 PyTorch IO DataPipes可用性、性能和功能
PyTorch IO DataPipes可用性、性能和功能
培训大型深层学习模式需要大型数据集。亚马逊简单存储服务(Amazon S3)是用于储存大型培训数据集的可缩放云点存储服务。 机器学习(ML)实践者需要高效的数据管道,能够从亚马逊S3下载数据,转换数据,并将数据输入GPU,用于高输送量和低潜伏度的培训模式。
我们在此为皮托尔奇推出新的S3 IO DataPipes(S3 IO DataPipes),s3 文件列表器和s3 文件加载器为了提高记忆效率和快速运行,新的数据平台使用C扩展号访问亚马逊S3基准显示:s3 文件加载器速度为59.8%ffspepefile 打开器用于下载亚马逊S3的自然语言处理(NLP)数据集。电子数据管道我们还表明,新的数据平台可以将贝尔特和ResNet50培训时间总体减少7%。
概览
亚马逊 S3 是一个可缩放的云存储服务系统,没有数据数量限制。 从亚马逊 S3 上载数据并将数据输入高性能的 GPU, 如 NVIDIA A100 等高性能的 GPU, 可能具有挑战性。 它需要高效的数据管道, 能够满足 GPU 的数据处理速度 。 为此, 我们为 PyTorrch 发布了一个新的高性能工具: S3 IO DataPipes 。 DataPipes 从参考文献数据库 参考文献数据库,以便他们能与宜用数据排气管接口。开发者可以快速建立数据平台 DAG, 以获取、转换和操作数据,并使用打乱、分割和批量功能。
新的 DataPipes 设计成文件格式的不可知性,亚马逊 S3 数据作为二进制大型对象( BLOBs) 下载。它可以用作可合成的构件块,用于组装一个DataPipe 图表,该图可以将表格、NLP和计算机视觉(CV)数据装入培训管道。
在引擎盖下,新的S3 IO DataPipes使用一个与 AWS C SDK 的 C S3 处理器。 一般来说, C 的安装比 Python 更能提高内存效率,并且与 Python 相比, C 的 CPU 核心使用( 没有全球解释器锁 ) 更好。 新的 C S3 IO DataPipes 被推荐在培训大型深层学习模型时使用高输送量、低潜伏数据。
新的S3 IO DataPipes提供两个头等公民API:
s3 文件列表器- 可在给定的 S3 前缀内列出 S3 文件 URL。 此 API 的功能名称是列表文件_by_s3.
s3 文件加载器- 从给定的 S3 前缀装入 S3 文件的可使用性。 此 API 的功能名称是负载文件_by_s3.
使用量
在本节中,我们为使用新的S3 IO DataPipes提供指导。负载_ files_by_s3 ().
从源构建
新建的 S3 IO DataPipes 使用 C 扩展名。 它被嵌入点火数据选项卡。但是,如果新的数据提示在环境中不可用,例如 Conda 上的 Windows,您需要从源构建。如果需要更多信息,请参见可迭接数据管道.
配置
亚马逊 S3 支持全球水桶。然而,在区域内创建一个水桶。您可以通过使用__init___()或者,您也可以导出 AWS_ REGION =us- 西向 2外壳或设置环境变量[AWS_REGION] =“我们一号” =“我们一号”在你的代码。
要在水桶中阅读无法公开查阅的物品,您必须通过下列方法之一提供AWS证书:
安装和配置排AWS 命令行界面(AWS CLLI)和(AWS CLLI)AWS 配置
设置当地系统AWS 认证档案档案中的全权证书。~/.锯/证书在 Linux, macOS 或 Unix 上
设定aws_ access_keey_id 访问器和aws_ secret_ access_keys 密钥环境变量
如果您使用这个图书馆亚马逊(Amazon EC2)实例,具体说明AWS 身份和准入管理(IMM)作用,然后让EC2实例有机会发挥这种作用
示例代码
下面的代码片断提供了一种典型的用法负载_ files_by_s3 ():
从 rch.utils. data 导入来自 rchdata. dataloader 从 rchdata. datapipops. iter 导入 IterableWrapper s3_shard_urls = IterableWrapper ([“s3://bucket/prefix/] ]).列表文件_by_s3 () s3_shards = s3_shard_urls.负载文件_by_s3 ()
基准基准基准
在本节中,我们展示新的数据平台如何能够减少Bert和ResNet50的总体培训时间。
对照FSSpec的孤立数据 Loader 业绩评价
ffspepefile 打开器是另一个 PyTollch S3 DataPipe 。它使用体核和传真/传真: http/ asyncioS3 数据访问 S3 数据。 以下是性能测试设置和结果(引自本地ASWDK与基于数据平台的FSspec(boto3)之间的业绩比较).
测试中的 S3 数据是一个碎片化的文本数据集。 每个碎片有大约10万条线, 每条线约为1.6 KB, 使每条碎片大约156 MB。 本基准中的测量量平均超过1,000 批。 没有进行打乱、 取样或变换 。
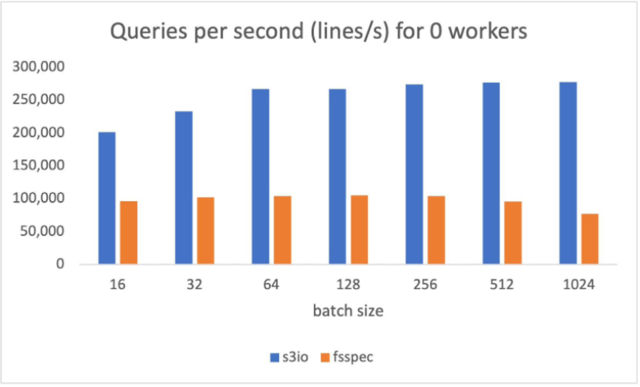
下图的图表汇报了以下表格中各种批量规模的通过量比较。num_工人=0,数据装载器在主过程中运行。s3 文件加载器每秒(QPS)的查询量较高(QPS),比(QPS)高90%。纤维分批体积为512。
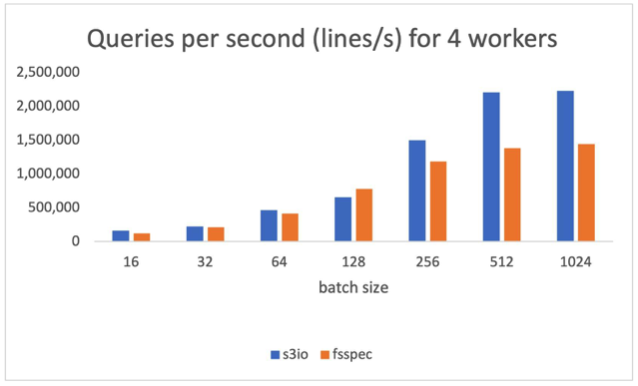
下图图表汇报了以下各项结果:num_工人=4,数据装载器运行在主进程。s3 文件加载器高于59.8%纤维分批体积为512。
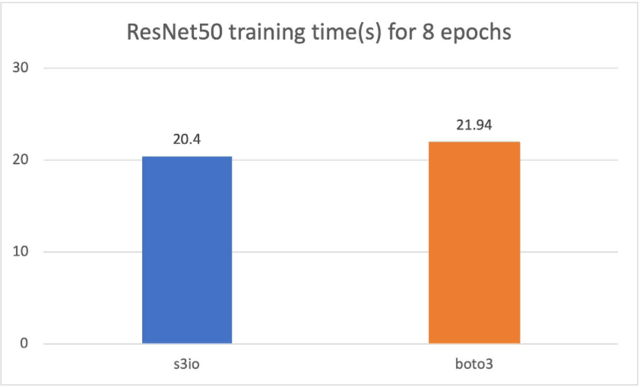
打击Boto3的训练ResNet50模式
在下图中,我们培训了RESNet50模型,该模型由4p3.16x大案例组成,总共32个GPUs。培训数据集是图像网络,有120万张图像,以1 000张图像碎片组成。培训批量尺寸为64。培训时间以秒计。对于8个时代,培训时间以8个时代计。s3 文件加载器比Boto3还快7.5%。
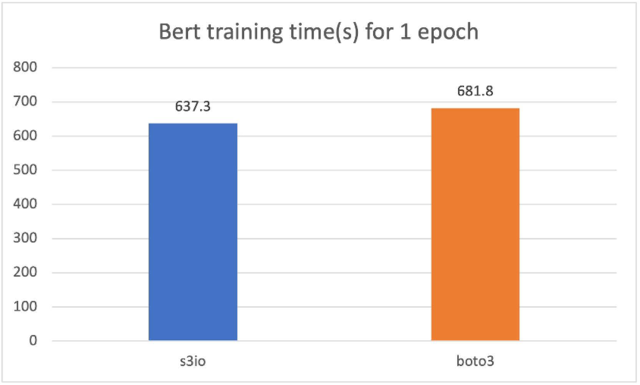
a 与Boto3相比的Bert培训模式
对于以下的马车,我们训练了一个Bert模型,在总共32个GPU的4 p3.16x大案例群中,共有1 474个文件。每个文件有大约15万个样本。要运行一个较短的时代,我们每个文件使用0.05%(大约75个样本)。批量大小为2 048,培训时间以秒计。对于一个时代,我们用0.5 % (大约75个样本)来测量。s3 文件加载器比Boto3还快7%
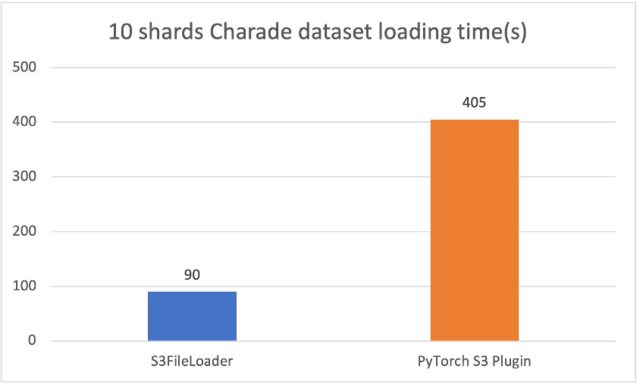
与原始 PyTorrch S3 插件的比较
新的PyTollch S3 DataPipes 运行比原运行要好得多PyTork S3 插件我们调整了内部缓冲大小s3 文件加载器。装载时间以秒计。
10个散乱的猜谜文件(每个约1.5GB),s3 文件加载器在我们的实验中 速度是3.5倍
最佳做法
培训大型深层学习模型可能需要一个包含数十个甚至数百个节点的大规模计算组。 集群中的每个节点都可能产生大量数据装载请求,这些请求会击中特定的 S3 碎片。 为了避免油门,我们建议在 S3 桶和 S3 文件夹上分割培训数据。
为了取得良好的业绩,它有助于拥有足够大的文件大小,足以在特定文件上平行,但并不大,以致于我们根据培训工作,在亚马逊S3上达到该物体的输送量极限。 最佳规模可能介于50-200 MB之间。
六. 结论和下一步措施
在此文章中,我们向您介绍了新的PyTorch IO DataPipes。新的 DataPipes 使用aws-sdk-cpp 缩略语并显示与基于 Boto3 的数据装载器相比的性能较好。
对于今后的步骤,我们计划改进可用性、性能和功能,侧重于以下特点:
S3授权,由IAM担任- 目前,S3 DataPipes支持明确的准入证书、案例简介和S3桶政策。 但是,有些使用案例更偏爱IMA角色。
双重缓冲- 我们计划提供双重缓冲 支持多工人下载
本地缓存- 我们计划使示范培训能够穿行培训数据集以通过多个传球。 第一个时代之后的本地缓冲可以缩短亚马逊三世的飞行延误时间,这可以大大加快随后时代的数据检索时间。
可定制配置- 我们计划披露更多参数,如内部缓冲大小、多部分块大小、执行人计数等,让用户进一步调整数据装载效率。
亚马逊 S3 上传- 我们计划扩大S3 DataPipes, 支持上传检查。
与 Fspec 合并 – 纤维用于其他系统,例如irch. save ()我们可以将新的 S3 数据 PDataPipes 与纤维这样他们就可以有更多的使用案例。
审核编辑:彭菁
-
数据
+关注
关注
8文章
6514浏览量
87609 -
gpu
+关注
关注
27文章
4424浏览量
126724 -
亚马逊
+关注
关注
8文章
2480浏览量
82382 -
pytorch
+关注
关注
2文章
763浏览量
12836
发布评论请先 登录
相关推荐






 工商网监
工商网监
评论