 如何在SAM时代下打造高效的高性能计算大模型训练平台
如何在SAM时代下打造高效的高性能计算大模型训练平台

关键词:SAM;PCB;SA-1B;Prompt;CV;NLP;PLM;BERT;ZSL;task;zero-shot;data;H100、H800、A100、A800、LLaMA、Transformer、OpenAI、GQA、RMSNorm、SFT、RTX 4090、A6000、AIGC、CHATGLM、LLVM、LLMs、GLM、NLP、AGI、HPC、GPU、CPU、CPU+GPU、英伟达、Nvidia、英特尔、AMD、高性能计算、高性能服务器、蓝海大脑、多元异构算力、高性能计算、大模型训练、通用人工智能、GPU服务器、GPU集群、大模型训练GPU集群、大语言模型、深度学习、机器学习、计算机视觉、生成式AI、ML、DLC、ChatGPT、图像分割、预训练语言模型、PLM、机器视觉、AI服务器
摘要:Segment Anything Model (SAM)是Meta 公司最近推出的一个创新AI 模型,专门用于计算机视觉领域图像分割任务。借鉴ChatGPT 的学习范式,将预训练和特定任务结合在一起,从而显著提升模型的泛化能力。SAM 的设计初衷是简化图像分割的过程,减少对专业建模知识的依赖,并降低大规模训练所需的计算资源。
在计算机视觉领域,SAM模型是一种基于CV领域的ChatGPT,提供强大的图像分割功能。然而,要使用SAM模型,我们需要进行SAM大模型环境的配置。虽然配置SAM环境可能会面临一些挑战,但一旦配置完成,我们将能够充分利用SAM模型的强大功能。
为配置SAM环境,我们需要确保服务器具备足够的计算资源和存储空间,以支持SAM模型的高效运行。SAM模型通常需要大量的计算资源和存储能力来进行准确的图像分割。然而,也需要注意SAM本地部署对服务器的影响。SAM模型的部署可能对服务器的性能和稳定性产生一定的影响。
蓝海大脑大模型训练平台提供强大计算集群、高速存储系统和高带宽网络连接,加速模型的训练过程;同时采用高效分布式计算框架和并行计算,使模型训练可以在多个计算节点上同时进行,大大缩短训练时间。兼备任务调度、资源管理和监控等功能,提升训练效率和可管理性。此外,丰富的工具和库,可用于模型开发、调试和优化。还为模型部署和推理提供支持。一旦模型训练完成,平台可将训练好的模型部署到生产环境中,以供实际应用使用。
SAM模型:CV领域的ChatGPT
一、什么是SAM模型?
SAM模型是 Meta 推出的人工智能模型,在官网上被描述为“仅需一次点击,即可在任何图像中分割出任何物体”。采用以前图像分割模型作为基础,并在庞大的数据集上进行训练,该模型旨在解决多个下游任务并成为一种通用模型。
该模型的核心要点有:
1、借鉴ChatGPT的启发思想,采用可提示学习范式,提高学习效率;
2、建立迄今为止最大的图像分割数据集Segment Anything 1-Billion(SA-1B),包含1100万张图像和超过10亿个掩码;
3、构建通用且自动的分割模型,在零样本情况下灵活应用于新的任务和领域,其结果优于以往的监督学习结果。
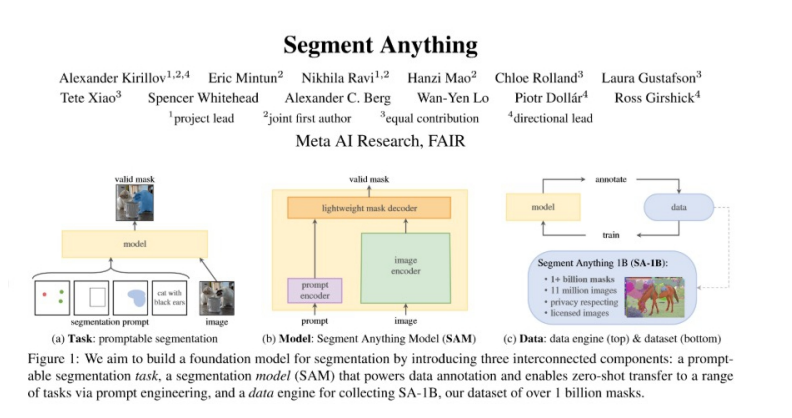
SAM 模型官方文章
二、Prompt:将 ChatGPT 的学习思维应用在 CV 领域
SAM 利用先进技术路线实现计算机视觉底层技术突破,具备广泛的通用性和零样本迁移的能力。采用 prompt-based learning 方式进行学习训练,即利用提示语作为模型输入。与传统的监督学习方式不同,该方法在 GPT-3 团队的推动下得到广泛应用。
1、Prompt之前的模型在做什么
预训练语言模型(PLM)是一种先进的自然语言处理(NLP)模型,在人和计算机交互方面起着重要的作用。NLP旨在改善人与计算机之间的交流和理解,而PLM则是这一领域前沿模型之一。

自然语言处理(NLP)的常用算法和模型
预训练模型根据学习范式和发展阶段可以分为四代:
1)特征学习:通过设置规则来提取文本特征编码文本,例如TF-IDF模型。
2)结构学习:引入深度学习在NLP中应用,代表性模型是Word2Vec。第一代、第二代预训练模型的共同点是输出被用作下游任务的输入,但本身并不直接执行下游任务。随后的模型将预训练结果和模型自身都应用于下游任务中。
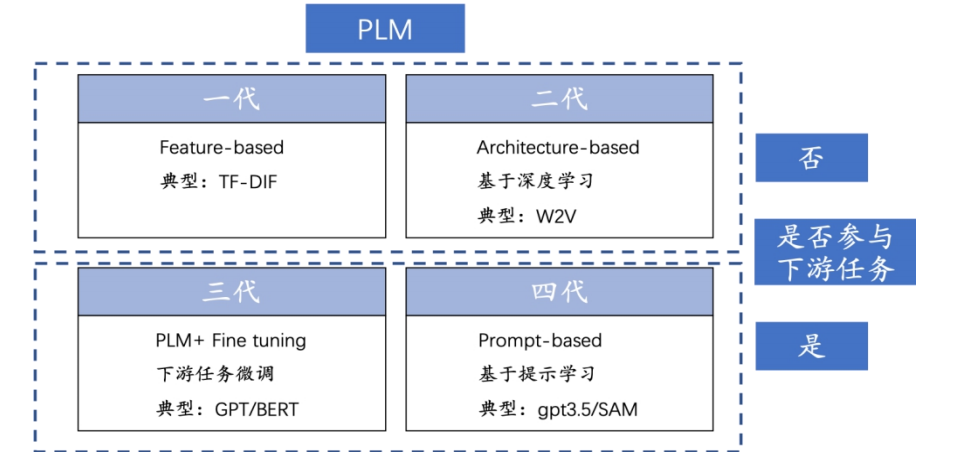
预训练模型(PLM)的发展阶段和特征
3)下游微调:采用预训练加下游微调方式,代表性模型有BERT和GPT。
4)提示学习:在BERT和GPT的基础上进一步改进,采用基于提示学习(Prompt-based Learning)方法。该方法将输入信息经过特定模板处理,将任务转化为更适合预训练语言模型处理形式。代表性模型有ChapGPT、GPT3.5和SAM。
预训练模型就像是培养出的高中毕业生,而下游任务则相当于大学的专业课程。高中毕业生学习未来应用领域相关的课程,就能够成为具备专业技能和知识的大学生,以应对专业岗位的要求。
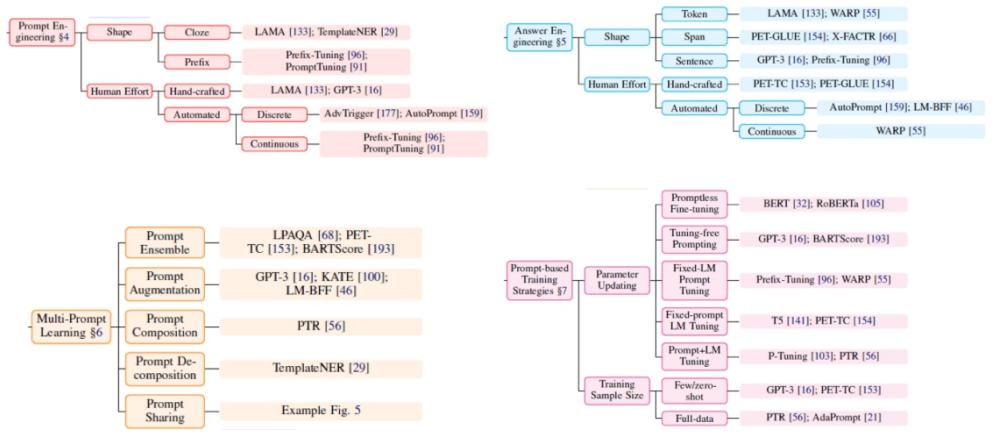
基于提示的学习(prompt-based learning)各分支
2、Prompt 的优势:实现预训练和下游任务的统一
如下图所示(左图),传统的PLM+微调范式存在上下游之间差异较大、应用不匹配问题,在预训练阶段使用自回归或自编码方法,但对于下游的微调任务来说,需要大量新数据来适应不同的形式和要求。
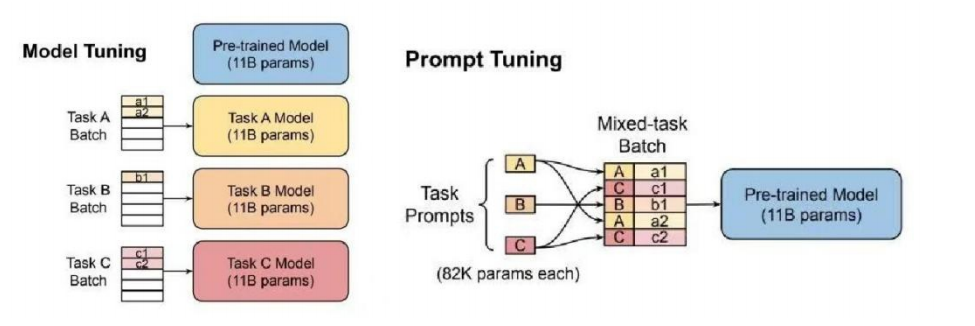
传统的预训练+微调模型以及 prompt范式
随着模型参数越来越庞大,企业部署模型成本非常高。同时为满足各种不同下游之间的任务,需要专门对每个任务进行微调,也是一种巨大的浪费。主要有以下两个缺点:
1)微调所需的样本数量非常大
2)模型的专用性高,部署成本高昂
针对以上缺点,PT-3团队提出在大量无监督文本阅读后,语言模型可以通过"培养广泛技能和模式识别能力"有效地解决问题。实验表明在少样本场景下,模型不需要更新任何参数就能实现不错的效果。预训练加微调范式是通过大量训练使模型适应下游任务。而Prompt则是将下游任务以特定模板的形式统一成预训练任务,将下游任务的数据组织成自然语言形式,充分发挥预训练模型本身的能力。
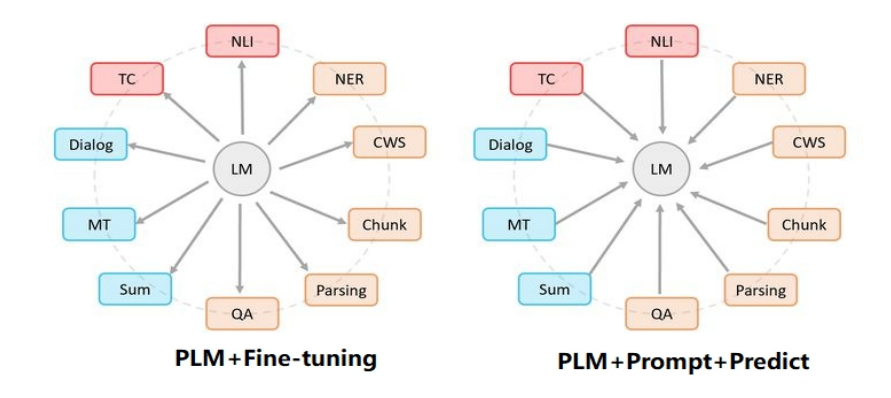
Fine-tune 和 prompt 两种范式的区别
以情感分类任务为例,使用传统Fine-tune方法需要准备一个微调数据集,其中包含对电影/书籍的评价以及人工阅读后的感受。该微调数据集必须足够大,以满足复杂任务需求。但是微调数据集的大小可能超过预训练数据集的规模,导致预训练的目的失去意义。
相比之下,利用Prompt的方式可以更好地处理情感分类任务并且充分利用预训练模型能力,避免繁重微调数据集准备工作。Prompt可以根据输入的句子来输出对MASK位置单词的预测,进而推测出用户对该作品作品的态度。
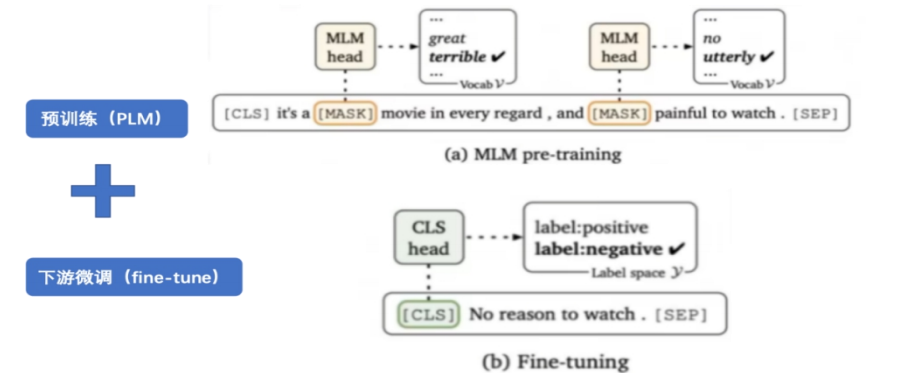
预训练+下游任务微调(PLM+Fine-tuning)处理情感分类任务(写影评)
Prompt范式具有以下优点:
1)大大降低模型训练所需样本量,可以在少样本甚至零样本的情况下进行训练
2)提高模型的通用性,在实际应用中减少成本并提高效率
当下,大型模型如GPT-4已经不再完全开放全部的模型参数,用户只能通过API接口使用模型进行预测。由此可见,Prompt工程在下游任务中的重要性已经不言而喻。
三、ZSL:零样本学习降本增效,提高模型泛化能力
1、什么是零样本学习能力?
零样本学习(Zero-shot Learning, ZSL)是机器学习中的一个难题,其目标是让模型能够对从未见过的"未知物体"进行分类和识别。下图中展示一个经典案例,即认识斑马。一个"儿童"在动物园里见过许多动物,如马、熊猫、狮子、老虎等,但从未见过斑马。通过老师的描述,该"儿童"了解到斑马有四条腿、黑白相间的条纹以及尾巴。最终这个"儿童"轻松地辨认出斑马。
类似,模型也可以通过零样本学习方式,从已见过的类别中提取特征(如外形类似马、具有条纹、黑白色),然后根据对未知类别特征的描述,识别那些从未见过的类别。换言之,模型通过之前学到的知识和特征,将其应用于未知物体的识别。

零样本学习(ZSL)示例
2、SAM 的零样本学习能力得到认可
SAM 正具备这样一种零样本分割能力,可以从各种 prompt 输入(包括点、方框和文本)中生成高质量的掩膜(Mask)。学术界有多篇论文探讨SAM 的 ZSL 能力, 如《SAM.MD: Zero-shot medical image segmentation capabilities of the Segment Anything Model》测试 SAM 的 ZSL 效果,在图像分割任务中输入部分点和框作为 prompt 提示,结果显示:专家用户可以通过 SAM 实现大部分场景下的快速半自动分割。虽然在实验中 SAM 没有表现出领先的全自动分割性能,但可成为推动临床医生半自动分割工具发展的潜在催化剂。

SAM 的零样本学习能力在 CT 影像中的应用
四、SA-1B:迄今为止最大的分割数据集,助力模型增效
1、Data Engine:使用数据引擎生成掩码
SAM使用数据集进行训练,并采用SAM交互式注释图像的方式对数据进行标注。另外,采用新颖的数据收集方法,结合模型和标注人员的力量,从而提高数据收集的效率和质量。整个过程可以分为三个阶段,让SAM的数据引擎更加完善和高效。
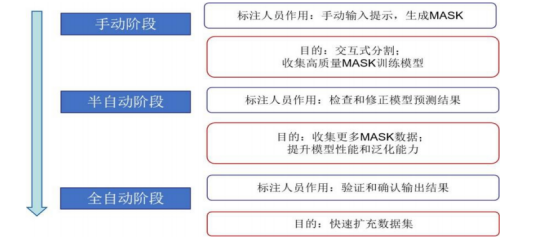
SAM使用数据引擎(data engine)渐进式收集数据示意图
1)手工阶段:在模型辅助的手工注释阶段,标注人员利用SAM模型作为辅助工具,在图像上进行点击、框选或输入文本等操作来生成MASK,并且模型会实时根据标注人员的输入更新MASK,并提供一些可选的MASK供标注人员选择和修改。该方式使得标注人员能够快速而准确地分割图像中的对象,无需手动绘制。其目的是收集高质量的MASK,用于训练和改进SAM模型。
2)半自动阶段:SAM模型已经具备一定的分割能力,能够自动预测图像中的对象。但是由于模型不够完善,预测MASK可能存在错误或遗漏。标注人员的主要任务是检查和修正模型的预测结果,以确保MASK的准确性和完整性。该阶段的目标是收集更多的MASK,以进一步提升SAM模型的性能和泛化能力。
3)全自动阶段:SAM模型已经达到较高水平,能够准确地分割图像中的所有对象,无需任何人工干预。因此,标注人员工作转变为确认和验证模型输出,以确保没有任何错误。该阶段旨在利用SAM模型的自动标注能力,快速扩展数据集的规模和覆盖范围。
2、Data Set:使用数据引擎生成掩码
通过逐步进行“模型辅助的手工注释——半自动半注释——模型全自动分割掩码”方法,SAM团队成功创建名为SA-1B图像分割数据集。该数据集具有规模空前、质量优良、多样化丰富和隐私保护的特点。
1)图像数量和质量:SA-1B包含多样化、高清晰度、隐私保护的1100万张照片,这些照片是由一家大型图片公司提供并授权使用,符合相关的数据许可证要求,可供计算机视觉研究使用。
2)分割掩码数量和质量:SA-1B包含11亿个精细的分割掩码,这些掩码是由Meta开发的数据引擎自动生成,展示该引擎强大的自动化标注能力。
3)图像分辨率和Mask数量:每张图像的平均分辨率为1500x2250像素,每张图像包含约100个掩码。
4)数据集规模对比:SA-1B比现有的分割数据集增加400多倍;相较于完全手动基于多边形的掩码标注(如COCO数据集),使用SAM的方法快6.5倍;比过去最大的数据标注工作快两倍。
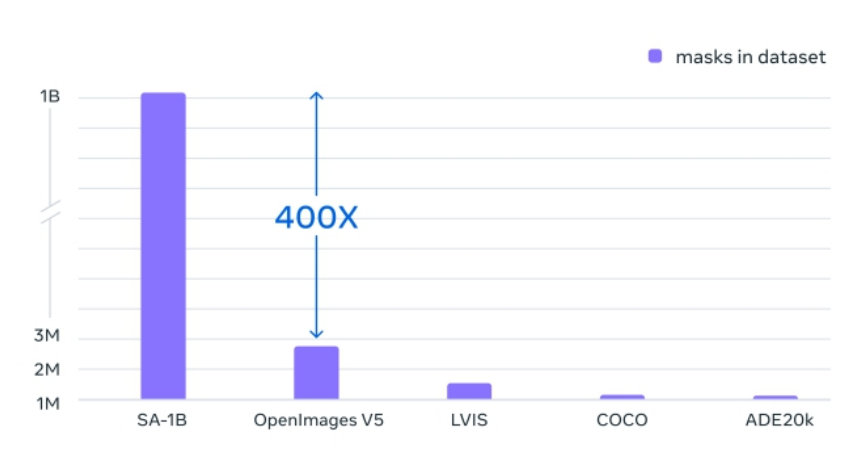
SA-1B比现有分割数据集多 400 倍
SA-1B数据集目标是训练一个通用模型,可以从开放世界图像中分割出任何物体。该数据集不仅为SAM模型提供强大的训练基础,同时也为图像分割领域提供一个全新的研究资源和基准。
此外,在SA-1B的论文中,作者进行RAI(Responsible AI,责任智能)分析,并指出该数据集的图像在跨区域代表性方面具有更强的特点。
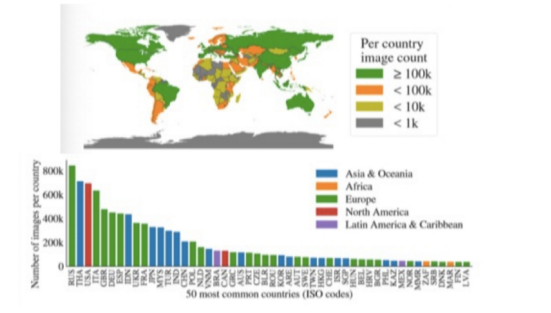
SA-1B 数据集的跨区域代表性较强
五、SAM 核心优势:减少训练需求,提升分割性能
SAM的核心目标是在不需要专业建模知识、减少训练计算需求以及自行标注掩码的情况下,实现目标通用分割。为逐步实现该目标,SAM采取以下三种方法构建图像领域的通用分割大模型:
1)数据规模和质量
SAM通过具备零样本迁移能力,收集大量高质量的图像分割数据(1100万张图像和11亿个掩码)构建SA-1B数据集,这是目前规模最大的图像分割数据集,远超过以往的数据集。
2)模型效率和灵活性
SAM借鉴Transformer模型架构,并结合注意力机制和卷积神经网络,实现高效且可引导的图像分割模型。该模型能够处理任意大小和比例的图像,并且能够根据不同的输入提示生成不同的分割结果。

SAM 的可提示分割模型分为三部分
3)任务的泛化和迁移
SAM实现图像分割任务的泛化和迁移能力。它通过采用可提示分割任务的方法,构建一个能够零样本迁移的图像分割模型。这意味着SAM可以适应新的图像分布和任务,而无需额外的训练数据或微调。这一特性使得SAM在多个图像分割任务上表现出色,甚至超过一些有监督的模型。
目前,SAM已经具备以下功能:
学习物体概念能够理解图像中物体的概念和特征。
生成未见过物体的掩码为图像或视频中未见过的物体生成准确的掩码。
高通用性具有广泛的应用性,能够适应不同的场景和任务。
支持多种交互方式SAM支持用户使用多种交互方式进行图像和视频分割,例如全选分割自动识别图像中的所有物体,以及框选分割(只需框选用户选择的部分即可完成分割)。

框选分割(BOX)
在图像分割领域,SAM是一个具有革命性意义的模型。它引入一种全新范式和思维方式,为计算机视觉领域的基础模型研究提供新的视角和方向。SAM的出现改变了人们对图像分割的认知,并为该领域带来巨大的进步和突破。
2、基于 SAM 二次创作,衍生模型提升性能
自从引入SAM以来,该技术在人工智能领域引起极大的兴趣和讨论,并且衍生出一系列相关模型和应用,如SEEM和MedSAM等。这些模型在工程、医学影像、遥感图像、农业等不同领域都有广泛应用。借鉴SAM理念和方法,并通过进一步改进和优化,使得SAM的应用范围更广泛。
1)SEEM:交互、语义更泛化,分割质量提升

SEEM在交互和语义空间上都比 SAM 更具泛化性
SEEM是一种基于SAM的新型交互模型,利用SAM强大的零样本泛化能力,实现对任意图像中所有物体的分割任务。该模型结合SAM和一个检测器,通过使用检测器输出的边界框作为输入提示,生成相应物体掩码。SEEM能够根据用户提供多种输入模态(如文本、图像、涂鸦等),一次性完成图像或视频中所有内容分割与物体识别任务。
这项研究已在多个公开数据集上进行实验,其分割质量和效率均优于SAM。值得一提的是,SEEM是第一个支持各种用户输入类型的通用接口,包括文本、点、涂鸦、框和图像,提供强大组合功能。

SEEM 根据用户输入的点和涂鸦进行图像识别
SEEM具备分类识别特性,可以直接输入参考图像并指定参考区域,从而对其他图像进行分割,并找出与参考区域相一致的物体。同时该模型还拥有零样本分割功能,对于模糊或经历剧烈变形的视频,能够准确地分割出参考对象。通过第一帧和用户提供的涂鸦等输入,SEEM能够在道路场景、运动场景等应用中表现出色。

SEEM 根据参考图像对其他图像进行分割
2)MedSAM:提升感知力,应用医学图像分割
为评估SAM在医学影像分割任务中的性能,深圳大学等多所高校合作创建COSMOS 553K数据集(迄今为止规模最大的医学影像分割数据集)研究人员利用该数据集对SAM进行全面、多角度、大规模的详细评估。该数据集考虑医学图像的多样成像模式、复杂边界以及广泛的物体尺度,提出更大的挑战。通过这次评估,可以更全面地了解SAM在医学影像分割任务中的性能表现。
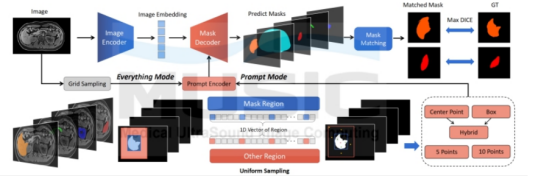
SAM 分割医学影像测试的详细框架
根据评估结果显示,SAM尽管具备成为通用医学影像分割模型的潜力,但在医学影像分割任务中的表现目前还不够稳定。特别是在全自动Everything的分割模式下,SAM对大多数医学影像分割任务的适应能力较差,其感知医学分割目标的能力有待提高。因此,SAM在医学影像分割领域的应用还需要进一步的研究和改进。
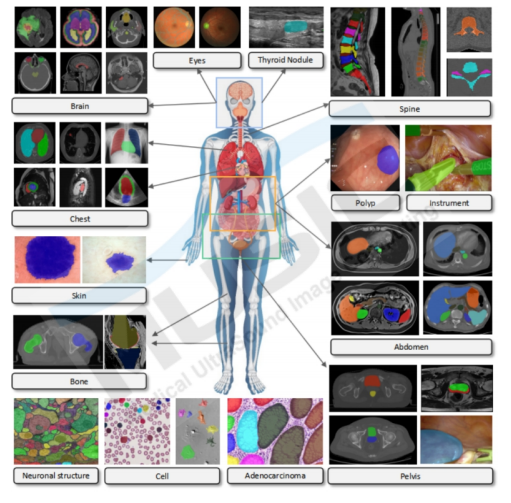
测试 SAM 对医学影像分割性能的数据集 COSMOS 553K 及分割效果
因此在医学影像分割领域,研究重点应该放在如何利用少量医学影像来有效地微调SAM模型以提高其可靠性,并构建一种适用于医学影像的Segment Anything Model。针对这一目标,MedSAM提出一种简单的微调方法,将SAM适应到通用的医学影像分割任务中。通过在21个三维分割任务和9个二维分割任务上进行全面的实验,MedSAM证明其分割效果优于默认的SAM模型。这项研究为医学影像分割提供一种有效的方法,使SAM模型能够更好地适应医学影像的特点,并取得更好的分割结果。
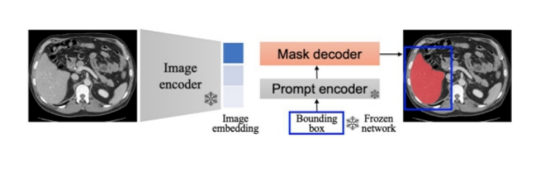
MedSAM 示意图
3)SAM-Track:扩展 SAM 应用领域,增强视频分割性能
最新开源的SAM-Track项目由浙江大学ReLER实验室的科研人员开发,为SAM模型增强在视频分割领域的能力。SAM-Track能够对任意物体进行分割和跟踪,并且支持各种时空场景,例如街景、AR、细胞、动画和航拍等。该项目在单卡上即可实现目标分割和跟踪,能够同时追踪超过200个物体,为用户提供强大的视频编辑能力。
相较于传统的视频分割技术,SAM-Track具有更高的准确性和可靠性。它能够自适应地识别不同场景下的物体,并快速而精确地进行分割和跟踪,从而使用户能够轻松地进行视频编辑和后期制作,实现更出色的视觉效果。总的来说,SAM-Track是在SAM基础上的有意义的研究成果,为视频分割和跟踪领域的研究和应用带来了新的可能性。它的出现为视频编辑、后期制作等领域带来更多机会和挑战。
3、SAM 及衍生模型赋能多场景应用
SAM模型是一种高效且准确的图像分割模型,在计算机视觉领域的应用具有广泛的潜力,可以赋能工业机器视觉领域,实现降本增效、快速训练和减少对数据的依赖。在AR/CR行业、自动驾驶和安防监控领域等赛道,SAM可以用于动态图像的捕捉和分割,尽管可能涉及到技术、算力和伦理隐私方面的挑战,但其发展潜力巨大。
此外,SAM对于一些特定场景的分割任务可能具有困难性,但可以通过微调或适配器模块的使用进行改进。在医学影像和遥感图像处理领域,SAM可以通过简单微调或少量标注数据的训练来适应分割任务。另外,SAM还可以与其他模型或系统结合使用,例如与分类器结合实现物体检测和识别或与生成器结合实现图像编辑和转换。这种结合能够进一步提高图像分割的准确性和效率,为各行业带来更多应用场景。
1)基于 3D 重建,赋能 AR、游戏
在AR/VR领域,SAM模型结合3D重建技术和图像处理算法,为用户提供更加逼真和沉浸的视觉体验。通过SAM模型,用户可以将2D图像转化为3D场景,并在AR或VR设备上进行观察和操控,实现对真实世界的模拟和还原。这样的技术结合为用户带来高度沉浸式的互动体验,能够在虚拟世界中与物体进行互动,享受更加逼真的视觉感受。
此外,SAM模型还结合了深度学习算法,对用户视线和手势识别和跟踪,以实现更智能化互动方式。举例来说,当用户注视某个物体时,SAM模型可以自动聚焦并提供更为详细的信息;当用户做出手势操作时,SAM模型也能够快速响应并实现场景的调整和变化。
2)跟踪运动物体,赋能安防监控
在图像分割领域,SAM是一种高效而准确的模型,能够进行视频和动态图像的分割,并产生SEEM和SAM-Track这两个衍生应用。这些衍生模型充分利用了SAM的零样本泛化能力,通过使用参考图像和用户输入的涂鸦、文字等信息,在模糊或剧烈变形的视频中实现对目标对象的准确分割。
例如,在跑酷、运动和游戏等视频中,传统的图像分割算法往往无法有效处理复杂的背景和快速移动的目标物体。然而,SEEM模型不仅能够准确识别参考对象,还能够消除背景干扰,从而提高分割的精度。简而言之,SAM模型及其相关应用在处理具有动态特征的图像分割问题上表现出出色的性能和准确度。
SEEM 在跑酷、运动、游戏视频中可以准确分割参考对象
除在运动场景中的应用之外,SEEM和SAM-Track还可以赋能安防和视频监控等领域,准确地对视频中的物体进行分割,以便进行后续的识别和处理。SEEM和SAM-Track通过输入的提示信息,能够准确地判断目标物体并进行精确的分割。
3)解决长尾难题,赋能自动驾驶
尽管目前自动驾驶技术已经在90%以上的道路场景下成功实现,但仍然存在10%的长尾场景难题,这主要是由于路况和车辆行驶情况的不可预测性所导致。这些长尾场景包括突发事件、复杂地形和恶劣气候等极端情况,如强降雨、暴风雪和雷电等,对自动驾驶系统的识别和决策能力构成巨大挑战。此外,在城市交通中,还需要考虑非机动车、行人和建筑物等因素对自动驾驶系统的影响。
为了解决长尾问题,自动驾驶技术需要整合更多的算法和传感器,并通过数据采集和深度学习等方法提升系统的智能水平。例如,通过整合雷达、摄像头、激光雷达等传感器的数据来提高对目标物体的识别和跟踪能力。同时,可以利用深度学习算法来模拟和预测复杂场景。此外,引入人工智能技术,让自动驾驶系统在长尾场景中不断学习和优化,以提高其适应性和泛化能力。

城市道路场景中长尾场景较多
在自动驾驶领域,图像分割在感知和理解道路环境中起着关键作用。SAM(Segment Anything Model)可以通过标记和分割图像中的不同物体和区域实现精确的场景感知。传统的手动标注方法耗时且容易出错,而SAM的自动化分割能够大幅降低成本并提高准确性。
SAM在自动驾驶系统中能够实时感知道路标记、车道线、行人、交通信号灯等关键元素。通过与其他深度学习模型结合,如目标检测和路径规划模型,SAM可以准确理解周围环境,帮助自动驾驶系统做出安全、高效的决策。
以行人识别和车道线跟踪为例,SAM能够预测行人和车辆的运动轨迹,帮助减少潜在的交通事故风险。
4)提高分割性能,赋能遥感图像
遥感图像是通过卫星、飞机等遥测手段获取地球表面信息的重要工具,其具备多样性、全覆盖和高精度等特点,在现代科技发展中扮演着不可或缺的角色。遥感图像在环境监测、自然资源管理、城市规划和灾害预警等领域应用广泛。
遥感数据包括光学遥感数据、光谱数据、SAR雷达数据、无人机数据等多种类型。处理遥感数据一般分为两个阶段:第一阶段通过遥感地面处理系统对接收到的卫星数据进行处理,包括大气校正、色彩均匀化和图像裁剪等,以得到可以进一步识别和处理的图像;第二阶段则是在此基础上,对遥感图像进行进一步处理和解译,主要是对图像中的物体进行识别。
由于遥感图像的多样性、复杂性和数据大量的特点,在处理过程中存在许多挑战和困难。
图像处理经历三个阶段:
人工解译阶段:完全依赖标注人员进行图像解释,但这种方法成本高且解译效率低下;
AI+遥感阶段:借助AI技术和算力的支持,有效缓解图像解译难点,并实现了人机协同。随着遥感和测绘等观测平台以及卫星数量的增长,AI与遥感的结合为图像解译提供更多可能性;
遥感大模型时代:随着大型神经网络模型的发布,遥感图像的解译有望进入大模型阶段。

遥感图像处理发展阶段
大型遥感图像分割模型SAM是一项新兴的技术,为遥感图像处理提供全新的方法。基于深度学习算法,SAM能够高效地对遥感图像进行分割、识别和生成,从而显著提升遥感图像解译的效率。利用SAM模型进行遥感图像分割,用户能够快速准确地生成高质量的地图和三维模型,从而提高环境监测和资源管理的效率及精度。此外,SAM模型还支持多源数据的融合,将遥感图像与其他数据相结合,以产生更全面、更精准的分析结果。提高遥感数据处理效率不仅为遥感应用打下坚实基础,也为下游的遥感应用带来更广阔的发展空间。

大模型应用于遥感图像处理
尽管SAM大模型在处理一些困难的遥感图像分割任务时仍然面临挑战,例如在面对阴影、掩体分割和隐蔽动物定位等任务时的准确性较低。遥感图像分割任务需要模型具备更高的感知力和识别能力,SAM模型目前无法完全做到"分割一切",特别是在处理细节方面还有进一步提升的空间。然而,通过不断改进和优化,SAM模型的性能可以提升。
另外,RS-promter是在SAM发布后由专家团队二次创作的一种基于SAM基础模型的遥感图像实例分割的prompt learning方法。这种方法被称为RSPrompter,使SAM能够生成语义可辨别的遥感图像分割结果,而无需手动创建prompt。RSPrompter的目标是自动生成prompt,以自动获取语义实例级别的掩码。这种方法不仅适用于SAM,还可以扩展到其他基础模型。
SAM模型在处理困难的遥感图像分割任务中仍然具有挑战,但通过改进和优化,包括引入更多数据集、采用更先进的神经网络架构以及基于RS-promter的改进方法,可以提高其性能。
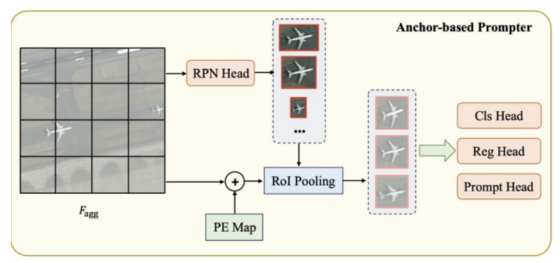
基于锚点的 prompter
研究人员进行了一系列实验来验证RSPrompter的效果。这些实验不仅证明RSPrompter每个组件的有效性,还展示它在三个公共遥感数据集上相较于其他先进的实例分割技术和基于SAM的方法具有更好的性能。
大模型为空天信息产业带来了驱动和挑战
大模型的引入为遥感图像领域带来新的推动力和挑战。在多模态时空遥感数据的应用中,大模型在基于合成孔径雷达(SAR)、光学、多光谱卫星和无人机航拍等方面具有广泛的应用。借助开源大模型基础结构,为遥感数据开展定制化模型研发,实现一站式、全流程的遥感大模型构建能力。另外,大模型支持处理大规模模型参数和标注数据量,实现更高效、精准的遥感数据处理和分析,为影像智能检索与推送、地物智能提取采编、数字孪生产品线等领域提供技术支持。
未来,大模型训练与小模型部署将结合起来,以实现更好的应用效果。传统的图像处理方法难以满足遥感影像处理的要求,因此使用大模型处理遥感图像已成为当前研究的重要方向。SAM模型的赋能进一步提升了遥感图像的意义和应用价值,为该领域的研究和应用带来新的机会和挑战,也为人们更好地认识和利用地球资源提供技术支持。
5)算力应用驱动,赋能机器视觉的功能主要归类为四种:识别、测量、定位、检测
识别
通过识别目标物的特征,如外形、颜色、字符、条码等,实现高速度和高准确度的甄别。
测量
将图像像素信息转化为常用的度量单位,精确计算目标物的几何尺寸。机器视觉在复杂形态测量和高精度方面具有优势。
定位
获取目标物体的二维或三维位置信息。
检测
主要针对外观检测,内容涵盖广泛。例如产品装配后的完整性检测,外观缺陷检测(如划痕、凹凸不平等)。

机器视觉四大功能及难度
机器视觉被称为"智能制造之眼",在工业自动化领域广泛应用。典型的机器视觉系统包括光源、镜头、相机和视觉控制系统(包括视觉处理分析软件和视觉控制器硬件)。根据技术的不同,机器视觉可分为基于硬件的成像技术和基于软件的视觉分析技术。机器视觉的发展受到四大核心驱动力的影响,包括成像、算法、算力和应用。每个方面都对机器视觉的发展起到重要的推动作用,不可或缺。
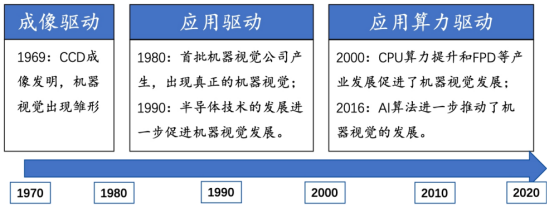
机器视觉发展历程
机器视觉技术的发展受到两大核心驱动力的影响。
应用驱动:随着传统制造业对机器视觉技术的逐步采纳和新兴行业的崛起,机器视觉需求不断增加。在智能制造领域,机器视觉技术可以帮助企业实现自动化生产,提高生产效率和产品质量。在智能医疗领域,机器视觉技术可以辅助医生进行诊断和治疗,提高医疗水平和治疗效果。
算力/算法驱动:随着CPU算力的增长和AI算法的快速进化,特别是深度学习等技术的应用,机器视觉技术在图像处理和分析方面变得更加高效和精确。高性能计算设备的推动和算法的不断进步,为机器视觉技术的发展提供强大支持。
引入AI大模型为机器视觉产业带来重大突破。当前,机器视觉领域采用先进技术,包括深度学习、3D处理与分析、图像感知融合以及硬件加速图像处理等。这些技术和模型大幅提升了机器视觉的智能应用能力,改进图像识别的复杂性和准确性,同时降低成本,提高效率。
基于 AI 的轻量级人脸识别网络,可用于视频实时分析、安防监控等
AI在机器视觉领域有广泛的应用。通过深度学习网络如CNN来实现物体的检测和识别,对图像进行分类理解场景,并提升图像的质量和恢复效果,实现实时分析和异常检测,进行3D重建和增强现实等技术。同时,AI赋予机器视觉“理解”所看到图像的能力,为各种应用场景带来无限的创新和发展机会。
其中,SAM作为一种重要的视觉领域AI大模型,可以在机器视觉领域推动创新和进步。例如,SAM可以直接应用于智慧城市中,提高交通监测、人脸识别等任务的效率。在智能制造领域,SAM可以增强视觉检测和质量控制的能力。此外,SAM还可以与OVD技术结合,自动地生成所需信息,加强语义理解能力,从而增强用户的交互体验。综上所述,AI在机器视觉领域的应用以及SAM模型的运用都为各个领域带来了巨大的潜力和机遇。
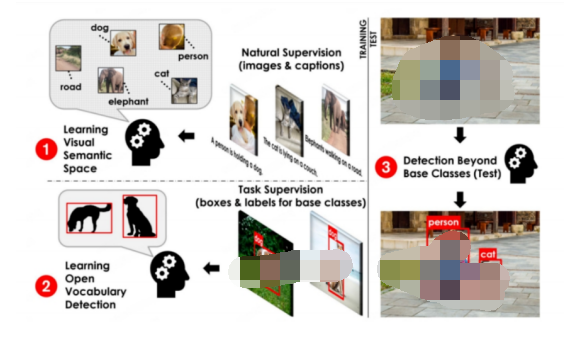
OVD 目标检测基本流程
SAM大模型环境配置
要部署 "Segment Anything Model",需要按以下步骤进行操作:
收集和标记训练数据:收集模型进行分割的对象的图像数据,并进行标记。
进行数据预处理:在训练之前,对图像进行预处理(调整图像的大小、剪裁不相关的区域或应用增强技术)以提高模型的准确性和泛化能力。
构建和训练模型:选择适合的模型,并使用预处理后的数据进行训练(合适的网络架构、调整超参数和优化模型的损失函数)。
模型评估和调优:对训练完成的模型进行评估,确保其在分割任务上的性能。可以进行模型调优,如调整阈值、增加训练数据或使用迁移学习等技术。
部署和推理:将训练好的模型部署到目标环境中,并使用新的图像数据进行推理。
以下是具体操作流程:
请确保系统满足以下要求:Python版本大于等于3.8,PyTorch版本大于等于1.7,torchvision版本大于等于0.8。
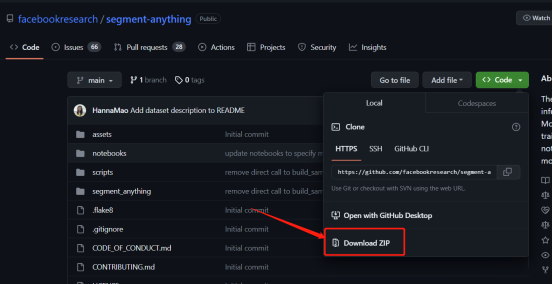
可以参考官方教程来进行操作:https://github.com/facebookresearch/segment-anything
一、以下是安装主要库的几种方式:
1、使用pip安装(需要配置好Git):
Pip install
git+https://github.com/facebookresearch/segment-anything.git
2、本地安装(需要配置好Git):
git clone git@github.com:facebookresearch/segment-anything.git
cd segment-anything
pip install -e .
3、手动下载+手动本地安装:
私信小助手获取zip文件,并解压后运行以下命令:
cd segment-anything-main
pip install -e .
二、安装依赖库:
为了安装依赖库,可以运行以下命令:
pip install opencv-python pycocotools matplotlib onnxruntime onnx
请注意,如果您在安装matplotlib时遇到错误,可以尝试安装特定版本的matplotlib,如3.6.2版本。可以使用以下命令安装指定版本的matplotlib:
pip install matplotlib==3.6.2
三、下载权重文件:
您可以从以下链接中下载三个权重文件中的一个:
1、default 或 vit_h:ViT-H SAM 模型。
2、vit_l:ViT-L SAM 模型。
3、vit_b:ViT-B SAM 模型。
如果您发现下载速度过慢,请私信小助手获取权重文件。
通过下载并使用其中一个权重文件,将能够在 "Segment Anything" 模型中使用相应的预训练模型。
如何配置训练SAM模型服务器
在计算机视觉领域,图像分割是一个关键的任务,涉及将图像中的不同对象或区域进行准确的分割。SAM模型作为一种基于CV领域的ChatGPT,为图像分割任务提供强大的能力。然而,要使用SAM模型,需要配置适合SAM环境的服务器,并满足SAM模型对计算资源和存储空间的需求。
配置适合SAM环境的服务器是充分利用SAM模型优势的关键。为满足SAM模型对计算资源和存储空间的需求,需要确保服务器具备足够的CPU和GPU资源、存储空间和高性能网络连接。
一、计算资源需求
由于SAM模型依赖于深度学习算法,需要进行大规模的矩阵运算和神经网络训练。因此通常需要大量的计算资源来进行高效的图像分割。所以配置SAM环境时,需要确保服务器具备足够的CPU和GPU资源来支持SAM模型的计算需求。特别是在处理大规模图像数据集时,服务器需要具备较高的并行计算能力,以确保模型的高效运行。
1、GPU
1)GPU内存:SAM模型需要大量的内存来存储模型参数和图像数据。因此,选择足够内存容量的GPU是至关重要的。
2)GPU计算能力:SAM模型依赖于深度学习算法,需要进行大规模的矩阵运算和神经网络训练。因此,选择具有较高计算能力的GPU可以提高SAM模型的运行效率。例如,选择具有较多CUDA核心和高时钟频率的GPU。
2、CPU
虽然GPU在SAM模型中扮演着重要的角色,但CPU也是服务器配置中不可忽视的组件。在SAM模型中,CPU主要负责数据的预处理、模型的加载和其他非计算密集型任务。因此,在选择CPU时,需要考虑以下几个因素:
1)CPU核心数量:由于CPU可以并行处理多个任务,所以选择具有较多核心的CPU可以提高SAM模型的整体性能。
2)CPU时钟频率:SAM模型的预处理和其他非计算密集型任务通常需要较高的时钟频率。因此,选择具有较高时钟频率的CPU可以加快这些任务的执行速度。
3、常用CPU+GPU推荐
1)AMD EPYC 7763 + Nvidia A100 80GB
AMD 7763是64核心的高端EPYC芯片,A100 80GB单卡内存高达80GB,可以支持大模型的训练。
2)双AMD EPYC 7742 + 8张 AMD Instinct MI50
7742是AMD的前一代32核心服务器CPU,双CPU可以提供64核心。MI50是AMD较高端的GPU,具有16GB内存,8张可以提供充足的计算资源。
3)双Intel Xeon Platinum 8280 + 8张 Nvidia V100 32GB
8280是Intel Scalable系列的28核心旗舰CPU,双CPU提供56核心。V100 32GB单卡32GB内存。
4)AMD EPYC 7713 + 8张 Nvidia RTX A6000
RTX A6000基于Ampere架构,具有48GB内存,相比A100更经济且内存也足够大。
5)双Intel Xeon Gold 6300 + 8张 AMD Instinct MI100
Intel Xeon Gold 6300系列提供较低成本的多核心Xeon CPU,MI100配合使用可以达到比较好的性价比。
6)对于CPU,AMD EPYC 7003系列处理器是一个不错的选择。这是AMD的第三代EPYC服务器CPU,使用TSMC 5nm制程,拥有高达96个Zen 3核心,提供强大的多线程处理性能。具体型号可以选择72核心的EPYC 7773X或64核心的EPYC 7713。
对于GPU,Nvidia的A100 Tensor Core GPU是目前训练大型神经网络的首选。它基于Ampere架构,具有高达6912个Tensor Core,可以提供高达19.5 TFLOPS的Tensor浮点性能。可以配置4-8块A100来满足训练需求。
另外,AMD的Instinct MI100 GPU也是一个不错的选择。它使用CDNA架构,具有120个计算单元,可以提供高达11.5 TFLOPS的半精度浮点性能。相比A100更经济高效。
4、存储需求
SAM模型在进行图像分割任务时,需要加载和存储大量的模型参数和图像数据。因此,服务器需要具备足够的存储空间来存储SAM模型和相关数据。此外,为了提高SAM模型的运行效率,我们还可以考虑使用高速存储设备,如SSD(固态硬盘),以加快数据的读取和写入速度。
5、高性能网络需求
SAM模型在进行图像分割任务时,需要通过网络接收和发送大量的数据。因此,服务器需要具备高速、稳定的网络连接,以确保数据的快速传输和模型的实时响应能力。特别是在处理实时图像分割任务时,服务器需要具备低延迟和高带宽的网络连接,以满足实时性的要求。
蓝海大脑大模型训练平台
蓝海大脑大模型训练平台提供强大的算力支持,包括基于开放加速模组高速互联的AI加速器。配置高速内存且支持全互联拓扑,满足大模型训练中张量并行的通信需求。支持高性能I/O扩展,同时可以扩展至万卡AI集群,满足大模型流水线和数据并行的通信需求。强大的液冷系统热插拔及智能电源管理技术,当BMC收到PSU故障或错误警告(如断电、电涌,过热),自动强制系统的CPU进入ULFM(超低频模式,以实现最低功耗)。致力于通过“低碳节能”为客户提供环保绿色的高性能计算解决方案。主要应用于深度学习、学术教育、生物医药、地球勘探、气象海洋、超算中心、AI及大数据等领域。

一、为什么需要大模型?
1、模型效果更优
大模型在各场景上的效果均优于普通模型
2、创造能力更强
大模型能够进行内容生成(AIGC),助力内容规模化生产
3、灵活定制场景
通过举例子的方式,定制大模型海量的应用场景
4、标注数据更少
通过学习少量行业数据,大模型就能够应对特定业务场景的需求
二、平台特点
1、异构计算资源调度
一种基于通用服务器和专用硬件的综合解决方案,用于调度和管理多种异构计算资源,包括CPU、GPU等。通过强大的虚拟化管理功能,能够轻松部署底层计算资源,并高效运行各种模型。同时充分发挥不同异构资源的硬件加速能力,以加快模型的运行速度和生成速度。
2、稳定可靠的数据存储
支持多存储类型协议,包括块、文件和对象存储服务。将存储资源池化实现模型和生成数据的自由流通,提高数据的利用率。同时采用多副本、多级故障域和故障自恢复等数据保护机制,确保模型和数据的安全稳定运行。
3、高性能分布式网络
提供算力资源的网络和存储,并通过分布式网络机制进行转发,透传物理网络性能,显著提高模型算力的效率和性能。
4、全方位安全保障
在模型托管方面,采用严格的权限管理机制,确保模型仓库的安全性。在数据存储方面,提供私有化部署和数据磁盘加密等措施,保证数据的安全可控性。同时,在模型分发和运行过程中,提供全面的账号认证和日志审计功能,全方位保障模型和数据的安全性。
三、常用配置
目前大模型训练多常用H100、H800、A800、A100等GPU显卡,以下是一些常用的配置。
1、H100服务器常用配置
英伟达H100 配备第四代 Tensor Core 和 Transformer 引擎(FP8 精度),与上一代产品相比,可为多专家 (MoE) 模型提供高 9 倍的训练速度。通过结合可提供 900 GB/s GPU 间互连的第四代 NVlink、可跨节点加速每个 GPU 通信的 NVLINK Switch 系统、PCIe 5.0 以及 NVIDIA Magnum IO™ 软件,为小型企业到大规模统一 GPU 集群提供高效的可扩展性。
搭载 H100 的加速服务器可以提供相应的计算能力,并利用 NVLink 和 NVSwitch 每个 GPU 3 TB/s 的显存带宽和可扩展性,凭借高性能应对数据分析以及通过扩展支持庞大的数据集。通过结合使用 NVIDIA Quantum-2 InfiniBand、Magnum IO 软件、GPU 加速的 Spark 3.0 和 NVIDIA RAPIDS™,NVIDIA 数据中心平台能够以出色的性能和效率加速这些大型工作负载。
CPU:英特尔至强Platinum 8468 48C 96T 3.80GHz 105MB 350W *2
内存:动态随机存取存储器64GB DDR5 4800兆赫 *24
存储:固态硬盘3.2TB U.2 PCIe第4代 *4
GPU :Nvidia Vulcan PCIe H100 80GB *8
平台 :HD210 *1
散热 :CPU+GPU液冷一体散热系统 *1
网络 :英伟达IB 400Gb/s单端口适配器 *8
电源:2000W(2+2)冗余高效电源 *1
2、A800服务器常用配置
NVIDIA A800 的深度学习运算能力可达 312 teraFLOPS(TFLOPS)。其深度学习训练的Tensor 每秒浮点运算次数(FLOPS)和推理的 Tensor 每秒万亿次运算次数(TOPS)皆为NVIDIA Volta GPU 的 20 倍。采用的 NVIDIA NVLink可提供两倍于上一代的吞吐量。与 NVIDIA NVSwitch 结合使用时,此技术可将多达 16 个 A800 GPU 互联,并将速度提升至 600GB/s,从而在单个服务器上实现出色的应用性能。NVLink 技术可应用在 A800 中:SXM GPU 通过 HGX A100 服务器主板连接,PCIe GPU 通过 NVLink 桥接器可桥接多达 2 个 GPU。
CPU:Intel 8358P 2.6G 11.2UFI 48M 32C 240W *2
内存:DDR4 3200 64G *32
数据盘:960G 2.5 SATA 6Gb R SSD *2
硬盘:3.84T 2.5-E4x4R SSD *2
网络:双口10G光纤网卡(含模块)*1
双口25G SFP28无模块光纤网卡(MCX512A-ADAT )*1
GPU:HV HGX A800 8-GPU 8OGB *1
电源:3500W电源模块*4
其他:25G SFP28多模光模块 *2
单端口200G HDR HCA卡(型号:MCX653105A-HDAT) *4
2GB SAS 12Gb 8口 RAID卡 *1
16A电源线缆国标1.8m *4
托轨 *1
主板预留PCIE4.0x16接口 *4
支持2个M.2 *1
原厂质保3年 *1
3、A100服务器常用配置
NVIDIA A100 Tensor Core GPU 可针对 AI、数据分析和 HPC 应用场景,在不同规模下实现出色的加速,有效助力更高性能的弹性数据中心。A100 采用 NVIDIA Ampere 架构,是 NVIDIA 数据中心平台的引擎。A100 的性能比上一代产品提升高达 20 倍,并可划分为七个 GPU 实例,以根据变化的需求进行动态调整。A100 提供 40GB 和 80GB 显存两种版本,A100 80GB 将 GPU 显存增加了一倍,并提供超快速的显存带宽(每秒超过 2 万亿字节 [TB/s]),可处理超大型模型和数据集。
CPU:Intel Xeon Platinum 8358P_2.60 GHz_32C 64T_230W *2
RAM:64GB DDR4 RDIMM服务器内存 *16
SSD1:480GB 2.5英寸SATA固态硬盘 *1
SSD2:3.84TB 2.5英寸NVMe固态硬盘 *2
GPU:NVIDIA TESLA A100 80G SXM *8
网卡1:100G 双口网卡IB 迈络思 *2
网卡2:25G CX5双口网卡 *1
4、H800服务器常用配置
H800是英伟达新代次处理器,基于Hopper架构,对跑深度推荐系统、大型AI语言模型、基因组学、复杂数字孪生等任务的效率提升非常明显。与A800相比,H800的性能提升了3倍,在显存带宽上也有明显的提高,达到3 TB/s。
虽然论性能,H800并不是最强的,但由于美国的限制,性能更强的H100无法供应给中国市场。有业内人士表示,H800相较H100,主要是在传输速率上有所差异,与上一代的A100相比,H800在传输速率上仍略低一些,但是在算力方面,H800是A100的三倍。
CPU:Intel Xeon Platinum 8468 Processor,48C64T,105M Cache 2.1GHz,350W *2
内存 :64GB 3200MHz RECC DDR4 DIMM *32
系统硬盘: intel D7-P5620 3.2T NVMe PCle4.0x4 3DTLCU.2 15mm 3DWPD *4
GPU: NVIDIA Tesla H800 -80GB HBM2 *8
GPU网络: NVIDIA 900-9x766-003-SQO PCle 1-Port IB 400 OSFP Gen5 *8
存储网络 :双端口 200GbE IB *1
网卡 :25G网络接口卡 双端口 *1
5、A6000服务器常用配置
CPU:AMD EPYC 7763 64C 2.45GHz 256MB 280W*2
内存:64GB DDR4-3200 ECC REG RDIMM*8
固态盘:2.5" 960GB SATA 读取密集 SSD*1
数据盘:3.5" 10TB 7200RPM SATA HDD*1
GPU:NVIDIA RTX A6000 48GB*8
平台:
机架式4U GPU服务器,支持两颗AMD EPYC 7002/7003系列处理器,最高支持280W TDP,最大支持32根内存插槽支持8个3.5/2.5寸热插拔SAS/SATA/SSD硬盘位(含2个NVMe混合插槽),可选外插SAS或RAID卡,支持多种RAID模式,独立IPMI管理接口,11xPCIe 4.0插槽。
2200W(2+2)冗余钛金电源(96%转换效率),无光驱,含导轨
6、AMD MI210服务器常用配置
CPU:AMD EPYC 7742 64C 2.25GHz 256MB 225W *2
内存:64GB DDR4-3200 ECC REG RDIMM*8
固态盘:2.5" 960GB SATA 读取密集 SSD*1
数据盘:3.5" 10TB 7200RPM SATA HDD*1
GPU:AMD MI210 64GB 300W*8
平台:
机架式4U GPU服务器,支持两颗AMD EPYC 7002/7003系列处理器,最高支持280W TDP,最大支持32根内存插槽支持8个3.5/2.5寸热插拔SAS/SATA/SSD硬盘位(含2个NVMe混合插槽),可选外插SAS或RAID卡,支持多种RAID模式,独立IPMI管理接口,11xPCIe 4.0插槽。
2200W(2+2)冗余钛金电源(96%转换效率),无光驱,含导轨
7、AMD MI250服务器常用配置
CPU: AMD EPYC™ 7773X 64C 2.2GHz 768MB 280W *2
内存:64GB DDR4-3200 ECC REG RDIMM*8
固态盘:2.5" 960GB SATA 读取密集 SSD*1
数据盘:3.5" 10TB 7200RPM SATA HDD*1
GPU:AMD MI250 128GB 560W*6
平台:
机架式4U GPU服务器,支持两颗AMD EPYC 7002/7003系列处理器,最高支持280W TDP,最大支持32根内存插槽支持8个3.5/2.5寸热插拔SAS/SATA/SSD硬盘位(含2个NVMe混合插槽),可选外插SAS或RAID卡,支持多种RAID模式,独立IPMI管理接口,11xPCIe 4.0插槽。
2200W(2+2)冗余钛金电源(96%转换效率),无光驱,含导轨
审核编辑 黄宇
-
amd
+关注
关注
25文章
5647浏览量
138998 -
人工智能
+关注
关注
1813文章
49734浏览量
261399 -
SAM
+关注
关注
0文章
116浏览量
34312 -
高性能计算
+关注
关注
0文章
95浏览量
13760 -
大模型
+关注
关注
2文章
3440浏览量
4960
发布评论请先 登录
【「大模型启示录」阅读体验】+开启智能时代的新钥匙
鸿蒙原生页面高性能解决方案上线OpenHarmony社区 助力打造高性能原生应用
适用于数据中心和AI时代的800G网络
NVIDIA火热招聘GPU高性能计算架构师
智能网卡简介及其在高性能计算中的作用
DGX SuperPOD助力助力织女模型的高效训练
如何将高性能计算和科学计算应用软件更好的部署到GPU计算平台
如何在GPU资源受限的情况下训练transformers库上面的大模型
AIGC大模型时代下,该如何应用高性能计算PC集群打造游戏开发新模式?






 工商网监
工商网监
评论