 嘉楠开源通用大语言模型Toucan中的INT4量化技术解析
嘉楠开源通用大语言模型Toucan中的INT4量化技术解析

ChatGPT与其之后不断涌现的大语言模型(LLM)迅速席卷了整个时代。随着计算机对人类自然语言的领悟程度突飞猛进,我们与计算机的交互方式正在迅速而深刻地改变着,这也即将带来一场既广泛又具有极强创新性的商业模式转型。
嘉楠科技(Canaan)是一家领先的ASIC芯片设计公司,也是第一家在美上市的中国自主知识产权AI芯片公司。嘉楠科技希望通过ASIC技术“提升社会运行效率,改善人类生活方式”,并成为区块链和AI高性能计算的领导者。
2023年6月30日,嘉楠科技正式发布参数量70亿的通用大语言模型Toucan-7B及INT4量化版本的Toucan-7B-4bit。其中,Toucan-7B基于LLaMA预训练权重进行指令微调,能够实现文案写作、代码解析、信息抽取等各种通用自然语言处理任务。Toucan-7B-4bit基于当前最新量化技术对Toucan-7B实现极低损失的INT4量化。此外,Toucan-7B是基于GTX-3090单卡GPU实现所有的实验流程,是真正方便每位开发者所使用的通用LLM模型。
Toucan模型精度
评估大语言模型的效果本身就是一个复杂的课题。目前还没有公认的、严格的科学评估标准。
Toucan采用开源的专业中文测试集BELLE进行效果评估,涵盖数学推理、代码解析、文本分类等多个维度。ChatGPT的表现作为参考基准。通过人工评估ChatGPT的表现,可以直观地判断不同模型的优劣。
ChatGLM(清华开源LLM模型)是国内首批开源的通用大语言模型,也是最优秀的中文大语言模型之一。因此,在Toucan的评估过程中,我们将主要以ChatGLM的表现作为参考,来衡量不同模型的效果,从而给出一个相对公正的评估结果。

如上表所示,Toucan-7B的效果略微优于ChatGLM-6B,并且Toucan-7B-4bit模型的效果也能够达到与ChatGLM-6B持平的水准。此外,我们可以发现:Toucan的强项是code任务与re-write任务,并且rewrite能力评分甚至超过ChatGPT。
上述对比验证了Toucan在多个维度上展现出色的语言理解与生成能力,这说明Toucan作为通用语言模型,具有较强的应用潜力。当然,大语言模型之间的对比评估是一个复杂的过程,不存在一个模型在所有方面都占绝对优势。我们会继续致力于完善评估方案,以更全面地判断模型的优劣。
Toucan模型INT4量化
如上节所述,Toucan-7B-4bit模型基于当前最前沿的INT4量化技术,实现了对Toucan-7B模型的近乎无损量化。本节对Toucan-7B-4bit模型中所使用的INT4量化技术进行简单介绍。
Toucan-7B-4bit模型中使用了GPTQ和VS-Quant两种IN4量化技术。GPTQ是一种one-shot PTQ 方法。不同于之前使用统计手段(如 kl-divergence)获得最小/最大值量化参数,GPTQ 先计算权重的Hessian 矩阵,再结合此矩阵和局部量化结果,逐步迭代权重。在物理意义上,Hessian 矩阵对角线数值,表示多元函数沿坐标轴方向的曲率。因此相对于统计量化方法,GPTQ 更具有说服力。VS-Quant技术使用更细粒度的缩放因子,为每个小向量(16-64个元素)使用一个独立的缩放因子,这可以提高每个元素的有效精度。并通过两级量化和训练,可以用低比特宽的整数来表示这些向量缩放因子。
这里4bit量化技术主要用于减小模型尺寸,降低显存容量和带宽占用,计算时需要反量化成fp16再进行计算。LLM推理,通常都是带宽和显存容量受限,计算并不是问题。
我们将Toucan-7B-4bit模型和Toucan-7B-fp16模型的实测显存占用量进行了对比:
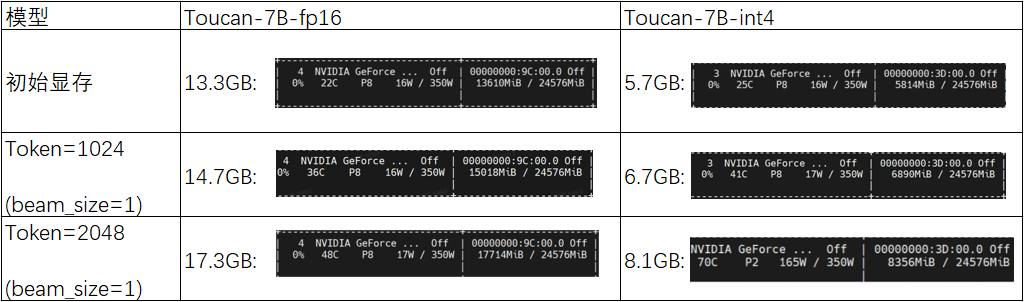
通过上表对比可以发现:在初始阶段,Toucan-7B-fp16模型的显存占用量为13.3GB,而Toucan-7B-int4模型的显存占用量仅为5.7GB;随着模型迭代推理的逐步进行,当Token长度达到1024时,Toucan-7B-fp16模型的显存占用量上至14.7GB,而Toucan-7B-int4模型的显存占用量仍维持在6.7GB;当达到模型支持的最大输入长度2048时,Toucan-7B-fp16模型的显存占用量达到了17.3GB,而Toucan-7B-int4模型的显存占用量仅为8.1GB。
Toucan-7B-int4模型可以在低显存占用的情况下大语言模型推理,这对采用消费级显卡的用户更为友好。在Toucan开源仓库中,嘉楠科技开源了Toucan-7B-4bit模型的量化参数生成代码以及量化模型推理代码,感兴趣的开发者可进行详细阅读相关内容。
Toucan单显卡训练
Toucan详细技术文档及代码见该开源仓库如下:
https://github.com/kendryte/Toucan-LLM:
如上图所示,为Toucan开源仓库的目录结构。在Toucan开源仓库中,更新了全参数微调训练代码、基于Gradio的推理代码、INT4量化代码,以及模型合并代码。微调后的浮点模型也有开源,可下载合并后使用。
启动训练:bash train/run.sh
推理:pythonscripts/demo.py
模型权重合并:
pythonscripts/apply_delta.py--base/path_to_llama/llama-7b-hf--target./save_path/toucan-7b--delta/path_to_delta/toucan-7b-delta/
Toucan模型能力展示
因为篇幅所限,我们在这里仅展示Toucan的部分能力。感兴趣的读者可以去Github-Toucan-LLM了解更多。
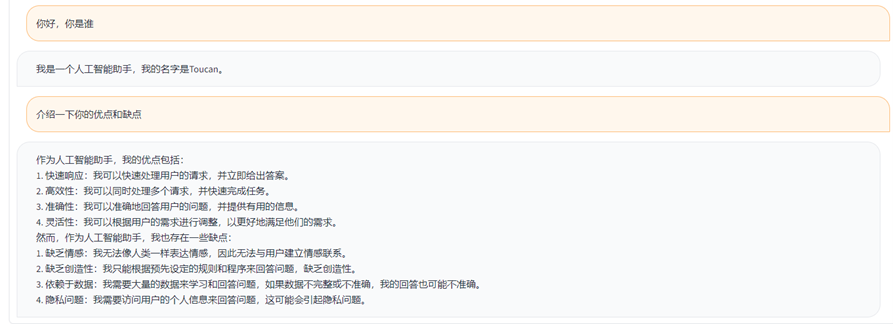
(1)自我介绍
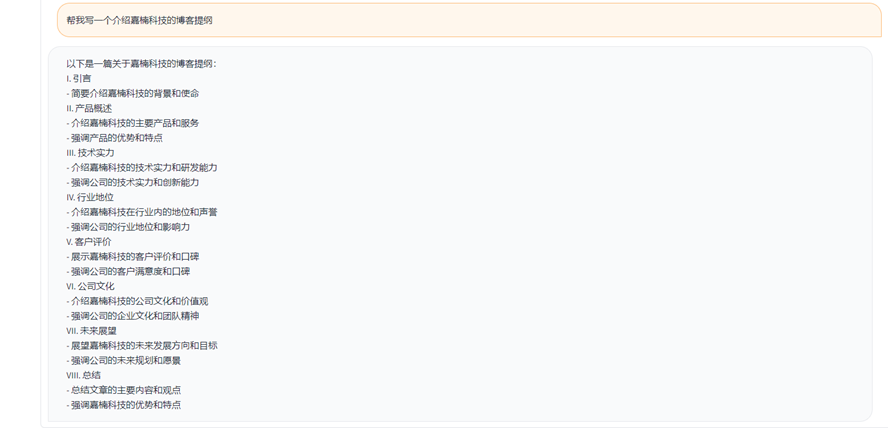
(2)写作助手
(3)信息抽取
(4)代码解析
加入我们
我们相信开源对技术进步具有重要意义,也希望Toucan能为推进开源大语言模型贡献一份力量。我们欢迎和鼓励开发者在Toucan代码库的基础上进行创造,无论是模型效果的提升还是应用场景的拓展。
在LLM时代,我们仍处在技术快速进步的早期阶段。加入开源力量。在开放、协作的开源社区中,每一份贡献都将变成技术进步的阶梯。
我们期待您的加入,与我们一同推动LLM和其他前沿技术的开源之旅!
审核编辑:汤梓红
-
asic
+关注
关注
34文章
1282浏览量
125105 -
芯片设计
+关注
关注
15文章
1186浏览量
56832 -
AI
+关注
关注
91文章
42161浏览量
303161 -
开源
+关注
关注
3文章
4431浏览量
46608 -
语言模型
+关注
关注
0文章
575浏览量
11378
原文标题:嘉楠开源通用大语言模型Toucan 且INT4量化效果媲美ChatGLM
文章出处:【微信号:CanaanTech,微信公众号:嘉楠科技】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
香蕉派 BPI-CanMV-K230D-Zero 采用嘉楠科技 K230D RISC-V芯片设计
香蕉派开发板BPI-CanMV-K230D-Zero 嘉楠科技 RISC-V开发板公开发售
为什么无法在GPU上使用INT8 和 INT4量化模型获得输出?
使用 NPU 插件对量化的 Llama 3.1 8b 模型进行推理时出现“从 __Int64 转换为无符号 int 的错误”,怎么解决?
【作品合集】嘉楠科技01 Studio K230开发板测评
华秋电子与嘉楠科技合作,推广勘智全系AI产品
重磅!华秋电子与嘉楠科技正式签订合作协议
华秋电子与嘉楠科技签订合作协议,7月起嘉楠系列产品陆续上线华秋商城
华秋电子与嘉楠科技正式签订合作协议,在开源生态、媒体社区等多领域开展深入合作
NCNN+Int8+yolov5部署和量化

深度解析MegEngine 4 bits量化开源实现
英伟达:5nm实验芯片用INT4达到INT8的精度
类GPT模型训练提速26.5%,清华朱军等人用INT4算法加速神经网络训练




评论