 如何使用加速PyTorrch2.0变异器
如何使用加速PyTorrch2.0变异器

如何使用加速PyTorrch2.0变异器和新推出的变异器irch. combile 。以下列示例为例加速大语言模型的方法纳米gptGPT模式在Andrej Karpropt的 Andrej Karpathy 中采用,采用新的规模化的 dot 产品关注量操作员通过加速PT2变换器,我们选择闪光点定制内核,并实现每个批次(用Nvidia A100 GPUs测量)更快的培训时间,从~143ms/批量基线到~113ms/批量基准,此外,利用SDPA操作员加强实施提供更好的数字稳定性。最后,利用加插投入进一步优化,如果加插投入与加插关注相结合,导致~87ms/批量。
最近,在日常生活中大量采用大型语言模式(LLMs)和创性AI,在时间和硬件利用方面,与这些不断增长的模式紧密结合,培训成本不断增加。加速变压器(以前称为“更好的变换器”)和JIT 汇编PyTorch 2.0 点火2.0.
在博客文章中,我们探索了利用SDPA的定制内核实施(也称“缩放点产品关注”)获得的培训优化,这是变压器模型中的一个关键层。SDPA的定制内核用一个全球优化的内核取代了若干独立的连续操作,避免分配大量的CUDA中间内存。这个方法提供了许多优势,包括但不限于:通过减少记忆带宽瓶颈,减少记忆足迹以支持较大批量尺寸,提高SDPA的性能计算,减少记忆足迹以支持较大批量尺寸,以及最终通过预先缩放输入压强器增加数字稳定性。 这些优化在NameGPT上展示,这是Andrej Karpath公司对GPT的开放源实施。
背景
扩大对点产品的关注是多头公司关注的基本构件,正如在2002年“注意是你们所需要的一切”并在LLM和产生性AI模型中广泛应用。
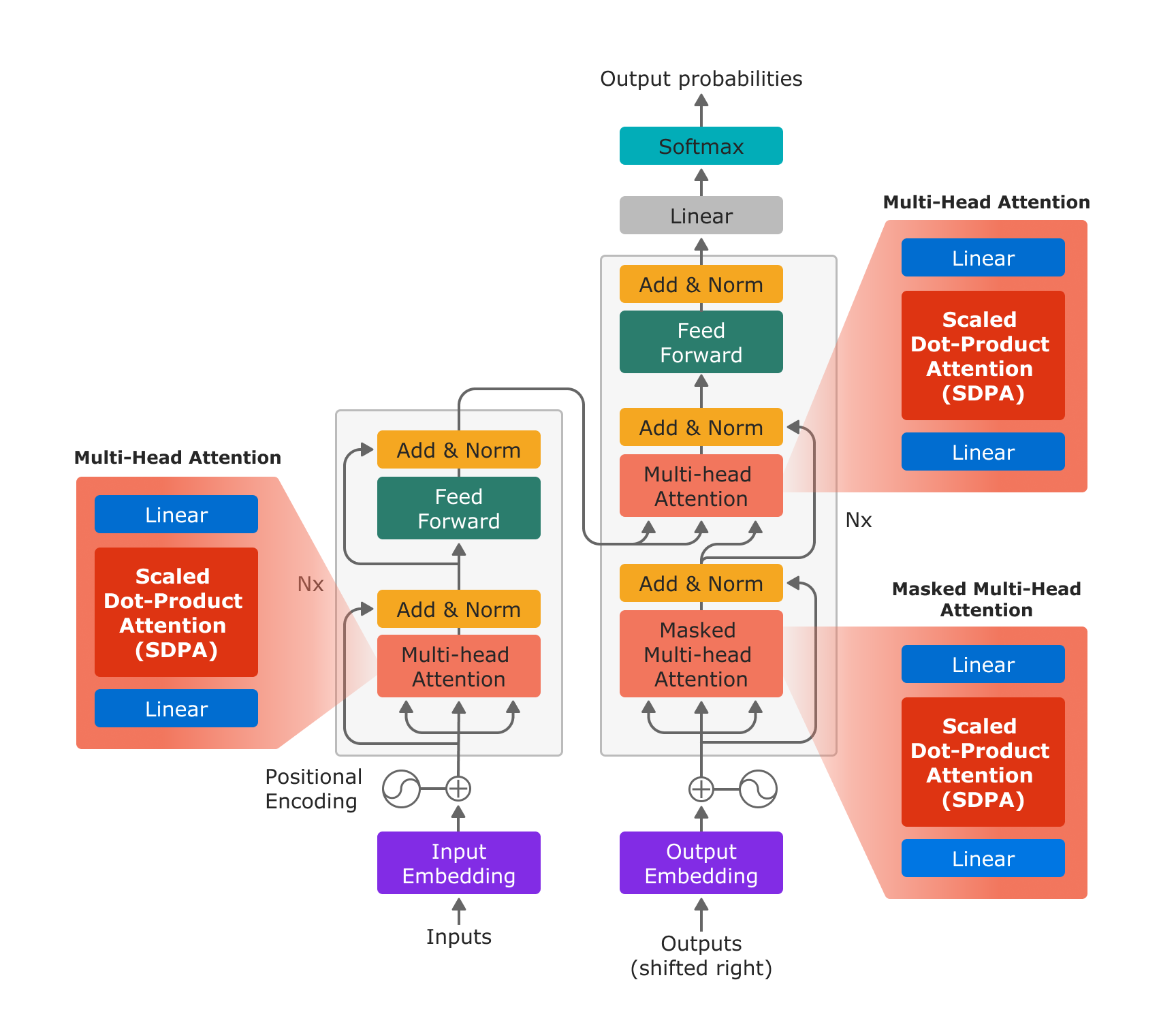
图1:以“注意是你们所需要的一切”使用新的PyTorrch SDPA操作员,多点关注由投射线层、SDPA操作员和投射线层有效实施。
使用新的缩放的多位元产品注意操作器,多头关注可以仅仅在三个步骤中进行:投射线性层、SDPA和投射线性层。
PyTorrch 2. 支持为特定用途案例优化的多个不同内核,并有具体要求。内核拾取器为特定输入参数组合选择最佳内核。如果不为特定输入参数组合优化“自定义内核 ” , 内核拾取器将选择一个能够处理所有输入组合的普通内核。
PyTorch 2.0 点火2.0号发射装置为SDPA操作员安装了3个装置:
用于执行函数中SDPA的数学方程式的通用内核sdpa_math 地图 ()
基于文件的优化内核“闪电注意”支持对SDPA进行评价,在计算SM80结构(A100)时采用16位浮点数据类型。
基于文件的优化内核“不需要O(n%2) 内存执行,并落实:旧前,它支持了范围更广的建筑结构(SM40和以后的SM40)上的32和16位浮数据类型。效率( mem) 效率( P)内核
请注意,两个优化的内核(上面列出两个和三个)都支持一个键嵌入面罩,并将支持的注意面罩限制为因果注意。 今天加速的 PyTorch 2.0 点火2.0 变换器只在指定使用因 - 因 - 因 - 因 - 原因当指定掩罩时,将选择通用内核,因为分析所提供掩罩的内容太昂贵,无法确定它是否为因果遮罩。PT2 加速变换器博客.
使用纳米GPPT的快速加速变换器
SDPA操作员是GPT模型的关键组成部分,我们确定开放源码纳米GPT模型是展示PyTorch 2.0 点火2.0加速变异器实施方便和效益的绝佳候选者。 以下展示了加速变异器在NAMGPT上启用的确切过程。
这一过程主要围绕取代现有的SDPA实施程序,由新加入的F.scald_dot_product_product_access 运营商取代。功能.py。这个程序可以很容易地调整,使操作员能够进入许多其他LLMs。或者,用户可以选择调用 F. multi_head_attention_forward () 或酌情直接使用 nn. Multi HeadAtention 模块。以下代码片断从 Karpathy 的 N纳米GPT 仓库中修改。
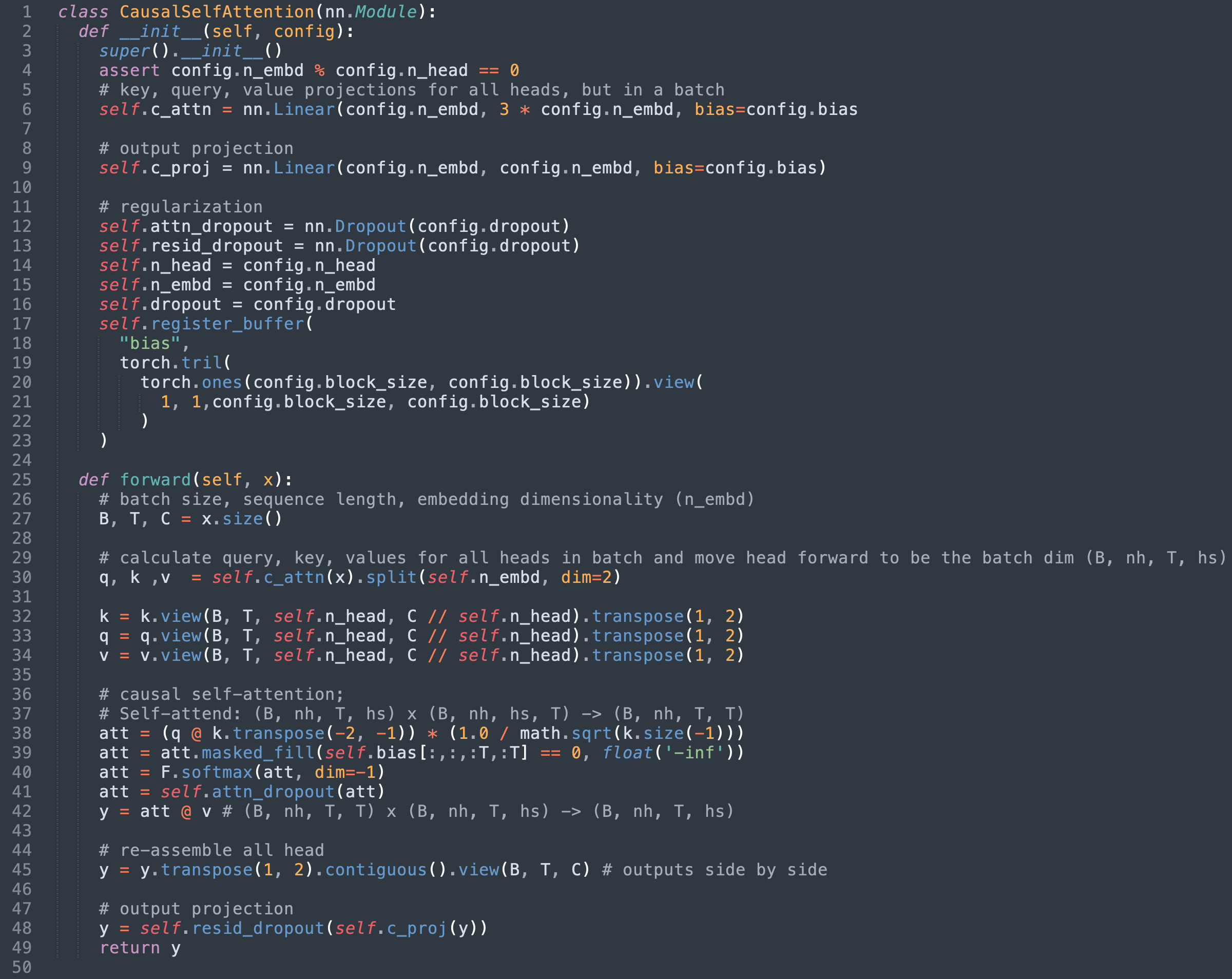
第1步:确定现有的SDPA执行情况
就纳米GPT而言,SDPA是在模型中实施的。以因果自 心类别。在撰写本报告时,为该员额对最初执行部分作如下调整。
第2步:用火炬取代缩放_ dot_ product_ 注意
目前,我们可以注意到以下几点:
第36至42行界定我们正在取代的SDPA的数学实施
39号线上应用的面具不再相关,因为我们使用的是缩放_dot_product_product_product_acceptions因 - 因 - 因 - 因 - 原因旗帜。
第41行使用的辍学层现在也没有必要。
换掉SDPA 的火炬( 缩放为_ dot_ product_ product_ attention), 并删除多余的代码, 产生以下效果 。
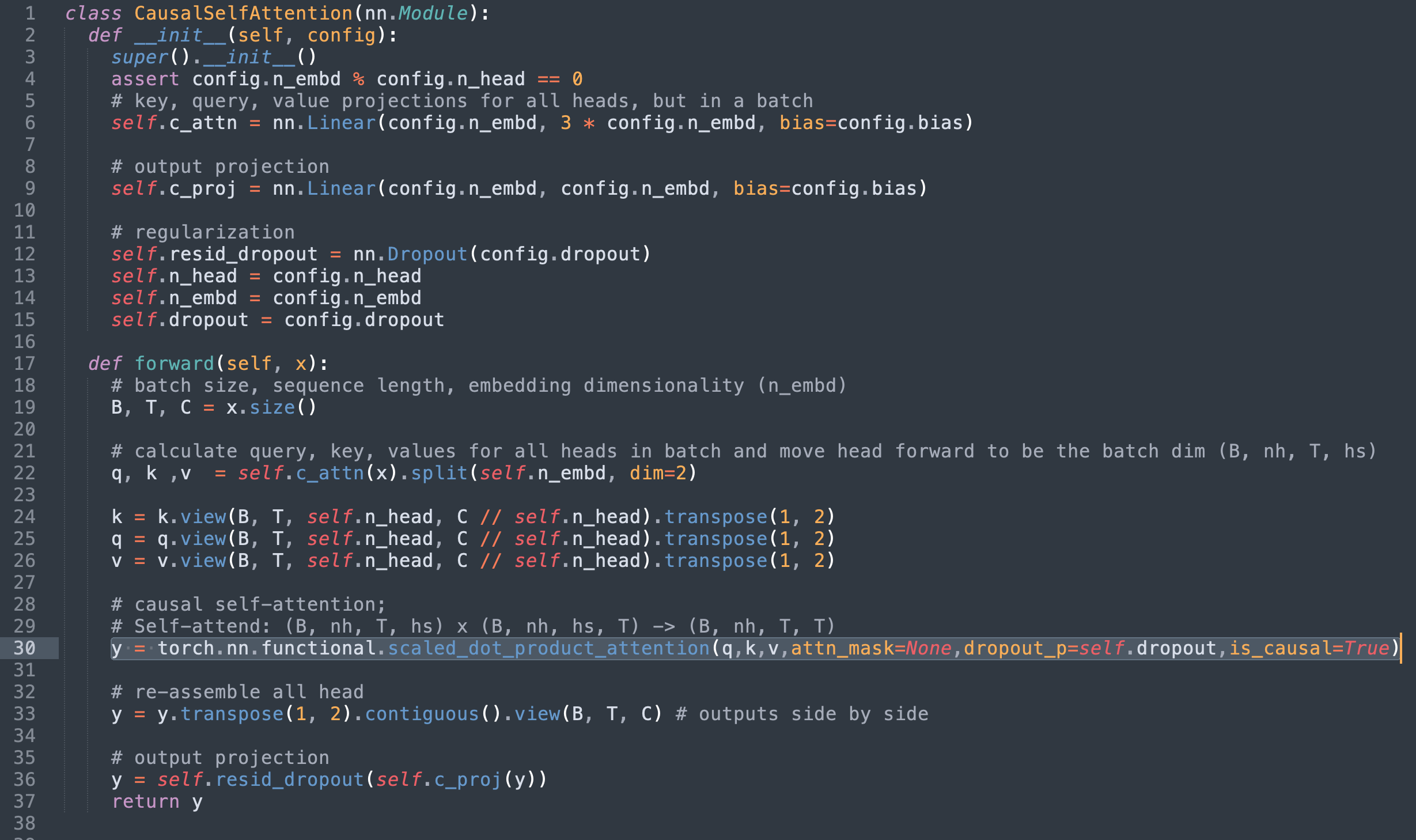
或者,也可以将原始面罩传递到attn-mask 缩略图然而,由于上述内核限制,将执行限制在只支持通用sdpa_math 地图内核
第3步(邦斯):用垫板更快的垫板
除了SDPA的性能改善之外,我们的分析还取得了良好的附带胜利。 在Andrej的“迄今为止对纳米GPT(~25%的加速率)最戏剧化的优化 ” , 就是简单地将鳄鱼的体积从50257个增加到50304个(接近64个的倍数 ) 。 ”
vocab 大小决定了 GPT 输出层的 matmuls 尺寸, 这些尺寸太大, 以至于它们正在使用占多数整个训练循环的时间点。 我们发现,他们的表现大大低于A100GPU上可以达到的最高量。NVIDIA的制表文件64 元素对齐将产生更好的效果。 事实上, 挂贴这些配制板可以实现近3x加速 。 根本原因是不对齐的内存存存取大大降低了效率。 更深入的分析可见于此推特线索.
通过这种优化,我们进一步缩短了每批培训时间,从~113毫斯(利用闪光关注)减少到~87毫斯。
结果结果结果 结果 结果
下图显示了利用Pytorch定制内核取得的性能。
基准线(执行NanoGPT):~14 300米
sdpa_math 地图( generic): ~ 134ms (6. 71% 更快)
效率( mem) 效率( P)内核:~119米(快20.16%)
闪闪注意内核:~113米(26.54%更快)
闪光- 注意加插 vocab:~ 8700米(64.37%更快)
所有代码都运行在80GB HBM[A100 SXM4 80GB]的8x NVIDIA Corporation A100服务器上,为试验目的,将这一辍学率设为0。
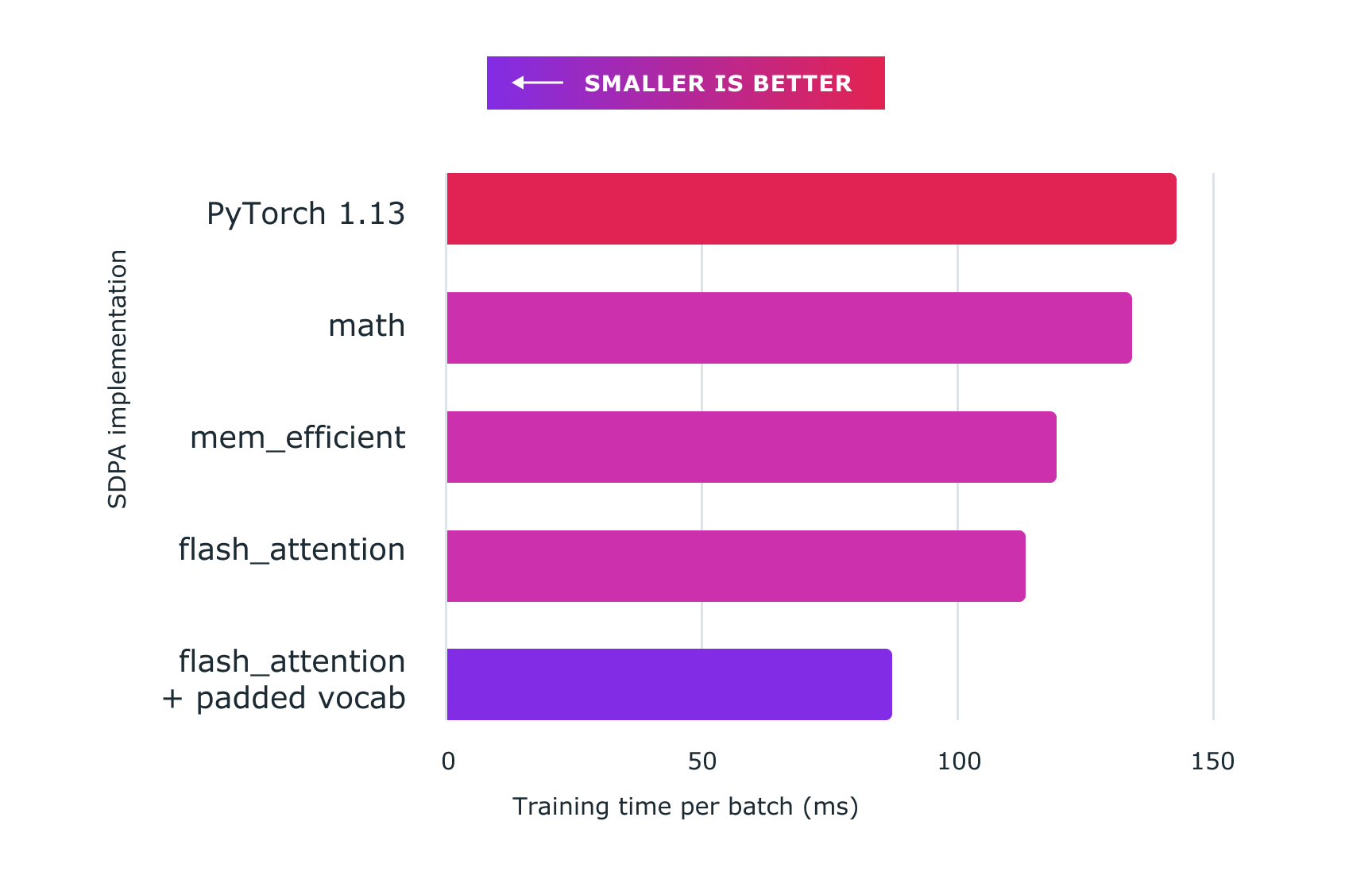
图2:使用定制内核和火炬的量级点产品注意和定制内核和火炬。纳米gpt在此显示 。
加强数字模型稳定
除了速度更快之外,PyTorrch的实施工作通过避免许多执行方案失去准确性,提高了数字稳定性。在这里,但基本上PyTollch 实施规模的查询和关键矩阵之前由于SDPA的合并定制内核结构,这一缩放在计算关注结果时不会增加间接费用,相比之下,个别计算组成部分的实施需要分别进行预先缩放,按额外费用计算。
改进内存消耗
然而,使用SDPA火炬内核的另一个大优点是记忆足迹减少,从而可以使用较大的批量尺寸。下图比较了经过一小时的闪光关注培训和因果关注基线实施后的最佳验证损失。从可以看出,基线因果关注实施(在8x NVIDIA Corporation A100服务器上,有80GB HBM, 80 GB HBM)实现的最大批量规模为24个,大大低于以闪光关注实现的最大数量,即39个。
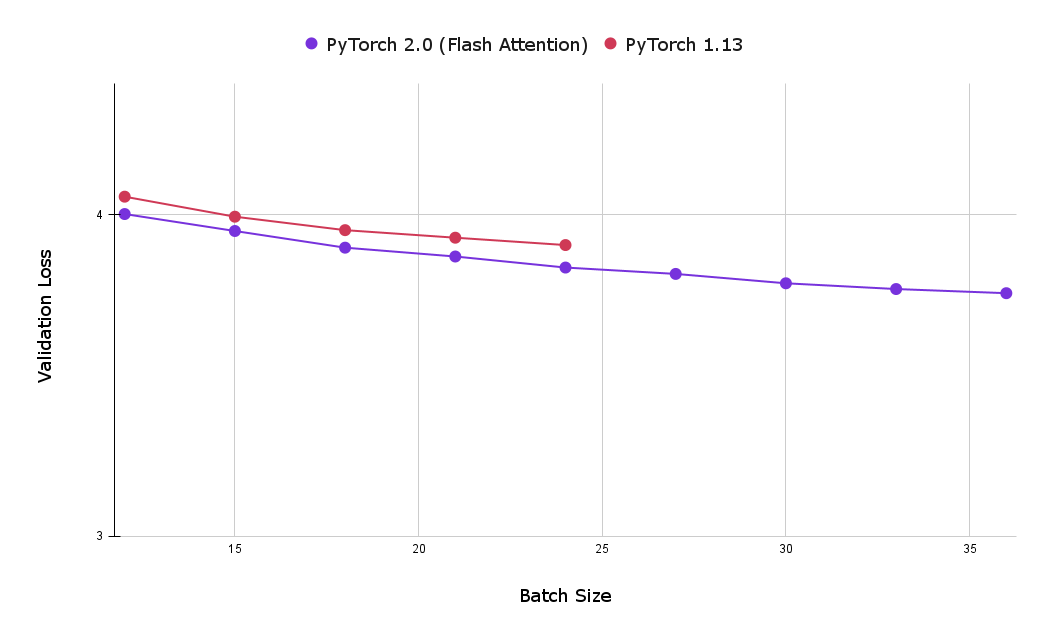
图3:使用 " 闪电注意 " 使得能够使用较大批量的批量,使用户在经过一小时培训后获得较低的验证损失(越小越好)。
结 结 结 结
新推出的PyTorrch SDPA运营商为培训变异器模型提供了更好的性能,对昂贵的大型语言模型培训特别有价值。
与固定批量规模的基准相比,培训速度加快26%以上
与基准量相比,用加插词汇表实现进一步加快速度,使总优化率达到约64%
额外数字稳定性
附录A:分析注意数字稳定
我们在本节更深入地解释前文提到的通过预估SDPA输入矢量而获得的增强数字稳定性。 下面是纳米GPT数学应用SDPA的简化版本。 这里需要指出的是,查询在不缩放的情况下进行矩阵倍增。
# 纳米gpt implementation of SDPA # notice q (our query vector) is not scaled ! att = (q @ k.transpose(-2, -1)) * (1.0 / math.sqrt(k.size(-1))) att = att.masked_fill(self.bias[:,:,:T,:T] == 0, float('-inf')) att = F.softmax(att, dim=-1) # Dropout is set to 0, so we can safely ignore this line in the implementation# att = self.attn_dropout(att) y_ nanogpt 识别器( y_ nanogpt) = att @ v # (B, nh, T, T) x (B, nh, T, hs) -> (B, nh, T, hs)
以下是火炬中等量的数学执行情况。缩放_ dot_ product_ 注意.
调
在数学方面,两种方法应当相等,然而,我们的实验表明,在实践中,我们从每一种方法得到的结果不同。
使用上述方法,我们核实了y 之前的 y_ 缩数(_S)匹配使用缩放_ dot_ product_ 注意方法时y_ nanogpt 识别器( y_ nanogpt)没有。
排火炬联盟具体地说,我们表明:
y_dpa = cherch.nn. 功能._ scald_dot_ product_atunited( q, k, v, attn-mask 缩略图=self. bias) [, : : : , T, : T] ! = 0, diut_ p= 0.0, 需要_ attn_ weights = False, 原因=False, ) toch.allclose( y_ sdpa, y_ nanogpt)
附录B:复制实验结果
试图复制这些结果的研究人员应首先从Andrej纳米GPT存储库的以下承诺开始:b3c17c6c6a363357623f2223aaa4a8b1e89d0a465。在测量每批量速度改进时,这一承诺被用作基准。对于包括添加词汇优化(按批量速度进行最大改进)在内的结果,使用以下承诺:77e7e04c26577846df30c1ca2d9f7cbb93ddeab。从任一取出中,选择实验的内核与使用该内核相比是微不足道的。
可以通过上下文管理器选择想要的内核 :
火炬. 后端. cuda. sdp_ 内核( 启用_ math = False, 启用_ flash = False, 启用_ mem_ valid = true): 火车( 模型)
审核编辑:彭菁
-
变压器
+关注
关注
162文章
8167浏览量
148797 -
GPT
+关注
关注
0文章
376浏览量
17020 -
pytorch
+关注
关注
2文章
813浏览量
14954
发布评论请先 登录
离体培养下的遗传与变异
变异原理在入侵检测技术中的应用
概化理论的方差分量变异量的估计
结合变异粒子群和字典学习的遥感影像去噪
基于DSEA的弱变异测试用例集生成方法
基于柯西-高斯动态消减变异的果蝇优化算法研究
基于数据竞争故障的变异策略
消息传递并行程序的变异测试
基于双变异策略的骨架差分算法
基于数据流分析的冗余变异体识别方法

基于数据流分析的冗余变异体识别及测试
基于软件的Vitis AI 2.0加速解决方案
初识变异源分析
Normal Variants 正常变异脑电波形时域分析




评论