 未来人机交互趋势:多模态大模型
未来人机交互趋势:多模态大模型

目前,市面上的交互产品是以单模交互为主,尤其是语音交互。
语音类产品的形态主要为语音助手。语音可以带来比按键更便捷的体验,尤其是,在行车过程中可以避免分散驾驶员的精力。
长城汽车多模态技术负责人林俊告诉笔者:
在交互类功能中,我们现在真正上车的主要是语音交互。例如,主驾可以说“帮我打开座椅加热”,副驾说“我也要”,那么,车机就会同时打开主驾和副驾的座椅加热功能。
在上述交互中,副驾通过说“我也要”来“复制”驾说的“打开座椅加热”指令,从而实现和主驾相同的功能。假如主驾通过按键来实现座椅加热功能,那么副驾就无法“复制”主驾的指令。
视觉类产品包括了DMS、HUD等。
随着汽车智能化趋势的深入,座舱的智能化相关功能越来越多,对交互便捷性的要求也越来越高,然而,现在的汽车离“便捷的人机交互空间”还有很大距离。
一部分的原因在于,各个模态的技术仍然存在一些局限,在某些场景下无法给用户提供良好的体验。
还有一部分的原因在于,车内虽然有手势识别、眼动追踪、语音识别等各种功能,但用户在实际使用时,各个模块往往是独立发挥作用,各个传感器接收到的信息很难被统一整合起来,那么整体体验就总有些“差强人意”。
具体来说,问题主要体现在以下5个方面——
01 语音识别在噪声环境下无法满足精度要求
虽然语音理解并不难,但在噪声环境下,系统很难把噪音和要识别的语音区分开,语音识别的结果会变得不够准确。
02 语音助手很难进行多轮对话
目前的语音识别技术还不够成熟,用户在和语音助手对话的时候,尤其是在多轮对话的场景中,由于缺乏对上下文的联合解读,语音助手会显得不那么“聪明”。
03 语音助手和车机其他应用尚未打通
现在的语音模型和车机里的app没有“打通”,语音助手无从得知车机里安装了哪些app,也不知道车机屏幕上展示了什么内容,在这种情况下,语音助手就陷入一种“孤立”的状态。
天猫精灵在家居场景里的表现比在车端好,是因为天猫精灵与需要互动的家居产品,例如窗帘、灯等的交互链路很短且是确定的,那么当向天猫精灵发出“打开灯光”、“打开窗帘”等指令时,天猫精灵执行起来就会比较顺畅。
但是在车端,导航的地点和之间的LBS的信息,是不打通的,语音助手无法判断某个时刻应该在舱内现实地图导航的信息还是其他的应用,抑或时空调、座椅等的设置信息。那么在车端环境里,用户在要和语音助手交互时,就会感觉语音助手比较“弱智”。
04 视觉在某些情形下无法满足精度要求
简单地做一个人脸识别系统并不难,但假如希望把精度做到很高就会比较困难。假如把人脸的角度偏转几十度,系统有时就会识别错误。
有业内人士吐槽道:“现在车上DMS的提醒有时让人‘很懵’,我头真的偏向一侧的时候它不会提醒,但正常行驶的时候它反而会提醒。”
前段时间,一位驾驶员由于眼睛较小而被车上的DMS系统识别为“在睡觉”,引起了业内的关注。
05 视觉尚难以准确判断用户行为
当前的视觉识别尚难以准确判断用户行为,很难准确地判断出用户是否在打电话,是否在抽烟。
一 通过多模融合技术来解决单模态交互存在的痛点
1. 多模融合的定义
为了提升用户的体验,除了优化系统对每个模态的信息的识别能力之外,还可以将不同模态的信息整合起来,也就是采用多模融合技术,来为用户提供更好的体验。
2. 多模融合技术的应用
如何用多模态技术提升用户体验呢?
根据笔者与行业内专家交流得到的信息,目前在车端落地的多模融合技术主要应用于两个方面。
2.1限定语音交互的区域和范围
第一类是通过热区(热点区域)来限定语音交互的区域和范围。
目前的座舱大致分为十个左右的热区,包括了中控、仪表、左右车窗、后视镜、前挡风玻璃、HUD等。划分好热区后,工程师方便把语音指令定位到比较确定的区域(语音一般是全舱的)。
也就是说,在用户发出一个语音指令后,后台可以比较精确地知道需要调用哪些区域的传感器或者执行器来完成指令。例如,驾驶员说“打开车窗”,系统会自动打开左边的窗户,而无需驾驶员强调“打开左车窗”。
2.2让信号输入更精准
第二类是语音叠加视觉等其他模态的信息,来让信号输入更加精准。
例如,可以用视觉感知(包括唇语识别、唇动识别、手势识别等)作为语音的补充,在车内环境比较嘈杂时,系统也可以较好地识别用户的意图。
当车窗处于打开状态或者其他情形导致车内噪音较大时,语音交互的识别精度会非常低,相应地,召回率(即用户讲话时,语音助手应答的概率)也会变得很低。
传统的方式主要是采取过滤的方式来应对嘈杂的环境。
现在可以采用视觉信息辅助判断,用摄像头捕捉车内用户的唇语信息,系统就能在嘈杂环境中更准确地判断用户具体在讲什么。
此外,在车里有多人同时讲话的时候,例如,主驾和副驾都在讲话,结合主驾和副驾的唇语信息,系统可以将主驾和副驾的语音分离,从而判断他们分别在讲什么。
商汤绝影智能车舱产品高级总监李轲告诉笔者:
在开窗驾驶汽车的时候,语音助手的召回率可能会受到较大影响比较低。那么,假如仅借助语音这个单一的态,我们做人机交互的时候会面临很大的困难。商汤的视觉模型可以对座舱内的视觉信息做进一步的分析,包括驾驶员的眼部动作、面部朝向、唇动、唇语等相关信息。我们把这些视觉信息和语音信息做一个融合,在背景噪音较大的情况下,可以将召回率大幅提高,如此以来,用户体验可以得到极大的提升。
二 目前落地的多模态融合技术
目前已经在量产车上落地的多模态融合技术主要包括结果层面的融合(也叫后融合)、特征层面的融合(也叫前融合)。
1. 后融合
1.1后融合的定义
结果层面的融合,是主机厂拿到不同模态的信息处理后的结果之后,包括视觉算法的结果、语音算法的结果等,在逻辑层对这些结果做一些结合。
根据笔者与业界专家交流得到的信息,目前,各个模块通常是由不同供应商分别研发,然后把识别后的结果给到主机厂,例如,主机厂可能把语音识别功能委托给擅长语音识别的供应商,把图像识别委托给擅长计算机视觉的供应商。
通常来说,一家供应商仅擅长一个方向,很少有供应商既擅长语音识别又擅长计算机视觉。主机厂通常是从不同供应商处拿到不同模块处理后的结果而非特征,因此,目前市面上的多模态融合方案一般是采取后融合的方式。
一位行业专家告诉笔者:
假如主机厂能够把供应商处理后的各个传感器回传的信息处理好,也就是做好后融合,其实已经很大进步了。但很遗憾的是现在即使是后融合也没做好。有的主机厂会担心即使做好了后融合,用户也感受不到与不做的区别,用户感受不到明显效果的话汽车销量就很难被带动,那么这个投入产出比就不划算。
在已量产的车型上,后融合现在是行业内多模融合的主流技术。但是,它却被诟病“天花板不够高”,这是因为什么呢?
1.2后融合的局限
1.2.1 结果很依赖于单车调优
根据笔者了解到的信息,后融合非常依赖于单车调优。同一套语音识别算法可能可以用在不同型号的手机上,而无需根据型号分别调优。但是在车端,车的空间大小、造型设计等可能都会影响到语音算法的效果,因此,算法需要针对不同的车型分别调优,工作量也会相应增加。视觉算法也是如此,也需要针对不同的车型来调优。
1.2.2 对不同模态识别结果的一致性要求较高
后融合想要实现好的效果,每个单模识别都具备一定的精度。
有业内专家告诉笔者:
首先要保证单模是非常精准的,只有单模的精度达标,带给用户的体验好,我们才能谈多模。
在实践中,主做视觉算法的公司和主做语音算法的公司在做方案的时候各自有侧重点,不一定能完全根据主机厂的意愿来优化。假如提供视觉算法的供应商把结果优化地很好,但是提供语音算法的供应商优化得不够好,整体效果也会不好,反之亦然。
有业内专家告诉笔者:
最终能够做出用户体验非常好的产品还是需要全栈能力都要有。而且最好是能够通过端上来解决。因为端相对云来说延时很低,对信息的处理效率高。
然而,要具备全栈能力,需要很大的投入,假如公司体量不够大,就无力投入太多资源。并且,按照目前的市场情况,这样的投入可能无法迅速见效,那么对于公司来说,就是极不合算的做法。
1.2.3 容易丢失信息
后融合会丢失信息,很难把不同模态的信息做有效的叠加,因为它在处理过程当中就已经丢失了很多原始信息。
2. 前融合
2.1前融合的定义
特征层面的融合,是指供应商将不同模态信息的特征提取出来,然后用同一个模型训练,交给主机厂的是已经合成了不同模态信息的结果。
相对于后融合,前融合由于融合阶段更早,天然地存在一些优势。
一方面,由于是用一个模型训练,前融合能规避掉不同供应商的能力不一致或者优化意愿不一致的问题。
另一方面,由于在训练的时候包含了不同模态的特征信息,信息利用程度相对后融合更高。
那么在性能上,前融合方式一般比后融合更好,因为采用一个模型来处理语音和视觉信息,融合的程度更深,最终实现的效果更好。
2.2 前融合的局限
2.2.1 电子电气架构不一定适配
科大讯飞汽车智能交互总监章伟告诉笔者:
在多模的信号关联度很高,输出精度要求很高,以及信号同步要求很高的情况下,电子电气架构需要做一些调整来保障信号的同步。
2.2.2 芯片适配、算法优化的工作量大
另外,产品需要能够在不同的芯片平台上运行,包括高通、英伟达、ti 等,对这些不同的芯片做适配需要很大的工作量。
据悉,商汤绝影有一个大几十人的团队专门去做不同架构芯片和指定企业的适配,同时降低资源占用。为什么要降低资源占用呢,因为车企现在发展越来越多的功能,除了DMS等视觉识别系统之外还有音乐、地图等,而且仪表的功能会越来越丰富,那么车企就会希望每一家供应商的产品的资源占用率要尽可能低。
也就是说,我们不仅要适配各种各样的芯片,还要不停地降低资源占用,以前处理不同模态信息的模型可能占芯片算力的10%,现在需要降低到5%。
降低资源占用主要是从两方面入手,一方面是优化模型来降低模型对芯片算力及存储空间等资源的占用;另一方面就是针对芯片底层的指令集进行优化,去降低芯片的资源占用。
2.2.3 供应商不一定有全栈能力
还有一点是前融合需要一家供应商,同时把语音和视觉都做得比较好,这存在一定难度。而且前融合也不是在所有情形下都比后融合效果好,另外还有一些场景不需要融合。
2.2.4 主机厂的采购可能不适应
一位业内专家提到:
由于习惯原因,一些主机厂的采购会习惯性地分开采购语音算法和视觉算法。假如突然变成需要采购融合后的结果,采购不一定能很快认可。
就笔者了解到的情况来看,大家可能会在前融合这个方向投入一些资源来研发,但由于目前车上的架构做后融合更方便,因此真正落地前融合的厂商不多。
地平线由于具备视觉、语音等全栈能力,是目前少有的有量产落地前融合方案的厂商。
然而,不管是前融合还是后融合,本质上都是基于两套逻辑的组合。
这样组合会带来两个缺点,一个是组合的逻辑是人为定义出来的,很难被普适得认可。
在客户认可组合的逻辑时,这样做不会有什么问题。但如果客户不认可组合的逻辑,可能供应商就需要重写组合逻辑。
例如,假如供应商给a厂商提供了一套前处理或者后处理的方案,这个方案到了b 厂商可能会被否决,因为厂商可能要追求产品的差异化,那么在处理不同模态信息时可能会有侧重,这样很难将一套方案复制到很多车型上,需要的工作量很大。
第二个问题是基于规则的组合很难避免生硬,即使花费很多精力,可能也只是让组合变得更完善了一些。
中科创达座舱产品线总经理赵锐告诉笔者:
我们不会走前融合或者后融合的路线的东西。我认为过渡态的内容,虽然是一个卖点,但我们是做产品的,要看终局。
第三个问题是基于规则的组合会对交互场景有限制,降低用户体验。
每一次大型的智能终端的变革,都伴随着人机交互方式的升级。早期PC主要依赖鼠标加键盘,智能手机依靠触屏。触碰这一交互方式不适合用于车端,到了智能汽车时代,驾驶员的手和眼都被占用了,在这种情况之下,就会以这种自然交互为核心。所谓自然交互,最简单的就是语音交互,然后辅以视觉,例如手势等。
在这样的交互方式中,假如要通过逻辑来限定一些场景和一些具体的交互措施,会给用户负面的体验。
多模态应该是一种能力,而不应该是一些设定好的一个规则。
用户在使用过程中会识别到更多更有趣的东西,假如用户只能在有限的几个场景里体验多模态技术,在其他场景中无法使用,这会给用户带来一种很割裂的感觉,整体的体验并不好。
假如不希望采用基于规则的组合,可以如何整合不同模态的信息呢?
答案是采用多模态大模型做模型层融合。
三 模型层融合
1.模型层融合的定义
模型层面的融合,是指训练模型的数据,既可以有语音数据的,也可以有图片数据的,以及其他各种各样的模态的数据。相当于融合的阶段更早,在数据这一层就已经开始融合了。
2023年3月,微软发布了Kosmos-1,一种MLLM(多模态大语言模型,Multimodal Large Language Model) ,模型的参数总量为16亿。Kosmos-1可以接收不同模态信息的输入,包括文本、图像、语音等,可完成语言理解、视觉问答、多模态对话等不同类型的任务,如下图所示。

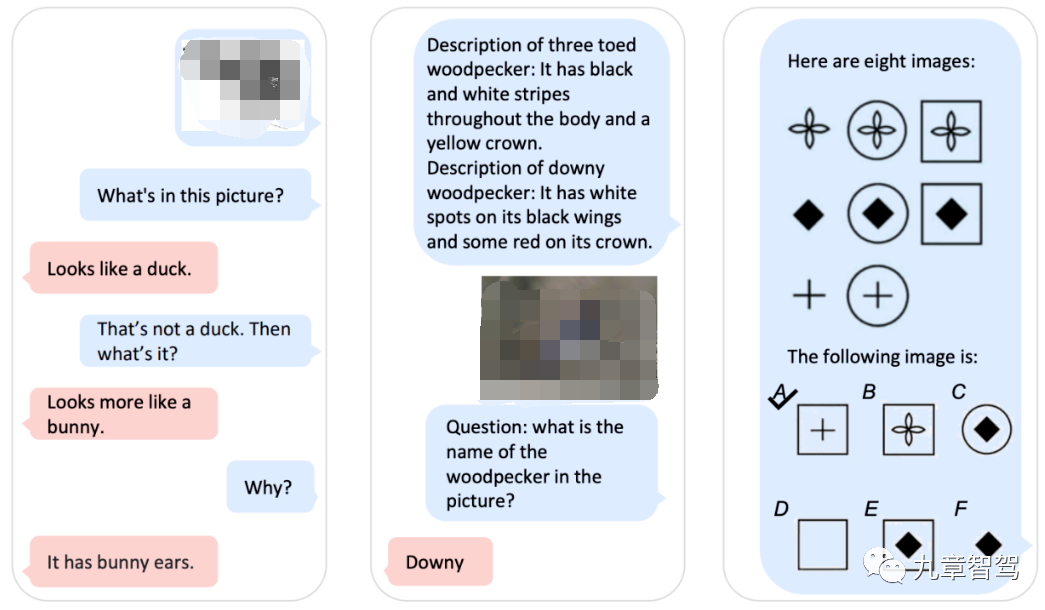
Kosmos-1的主干是一个以Transformer为基础的语言模型,自然语言以及其他模态的信息都会被处理成统一的格式输入到Transformer decoder中。
在输入中,研究人员采用和来分别代表一个序列的开头和结尾,
下图列出了几种不同的输入信息,包括文本、图片以及文本和图片的混合信息。

Kosmos-1的提出给人机交互带来了新的可能,虽然离大规模落地还有一定的过程。
商汤绝影智能车舱产品高级总监李轲告诉笔者:
只有把语音和视觉融合在一起才能叫多模,商汤的特色就是大模型和多模态的融合。
有了多模态的能力,车辆就可以收集动态信息,包括语音的、视觉的,然后综合地图上的信息,可以实现对车内驾乘人员的主动推荐功能。
主动推荐是一个关键的提升。以前,我们通常是直接下达指令,告诉车机我们需要什么,例如要车机帮忙打开车窗、打开空调、美食推荐。
现在,我们可以让车机根据用户当前的状态和一些习惯“主动”地做一些推荐,例如,在用户开车上班途中,为他/她推荐吃早餐的地点。
某业内专家告诉笔者:
我认为模型层面的融合是比较接近自然交互的终极状态,相当于我们是直接去走终极的路,而不是先做一个过渡态。
为什么模型层融合是自然交互的终极状态呢?在模型层做融合具体有哪些优势?
2. 在模型层做融合的优势
2.1 更贴近人的习惯
从第一性原理来说,从模型层面融合更贴近人与外界交互的方式。
人与外界交互时,是一边听一边看,同时接收听觉、视觉以及其他感官的信息,然后形成综合的判断,而不是通过视觉做一个判断,然后再通过听觉再做一个判断。这就类似于多模态模型接收不同模态的信息输入,综合处理之后输出结果。
2.2 更充分利用信息
有了多模态的模型出来之后,我们就不用考虑是要前融合还是后融合的问题,可以直接在模型层面融合,也就是说,视觉信息、语音信息等不同模态的信息可以同时输入模型,模型可以直接对不同模态的信息做处理,可以不用担心在中间处理过程中信息丢失的问题。
某业内专家告诉笔者:
模型层面的融合效果会比较好,它可以从多个维度提取一些比较深度的信息。
2.3 更方便持续学习
多模态大模型具备上下文学习(in-context learning)的能力,在接入一个场景之后,可以根据该场景的数据持续学习。
例如,多模态大模型接入了github之后,它就能学习代码的一些逻辑,包括如何生成代码、如何给代码编译做查错处理等,它接入到office全家桶之后,文本编辑能力就大幅提升。
也就是说,随着模型接入越来越多的不同模态的信息之后,它就会有更进一步的训练,更好的强化学习的能力。在这种情况之下,它本身就是可以“生长”的,而不是通过人定义的a、b、c、d等规则来实现。
大模型不需要人为地定一个规则,只需要喂给它数据,它可以根据数据自己学习如何融合不同模态的信息。
并且,经过了十多年的发展,无监督训练已经相对成熟,未经标注的数据也可以作为多模态大模型学习的“素材”,也就是说可以用来“学习”的数据大大增加。这非常有利于模型能力的进化。
在实践中,多模态大模型可以如何落地呢?
3. 如何用多模态大模型实现自然交互
中科创达座舱产品线总经理赵锐告诉笔者:
我认为chatgpt可能会成为一个场景中枢,语音识别、视觉识别等算法可以由供应商提供,具体和用户如何互动,例如屏幕上需要投放什么内容,根据与用户互动的数据持续更新需要大模型来做,可以依靠云端的算力来做一些比较深度的处理。当然了,在车端信号不好,也就是通信时效无法得到保障的时候,可以用一个简单的小模型来过滤。
相比起自动驾驶,业界普遍认为多模态的能力会先被集成到智能座舱,在座舱中可能会出现一到两个爆款的场景应用,让用户都能够体验到多模态技术带来的好处。
在实践中,可能会做成一个产品引擎的方案,这个方案会分成几层。
底层就是各种感知信号的输入源,包括视觉类的、音频类的、账户类的、第三方信息类,以及用户身上的一些展示信息。
底层往上是策略层,策略层按照发展历程又分几个阶段。
第一阶段主要是偏固定脚本编辑式的,这样的方案已经在给主机厂做场景方案的时候落地了。
在这样的方案中,我们可以预设几个场景。例如,用户出门工作可以定义为一个场景,在这个场景中,车机可以预先打开空调,预设一下导航查看路况。也就是说,只要用户一键触发这个场景,与这个场景相关的任务都会被自动执行。
到了第二个阶段,是结合推荐算法来使用。也就是说,产品经理希望在车端的app中使用推荐算法,主动为用户做一些推荐。
但是目前这个功能还并不好用,因为车端的各类数据相对独立,车机实际上并不太理解用户。因为车的 id 和普通 app的 id 是不一样的,车载的信息都在主机厂。主机厂一般不会对供应商开放数据,所以车端app的推荐不如抖音、头条等“合乎用户心意”。
到了第三阶段,是在车端用上多模态大模型的能力,让大模型主动抓取不同模态、不同来源的信号,从而实现和用户的自然交互。前文提到的商汤绝影根据用户当前的状态和一些习惯“主动”地做一些推荐即为此类。
然而,在当前的市场环境下,用户还很难为多模态产品买单。除了长安的UNIT-T车型在宣传的时候以多模态产品作为卖点,其他厂商在宣传过程中很少会突出多模态。
chatgpt的出现可能会给这个行业增加一些新意,以后用户可能可以真正感受到多模产品带来的体验的提升,然后用户才会愿意为之买单,那么这个行业才会进入一个爆发的时点。
4. 目前多模态大模型在应用方面的局限
愿景是美好的,但实践起来可能是困难的。目前,虽然很多业界人士都认为多模态大模型可能是“未来”,但目前车端的大规模落地尚未实现。多模态大模型在车端落地可能会存在哪些困难呢?
4.1 训练数据尚缺
在基于多模态大模型的产品在车端没有形成成熟生态的时候,训练模型用到的数据都是基于其他行业的。不管是语音还是视觉的数据,都是基于目前已经大规模落地的产品方案来获取的。但假如我们希望多模态大模型在车端能实现很好的效果,需要很多车端的数据来帮助训练。
目前,主机厂对用户的的数据有较强的隔离,不会随便开放。有的主机厂会给供应商提供一个账号,然后让供应商去训练,但是数据的所有权仍然属于主机厂。
这对后续的形态会有很大的挑战,包括迭代的速度、功能体验的提升。
另一方面,大模型在车端的落地尚处于非常早期的状态,因此这一部分的训练数据较为稀缺。我们可以看到文心一言一开始在做图片的编辑生成的时候,例如生成“胸有成竹”、“夫妻肺片”等对应的图片时会就出现一些令人啼笑皆非的结果。
原因是工程师在开发这些场景的时候,没有考虑到用户这么玩儿。这一部分对应的冷启动期间的预训练,或者说是初步规则的制定还没有达到一定的量级。
某业内专家告诉笔者:
目前主要是大家还没有形成共识,很多厂商可能抱着一种先小规模测试一下,结合用户的反馈信息来决定接下来该如何决策。现状更多的是一个令人振奋的新东西出来了,大家觉得这是未来的方向。那么,我们先把它实现出来,让用户开始习惯新的方案。前方的路比较确定了,只是过程中还存在一些难题,但我相信这些都会被解决的。
另外,在车内采集数据会涉及到隐私问题,厂商可能需要做一些脱敏的方案,例如不需要把整段语音都上传到云端,而是可以做一些特征点的裁剪,来做语料的补充。
或者端侧部署的方案,也就是说,大模型本身可能是一个公版,但是交到每一个厂商那里时会有一个定制版,或者说是封装的一个版本。
4.2 车端信息庞杂
车里的信息是很多的,而且座舱是一个很大的市场,同时也是一个很大的挑战,这背后很重要的点就是汽车是目前人类社会上最大的智能移动终端,大、智能、移动这几个关键词都很重要,汽车的这些特点决定了我们在设计产品的时候安全是第一位的。
叠加了大以及可移动这些属性之后,汽车这个智能终端就和很多其他的终端(例如手机)很不一样。手机只有一个屏,所有内容都从一个屏输出,而且手机的传感器感知的内容特别少,主要就是语音、视觉、gps定位信息等。
但是在车端,即使不算上车身的气垫等,传感器数量就大概是手机里的十倍以上。而且座舱内的很多部件自由度很高,可以改造的余地很大,座椅、氛围灯等都可以改造,还有一些新的交互方式例如HUD、VR等在上车,在这样的背景下,工程师希望用一个统一的模型来做场景开发就会比较困难,因为输入越多,挑战就越大。
在智能家居里做一个天猫精灵是容易的,但是在车里做一个ai 助手很难,因为信息太杂。
4.3 大模型的使用门槛较高
现在使用大模型的门槛不低,例如最近有很多用户的gpt账户都被封掉了。这本质上是因为目前的网络基础设施承载不了大规模的访问。
另外就是可能会涉及到泄密,因为它的爬虫可以抓取很多数据,后面登录的用户可以看到之前登录的用户的信息。这样会比较危险,因为用户尚不清楚它到底会抓取什么数据,以及如何处理抓取的数据。
在此次采访中,笔者不止一次听到有厂商在和微软或者其他一些具备通用大模型能力的公司洽谈合作的消息。据悉,有的公司已经开始尝试将大模型应用在座舱上,并且已经拿到某主流主机厂的定点。
假如过程顺利,也许我们很快就能体验到更智能的座舱,届时,汽车上的人机交互可能会进入一个新的时代。
编辑:黄飞
-
传感器
+关注
关注
2577文章
55506浏览量
793964 -
人机交互
+关注
关注
12文章
1299浏览量
58132 -
手势识别
+关注
关注
8文章
232浏览量
49299 -
语音助手
+关注
关注
7文章
243浏览量
27647 -
大模型
+关注
关注
2文章
3771浏览量
5273
原文标题:多模态大模型会是未来人机交互的方向吗?
文章出处:【微信号:阿宝1990,微信公众号:阿宝1990】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
大模型驱动下的人机交互革命,“超拟真人互动” 让玩具读懂你的情绪



评论