 ChatGPT真的产生心智了吗?ChatGPT是如何产生心智的?
ChatGPT真的产生心智了吗?ChatGPT是如何产生心智的?

一、前言--ChatGPT真的产生心智了吗?
来自斯坦福大学的最新研究结论,一经发出就造成了学术圈的轰动,“原本认为是人类独有的心智理论(Theory of Mind,ToM),已经出现在ChatGPT背后的AI模型上”。所谓心智理论,就是理解他人或自己心理状态的能力,包括同理心、情绪、意图等。这项研究中,作者发现:davinci-002版本的GPT3已经可以解决70%的心智理论任务,相当于7岁儿童。
2023 年,面对铺天盖地的 AI 应用,我们人类终于意识到,有一些东西被永远的改变了。但在这波 AI 热潮之中,只有一个应用是真正吓人的——ChatGPT。由于心智无法通过量化评判,但ChatGPT确实满足智能的定义,例如推理、计划、解决问题、抽象思考、理解复杂想法、快速学习。但ChatGPT本质上只做一件事情:续写。当我们给出前N个词汇的时候,如果一个模型能够告诉我们第“N+1”个词汇大概率会是什么,我们就认为模型掌握了语言的基本规律。

为什么光凭“续写”就可以产生智能?以下是摘自知乎的一段回答:
“为什么这么一个简单的接话茬能力让ChatGPT看起来能够解决各种各样的任务呢?因为我们人类大部分的任务都是以语言为载体的。当我们前面说了一些话,它把接下来的话接上,任务就完成了。ChatGPT作为一个大语言模型,目的就是“把话接上”,而把话接上这件事情可以在不知不觉中帮我们完成各种任务。”,这也解释了为什么ChatGPT有时候瞎胡诌,他并没有撒谎,他不知道对错,他只是想把对话顺利进行下去。
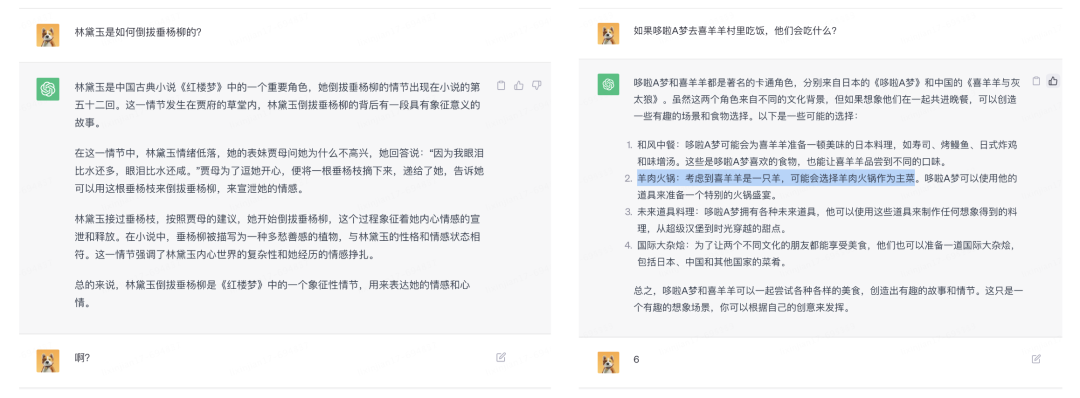
如果真的像上述所说,那GPT似乎没有我们想象的神奇,看起来只是一个基于大数据和统计学的语言模型,通过它学习的海量文本预测下一个概率最高的词。就像是有一个容量巨大的“数据库”,所有的回答都是从这个数据库里拿到的。
但奇怪的是,ChatGPT又可以回答他没有学习过的问题,最具代表性的是训练集中不可能存在的六位数加法,这显然无法通过统计学的方式来预测下一个最高概率的数字是多少。
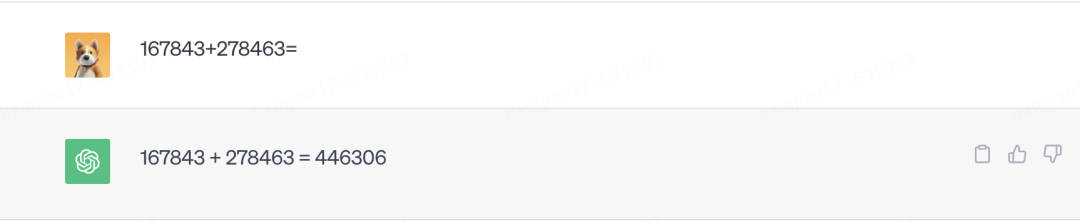
不仅如此,GPT还学习到了在对话中临时学习的能力。
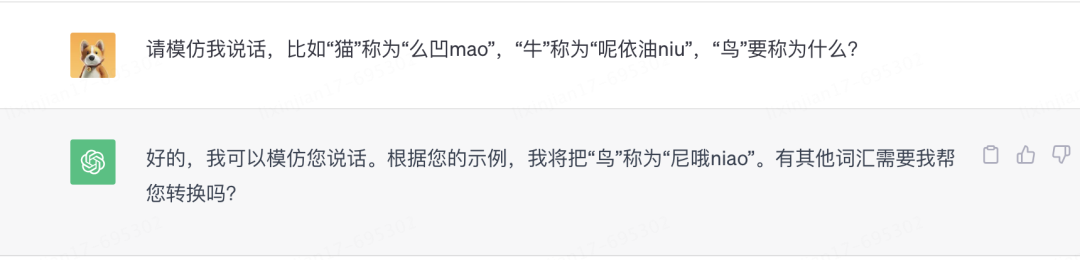
看起来ChatGPT除了“续写”外,还真的产生了逻辑推理能力。这些统计之外的新能力是如何出现的?
如何让机器理解语言,如何让代码存储知识?这篇文章,只是为了回答一个问题:一段代码是如何拥有心智的?
二、Attention is all you need--注意力机制
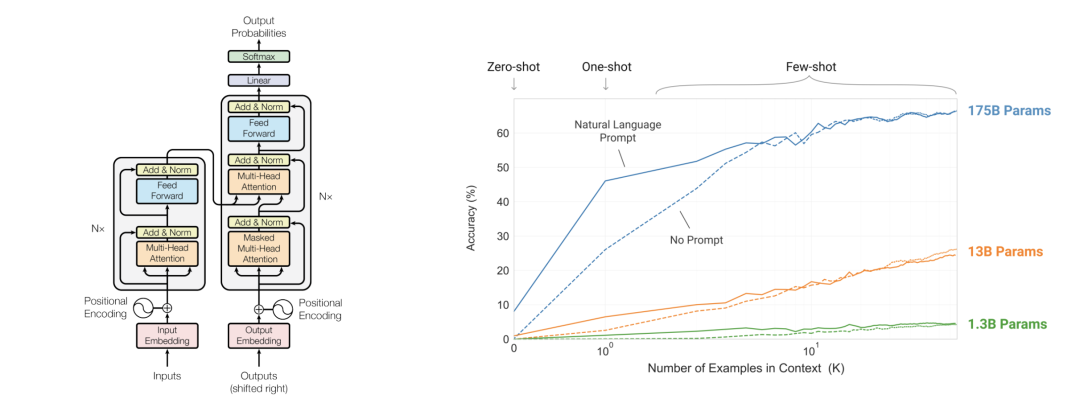
搜索所有有关ChatGPT的文章,发现有一个词的出现频率特别高,Attention is all you need。ChatGPT的一切都建立在“注意力机制”之上,GPT的全称是Generative Pre-trained Transformer,而这个transformer就是一个由注意力机制构建的深度学习模型。其来源于2017年的一篇15页的论文,《Attention is all you need》[1]。再结合OpenAI对于GPT2和GPT3的两篇论文[2][3],我们可以拆开这个大语言模型,看看他在说话的时候究竟发生了什么。
注意力机制的诞生来源于人脑的思维方式,例如在读这段话时,你的注意力会不断的从左往右一个字一个字的闪过,之后再把注意力放到完整的句子上,理解这些字词的关系,其中有些关键词还会投入更多的注意,这一切发生在电光火石之间。
而基于注意力机制的Transformer和GPT系列模型就是在模拟这一思维过程,通过让机器理解一句话中字词之间的关系和意义,完成下一个词的续写,然后再理解一遍,再续写一个词,最后写成一段话。要让程序模仿这件事并不容易。如何让机器计算字符,如何让代码存储知识,为什么将以上模型框架中的一个单元拆开后,全都是圆圈和线?
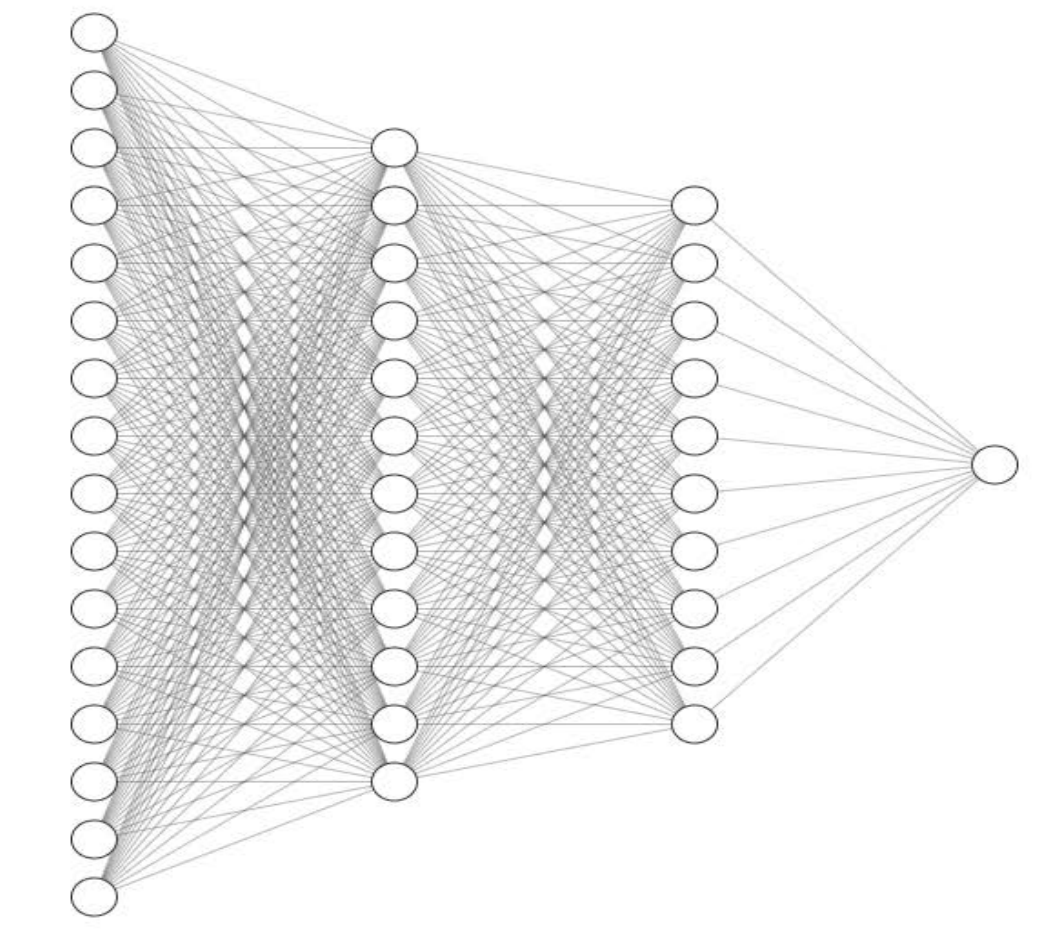
所以研究AI的第一步,是搞清楚上图中的一个圆圈究竟能够干什么。
【 神经元--圆圈和线 】
1957年的一篇论文,《感知器:大脑中信息存储和组织的概率模型》[4]中也出现了一堆圆圈和线,这就是今天各种AI模型的基本单元,我们也叫它神经网络。一个世纪前,科学家就已经知道了人脑大概的运作方式,这些圆圈模拟的是神经元,而线就是把神经元连接起来的突触,传递神经元之间的信号。
将三个神经元连接在一起,就得到了一个开关,要么被激活输出1,要么不被激活输出0。开关可以表达是否,区分黑白,标记同类,但是归根到底都是一件事情,分类。过去几十年,无数个人类最聪明的头脑所做的,就是通过各种方式把这些圆圈连接起来,试图产生智能。
这个网站可以模拟更多的神经元分裂问题。可以看到一个神经元能处理的情况还是太有限了,能分开明显是两块的数据,而内圈外圈的数据就分不开。但如果加入激活函数,再增加新的神经元,每一个新增的神经元都可以在边界上新增一两条折线,更多的折线就可以围得越来越像一个圆,最终完成这个分类。
分类可以解决很多具体问题,假如上图中的每个点的X轴和Y轴分别代表一只小狗的岁数和体重,那么只凭这两种数值就可以分出来这是两个不同品种的狗,每个点代表的信息越多,能解决的问题也就越复杂。比如一张784个像素的照片,就可以用784个数字来表示分类,这些点就能分类图片。更多的线,更多的圆圈,本质上都是为了更好的分类。这就是今天最主流的AI训练方案,基于神经网络的深度学习。

学会了分类,某种程度上也就实现了创造。
这就是为什么有这么多业界学者意识到了深度学习的本质,其实是统计学,沿着圆圈和线的道路,他们终究会到达终点,成为人人都可以使用的工具。而如果拆开GPT系列模型,暴露出来的也仍然只是这些圆圈和线。但分类和统计真的能模仿人的思维吗?在论述之前,先了解一下成语接龙的底层原理。
【 成语接龙 】
在2018年第一代GPT的原始论文[5]中,我们可以看到GPT系列的模型结构。回想上文中提到的注意力机制,这一层被叫做注意力编码层,它的目标就是模仿人的注意力,抽取出话语之间的意义,把12个这样的编码层叠在一起,文字从下面进去,出来的就是GPT预测的下一个词。
比如输入how are you之后,模型会输出下一个单词doing,为什么它会输出doing?接下来我们就得搞明白中间到底发生了什么。
输入how are you后,这三个单词会被转换为3个1024维度的向量,接着每个向量都会加上一个位置信息,表示how是第一个词,are是第二个词,以此类推之后它们会进入第一个注意力编码层,计算后变成三个不一样的1024长的向量,再来到第二层、第三层,一直经过全部的24个注意力编码层的计算处理,仍然得到三个1024长的向量,对下一个词的续写结果就藏在最后一个向量里面。关键的计算就发生在这些注意力编码层,这一层里又可以分成两个结构,先算多头注意力,再算全连接层。注意力层的任务是提取话语间的意义,而全链接层需要对这些意义做出响应,输出存储好的知识。
我们可以先用how做个例子,注意力层里有三个训练好的核心参数KQV,用于计算词语间的关联度,将它们与每个向量相乘后,就能得到how和are的关联度,再通过这种方式计算how和you, how和how的关联度,就能得到三个打分,分数越高意味着它们的关联越重要。之后再让三个分数和三个有效信息相乘再相加,就把how变成了一个新的64个格子的向量,然后对are和you做同样的操作,就得到了三个新的向量。

参与这轮计算的KQV是固定的,而模型里一共有16组不同的KQV,他们分别都会做一轮刚才这样的运算,得到16组不同的输出,这叫做多头注意力,意味着对这句话的16组不同的理解。把它们拼在一起,就得到了和输入相同长度的1024个格子,再乘一个权重矩阵W就进入到了全链接层的计算。
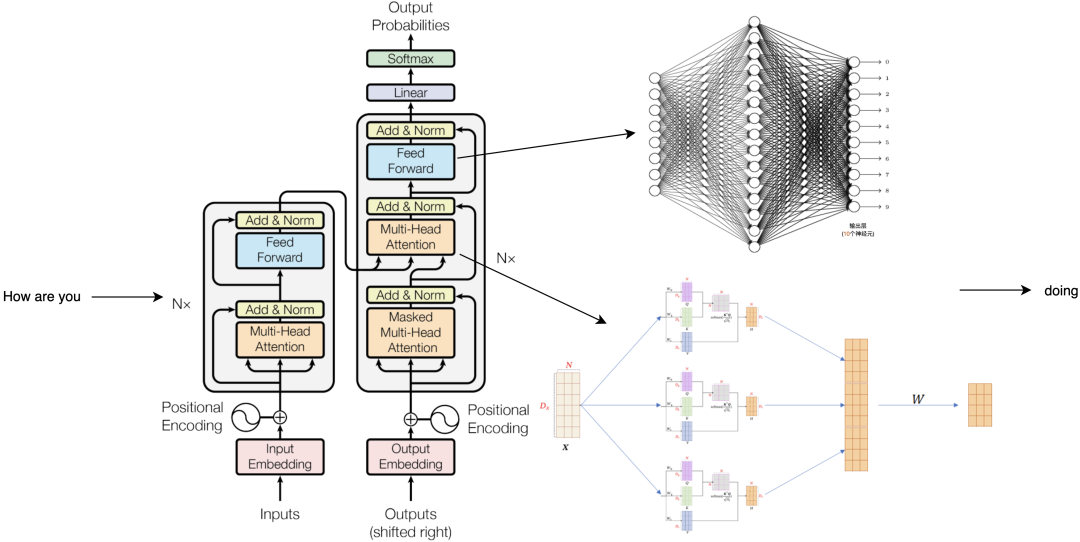
在全连接层里,就是4096个我们熟悉的神经元,它们都还是在做分类的工作。这里的计算是把被注意力层转换后的how向量和这里的每一个神经元都连接在一起,1024个格子里的每一个数字都分别和第一个神经元的连线的权重相乘再相加,这个神经元会输出一个相似度分值,与此同时,每一个神经元都在做类似的操作。只有少数神经元的输出大于零,也就意味着神经元对这个敏感,再连接1024个格子号所对应的向量,就又得到了一个新的向量。之后are和you做类似的计算,就得到了三个和初始长度一样的1024长的格子串,这就是一层注意力编码层内发生的事情。之后的每一层都按照相同的流程在上一层的基础上做进一步的计算,即便每一层都只带来了一点点理解,24层算完以后也是很多理解了,最终还是得到三个向量,每个1024长。而模型要输出的下一个词就基于这最后一个向量,也就是you变换来的向量,把它从1024恢复成0-50256范围的序号,我们就能看到这个序号向量在词表里最接近的值。到这一步就可以说模型算出了how are you之后的下一个词,最有可能是doing。
我们希望模型继续续写,就把这个doing续在how are you后面,转换成四个向量,再输入进模型,重复刚才的流程,再得到下一个词。这样一个接一个,一段话越来越长,直到结束,变成我们看到的一段话,这就是文字接龙的秘密。而ChatGPT也只是把这个续写模型改成了对话界面而已,你提的每一个问题都会像这样成为续写的起点,你们共同完成了一场文字接龙。
【 “大”语言模型 】
刚刚提到的每一层的计算流程长,其实还好,GPT真正吓人的地方是参数量大。GPT1的基本尺寸是768,每一层有超过700万个参数,12层就是1.15亿个参数,在他发布的2018年已经非常大了。我们刚刚拆开的GPT medium基本尺寸是10241,共有24层,每一层有1200万参数,乘起来就是3.5亿参数。而到了ChatGPT用的GPT3的版本,它的参数量是1750亿,层数增加到了96层。GPT4并没有公布它的大小,有媒体猜测它是GPT3的六倍,也就是一万亿参数。这意味着,即便把一张3090显卡的显存变大几百倍,让他能装的下级GPT4,回答一个简单问题可能仍然需要计算40分钟。
拆开这一切,就会发现没有什么惊人的秘密,只有大,文明奇观的那种大,无话可说的那种大,这就是GPT系列的真相,一个“大”语言模型。但是我们还是无法回答为什么这样的模型能够产生智能,以及现在还出现了一个新的问题,为什么参数量非得这么大?
让我们先总结一下目前的已知信息,第一,神经网络只会做一件事情,数据分类,第二,GPT模型里注意力层负责提取话语中的意义,再通过全链接层的神经元输出存储好的知识,第三,GPT说的每一个词都是把对话中的所有词在模型中跑一遍,选择输出概率最高的词。所以,GPT拥有的知识是从哪来的?我们可以在OpenAI的论文中看到ChatGPT的预训练数据集,他们是来自网站、图书、开源代码和维基百科的大约700GB的纯文本,一共是4991个token,相当于86万本西游记。而它的训练过程就是通过自动调整模型里的每一个参数,完成了这些海量文字的续写。
在这个过程中,知识就被存储在了这一个一个的神经元参数里,之后它的上千亿个参数和存储的知识就不再更新了。所以我们使用到的ChatGPT其实是完全静止的,就像一具精致的尸体,它之所以看起来能记住我们刚刚说的话,是因为每输出一个新的词,都要把前面的所有词拿出来再算一遍,所以即便是写在最开头的东西,也能够影响几百个单词之后的续写结果。但这也导致了ChatGPT每轮对话的总词汇量是有上限的,所以GPT不得不限制对话程度。就像是一条只有七秒记忆的天才金鱼。
现在回到前言中提到的问题,为什么ChatGPT可以回答他没有学习过的互联网不存在的问题,例如一个训练数据里不可能存在的六位数加法,这显然无法通过统计学的方式来预测下一个最高概率的数字是多少,这些统计之外的新能力是如何出现的?
今年5月,OpenAI的新研究给了我启发,这篇论文名为《语言模型,可以解释语言模型中的神经元》[6]。简单来说就是用GPT4来解释GPT2。给GPT2输入文本时,模型里的一部分神经元会激活,Open AI让GPT4观察这个过程,猜测这个神经元的功能,再观察更多的文本和神经元,猜测更多的神经元,这样就可以解释GPT2里面每一个神经元的功能,但是还不知道GPT4猜的准不准。验证方法是让GPT4根据这些猜想建立一个仿真模型,模仿GPT2看到文本之后的反应,再和真的GPT2的结果做对比,结果一致率越高,对这个神经元功能的猜测就越准确。OpenAI在这个网站里记录了他们对于每一个神经员的分析结果。
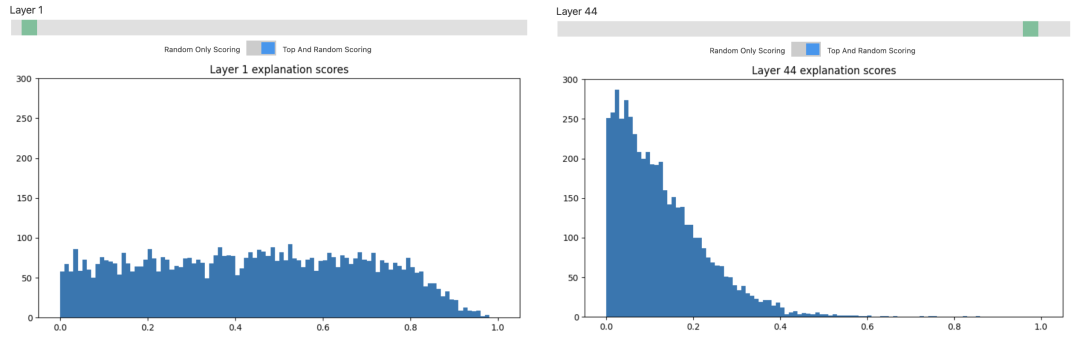
比如我们输入30, 28,就可以看到第30层的第28个神经元的情况。GPT4认为这个神经元关注的是具体时间。下面是各种测试例句,绿色就表示神经元对这个词有反应,绿色越深,反应就越大。可以发现,即便拼写完全不同,但这些模型中间层的神经元也已经可以根据词语和上下文来理解它们的意义了。

但OpenAI也发现,只有那些层数较低的神经元才是容易理解的。这个柱状图里的横坐标是对神经元解释的准确程度,纵坐标是神经元的数量。可以看到,对于前几层的神经元,差不多一半都能做到0.4以上的准确度。但是层数越高,得分低的神经元就越来越多了,大多数神经元还是处在一片迷雾之中。
因为对于语言的理解本来就是难以解释的,比如这样一段对话。对于中文母语的我们来说,很快就能理解这段话的意思,但是对于一个神经网络,只靠几个对“意思”有反应的神经元显然是不够意思。
A:“你这是什么意思?”
B:“没什么意思,意思意思。”
A:“你这人真有意思。”
B:“其实也没有别的意思。”
A:“那我就不好意思了。”
B:“是我不好意思。”
而GPT似乎理解了这些意思,它是如何做到的?
【 Emergence--涌现 】
“将万事万物还原为简单基本定律的能力,并不蕴含从这些定律出发,重建整个宇宙的能力。” —— Philip Anderson.
1972年,理论物理学家Philip Anderson在Science发表了一篇名为《More is Different》[7]的论文,奠定了复杂科学的基础,安德森认为:“大量基本粒子的复杂聚集体的行为并不能依据少数粒子的性质作简单外推就能得到理解。取而代之的是在每一复杂性的发展层次之中呈现了全新的性质,从而我认为要理解这些新行为所需要作的研究,就其基础性而言,与其它相比也毫不逊色”。
回顾语言模型的结构,信息是随着注意力编码层不断往上流动的,层数越高的神经元越有能力关注那些复杂抽象的概念和难以言说的隐喻。这篇叫《在干草堆里找神经元》[8]的论文也发现了类似的情况,他们找到了一个专门用来判断语言是否为法语的神经元。如果在小模型当中屏蔽这个神经元,他对法语的理解能力马上会下降,而如果在一个大模型中屏蔽它,可能几乎没什么影响。这意味着在模型变大的过程中,一个单一功能的神经元很可能会分裂出多个适应不同情况的神经元,它们不再那么直白的判断单一问题,进而变得更难。
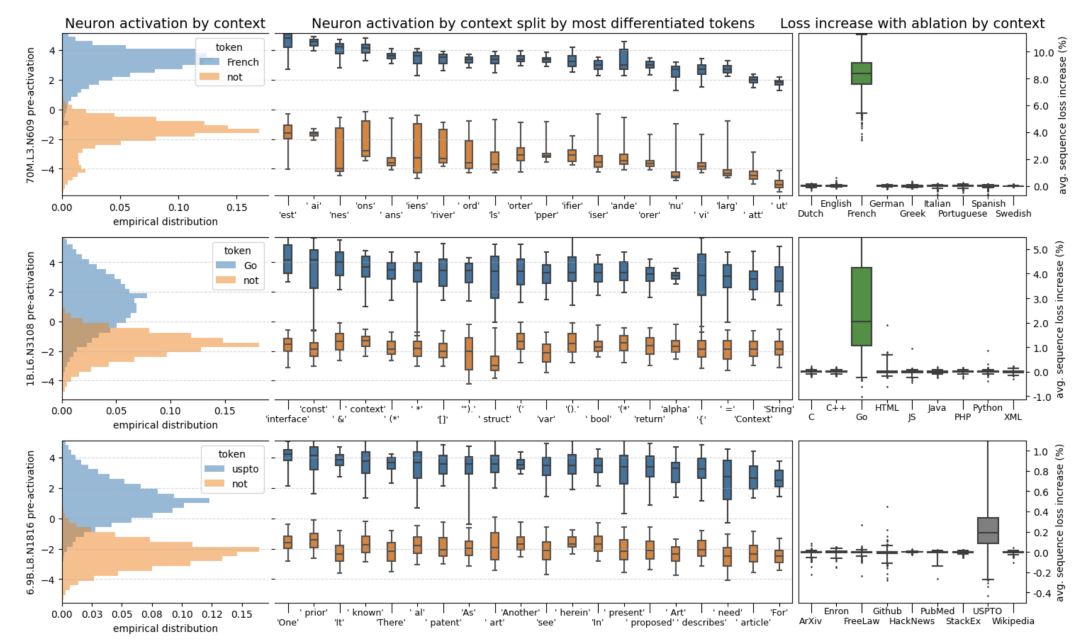
能理解这就是OpenAI为什么非得把模型搞得这么大的原因,只有足够大才足够抽象,而大到了一定程度,模型甚至会开始出现从未出现过的全新能力。
在这篇名为《大语言模型的涌现能力》的论文中[9],研究人员对于这些大小不同的语言模型完成了八项新能力的测试。可以看到,他们在变大之前一直都不太行,而一旦大到某个临界点,它突然就行了,开始变成一条上窜的直线,就像是在一瞬间顿悟了一样。
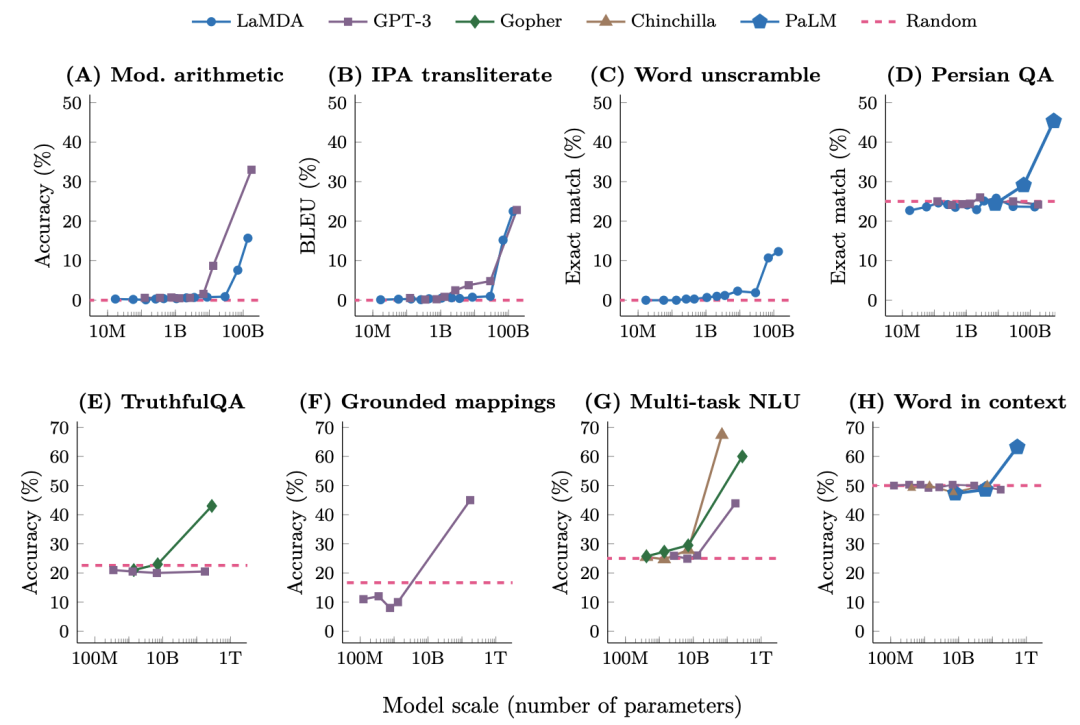
纵观我们的自然和宇宙,一个复杂系统的诞生往往不是线性成长,而是在复杂度积累到某个阈值之后,突然的产生一种新的特质,一种此前从未有特的全新状态,这种现象被称作涌现,Emerge。而这个上千亿参数的大语言模型,好像真的涌现出了一些数据分类之上的新东西。
最近读了《失控》这本书,里面也提到了一个概念叫涌现,可以理解为蜂群智慧。一只蜜蜂是很笨的,但是组成一个群体就可以完成很多超越个体智慧的决策。当然我不觉得AI的单个神经元是愚笨的,而是会不会这种“意识”,也会因为大量功能迭代,学习,突然涌现出来,就像人类的进化,不知怎么的就有了意识。就像这个世界的一切都是由原子构成,但如果只是计算原子之间的相互作用力,我们永远也无法理解化学,也无法理解生命。所以,如果仅仅从还原论的角度把AI看作只做二元分裂的圆圈和线,我们就永远无法理解大语言模型今天涌现出的抽象逻辑和推理能力,为此,我们需要在一个新的层级重新理解这件事。
三、中文房间
1980年,美国哲学教授John Searle在这篇名为《心智大脑和程序》[10]的论文中提出了一个著名的思想实验,中文房间。把一个只懂英文的人关在一个封闭的房间里,只能通过传递纸条的方式和外界对话。房间里有一本英文写的中文对话手册,每一句中文都能找到对应的回复。这样房间内的人就可以通过手册顺畅的和外界进行中文对话,看起来就像是会中文一样,但实际上他既不理解外面提出的问题,也不理解他所返回的答案。
他试图通过中文房间证明,不管一个程序有多聪明或者多像人,他都不可能让计算机拥有思想、理解和意识。真的是这样吗?在这个名为互联网哲学百科全书的网站中,可以看到围绕中文房间的各种争论,他们都没能互相说服。

这些讨论都停留在思想层面,因为如果只靠一本打印出来的手册,中文房间是不可能实现的。中文对话有着无穷无尽的可能,即便是同样一句话,上下文不同,回答也不同。这意味着手册需要记录无限多的情况,要不然总有无法回答的时候。但诡异的是,ChatGPT真的实现了。作为一个只有330GB的程序,ChatGPT在有限的容量下实现了几乎无限的中文对话,这意味着他完成了对中文的无损压缩。
想象有一个这样的复读机,空间只有100MB,只能放十首歌。要听新的歌,就得删掉旧的歌。但现在我们发现了一个神奇复读机。现在只需要唱第一句,这个复读机就可以通过续写波形的方式把任何歌曲播放出来。我们应该怎么理解这个复读机?我们只能认为他学会了唱歌。
四、Compression--压缩即智慧
回想GPT的学习过程,它所做的,就是通过它的1750亿个参数,实现了它所学习的这4990亿个token的压缩。到这一步,逐渐意识到,是压缩产生了智能。
Jack Ray, OpenAI大语言模型团队的核心成员,在视频讲座中提到,压缩一直是我们的目标。

接下来是我对于压缩及智能这件事的理解,假设我要给你发送这句话,“压缩即智慧”。
我们可以把GPT当做一种压缩工具,我用它压缩这句话,你收到后再用GPT解压,我们得先知道这句话的信息量有多大。在GBK这样的编码里,一个汉字需要两个字节,也就是16个0/1来表述,这可以表示2的16次方,也就是65536种可能。这句话一共5个字符,就需要一共80个0和1,也就是80比特。但实际上这句话的信息量是可以小于80比特的。它的真实信息量其实可以用一个公式计算。
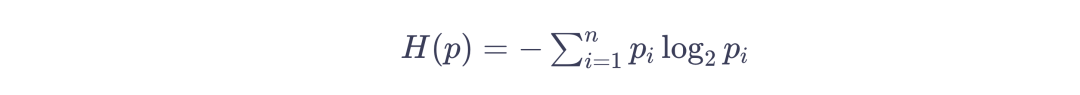
这是1948年香农给出的信息熵的定义,它告诉我们信息的本质是一种概率密度。我们可以把这里的P简单理解为每个字出现的概率,它们出现的概率越低,整句话的信息量就越大。如果这句话里的每个字都是毫无规律的随机出现,那么P的概率就是1/65536,计算后的信息量就是原始的80比特。常见的传统压缩方法是找到重复的字,但几乎不重复的句子就很难压缩。更重要的是,正常的语言是有规律的,“压”后面跟着“缩”的概率远大于1/65536,这就给了信息进一步压缩的空间。而语言模型所做的就是在压缩的过程中找到语言的规律,提高每个字出现的概率。比如我们只发送“压缩”,让语言模型开始续写,预测的概率表里就会出现接下来的词,我们只需要选择“即”和“智慧”所在的位置,例如(402,350)。那这两这个数字就实现了信息的压缩,接收方基于这些信息,从相同语言模型的概率去处理,选出数字对应的选项,就完成了解压。2个最大不超过5000的数字,每个数字只要13位0/1就能表示,加上前2个字,一共也只需要发送52位0/1,信息压缩到原来的52/80大约65%。
相反,如果语言模型的预测效果很差,后续文字的词表还是会很长,无法实现很好的压缩效果。所以可以发现,压缩效果越好意味着预测效果越好,也就反映了模型对于被压缩信息的理解,而这种理解本身就是一种智能。为了把九九乘法表压缩的足够小,他需要理解数学,而如果把行星坐标压缩的足够小,他可能就理解了万有引力。今天,大语言模型已经成为了无损压缩的最佳方案,可以实现14倍的压缩率。压缩这一视角最大的意义在于,相比于神秘莫测的涌现,它给了我们一个清晰明确、可以量化机器智能的方案。即便面对中文房间这样的思想实验,我们也有办法研究这个房间的智能程度。
但是,通过压缩产生的智慧和人的心智真的是同一种东西吗?
五、写在最后
如果要问,现阶段GPT和人类说话方式最大的不同是什么,我认为,答案是他不会说谎。对于语言模型来说,说和想是一件事情,他只是一个字一个字的把他的思考过程和心理活动说出来了而已。GPT从不回答我不知道,因为他并不知道自己不知道,这就是AI的幻觉,看起来就像是一本正经的胡说八道,他只是想让对话继续下去,是否正确反而没那么重要。优化这个问题的方法也很简单,只需要在提问的时候多补充一句,Let's think step by step,请逐步分析,让GPT像人一样多想几步,对他来说也就是把想的过程说出来。Step by step,这种能力也被称为Chain of Thought,思维链。心理学家Daniel Kahneman把人的思维划分成了两种,系统一是直觉、快速的、没有感觉的,系统二则需要主动的运用知识、逻辑和脑力来思考。前者是快思考,就像我们可以脱口而出八九七十二,九九八十一,而后者是慢思考。就比如要回答72乘81是多少,就必须列出过程,一步步计算。思维链的存在意味着大语言模型终于有了推理能力。而为了做到这件事,我们的大脑进化了6亿年。我们可以在6亿年前的水母身上看到神经网络最古老的运行方式。水母外围的触角区域和中心的嘴部区域都有神经元。当触角感知到食物时,这里的神经元会激活,然后把信号传给中心的神经元,食物也会被这个触角卷起来送到嘴里。漫长的岁月里,我们的大脑就在神经网络的基础上一层又一层的叠加生长出来。
首先进化出来的是爬虫类脑,这部分和青蛙的脑子有点像,它控制着我们的心跳、血压、体温这些让我们不会死的东西。然后是古生物脑,它支配着我们的动物本能,饥饿、恐惧和愤怒的情绪,繁衍后代的欲望都来自边缘系统的控制。而最外侧这两毫米左右的薄薄的一层,是最近几百万年才进化出来的新结构、新皮质,我们人类引以为傲的那些部分,语言、文字、视觉、听力、运动和思考都发生在这里,但我们对新皮质还是知之甚少。目前已知的是,这里有大概200亿个神经元,每一平方厘米的新皮质中都大约有一千万个神经元和500亿个神经元之间的连接。只需要从人类大脑外侧取下一小片三平方厘米的新皮质,就已经和ChatGPT大的吓人的参数量类似了。而我们的大脑之所以需要这么多神经元,是因为GPT仅仅需要预测下一个词,而我们的神经元需要时刻预测这个世界下一秒会发生什么。
最近几十年的神经科学研究发现除了能激活神经元的突触信号,还存在大量负责预测的树突脉冲信号。一个处于预测状态的神经元如果得到足够强的突出信号,就可以比没有预测状态的神经元更早的被激活,进而抑制其他的神经元。这意味着有一个事无巨细的世界模型就存储在我们新皮质的200亿个神经元里,而我们的大脑永远不会停止预测。所以,当我们看到一个东西,其实看到的是大脑提前构建的模型,如果它符合我们的预测,无事发生。而一旦预测错误,大量的其他神经元就会被激活,让我们注意到这个错误,并及时更新模型。所以每一次错误都有它的价值。我们也正是在无数次的预测错误和更新认知中真正认识了世界。
现在我可以试着回答最初的问题,GPT或许尚未涌现心智,但他已经拥有了智能。它是一个“大”的语言模型,是几百万个圆圈和线互相连接的分类器,是通过预测下一个词实现文字接龙的聊天大师,是不断向上抽取意义的天才金鱼,是对几千亿文字无损压缩的复读机,是不论对错永远积极回应人的助手。它可能又是一场快速退潮的科技热点,也可能是人类的最后一项重要的发明。从围棋、绘画、音乐到数学、语言、代码,当AI开始在那些象征人类智力和创造力的事情上逐渐超越的时候,给人类最大的冲击不仅仅是工作被替代的恐惧,而是一种更深层的自我怀疑。人类的心智是不是要比我们想象的浅薄的多,我不这么认为。
机器可以是一个精妙准确的复读机,而人类是一个会出错的复读机。缺陷和错误定义了我们是谁。每一次不合规矩,每一次难以理解,每一次沉默、停顿和凝视,都比不假思索的回答更有价值。
审核编辑:刘清
-
编码器
+关注
关注
45文章
4033浏览量
144006 -
GPT
+关注
关注
0文章
378浏览量
17067 -
机器语言
+关注
关注
0文章
36浏览量
11085 -
ChatGPT
+关注
关注
31文章
1611浏览量
10512
原文标题:ChatGPT是如何产生心智的?
文章出处:【微信号:OSC开源社区,微信公众号:OSC开源社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
OpenAI将对ChatGPT进行史上最大升级
MK-Excel VBA编程与ChatGPT自动化实战-宏录制/条件判断
ChatGPT 5.5镜像站技术升级解析:更快的生成速度对开发者意味着什么?
2026实测:如何在国内免费平台上将ChatGPT 5.5镜像站设为主力生成模型,搭配其他模型完成事实核查
OpenAI正式发布ChatGPT Images 2.0版本
智能驾驶时代:消费者心智与购车决策的重塑
ChatGPT突然无法登录是什么情况?如何解决?

浅析电源EMI产生机理
巨头竞逐AI医疗健康:OpenAI推出ChatGPT Health,蚂蚁阿福国内领跑
从共识到共行:拓普联科关于“一次性做好”的团队心智集结

中汽中心智能网联科技创新基地建设项目正式开工
负电压的产生方法和应用场景
中汽中心智能网联科技创新基地落户天津
ChatGPT 智能体发布的观点解析及对科义相关系统的现实意义
AI真会人格分裂!OpenAI最新发现,ChatGPT善恶开关已开启




评论