧可见,但是这个计数器,又必须在所有栈帧中可见,所以只能用引用类型)
* @param stackDepth 每一个异常栈的打印深度
* @param sb 字符串构造器
*/
public static void recursiveReversePrintStackCause(Throwable t, int causeDepth, ForwardCounter counter, int stackDepth, StringBuilder sb){
if(t == null){
return;
}
if (t.getCause() != null){
recursiveReversePrintStackCause(t.getCause(), causeDepth, counter, stackDepth, sb);
}
if(counter.i++ < causeDepth){
doPrintStack(t, stackDepth, sb);
}
}
要降低存储成本,同时也要确保信息不失真,我们考虑对堆栈行下手,把全限定类名简化为类名全打,包路径只打第一个字母,行号保留。如:c.a.u.m.s.LogAspect#log:88。核心代码如下。
public static void doPrintStack(Throwable t, int stackDepth, StringBuilder sb){
StackTraceElement[] stackTraceElements = t.getStackTrace();
if(sb.lastIndexOf(" ") > -1){
sb.deleteCharAt(sb.length()-1);
sb.append("Caused: ");
}
sb.append(t.getClass().getName()).append(": ").append(t.getMessage()).append("
");
for(int i=0; i < stackDepth; ++i){
if(i >= stackTraceElements.length){
break;
}
StackTraceElement element = stackTraceElements[i];
sb.append(reduceClassName(element.getClassName()))
.append("#")
.append(element.getMethodName())
.append(":")
.append(element.getLineNumber())
.append("
");
}
}
最终的效果大概长这样。我们随机挑了一个堆栈做对比,统计字符数量,在同等信息量的情况下,压缩比达到88%。
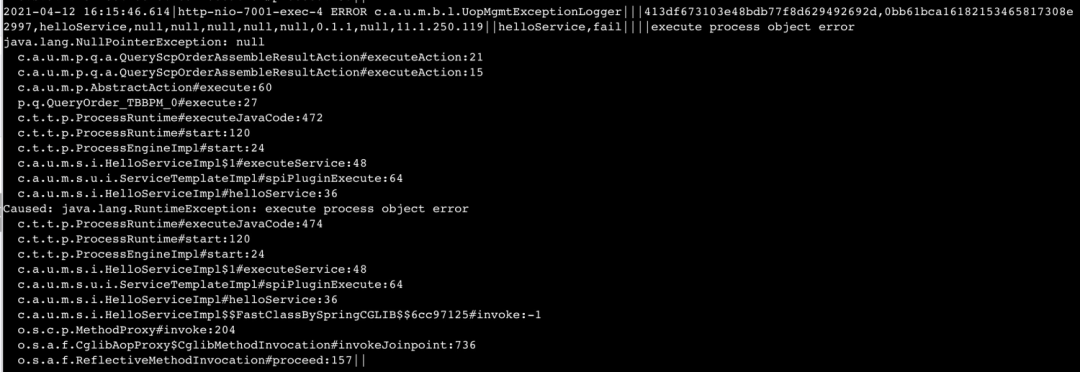
思维拓展
很多文章喜欢鼓吹所谓的最佳实践,在笔者看来最佳实践是个伪命题。当你在谈最佳实践的时候,你需要指明这个"最"是跟谁比出来的,你的适用范围是哪些,我相信没有任何一个人敢大言不惭自己的框架或方案是放之四海而皆准的。
本文所提出的日志设计实践方案,是在一个典型的中台应用中落地的,三段的日志分层方案虽然足够简单,足够通用,但是最近解触了一些富客户端应用,这个方案要想迁移,可能就得做一些本土化的改造了。他们的特点是依赖的三方服务少,大量的采用缓存设计,这种设计的底层逻辑是,尽量使得所有逻辑能在本地客户端执行以降低分布式带来的风险和成本,这意味着,可能99%的日志都是内部执行逻辑打的,那我们就得考虑从另一些维度去做拆分。另外对于日志降本,本文探讨的也只是降堆栈的存储,一个系统不可能所有日志都是堆栈,所以实际整体的日志存储成本,可能降幅不会有这么多。
谈这么多,归根结底还是一句话,不要迷信银弹,减肥药一类的东西,所有的技术也好,思想也好,都要量体裁衣,量力而行。
审核编辑:汤梓红
-
存储
+关注
关注
13文章
4891浏览量
90290 -
文件
+关注
关注
1文章
598浏览量
26117 -
日志
+关注
关注
0文章
149浏览量
11097
原文标题:十行代码让日志存储降低80%
文章出处:【微信号:OSC开源社区,微信公众号:OSC开源社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
【开发指南】全志系列核心板开发过程中的常见问题及排查策略

嵌入式系统开发过程中的常见问题和解决方法
单片机开发过程中的常见问题
学习ETS开发过程中的常见问题及解决办法
客车产品设计与开发过程中的质量管理
光端机在使用过程中遇到的常见问题及对应的解决方案
STM32开发过程的常见问题

如何读懂FPGA开发过程中的Vivado时序报告?

PCB设计中的常见问题有哪些?




评论