 Kubernetes集群中如何选择工作节点
Kubernetes集群中如何选择工作节点

简要概述:本文讨论了在Kubernetes集群中选择较少数量的较大节点和选择较多数量的较小节点之间的利弊。
当创建一个Kubernetes集群时,最初的问题之一是:“我应该使用什么类型的工作节点,以及需要多少个?”
如果正在构建一个本地集群,是应该采购一些上一代的高性能服务器,还是利用数据中心中闲置的几台老旧机器呢?
或者,如果正在使用像Google Kubernetes Engine(GKE)这样的托管式Kubernetes服务,是应该选择八个n1-standard-1实例还是两个n1-standard-4实例来实现所需的计算能力呢?
目录
集群容量
Kubernetes工作节点中的预留资源
工作节点中的资源分配和效率
弹性和复制
扩展增量和前导时间
拉取容器镜像
Kubelet和扩展Kubernetes API
节点和集群限制
存储
总结和结论
集群容量
一般来说,Kubernetes集群可以被看作是将一组独立的节点抽象为一个大的“超级节点”。
这个超级节点的总计算能力(包括CPU和内存)是所有组成节点的能力之和。
有多种实现这一目标的方法。例如,假设您需要一个总计算能力为8个CPU核心和32GB内存的集群。以下是两种可能的集群设计方式:
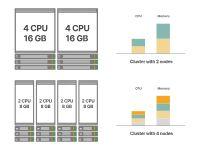
Kubernetes集群中的小型节点与大型节点
这两种选择都会得到相同容量的集群。
左边的选择使用了四个较小的节点,而右边的选择使用了两个较大的节点。
问题是:哪种方法更好呢?
为了做出明智的决策,让我们深入了解如何在工作节点中分配资源。
Kubernetes工作节点中的预留资源
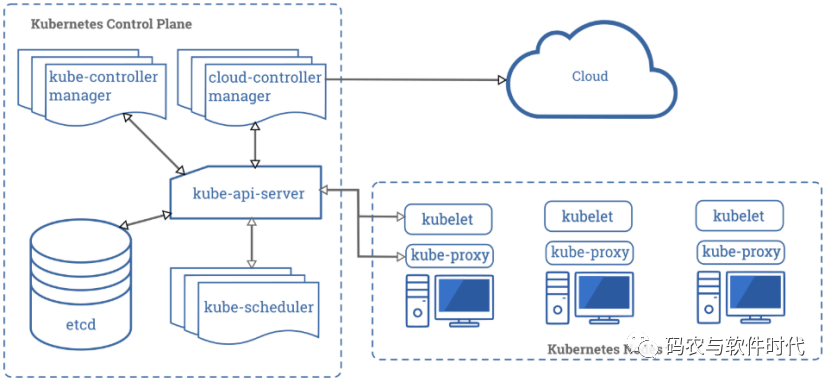
Kubernetes集群中的每个工作节点都是一个运行kubelet(Kubernetes代理)的计算单元。
kubelet是一个连接到控制平面的二进制文件,用于将节点的当前状态与集群的状态同步。
例如,当Kubernetes调度程序将一个Pod分配给特定节点时,它不会直接向kubelet发送消息。相反,它会创建一个Binding对象并将其存储在etcd中。
kubelet定期检查集群的状态。一旦它注意到将一个新分配的Pod分配给其节点,它就会开始下载Pod的规范并创建它。
通常将kubelet部署为SystemD服务,并作为操作系统的一部分运行。
kubelet、SystemD和操作系统需要资源,包括CPU和内存,以确保正确运行。
因此,并不是所有工作节点的资源都仅用于运行Pod。
CPU和内存资源通常分配如下:
操作系统。Kubelet。Pods。驱逐阈值。
Kubernetes节点中的资源分配
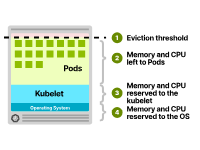
您可能想知道这些组件分配了哪些资源。虽然具体配置可能会有所不同,但CPU分配通常遵循以下模式:
第一个核心的6%。后续核心的1%(最多2个核心)。接下来的两个核心的0.5%(最多4个核心)。四个核心以上的任何核心的0.25%。内存分配可能如下:
小于1GB内存的机器分配255 MiB内存。前4GB内存的25%。接下来的4GB内存的20%(最多8GB)。接下来的8GB内存的10%(最多16GB)。接下来的112GB内存的6%(最多128GB)。超过128GB的任何内存的2%。最后,驱逐阈值通常保持在100MB。
驱逐阈值 驱逐阈值代表内存使用的阈值。如果一个节点超过了这个阈值,kubelet将开始驱逐Pod,因为当前节点的内存不足。
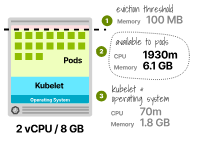
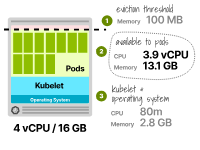
考虑一个具有8GB内存和2个虚拟CPU的实例。资源分配如下:
70毫核虚拟CPU和1.8GB供kubelet和操作系统使用(通常一起打包)。保留100MB用于驱逐阈值。剩余的6.1GB内存和1930毫核可以分配给Pod。只有总内存的75%用于执行工作负载。
但这还不止于此。
您的节点可能需要在每个节点上运行一些Pod(例如DaemonSets)以确保正确运行,而这些Pod也会消耗内存和CPU资源。
例如,Kube-proxy、诸如Fluentd或Fluent Bit的日志代理、NodeLocal DNSCache或CSI驱动程序等。
这是一个固定的成本,无论节点大小如何,您都必须支付。
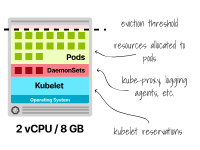
带有DaemonSets的Kubernetes节点中的资源分配 考虑到这一点,让我们来看一下"较少数量的较大节点"和"较多数量的较小节点"这两种截然相反的方法的利弊。
请注意,本文中的"节点"始终指的是工作节点。关于控制平面节点的数量和大小的选择是一个完全不同的主题。
工作节点中的资源分配和效率
随着更大实例的使用,kubelet预留的资源会减少。
让我们来看两种极端情况。
您想要为一个请求0.3个vCPU和2GB内存的应用部署七个副本。
在第一种情况下,您将为一个单独的工作节点提供资源以部署所有副本。在第二种情况下,您在每个节点上部署一个副本。为简单起见,我们假设这些节点上没有运行任何DaemonSets。
七个副本所需的总资源为2.1个vCPU和14GB内存(即7 x 300m = 2.1个vCPU和7 x 2GB = 14GB)。
一个4个vCPU和16GB内存的实例能够运行这些工作负载吗?
我们来计算一下CPU的预留:
第一个核心的6%=60m+ 第二个核心的1%=10m+ 剩余核心的0.5%=10m 总计=80m
用于运行Pod的可用CPU为3.9个vCPU(即4000m - 80m)——绰绰有余。
接下来,我们来看一下kubelet预留的内存:
前4GB内存的25%=1GB 接下来的4GB内存的20%=0.8GB 接下来的8GB内存的10%=0.8GB 总计=2.8GB
分配给Pod的总内存为16GB -(2.8GB + 0.1GB)——这里的0.1GB考虑到了100MB的驱逐阈值。
最后,Pod可以使用最多13.1GB的内存。
带有2个vCPU和16GB内存的Kubernetes节点中的资源分配
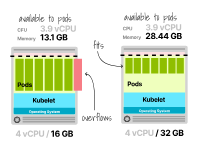
不幸的是,这还不够(即7个副本需要14GB的内存,但您只有13.1GB),您应该为部署这些工作负载提供更多内存的计算单元。
如果使用云提供商,下一个可用的增量计算单元是4个vCPU和32GB内存。
带有2个vCPU和16GB内存的节点不足以运行七个副本
 太好了!
太好了!
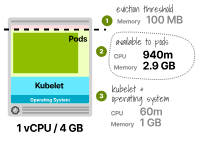
接下来,让我们看一下另一种情况,即我们尝试找到适合一个副本的最小实例,该副本的请求为0.3个vCPU和2GB内存。
我们尝试使用具有1个vCPU和4GB内存的实例类型。
预留的CPU总共为6%或60m,可用于Pod的CPU为940m。
由于该应用仅需要300m的CPU,这足够了。
kubelet预留的内存为25%或1GB,再加上额外的0.1GB的驱逐阈值。
Pod可用的总内存为2.9GB;由于该应用仅需要2GB,这个值足够了。
太棒了!
带有2个vCPU和16GB内存的Kubernetes节点中的资源分配 现在,让我们比较这两种设置。
第一个集群的总资源只是一个单一节点 — 4个vCPU和32GB。
第二个集群有七个实例,每个实例都有1个vCPU和4GB内存(总共为7个vCPU和28GB内存)。
在第一个示例中,为Kubernetes预留了2.9GB的内存和80m的CPU。
而在第二个示例中,预留了7.7GB(1.1GB x 7个实例)的内存和360m(60m x 7个实例)的CPU。
您已经可以注意到,在配置较大的节点时,资源的利用效率更高。
在单一节点集群和多节点集群之间比较资源分配情况
但还有更多。
较大的实例仍然有空间来运行更多的副本 — 但有多少个呢?
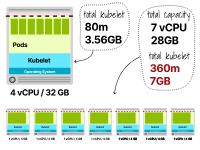
预留的内存为3.66GB(3.56GB的kubelet + 0.1GB的驱逐阈值),可用于Pod的总内存为28.44GB。预留的CPU仍然是80m,Pods可以使用3920m。此时,您可以通过以下方式找到内存和CPU的最大副本数:
TotalCPU3920/ PodCPU300 ------------------ MaxPod13.1
您可以为内存重复进行计算:
总内存28.44/ Pod内存2 最大Pod14.22
以上数字表明,内存不足可能会在CPU之前用尽,而在4个vCPU和32GB工作节点中最多可以托管13个Pod。
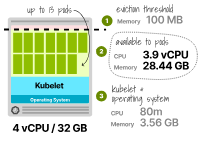
为2个vCPU和32GB工作节点计算Pod容量 那么第二种情况呢?
是否还有空间进行扩展?
实际上并没有。
虽然这些实例仍然具有更多的CPU,但在部署第一个Pod后,它们只有0.9GB的可用内存。
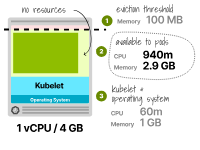
为1个vCPU和4GB工作节点计算Pod容量 总之,不仅较大的节点能更好地利用资源,而且还可以最小化资源的碎片化并提高效率。
这是否意味着您应该始终提供较大的实例?
让我们来看另一个极端情况:节点意外丢失时会发生什么?
弹性和复制
较少数量的节点可能会限制您的应用程序的有效复制程度。
例如,如果您有一个由5个副本组成的高可用应用程序,但只有两个节点,那么有效的复制程度将降低为2。
这是因为这五个副本只能分布在两个节点上,如果其中一个节点失败,可能会一次性失去多个副本。
具有两个节点和五个副本的集群的复制因子为两个

另一方面,如果您至少有五个节点,每个副本都可以在一个单独的节点上运行,而单个节点的故障最多会导致一个副本失效。
因此,如果您有高可用性要求,您可能需要在集群中拥有一定数量的节点。
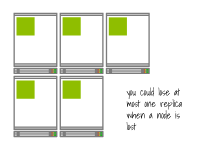
具有五个节点和五个副本的集群的复制因子为五 您还应该考虑节点的大小。
当较大的节点丢失时,一些副本最终会被重新调度到其他节点。
如果节点较小,仅托管了少量工作负载,则调度器只会重新分配少数Pod。
虽然您不太可能在调度器中遇到任何限制,但重新部署许多副本可能会触发集群自动缩放器。
并且根据您的设置,这可能会导致进一步的减速。
让我们来探讨一下原因。
扩展增量和前导时间
您可以使用水平扩展器(即增加副本数量)和集群自动缩放器(即增加节点计数)的组合来扩展部署在Kubernetes上的应用程序。
假设您的集群达到总容量,节点大小如何影响自动缩放?
首先,您应该知道,当集群自动缩放器触发自动缩放时,它不会考虑内存或可用的CPU。
换句话说,总体上使用的集群不会触发集群自动缩放器。
相反,当一个Pod因资源不足而无法调度时,集群自动缩放器会创建更多的节点。
此时,自动缩放器会调用云提供商的API,为该集群提供更多的节点。
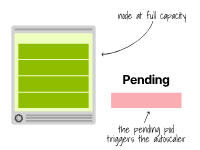
集群自动缩放器在Pod由于资源不足而处于挂起状态时提供新的节点。
集群自动缩放器在Pod由于资源不足而处于挂起状态时提供新的节点。

不幸的是,通常情况下,配置节点是比较缓慢的。
要创建一个新的虚拟机可能需要几分钟的时间。
提供较大或较小实例的配置时间是否会改变?
不,通常情况下,无论实例的大小如何,配置时间都是恒定的。
此外,集群自动缩放器不限于一次添加一个节点;它可能会一次添加多个节点。
我们来看一个例子。
有两个集群:
第一个集群有一个4个vCPU和32GB的单一节点。第二个集群有13个1个vCPU和4GB的节点。一个具有0.3个vCPU和2GB内存的应用程序部署在集群中,并扩展到13个副本。
这两种设置都已达到总容量
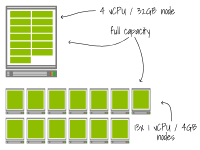
当部署扩展到15个副本时会发生什么(即增加两个副本)?
在两个集群中,集群自动缩放器会检测到由于资源不足,额外的Pod无法调度,并进行如下配置:
对于第一个集群,增加一个具有4个vCPU和32GB内存的额外节点。对于第二个集群,增加两个具有1个vCPU和4GB内存的节点。由于在为大型实例或小型实例提供资源时没有时间差异,这两种情况下节点将同时可用。
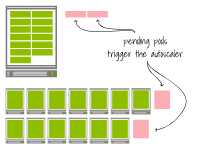
然而,你能看出另一个区别吗?
第一个集群还有空间可以容纳11个额外的Pod,因为总容量是13个。
而相反,第二个集群仍然达到了最大容量。
你可以认为较小的增量更加高效和更便宜,因为你只添加所需的部分。
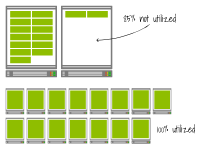 但是让我们观察一下当您再次扩展部署时会发生什么——这次扩展到17个副本(即增加两个副本)。
但是让我们观察一下当您再次扩展部署时会发生什么——这次扩展到17个副本(即增加两个副本)。
第一个集群在现有节点上创建了两个额外的Pod。而第二个集群已经达到了容量上限。Pod处于待定状态,触发了集群自动缩放器。最终,又会多出两个工作节点。
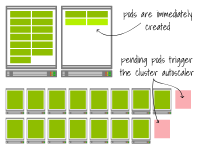
在第一个集群中,扩展几乎是瞬间完成的。
而在第二个集群中,您必须等待节点被配置完毕,然后才能让Pod开始提供服务。
换句话说,在前者的情况下,扩展速度更快,而在后者的情况下,需要更多的时间。
通常情况下,由于配置时间在几分钟范围内,您应该谨慎考虑何时触发集群自动缩放器,以避免产生更长的Pod等待时间。
换句话说,如果您能够接受(潜在地)没有充分利用资源的情况,那么通过使用较大的节点,您可以实现更快的扩展。
但事情并不止于此。
拉取容器镜像也会影响您能够多快地扩展工作负载,这与集群中的节点数量有关。
拉取容器镜像
在Kubernetes中创建Pod时,其定义存储在etcd中。
kubelet的工作是检测到Pod分配给了它的节点并创建它。
kubelet将会:
从控制平面下载定义。
调用容器运行时接口(CRI)来创建Pod的沙箱。CRI会调用容器网络接口(CNI)来将Pod连接到网络。
调用容器存储接口(CSI)来挂载任何容器卷。
在这些步骤结束时,Pod就已经存在了,kubelet可以继续检查活跃性和就绪性探针,并更新控制平面以反映新Pod的状态。
kubelet与CRI、CSI和CNI接口需要注意的是,当CRI在Pod中创建容器时,它必须首先下载容器镜像。
这当然是在当前节点上的容器镜像没有缓存的情况下。
让我们来看一下这如何影响以下两个集群的扩展:
第一个集群有一个4个vCPU和32GB的单一节点。第二个集群有13个1个vCPU和4GB的节点。让我们部署一个使用基于OpenJDK的容器镜像的应用程序,该应用程序使用0.3个vCPU和2GB内存,容器镜像大小为1GB(仅基础镜像大小为775MB)的13个副本。
对这两个集群会发生什么?
在第一个集群中,容器运行时只下载一次镜像并运行13个副本。在第二个集群中,每个容器运行时都会下载并运行镜像。在第一个方案中,只需要下载1GB的镜像。
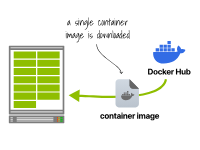
容器运行时下载一次容器镜像并运行13个副本 然而,在第二个方案中,您需要下载13GB的容器镜像。
由于下载需要时间,第二个集群在创建副本方面比第一个集群要慢。
此外,它会使用更多的带宽并发起更多的请求(即至少每个镜像层一个请求,共计13次),这使得它更容易受到网络故障的影响。
13个容器运行时中的每一个都会下载一个镜像 需要注意的是,这个问题会与集群自动缩放器紧密关联。
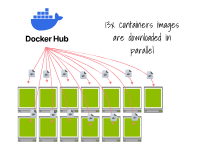
如果您的节点较小:
集群自动缩放器会同时配置多个节点。
一旦准备好,每个节点都开始下载容器镜像。
最终,Pod被创建。
当您配置较大的节点时,容器镜像很可能已经在节点上缓存,Pod可以立即开始运行。
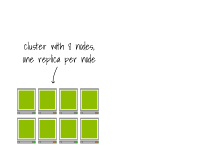 想象一下拥有8个节点的集群,每个节点上有一个副本。
想象一下拥有8个节点的集群,每个节点上有一个副本。
最终,Pod会被创建在节点上。
想象一下拥有8个节点的集群,每个节点上有一个副本。
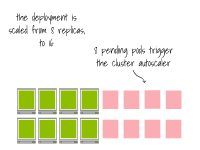
该集群已经满载;将副本扩展到16个会触发集群自动缩放器。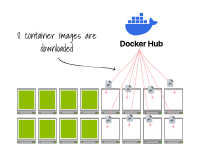
一旦节点被配置完毕,容器运行时会下载容器镜像。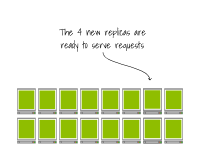 最终,Pod会在节点上创建。
最终,Pod会在节点上创建。
所以,您是否应该始终配置较大的节点?
未必如此。
您可以通过容器注册表代理来减轻节点下载相同容器镜像的情况。
在这种情况下,镜像仍然会被下载,但是从当前网络中的本地注册表中下载。
或者您可以使用诸如spegel之类的工具来预热节点的缓存。
使用Spegel,节点是可以广告和共享容器镜像层的对等体。
在这种情况下,容器镜像将从其他工作节点下载,Pod几乎可以立即启动。
但是,容器带宽并不是您必须控制的唯一带宽。
Kubelet与Kubernetes API的扩展
kubelet被设计为从控制平面中获取信息。
因此,在规定的间隔内,kubelet会向Kubernetes API发出请求,以检查集群的状态。
但是控制平面不是会向kubelet发送指令吗?
拉取模型更容易扩展,因为:
控制平面不需要将消息推送到每个工作节点。
节点可以以自己的速度独立地查询API服务器。
控制平面不需要保持与kubelet的连接打开。
请注意,也有显著的例外情况。例如,诸如kubectl logs和kubectl exec之类的命令需要控制平面连接到kubelet(即推送模型)。
但是Kubelet不仅仅是为了查询信息。
它还向主节点报告信息。
例如,kubelet每十秒向集群报告一次节点的状态。
此外,当准备探针失败时(以及应从服务中删除pod端点),kubelet会通知控制平面。
而且kubelet会通过容器指标将控制平面保持更新。
换句话说,kubelet会通过从控制平面发出请求(即从控制平面和向控制平面)来保持节点正常运行所需的状态。
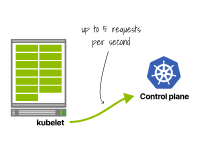
在Kubernetes 1.26及更早版本中,kubelet每秒可以发出多达5个请求(在Kubernetes >1.27中已放宽此限制)。
所以,假设您的kubelet正以最大容量运行(即每秒5个请求),当您运行几个较小的节点与一个单一的大节点时会发生什么?
让我们看看我们的两个集群:
第一个集群有一个4个vCPU和32GB的单一节点。
第二个集群有13个1个vCPU和4GB的节点。
第一个集群生成5个每秒的请求。
一个kubelet每秒发出5个请求
第二个集群每秒发出65个请求(即13 x 5)。
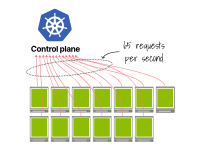
13个kubelet每秒各自发出5个请求
当您运行具有许多较小节点的集群时,您应该将API服务器的扩展性扩展到处理更频繁的请求。
而反过来,这通常意味着在较大的实例上运行控制平面或运行多个控制平面。
节点和集群限制
Kubernetes集群的节点数量是否有限制?
Kubernetes被设计为支持多达5000个节点。
然而,这并不是一个严格的限制,正如Google团队所演示的,允许您在15,000个节点上运行GKE集群。
对于大多数用例来说,5000个节点已经是一个很大的数量,可能不会是影响您决定选择较大还是较小节点的因素。
相反,您可以运行在节点中运行的最大Pod数可能会引导您重新思考集群架构。
那么,在Kubernetes节点中,您可以运行多少个Pod?
大多数云提供商允许您在每个节点上运行110到250个Pod。
如果您自己配置集群,则默认为110。
在大多数情况下,这个数字不是kubelet的限制,而是云提供商对重复预定IP地址的风险的容忍度。
为了理解这是什么意思,让我们退后一步,看看集群网络是如何构建的。
在大多数情况下,每个工作节点都被分配一个具有256个地址的子网(例如10.0.1.0/24)。
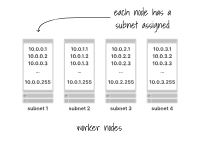
每个工作节点都被分配一个子网
其中两个是受限制的,您可以使用254来运行您的Pods。
考虑这种情况,其中在同一个节点上有254个Pod。
您创建了一个更多的Pod,但已经耗尽了可用的IP地址,它保持在挂起状态。
为了解决这个问题,您决定将副本数减少到253。
那么挂起的Pod会在集群中被创建吗?
可能不会。
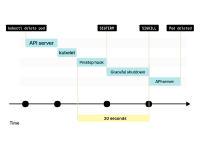
当您删除Pod时,其状态会变为“正在终止”。
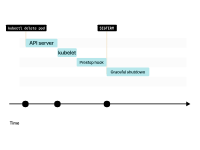
kubelet向Pod发送SIGTERM信号(以及调用preStop生命周期钩子(如果存在)),并等待容器优雅地关闭。
如果容器在30秒内没有终止,kubelet将发送SIGKILL信号到容器,并强制进程终止。
在此期间,Pod仍未释放IP地址,流量仍然可以到达它。
当Pod最终被删除时,IP地址被释放。
kubelet通知控制平面Pod已成功删除。IP地址终于被释放。
想象一下您的节点正在使用所有可用的IP地址。
当一个Pod被删除时,kubelet会收到变更通知。
如果Pod有一个preStop钩子,首先会调用它。然后,kubelet会向容器发送SIGTERM信号。
默认情况下,进程有30秒的时间来退出,包括preStop钩子。如果在这之前进程没有退出,kubelet会发送SIGKILL信号,强制终止进程。
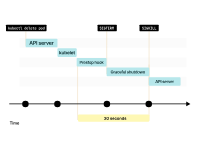
kubelet会通知控制平面Pod已成功删除。IP地址最终被释放。
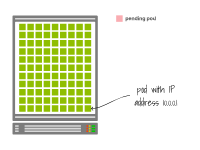
当一个Pod被删除时,IP地址不会立即释放。您必须等待优雅的关闭。
这是一个好主意吗?
好吧,没有其他可用的IP地址 - 所以您没有选择。
想象一下,您的节点正在使用所有可用的IP地址。
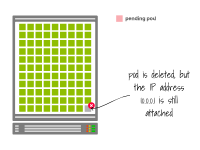
一旦Pod被删除,IP地址就可以被重新使用。
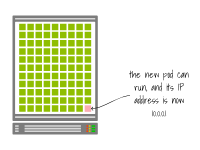
kubelet通知控制平面Pod已成功删除。IP地址终于被释放。
此时,挂起的Pod可以被创建,并且分配给它与上一个相同的IP地址。
想象一下,您的节点正在使用所有可用的IP地址。
下一页
那后果会怎样?
还记得我们提到过,Pod应该优雅地关闭并处理所有未处理的请求吗?
嗯,如果Pod被突然终止(即没有优雅的关闭),并且IP地址立即分配给另一个Pod,那么所有现有的应用程序和Kubernetes组件可能仍然不知道这个更改。
入口控制器将流量路由到一个IP地址。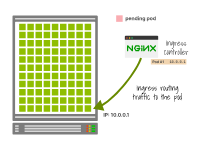
如果IP地址在没有等待优雅关闭的情况下被回收并被一个新的Pod使用,入口控制器可能仍然会将流量路由到该IP地址。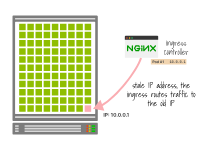
因此,一些现有的流量可能会错误地发送到新的Pod,因为它与旧的Pod具有相同的IP地址。
为了避免这个问题,您可以分配较少的IP地址(例如110)并使用剩余的IP地址作为缓冲区。
这样,您可以相当肯定地确保不会立即重新使用相同的IP地址。
存储
计算单元对可以附加的磁盘数量有限制。
例如,在Azure上,具有2个vCPU和8GB内存的Standard_D2_v5实例最多可以附加4个数据磁盘。
如果您希望将StatefulSet部署到使用Standard_D2_v5实例类型的工作节点上,您将无法创建超过四个副本。
这是因为StatefulSet中的每个副本都附加有一个磁盘。
一旦创建第五个副本,Pod将保持挂起状态,因为无法将持久卷声明绑定到持久卷。
为什么呢?
因为每个持久卷都是一个附加的磁盘,所以您在该实例中只能有4个。
那么,您有哪些选择?
您可以提供一个更大的实例。
或者您可以使用不同的子路径字段重新使用相同的磁盘。
让我们看一个例子。
下面的持久卷需要一个具有16GB空间的磁盘:
如果您将此资源提交到集群,您将看到创建了一个持久卷并绑定到它。
$kubectlgetpv,pvc
持久卷与持久卷声明之间存在一对一的关系,因此您无法有更多的持久卷声明来使用相同的磁盘。
apiVersion:apps/v1 kind:Deployment metadata: name:app1 spec: selector: matchLabels: name:app1 template: metadata: labels: name:app1 spec: volumes: -name:pv-storage persistentVolumeClaim: claimName:shared containers: -name:main image:busybox volumeMounts: -mountPath:'/data' name:pv-storage
如果您想在您的Pod中使用该声明,可以这样做:
apiVersion:apps/v1 kind:Deployment metadata: name:app2 spec: selector: matchLabels: name:app2 template: metadata: labels: name:app2 spec: volumes: -name:pv-storage persistentVolumeClaim: claimName:shared containers: -name:main image:busybox volumeMounts: -mountPath:'/data' name:pv-storage
您可以有另一个使用相同持久卷声明的部署:
但是,通过这种配置,两个Pod将在同一个文件夹中写入其数据。
您可以通过在subPath中使用子目录来解决此问题。
apiVersion:apps/v1 kind:Deployment metadata: name:app2 spec: selector: matchLabels: name:app2 template: metadata: labels: name:app2 spec: volumes: -name:pv-storage persistentVolumeClaim: claimName:shared containers: -name:main image:busybox volumeMounts: -mountPath:'/data' name:pv-storage
subPath: app2
部署将在以下路径上写入其数据:
对于第一个部署,是/data/app1
对于第二个部署,是/data/app2
这个解决方法并不是完美的,有一些限制:
所有部署都必须记住使用subPath。如果需要写入卷,您应该选择可以从多个节点访问的Read-Write-Many卷。这些通常需要昂贵的提供。此外,对于StatefulSet,相同的解决方法无法起作用,因为这将为每个副本创建全新的持久卷声明(和持久卷)。
总结和结论
那么,在集群中是使用少量大节点还是许多小节点?
这取决于情况。
反正,什么是小的,什么是大的?
这取决于您在集群中部署的工作负载。
例如,如果您的应用程序需要10GB内存,那么运行一个具有16GB内存的实例等于“运行一个较小的节点”。
对于只需要64MB内存的应用程序来说,相同的实例可能被认为是“大的”,因为您可以容纳多个这样的实例。
那么,对于具有不同资源需求的混合工作负载呢?
在Kubernetes中,没有规定所有节点必须具有相同的大小。
您完全可以在集群中使用不同大小的节点混合。
这可能让您在这两种方法的优缺点之间进行权衡。
-
cpu
+关注
关注
68文章
11331浏览量
225904 -
节点
+关注
关注
0文章
230浏览量
25671 -
服务器
+关注
关注
14文章
10364浏览量
91760 -
容器
+关注
关注
0文章
536浏览量
23029 -
kubernetes
+关注
关注
0文章
275浏览量
9536
原文标题:在 Kubernetes 集群中,如何正确选择工作节点资源大小
文章出处:【微信号:magedu-Linux,微信公众号:马哥Linux运维】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
Kubernetes架构和核心组件组成 Kubernetes节点“容器运行时”技术分析
KubePi:开源Kubernetes可视化管理面板,让集群管理如此简单
阿里云上Kubernetes集群联邦
Kubernetes Ingress 高可靠部署最佳实践
Kubernetes 从懵圈到熟练:集群服务的三个要点和一种实现
如何部署基于Mesos的Kubernetes集群
Kubernetes集群的关闭与重启
Kubernetes的集群部署
使用Velero备份Kubernetes集群



评论