 JVM指针压缩的工作原理
JVM指针压缩的工作原理

一前言
当今,Java已经成为了世界上最流行的编程语言之一。在Java的生态系统中,JVM(Java虚拟机)是至关重要的组成部分。JVM 是 Java 程序运行的环境,它负责将 Java 字节码翻译成机器码,并执行程序。在 JVM 中,内存使用以及分配一直是个重要的问题。
在 32 位系统中,一枚指针占用 4 字节,随着 64 位系统的逐渐普及,指针的大小也增长到了 8 个字节,JVM 为了降低内存占用,使用了指针压缩技术来降低内存的占用,接下来,我们将自顶向下的深入探讨 JVM 指针压缩的工作原理。
二理解压缩指针
为什么 JVM 需要压缩指针?
在计算机中,指针的大小通常取决于计算机的字长。例如,在 32 位系统一字长为 4 字节,即一枚指针的占用内存空间大小为 4 字节。随着计算机性能的提升,内存价格的降低,64 位系统也开始逐渐普及。而在 64 位系统中,字长和指针也由原来的增长到 8 个字节,JVM 为了降低内存占用,开发了指针压缩算法,即:在 64 位系统中,指针依然使用 4 字节存储。
数据指针与字长的关系
字长是指一台计算机中处理器可以一次性处理的二进制数字的位数。它通常是 8 位、16 位、32 位或 64 位,这意味着在一次处理中可以处理 8 个、16 个、32 个或 64 个二进制数字。字长越长,计算机处理数据的能力越强,但同时也会增加计算机的成本和复杂度。
CPU 的上下文是寄存器,CPU 运算的本质就是不断从 CS IP 寄存器中取指令然后执行,CPU 运算所需的数据也是放在寄存器里,CPU 一次性处理的数据大小就是寄存器的大小。
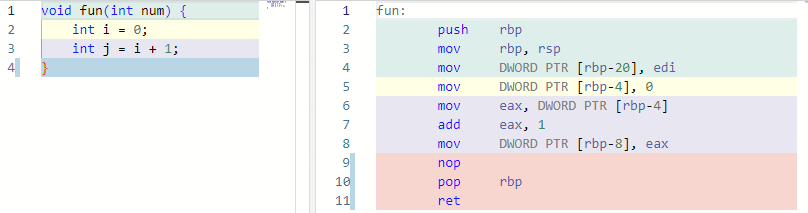
上图左侧是一段简单的 C 语言代码片段,右侧是该代码的汇编代码(即 CPU 执行这段代码的实际机器码的解释)。
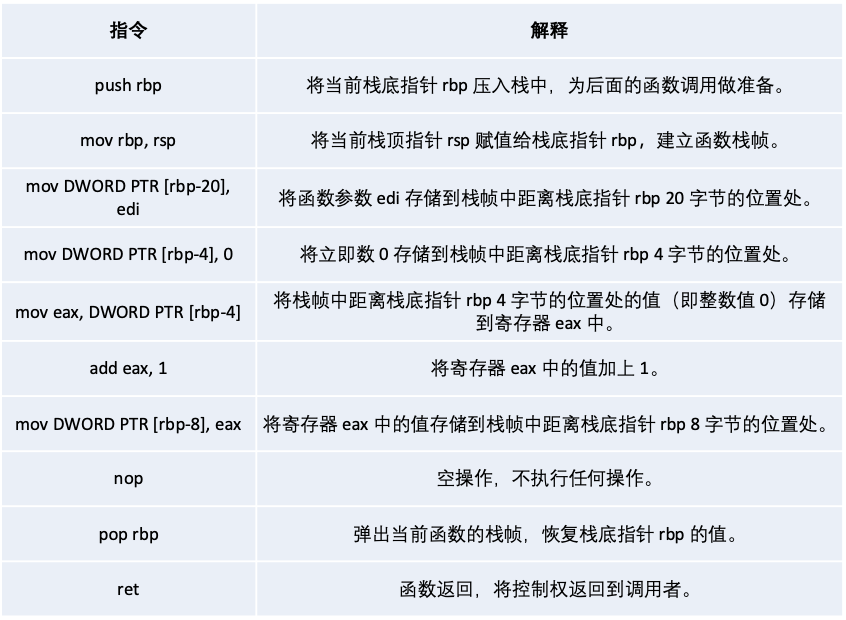
CPU 执行计算时,需要先将数据读取到寄存器,存取内存中的变量时,是直接操作变量所在地址及偏移量,而变量所在地址(即指针)也是存储在寄存器中的,因此寄存器大小直接决定了 CPU 所能访问内存的地址空间。因此,在 32 位系统中,寄存器的最大长度是 32 bit(即 4 个字节),因此最大支持访问 4GB 的内存空间,在 64 位系统中,寄存器最大 64 bit(即 8 字节)。而数据的指针由于需要指向整个内存空间,因此也就是 8 字节。8 字节大小的指针所能允许访问的最大地址为:16EB(16384PB=16777216TB=17179869184GB)的内存空间。
所以字长其实就等于寄存器的大小,指针为了能指向整个内存空间,通常也等于字长大小。
理解内存对齐
这是一段简单的 C 语言代码:
#includestruct Test { int a; char b; int c; } test; int main(void) { test.a = 1; test.b = 2; test.c = 3; printf("struct Test size: %d ", sizeof(test)); return 0; }
在 C 语言中,结构体数据是连续的,Int 为 4 字节,Char 为 1 字节,所以 Struct Test 为 9 字节。
但是实际输出结果却是 12 字节:


通过汇编指令可以分析出,结构体 Test 的内存布局如下:

可以看出,在 Char 类型数据后面被空出了 3 个字节的位置,原因如下:
计算机只能从 4 字节的整数倍开始寻址,如果在 Char b 后不进行空数据填充,则编译后的指令会很长,极大的降低 CPU 执行效率:
所以在 JVM 中,对象的存储也是如此设计:
class Test {
int a;
char b;
int c;
}
对象布局如下:
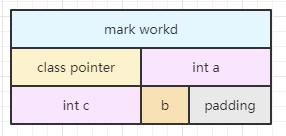
可以看出 Char b 数据后空出了 3 个字节的内存空间作为 Padding, 以供后面的对象进行内存对齐。
为什么计算机只能从特定地址读取数据?
计算机之所以只能从特定地址开始读取数据,是由于在内存中存储的物理位置导致的。

这是一根内存条,上面有 4 个内存颗粒(Chip),在我们声明一个变量 Int a = 1;时,CPU 想一次从内存中同时取出 32 位数据,为了发挥并行传输数据的能力,同时与 4 个内存颗粒进行交互肯定比一个内存交互要快,因此数据 a 分别在 4 个颗粒中存储 0x01 0x00 0x00 0x00。

每个内存颗粒 Chip 中有 8 个 bank,每次同时从 8 个 bank 中取一位数据。
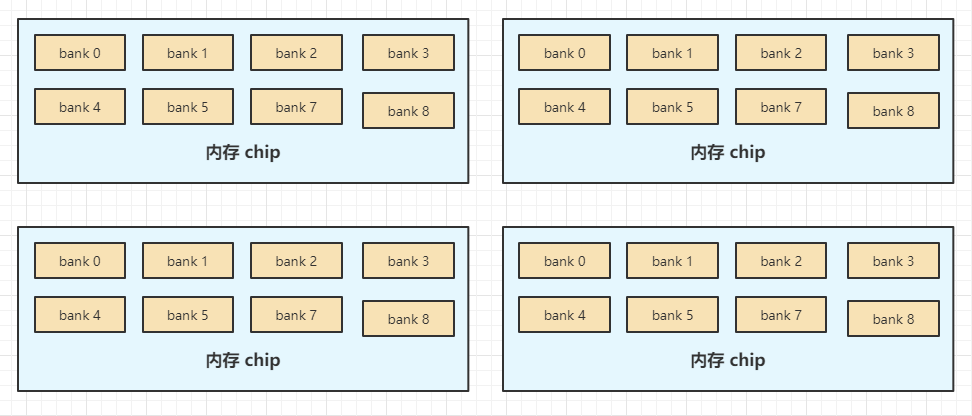
为了尽可能节约地址总线位数,变量 a 的每字节数据在各 Chip 中相对位置是相同的,每字节中的每位数据在 bank 中的行数和列数也是相同的。
总结,为了能利用有限的地址总线,尽量快速寻址到尽可能多的数据,在设计计算机时取了巧,CPU 同时只能访问 32 个相对地址相同的数据位,表现上就是只能从被 4 字节整除的地址开始寻址。
理解指针压缩
在 64 位系统中,JVM 为了降低 8 字节的指针对内存的占用,使用了指针压缩的技术,将 8 字节的指针压缩为 4 字节。
前面说到,JVM 出于性能考虑,对数据做了对齐到 4 字节的处理,因此指针的值末尾 5 bit 始终为 0B11111。JVM 的指针压缩算法就是,把本来应该使用 8 个字节的指针,直接改为 4 字节的进行代替,那么 4 字节的指针实际最高可以表示 32G 的内存空间。这也就是为什么当物理内存超过 32G 时,需要关闭 JVM 指针压缩。
三实战解码指针
工具介绍
HSDB
HSDB(HotSpot Debugger),是一个用于 HotSpot 虚拟机的调试工具。它提供了一种可视化的方式来查看和调试 Java 应用程序在 JVM 上的运行情况。HSDB 可以用于分析线程、堆、类、对象、方法、编译器和代码缓存等方面的信息。它还可以用于监视虚拟机性能和调试垃圾回收器。HSDB 是一个非常强大的工具,可以帮助开发人员更好地理解和优化 Java 应用程序的性能。
官方提供的 HSDB 命令行不是很好用,比如命令补全、命令提示、光标移动、命令历史记录等都不存在,所以本次分享讲利用 PerfMa 开源的 XPocket 工具,配合 HSDB 插件来操作。
XPocket 工具
XPocket 是 PerfMa 为解决性能问题而生的开源的插件容器,它是性能领域的乐高,将定位或者解决各种性能问题的常见的 Linux 命令,JDK 工具,知名性能工具等适配成各种 XPocket 插件,并让它们可以相互联动一键解决特定的性能问题。目前 XPocket 插件生态已经实现了 HSDB、JDB、JConsole、Perf、Arthas 等多个优秀的开源性能工具的插件化集成。
快速开始
下载 XPocket,然后解压运行。
wget https://a.perfma.net/xpocket/download/XPocket.tar.gz tar -xvf XPocket.tar.gz sh xpocket/xpocket.sh
# 切换至 HSDB 插件空间 XPocket [system] > use jhsdb@JDK # 启动 clhsdb 命令行 XPocket [jhsdb] > clhsdb # attach 到目标进程 XPocket [jhsdb] > attach 29516
利用 HSDB 查看 JVM 对象内存布局
准备工作
编写一个测试类,启动 JVM 进程。
@Data
@Component
public class BeanTest {
private long l = 1;
private BeanTest pointer = this;
private int i = 2;
private boolean b = false;
private char c = 3;
private BeanTest[] arr = {this};
}
想要查看对象的内存布局,首先要找到这个对象所在位置,JVM 的对象分布在堆上,可以通过 Universe 命令确定堆内的相关区域对应位置。
# 执行以下命令,切换至 HSDB 插件 XPocket [system] > use jhsdb@JDK # 启动 HSDB 插件 XPocket [jhsdb] > clhsdb # 通过 jps 命令,查询 JVM 进程的 pid,attach 到这个 JVM 进程 XPocket [jhsdb] > attach 29516 # 执行 universe 命令,查看堆内存分布情况 XPocket [jhsdb : 29516] > universe
内存分布情况如下:

括号内的第一个值为内存起始位置,第二个值为已使用的位置,第三个值为该区域最大地址。以上图 eden 区为例:
eden 区空间范围为:0x00000000fab00000 ~ 0x00000000fef00000,相减得到 71303168,68MB。
eden 区已使用空间为:0x00000000fab00000 ~ 0x00000000fafd2a60,相减得到 5057120,4.82M。
找到我们定义的对象
我们要找的对象是受 Spring 管理的,所以很容易判断,通常情况下都会在老年代里。那么我们直接在老年代内检索这个对象即可。由于 Oop(简单对象指针)是所有 Java 对象的基类,所以我们可以利用 Scanoops 命令来检索这个对象。
XPocket [jhsdb : 29516] > scanoops 0x00000000f0000000 0x00000000f1265ca8 com.poizon.robot.test.BeanTest
检索到的结果如下:
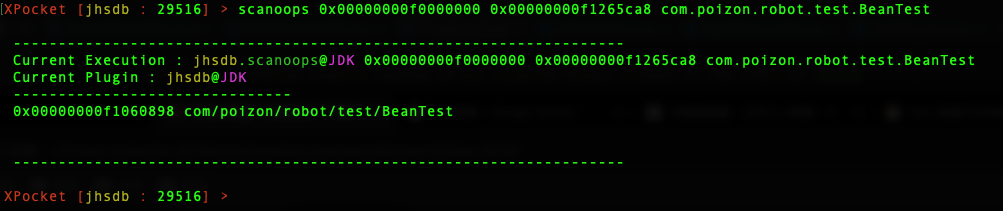
0x00000000f1060898 是这个对象实例的内存地址,也就是该对象的指针值。
查看对象内存布局
然后我们就可以通过 Inspect 命令来查看该对象的内存布局了。
XPocket [jhsdb : 29516] > inspect 0x00000000f1060898
得到结果如下:
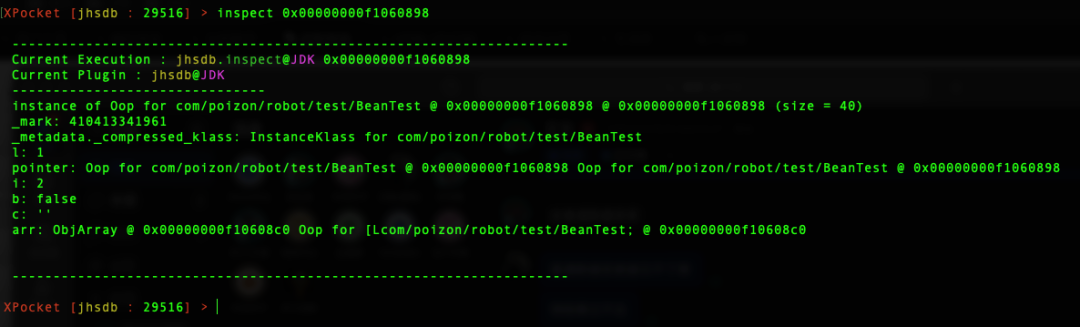
注意:这里显示的数据是按照类变量顺序来展示的,并非实际结构
由图返回结果可以看出, BeanTest 对象大小为 40 字节,当前系统为 X64 架构,一个字长为 8 字节,即此对象占用 5 个字长。执行 Mem 命令,获取整个对象(5 个字长)的数据。
XPocket [jhsdb : 29516] > mem 0x00000000f1060898 5
得到结果如下:
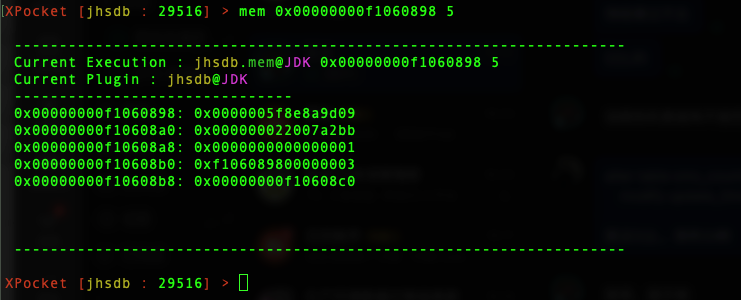
左侧为当前字长的数据起始地址,右侧为数据值。
我们再来复习一遍对象头(Oop数据),前 8 位是 Mark Word,后 8 位中,如果开启了指针压缩,则前 4 位为当前实例所在类的指针,后 4 位填充当前对象 <=4 字节的数据(Gap Padding);如果未开启指针压缩,则该 8 位为当前实例对所在类的指针。
查找类的指针
我们这次启动的进程开启了指针压缩,把第二个字长的数据(0x000000022007a2bb)按 4 字节拆成两部分:
0x00000002:BeanTest 对象中只有一个值为 2 ,所以该值是Int i = 2;
0x2007a2bb(类指针):前面说过,指针压缩的原理只是简单的把 8 字节指针削减为 4 字节,因为后 5 位始终为 0,因此若要还原压缩后的指针实际内存地址,直接把指针值 * 8即可。
BeanTest 类所在地址为:0x2007a2bb * 8 = 0x1003D15D8
执行 Inspect 命令,查看 BeanTest 类结构。
XPocket [jhsdb : 29516] > inspect 0x1003D15D8
结果如下:
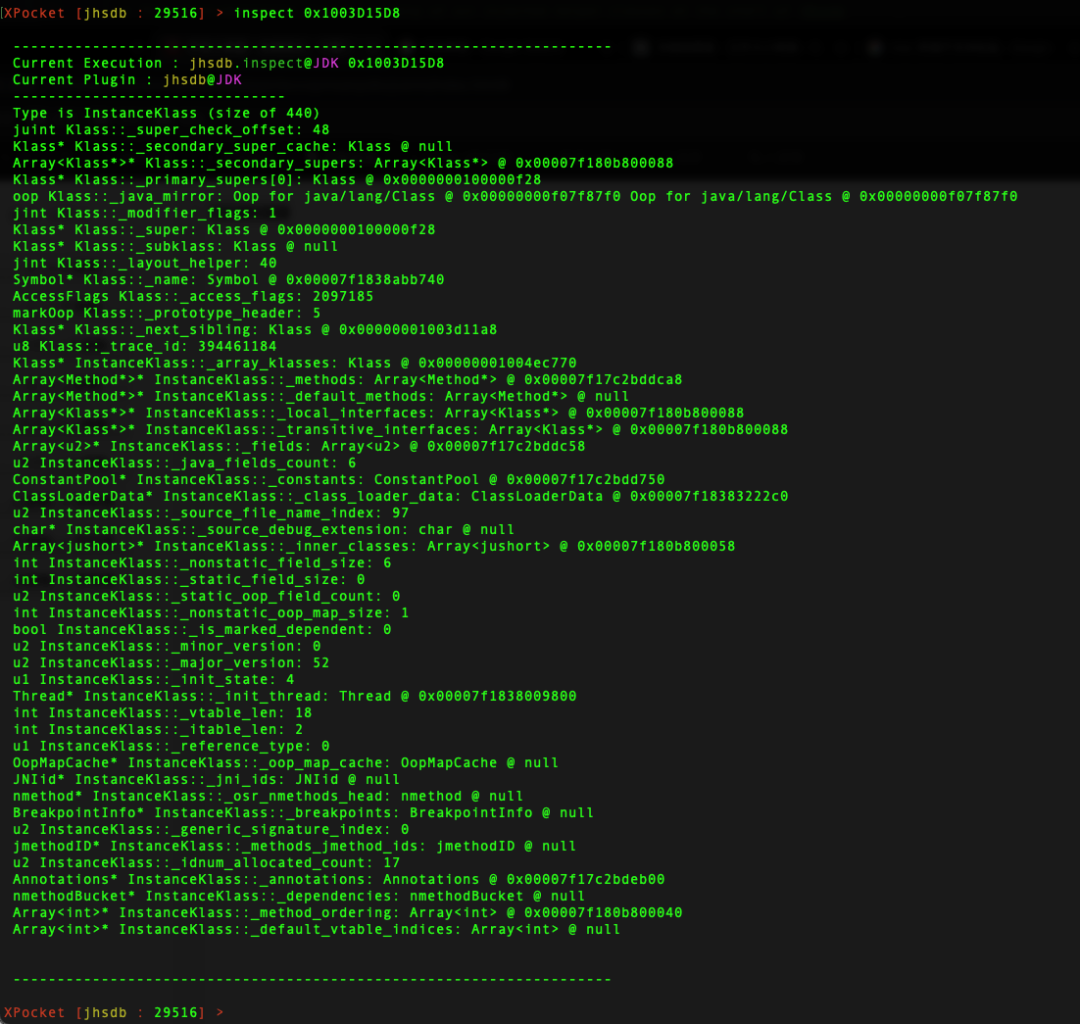
证实
BeanTest 在 JVM 对象为 c++ 的 InstanceKlass 实例,可以看出 _name 属性为 Symbol,接下来查看 InstanceKlass _name 属性,证实当前为 BeanTest 类的实例,执行 Symbol 命令查看 _name 的值:
XPocket [jhsdb : 29516] > symbol 0x00007f1838abb740
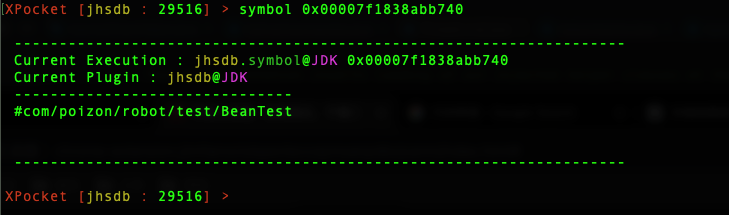
证实 0x1003D15D8 所在的内存地址,即是 com.poizon.robot.test.BeanTest 的 Class 对象。
四总结
在我们日常开发中遇到的一点小小的,看似不起眼的奇怪的规范,深挖之下往往能够牵扯出一大串知识体系,保持好奇心刨根问底同样也是很重要学习方法。有兴趣的同学也可以自己尝试找一下示例类中其他属性所对应的 Class 指针,说不定还可以对网上的一些文章做一次勘误呢~
审核编辑:汤梓红
-
计算机
+关注
关注
19文章
7837浏览量
93447 -
JAVA
+关注
关注
20文章
3005浏览量
116820 -
编程语言
+关注
关注
10文章
1965浏览量
39850 -
指针
+关注
关注
1文章
484浏览量
71949 -
JVM
+关注
关注
0文章
161浏览量
13084
原文标题:硬核 JVM 压缩指针详解
文章出处:【微信号:OSC开源社区,微信公众号:OSC开源社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
Jvm的整体结构和特点
什么是制冷压缩机,制冷压缩机的工作原理
Jvm工作原理学习笔记
压缩机工作原理
汽车压缩机工作原理
往复式压缩机的工作原理_往复式压缩机的工作过程
压缩机的工作原理
离心压缩机的工作原理是什么
螺杆式制冷压缩机工作原理 离心式压缩机和螺杆式压缩机区别
螺杆压缩机工作原理 螺杆压缩机的工作循环可分为
从原理聊JVM(一):染色标记和垃圾回收算法



评论