 ASR算法实践及部署方案
ASR算法实践及部署方案

一
引言
语音识别(Automatic Speech Recognition)是AI领域的一项重要应用,是一种将人的语音转换为文本的技术。
其主要的应用场景有:单独使用该技术的字幕生成,会议转写以及联合语音合成技术使用的智能助手、智能音箱、智能汽车等。
其中字幕生成包括视频的离线字幕生成以及直播场景下的在线字幕生成。随着短视频和直播场景的兴起,我们对自动字幕的需求也越来越大,这对推理GPU的速度、延时和成本也是很大的挑战。
本文将介绍ASR模型工作原理,离线字幕生成场景优化,以及ASR在沐曦曦思N100人工智能推理GPU上如何做静态部署,后者可作为其他序列生成模型的静态化部署参考方案。
二
ASR模型介绍
一般声音声波输入声学模型前,会将语音预处理转换为梅尔图谱,即将声音以一定的帧长切成短帧,然后使用傅里叶变换得到频谱,依照人类对不同频率音频的敏感程度不同,频谱又经过梅尔三角滤波器组,最后得到信息密度更高的梅尔频谱作为ASR模型的输入。
为了解决从梅尔频谱到文字的对齐问题,学界有两种对齐方案:
对齐方案 1
不学习对齐,允许空格和重复输出,直接在计算损失时使用CTC 损失得到规整后为正确结果的所有路径概率和,让概率和最大。本方案为非自回归方案,速度快、易训练,但由于不考虑上下文,其结果容易造成结巴或漏字。
对齐方案 2
用序列到序列编码器-解码器的方式学习基于注意力的语音文字软对齐。本方案为自回归方案,考虑了上下文,精度更高,但对齐灵活性容易被干扰且解码速度更慢。
目前效果较好且比较流行的语音识别端到端模型的一般结构是结合前面两种方案,即把两种模型放在同一个模型结构中,共享编码器部分,以wenet模型[1]为例,其训练时的数据流向为:
1
用语音预处理从语音波形中提取梅尔图谱特征。
2
以conformer模型作为编码器(绿色),进一步提取和融合输入特征。
3
注意力解码器部分(红色)在训练时为编码器后接入一个基于注意力的解码器,在只能看到历史信息的掩码限制下生成目标句子,再对每个字得到平滑交叉熵损失。在前向推理时,利用编码器输出和历史解码器结果自回归生成下一个文字。(红色部分)。
4
CTC 解码器部分(黄色)在训练时为编码器后接一个全连接层再接CTC损失,利用CTC规避训练时的语音文本对齐问题,在前向推理时每帧得到空格或文字,对生成结果规整后即得到目标语句。CTC 解码器在前向推理时可以结合语言模型如n-gram语言模型一起使用,提升正确率。
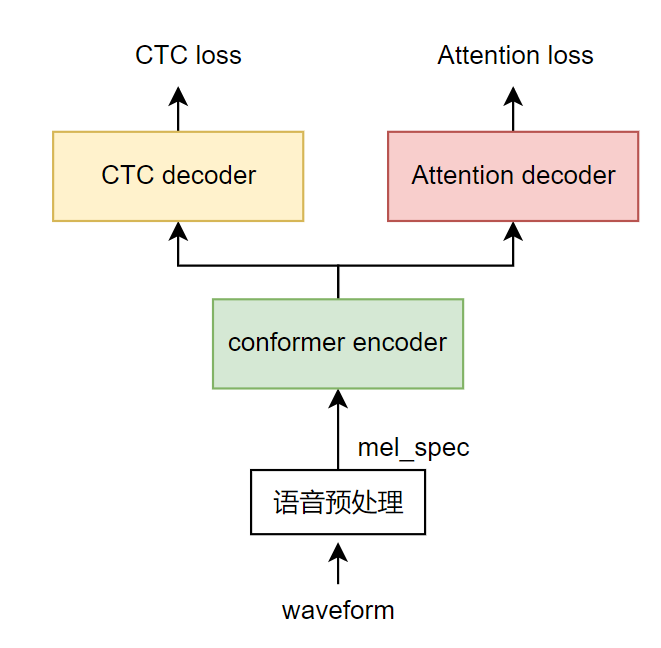
图2 ASR模型结构介绍
由于CTC head加ngram语言模型和注意力head均能生成结果文字,在落地使用时有多种解码方式:
解码方案 1
直接以CTC head结果为准,这种方案解码速度很快,但正确率较低。
解码方案 2
CTC head生成概率最高的topk句,由注意力 head分别为多句进行评分,即整句每个字概率加和,选出top1的句子,这种方案正确率高于方案1,速度慢于方案1。
解码方案 3
注意力head每个字生成后,结合该字在CTC head的分数共同评估,得到当前时刻的top1的字,这种方案正确率高于方案2,速度慢于方案2。
从方案1到方案3,正确率越来越高,解码速度越来越慢。使用时可根据实际场景选择。为确保正确率,一般采取后两种方案。
三
字幕生成链路改进
经过调研和实验,我们尝试了一些让生成字幕准确率更高的方法,以下为完备有效的链路:

图3 字幕生成链路
从视频提取到音频后,先使用传统方法对背景音乐和噪声进行去除;然后启用长音频切分,即利用深度学习方法检测人声,在合适的没有检测到人声的地方把长语音断成许多短语音;接着将短语音送入ASR声学模型,在热词的辅助下输出识别结果;最后将结果送入纠错语言模型进行一些简单的词错误纠正,得到最终的字幕文件。以上各模块均能发挥一定的作用。
以下是链路中模块加入前后的示例:
音频原识别结果改进后识别结果改进原理
那这样吧今天下午我来拿情脸那这样吧今天下午我来拿行李前置去背景音乐模块后ASR模型就能正确识别最后两个字
不过你也知道我大姐的脾气,他向来不主张明家的子弟去搞政治不过你也知道我大姐的脾气,她向来不主张明家的子弟去搞政治原音频为两段,通过VAD后聚类后两段合成一段,使得模型有更多前后信息,“她”字识别正确
喂清云我错了喂清俞我错了加入的热词中有角色名,解码时优先热词,“俞”字识别正确
下将具体介绍我们在长音频切分模块和ASR模型解码模块做的一些改进。
3.1
长音频切分优化
长音频切分模块中,我们通过使用深度学习模型marblenet做语音活动性检测,即判断每一帧是人声还是环境音,并通过模型蒸馏、构造数据、加入更丰富影视数据等提升分类精度。
在得到帧分类后可通过设定pad_onset, pad_offset, min_duration.max_duration等参数找到切分点,把长句切分成多个短句,可根据实际需要调整以上参数数值。
同时由实验得到,多个相关短句合并成小长句后识别效果常好于单个短句,原因是在解码时能利用上文语义信息得到更好的结果,但太长又会导致耗时和显存增加。故在切分准确的基础上,我们通过一维时间聚类的方式,将距离较近的短句通过多轮融合,形成限定长度内的小长句进行识别。
具体的合并逻辑是所有短句按照由短到长的优先顺序,每个短句左右扩张pad_len,若触达另一短句则合二为一。以上逻辑重复多次,pad_len也慢慢增大。同时在合并过程中如果长度达到max_len则也不再扩张。

图4 短句聚合逻辑
以上逻辑能在合理范围内,把时间上靠近的短句集合合成一句长句,有利于在解码时语言模型的信息获取,使识别结果更加准确。
3.2
ASR模型及解码参数优化
在电视剧场景中使用ASR模型首先会碰到背景噪声问题,我们在模型方面也做了微调使得ASR模型对噪声更加鲁棒。具体的做法是取部分训练数据,在训练时原语音随机添加上脚步声、人群嘈杂声、环境声等噪声数据,利用这些数据对原始模型进行微调,微调后字幕CER减少0.07%左右。
同时,我们在CTC解码时使用上了4_gram语言模型,以下是一些字幕生成场景下ASR模型解码参数调整经验:
1
电视剧涉猎较广,如古装电视剧常出现成语,商业电视剧常出现经济用语等,可根据实际需要针对性地增加4_gram语言模型的训练语料。
2
也可把上述4_gram语言模型换成bert或者加入bert,能提升一些识别正确率但是严重影响解码速度,故工程上还是建议4_gram语言模型。
3
电视剧语气词较多,若要保留这些语气词,防止使用语言模型后语气词消失,需调高识别成空格的阈值,blank_skip_thresh可设为0.99。
4
与上同理,为保留更多语气词适当增加WFST解码时声学模型的概率,acoustic_scale可设为2。
5
为让热词发挥更好的效果,可适当调大热词权重,context_score可设为10。
总的来说,在影视剧字幕生成领域中,我们发现长音频切分的好坏对字幕结果起到了决定性作用。同时将wenet模型用于部署时可根据使用场景对模型或者解码参数进行一些微调,能在目标领域变得更加准确。通过以上改进再加上链路上的前后处理,我们测试集上平均字错率由16.57%下降到12.11%。仅从识别准确度看,比当前最好的商用软件效果略好。
四
ASR部署
出于对推理速度的要求,一般需要将训练好的模型部署在GPU上使用, ASR模型输入shape是动态变化的,为达到静态化部署的目的,这里采用padding-分桶思路来支持动态输入,本方案对其他编码器_解码器类生成式任务的静态化部署都有借鉴意义。
在ASR中,输入的语音长度是变化的,即编码器的输入输出,CTC 解码器的输入输出以及注意力解码器的输入输出都是变化的,中间特征的长度会随着输入语音长度的变化而变化。
为固定输入长度,我们将输入语音pad到最长语音长度max_speech_len,之后用mask控制计算的范围,同时使用注意力解码器时也把历史文字输出pad到最长文字长度max_word_len,之后用valid_len来表示本次前向要生成的文字编号。具体来说,需要对编码器编码模块和注意力解码模块做一定的调整。
实践使用中,可以设置多个梯度max_speech_len,实际使用中按照输入语音长度分桶,用对应最大长度模型解码。
4.1
encoder模块部署
其中,encoder的具体模型结构如下:
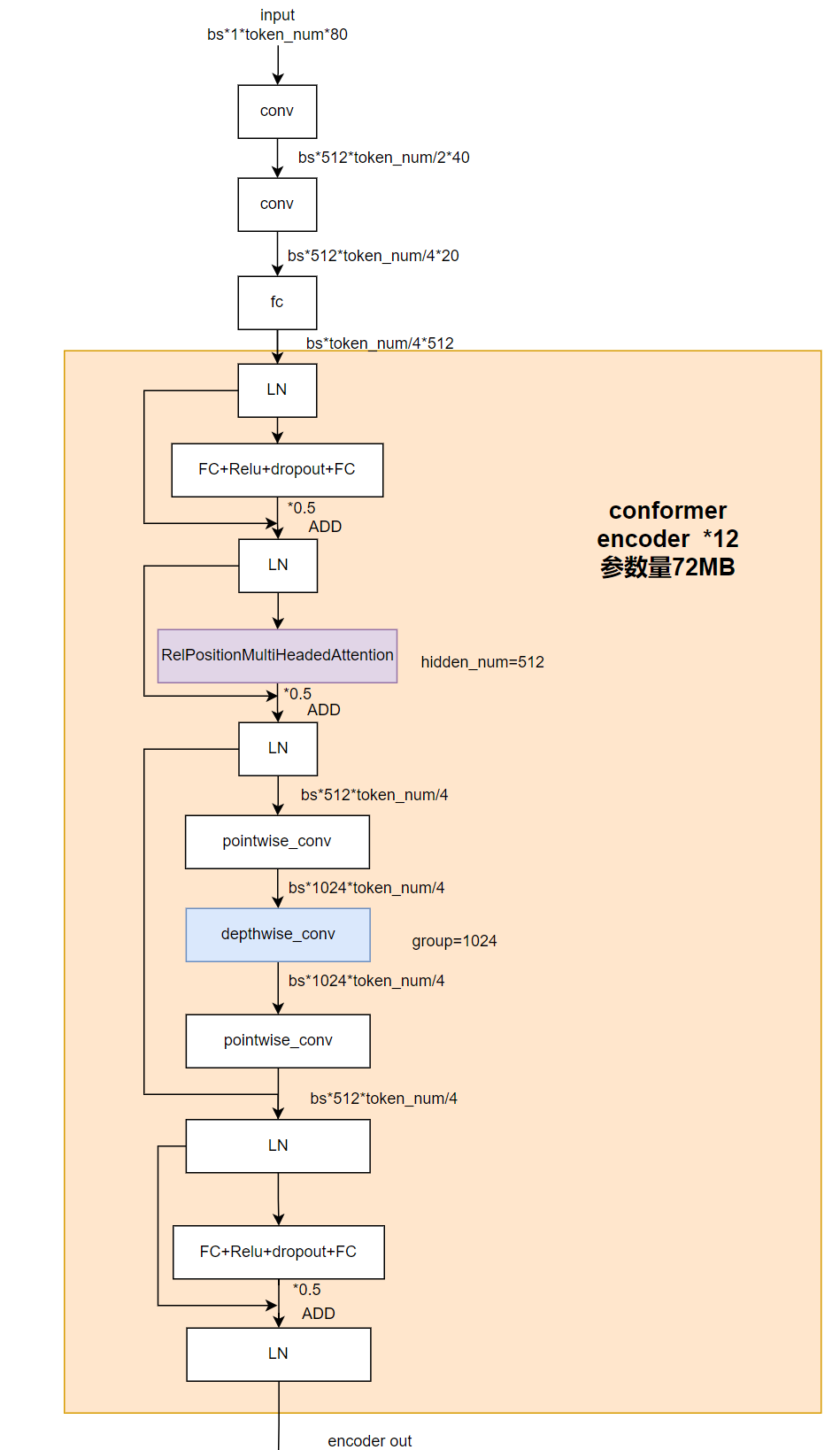
图5 encoder部分细节结构图
其中token_num取决于输入语音的长度,是可变的,为剔除动态性我们将该维度pad到最大,但是直接padding会影响softmax计算和conformer结构里相对位置编码以及depthwise卷积部分,为了消除对计算结果的影响,需要对模型结构进行微调。
4.1.1
消除Padding对softmax计算的影响
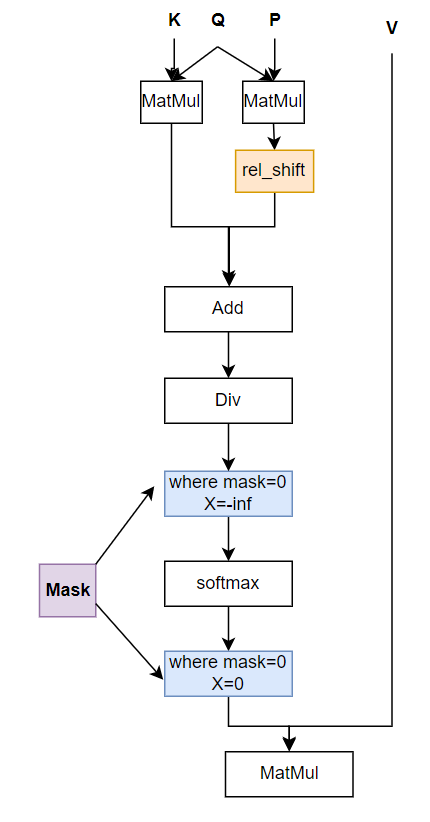
图6 encoder部分RelPositionAttention模块前向图
模型的输入改为:
input_pad:pad后的input
mask:记录了input_pad中有效的长度,其中mask的前valid_len个为1,后面为0
mask中包含有效长度信息后能去除掉计算中pad部分的影响。
4.1.2
消除Padding对rel_shift的影响
如上图中所示,espnet工程中matrix_bd会先经过rel_shift来达到把matrix_bd中绝对位置编码改成相对位置编码的目的,原代码的实现方式为:
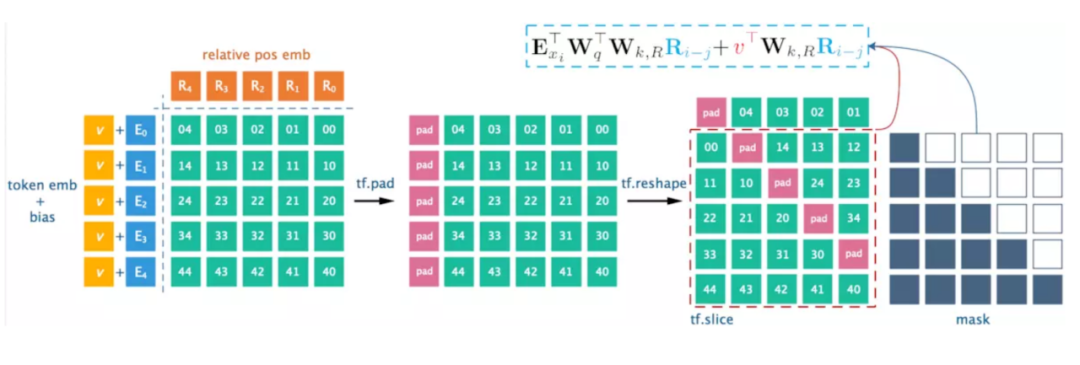
图7 rel_shift 实现方式
来源:https://zhuanlan.zhihu.com/p/74485142
通过对矩阵的pad+reshape达到相对位置编码的作用。
输入作pad填充后token_emb后面为无效特征,再用pad+reshape方式rel_shift,会导致无效特征前移错位。
我们这里先分别用gather操作得到左下角和右上角矩阵,再利用一个半角mask将两个矩阵进行合并。最后对多余部分进行置0操作,得到和原rel_shift操作结果一致(只是做了pad)的结果。
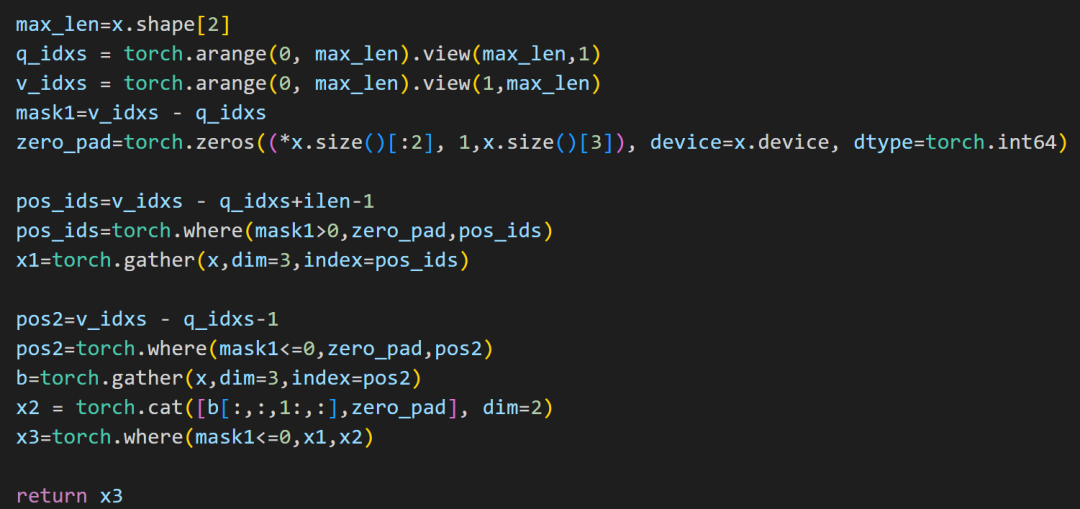
图8 输入pad后复现rel_shift 方案
4.1.3
消除Padding对depthwise_conv的影响
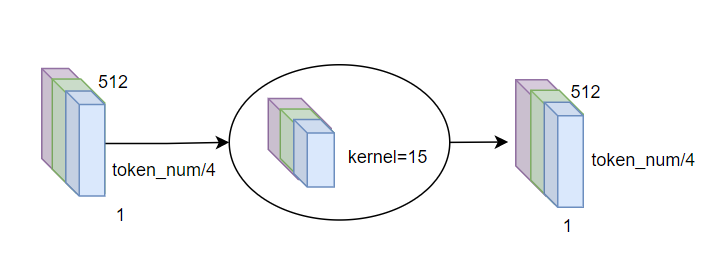
图9 输入pad后复现rel_shift方案
conformer模块中使用了分组卷积,前后分别进行pointwise conv和1D depthwise conv。由于token_num/4维度我们会pad到最大,此时由于depthwise conv kernel》1,会让无效特征也参与计算干扰结果。
解决方案是在depthwise前加一步根据mask的归0操作,把pad进去部分的特征都归0。
4.2
Attention decoder模块部署
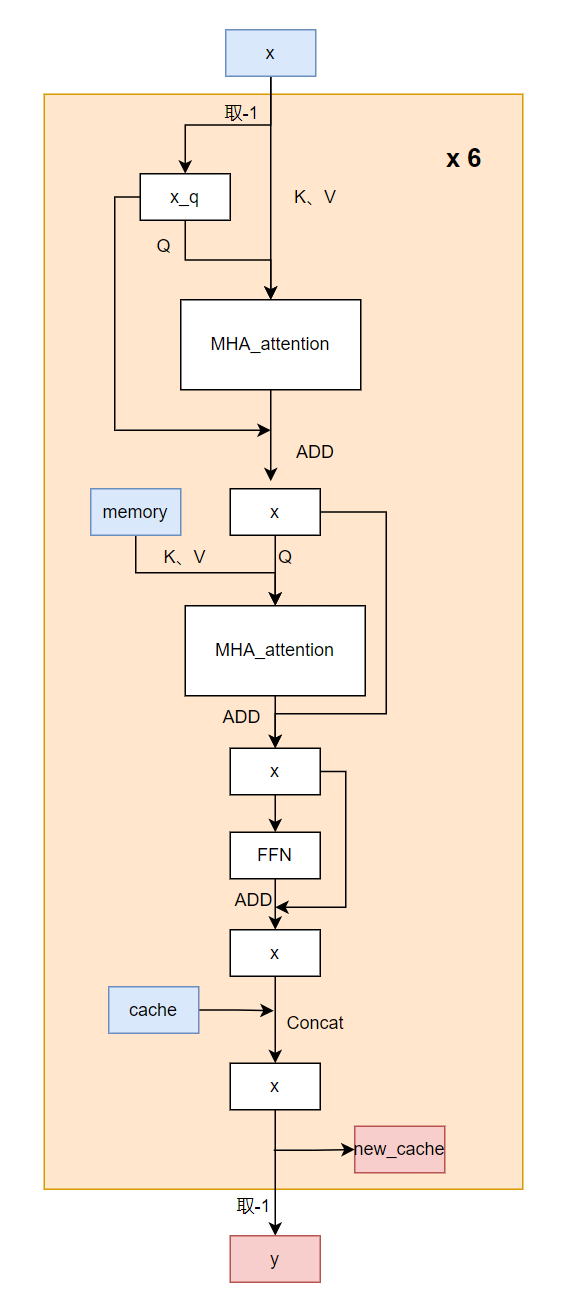
图10 encoder部分细节结构图
Attention decoder每次调用只生成一个字。其输入是encoder output特征,我们记作memory,以及历史生成的字x,输出是语音的下一个字。生成一句N个字的句子需要调用Attention decoder N+1次,在遇到标签或者达到最高字数时停止。
这里模型调用了6层decode layer,每层由一个self attention以及一个cross attention组成,为减少重复计算,会保存每次每层decoder layer的输出(我们记作cache),在下一次计算时只计算每层最新的一个token结果然后和保存的concat,再输往下一层,同时为下一次decoder保存当前new_cache。
原始输入为x,memory和cache。
要把Attention decoder改为固定长度输入,需要做的修改如下:
1
self attention部分:x改为x_pad和x_q,这里x表示历史的n无法根据index动态抽取,我们提前将最后一个token单独提取出来作为外部传入的输入x_q,x_q为x_pad里有效的最后一个token,注意需手动加上对应位置的position embedding。
2
cross attention部分:保持前面self attention的结果作为把原始的不定长的memory改为encoder output输入的pad后memory,同时加上memory mask以指示有效长度,防止关注到pad的部分,用于cross attention部分。
3
self attention和cross attention组成一层完整的decoder层,在生成一层decoder输出x_q后,在动态输入操作中,需要把之前保存的该层输出前面token结果concat到x_q上去,这也属于动态维度的操作,部署中无法使用,而在我们静态输入中,则选择where操作把x_q拷贝到pad后的state的第valid_len-1位置上去,故这里需要valid_len作为输入来进行拷贝引导,这里的valid_len是用于指示当前共有几个字,即我们关注的是第几个token的输出,在使用时每次调用valid_len加一。
4
取最后一层decoder的输出的x_q,经过一层softmax层得到最终的token概率分布。
修改后的输入为x_pad,x_q,memory,memory_mask,cache和valid_len,
修改后的代码流程如下:
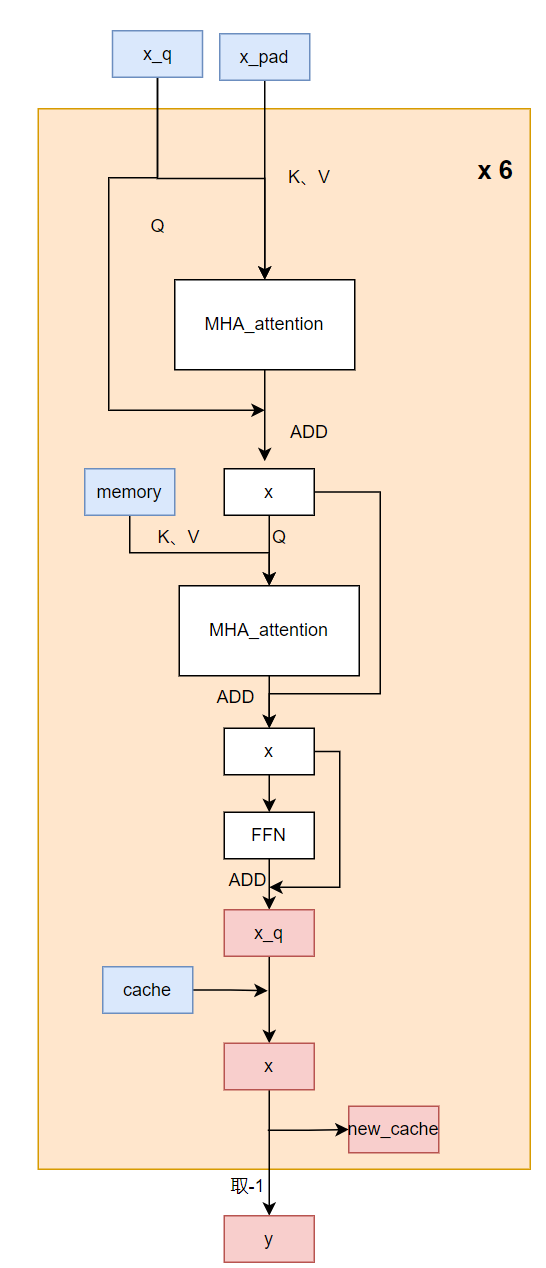
图11 attention decoder部分修改后示意图
五
小结
以上介绍了语音识别技术的应用场景,语音识别算法的原理、难点和解决方案,也介绍了我们在字幕生成场景中所做的实践。微调开源模型加上细致的前后处理,在我们的测试集上能够达到较好的可使用效果。未来ASR瓶颈更多的在于如何提升识别速度,以及在复杂场景下怎样结合其他技术优化ASR结果。
最后我们为ASR在沐曦曦思N100人工智能推理GPU上做了较好的静态部署,通过pad加mask的方案使动态输入达成固定长度,为保持计算逻辑不变,我们也对模型编码器和注意力解码器部分做了许多调整,该解决方案可作为其他序列生成模型的静态化部署参考。
-
算法
+关注
关注
23文章
4807浏览量
98569 -
ASR
+关注
关注
2文章
45浏览量
19453 -
模型
+关注
关注
1文章
3819浏览量
52274 -
傅里叶变换
+关注
关注
6文章
446浏览量
43800
原文标题:【智算芯闻】ASR算法实践及部署方案
文章出处:【微信号:沐曦MetaX,微信公众号:沐曦MetaX】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
最新一款LoRa 集成了单芯片SoC ASR6501/ASR6502
国内全新LoRa系统芯片ASR6505 内置SOC
ASR6501与SX1262优势区别
简化针对云服务的语音检测算法的部署
怎样去验证可部署目标硬件与软件算法模型之间的算法性能一致性?
asr翱捷LORA系列芯片选型参考推荐ASR6601/asr6505/asr6501/asr6500
基于粒子群优化PSO算法的部署策略
解决自动语音识别部署难题



评论