 低延迟SSD上的快速图处理
低延迟SSD上的快速图处理

一、背景
图处理在社交媒体、导航、推荐等领域应用广泛。很多场合下图数据往往非常大以至于难以在单个机器的内存中存储。分布式图处理选择将图数据存储在分布式集群的内存中;而与分布式图处理不同,外部图处理系统选择在单台机器上利用二级存储来辅助存储图数据,同时也能提供与分布式图处理相近或更优的性能。外部图处理系统根据存储方式可以进一步分为半外部系统和全外部系统。前者将图数据中的顶点数据存储在内存、边数据存储在SSD中;后者则将两者都存储在SSD中。本文提出的Blaze就属于半外部系统。
二、问题
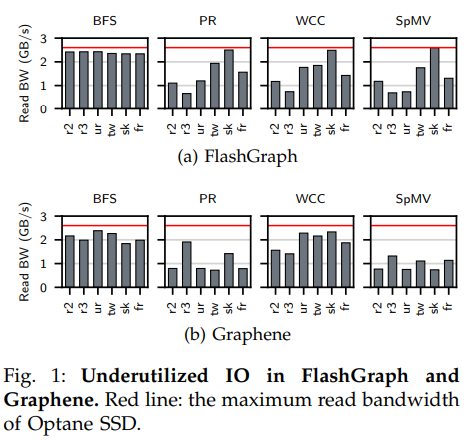
尽管现在新兴的快速NVMe SSD提供了比过去的SSD更高的带宽,但是现有的半外部图处理系统不能充分利用这些快速SSD带来的性能提升。本文通过实验(上图)发现主要问题为IO利用率低下,可以看出在两个代表性的半外部处理系统中除了BFS算法以外其他例程的执行中IO带宽(柱)都远未达到快速SSD的最大带宽(红线)。
本文作者认为IO利用率低下的原因主要包含3个方面:计算倾斜、IO倾斜、IO快计算慢。
1. 计算倾斜
并行图处理系统需要同步机制来避免并发更新算法相关的顶点数据时出现竞争。现有的半外部图处理系统FlashGraph采用消息机制来解决同步问题,它为每个顶点分配了一个消息队列,并按照顶点ID将每个顶点分派给一个计算线程。图算法迭代性地执行,在执行的每一个迭代中顶点间通过消息通信;在迭代结束的时候系统处理这些消息,并根据处理的结果更新顶点数据。
对于FlashGraph而言,由于图结构服从照幂律分布,一些线程需要比其他的处理更多消息,即计算倾斜。而(下一迭代的)IO必须得等待这种落伍线程完成处理才能开始。快速SSD在本轮迭代中的IO操作很可能比这个落伍线程完成的早,导致其空闲。
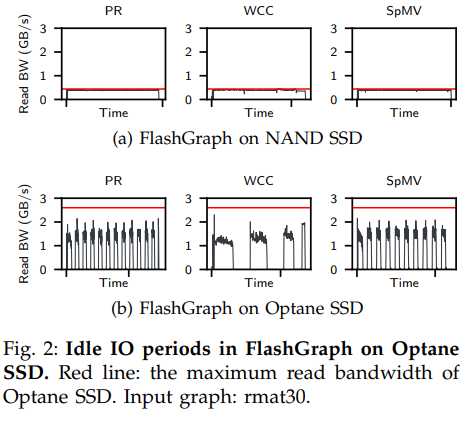
下图的实验证明快速SSD(Optane SSD)相较于低速SSD(图中NAND SSD)带来的带宽提升(红线为磁盘最大读取带宽)确实造成了上述问题,造成了IO更多的空闲。
2. IO倾斜
为了更大的容量和带宽,一些半外部图处理系统会将边数据分布在多块磁盘中。而当IO负载不均的时候显然会造成部分磁盘比其他磁盘完成IO更慢而造成其他磁盘的空闲。
另一个半外部图处理系统Graphene采用了一种2D图分区技术以将边均匀地分配到每个分区,并将这些分区均匀分布到多个磁盘上。尽管其分布均匀,但是Graphene在执行采用了边数据选择性调度的算法的时候仍然受IO倾斜的影响。
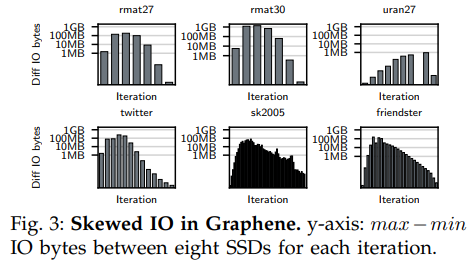
下图中的实验证实了上述问题,图中纵轴表示每轮迭代中各个磁盘间最大IO量减去最小IO量。尽管均匀分布的数据集可能有着低于1MB的倾斜,但对于其他幂律分布的图则有着最大可达100MB的倾斜。
3. IO快计算慢
Graphene为每个SSD分配了一个计算核心和一个IO核心,对于慢速SSD而言这样的设计可以最大化IO带宽;然而对于快速SSD而言这样的设计导致计算速度比IO更慢,IO填满缓冲区的速度比计算使用的速度更快,导致缓冲区填满后IO必须等待新的缓冲区。
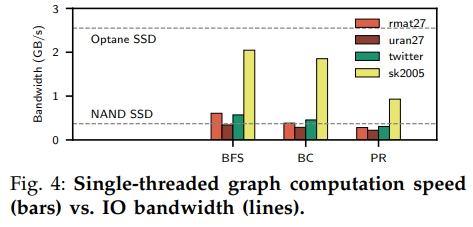
下图中的实验对比了计算的速度和存储设备的读取带宽,可以看出计算的速度比快速SSD要慢得多,证明了上述问题。
三、设计
1. Online binning
Blaze采用名为Online binning的机制应对计算倾斜的问题。Bin是存储在内存中的数据结构,存储了多条bin record,而bin record则是包含顶点ID和一个数值。Blaze在算法执行时根据目标顶点ID和用户定义的scatter函数的返回值创建bin record,然后对顶点ID取模计算出需要进入的bin ID。填满的bin被推入名为full_bins的并发队列,由gather线程取出处理。每个gather线程独自处理一个填满的bin,以避免同步开销。
2. 页面交织
为了应对IO倾斜的问题,Blaze采用了页面交织的存储方式来存储边数据。页面交织基本类似RAID 0的方式。Blaze将CSR格式存储的边数据以4KB粒度交织分布到多个SSD上。
3. Blaze整体执行流程
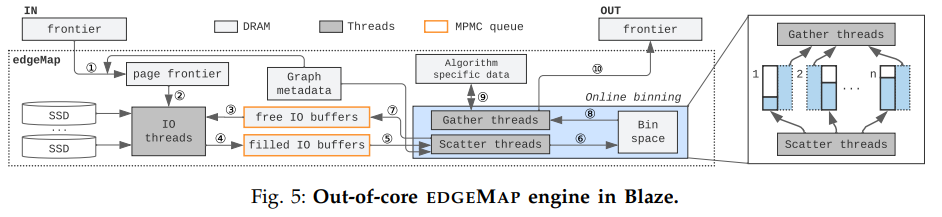
图算法一般按迭代执行,上图提供了Blaze中每轮迭代中的处理流程。
作为输入之一,算法程序会提供需要处理的顶点ID。为了接下来访问各个顶点的边列表,Blaze在第1步发动所有可用的线程将顶点ID集合转换成其边列表所在的磁盘页面ID集合(即page frontier内容)。转换完成后根据其磁盘页面ID从SSD中访问数据,写入到空的IO buffer中,生成满的IO buffer。Scatter线程取出填满的IO buffer,计算并生成bin record装入对应的bin,并将用完的IO buffer还给空IO buffer池。Gather线程取出填满的bin并处理,根据处理结果修改算法相关的顶点数据。最后返回下一个迭代所需要处理的顶点集合。
四、实验评估
1. 实验设置
实验测试平台是一台单处理器(Intel Xeon Gold 6230,20核心,禁用超线程),96GB内存的机器,存储配置了一块960GB的快速SSD(Intel DC P4800X)。
对比的算法包含:BFS、PageRank、WCC、稀疏矩阵乘(SpMV)、BC。
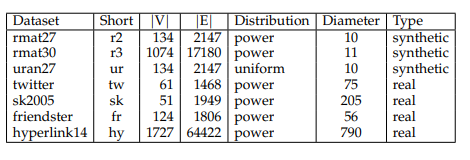
数据集如下表所示:
2. 系统对比
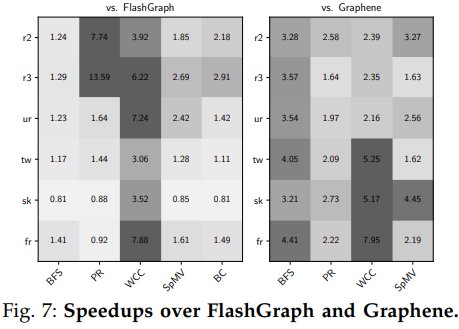
本文将Blaze与FlashGraph和Graphene分别作了对比计算了加速比,加速比如下图所示(Graphene没有实现BC算法所以没做对比)。除了sk2005数据集中FlashGraph表现更优以外总体都有一定提升。sk2005数据集上的处理有着更高的局部性,FlashGraph的LRU页面缓存借此减少了存储访问,而Blaze并没有针对页面缓存做专门的优化。
3. IO利用率
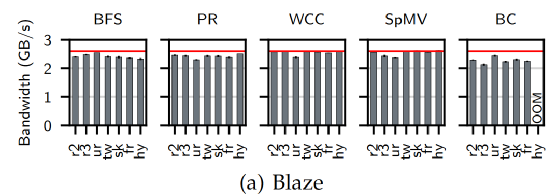
IO利用率的评估如下图所示,可以看出Blaze的平均IO带宽基本达到快速SSD的带宽。
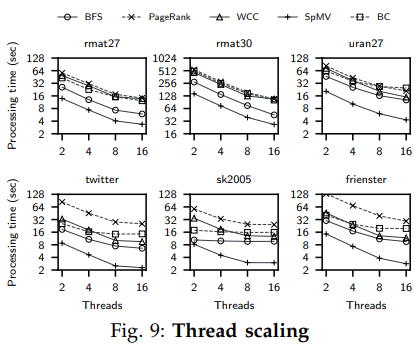
4. 可扩展性
实验表明Blaze的性能大致随着核心数的增加而线性增长,除了少部分负载下(如sk2005上的BFS)较快地饱和了IO带宽而不能扩张其性能。
五、总结
本文提出了一个新的半外部图处理系统Blaze。Blaze采用了全新的scatter-gather技术,online binning,解决了现有半外部图处理系统应用快速SSD后不能充分利用其高带宽的问题。
审核编辑:刘清
-
处理器
+关注
关注
68文章
20325浏览量
254694 -
CSR
+关注
关注
3文章
120浏览量
70887 -
SSD
+关注
关注
21文章
3147浏览量
122588 -
BFS
+关注
关注
0文章
9浏览量
2323
原文标题:Blaze:低延迟SSD上的快速图处理
文章出处:【微信号:SSDFans,微信公众号:SSDFans】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
DP83826:确定性、低延迟、低功耗工业以太网PHY的卓越之选
DP83826Ax工业以太网PHY:确定性、低延迟与低功耗的完美融合
DP83826Ax:确定性、低延迟工业以太网PHY的深度解析
兼容性高,延迟低,慧视定制CVBS接口AI图像处理板

巡检机器人落地攻略:RK3576驱动12路低延迟视觉
车载360环视平台:米尔RK3576开发板支持12路低延迟推流
新唐科技推出低延迟音频编解码器NAU88L21C

12 路低延迟推流!米尔 RK3576 赋能智能安防 360° 环视

游戏党的福音:支持ALLM自动低延迟模式的HDMI线推荐
延迟低至30ms+ LLSM流媒体传输模块低延迟方案推荐
明远智睿SSD2351开发板:语音机器人领域的变革力量
LLSM——基于RK3588的低延迟低带宽流媒体传输模块
XMOS直播声卡——可支持实时音频DSP处理的低延迟音频方案



评论