 分布式存储:GPFS与Ceph对比
分布式存储:GPFS与Ceph对比

1. GPFS和CEPH的初次亮相
GPFS,是一个高性能的共享并行文件系统,自诞生起,就为高性能、数据共享、开放、安全而生。为了更好的融入IBM光谱存储大家庭,我有了个更好听的名字——SPECTRUM SCALE,当然对于我来说,这不仅仅是名字的变更,也意味在我身上,增加了关于闪存、容灾、备份、云平台接入等诸多特性,我扮演的角色更加重要,职能定位也愈加明晰了。关于未来,我也有自己的想法,有更大的愿景,希望能和数据中心的其它小朋友们相处愉快,和谐。
CEPH,是一个00后,名字来源于宠物章鱼的一个绰号,头像就是一只可爱的软体章鱼,有像章鱼触角一样并发的超能力。我平常主要活跃在云计算领域,经过多年的脱胎换骨,不断迭代,我积攒了良好的口碑,好用,稳定,关键还免费,我可以提供对象,块和文件级存储的接口,几乎可以覆盖所有…哇,说着说着突然感觉自己原来无所不能呢,当然,目前我还在长身体的阶段,很多特性在趋于完善,希望未来我们可以相互促进成长。
2. GPFS的前世今生
作为一款成熟的商业产品,GPFS的发展史早已百转千回了,在揭开GPFS的面纱之前,我们还是先来扫扫盲,复习一下在GPFS集群架构中涉及到的基本概念和组件。
GPFS架构解藕
a) Cluster:GPFS的组成架构,由一系列的节点和NSD组成,集群的配置文件通常保存在两台主备的节点上。
b) Node:安装了GPFS软件的主机,它可以通过直接或者通过网络访问其它节点的方式来访问存储,每个节点在集群配置中有不同的角色。
c) Cluster manager:负责整个集群配置的正确性和完整性,主要负责监控磁盘租约,检测节点故障和控制节点的故障恢复,共享配置信息,选举文件管理节点等任务。
d) File system manager:维护文件系统中磁盘的可用性信息,管理磁盘空间,文件系统配置,磁盘配额等。
e) Block:一个集群中单个I/O操作和空间分配的最大单位。
f) NSD:提供全局数据访问的集群组件,如果节点和磁盘间没有直接连接,则NSD最好具有主服务节点和辅服务节点。
g) Chunk: FPO架构中的概念,它是一组block块的集合,看起来像一个大的block,一般用于大数据环境。
h) Failure Group:一组共享故障的磁盘组,当其中一块盘失效时,整个组会同时失效。
i) Metadata:包括集群配置信息和非用户数据。
j) Quorum Nodes:用于保持集群活动的仲裁节点,一般有两种仲裁方式,节点仲裁和带Tiebreakerdisk(心跳盘)的仲裁
上述组件如何有机的组合在一起提供存储服务呢,把以上组件拼接起来,就可以得到下图所示的集群大体架构:
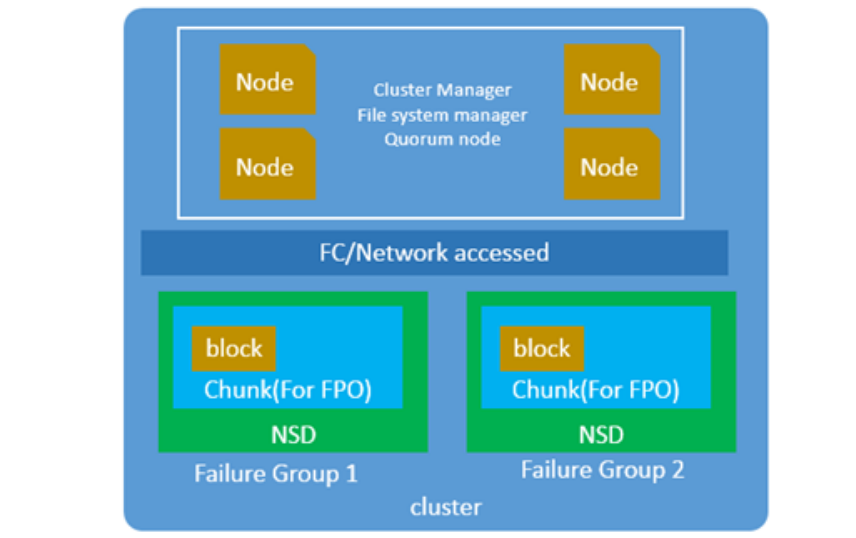
GPFS使用方案
基本架构了解了,那怎么用呢?先祭出三张架构图,业内人士一看应该懂,不明白没关系,往下针对这几张图稍作解释:
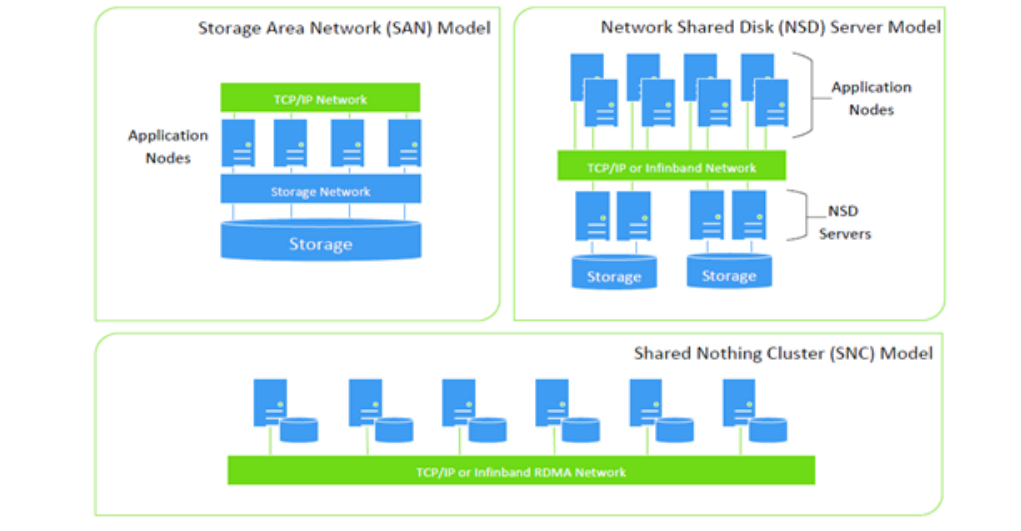
GPFS在系统架构设计十分灵活,丰富的功能延伸出了多种组网方式,而每种组网方式适配不同的应用模式,常见组网方式包括SAN、NSD、SNC、Remote Cluster和混合组网方式。
Storage Area Network(SAN) Model要求计算节点直接挂载存储,并且充当计算节点、NSD Server、NSD Client三种角色。NSD Server通过存储网络或直连的方式连接到存储设备上,前端通信协议为GE,后端通信协议为FC或Infiniband,适用于小规模集群。
Network Shared Disk(NSD) Server Model要求计算节点安装GPFS软件,并充当NSD Client角色,使用单独的服务器充当NSD Server,负责处理I/O。NSD磁盘BuildingBlock的方式,每两台服务器通过直连的方式连接到NSD Server上,前端通信协议为10GE或Infiniband,后端通信协议为FC或Infiniband,适用于大规模集群扩展。
Shared Nothing Cluster(SNC)Model要求计算节点安装GPFS软件,并充当NSD Client角色,使用单独的服务器充当NSD Server,负责处理I/O。NSD采用服务器自带硬盘,或者独立存储,数据之间不使用宽条带方式进行分布,而采用FPO方式进行排布。前端通信协议为10GE或Infiniband,后端通信协议为FC或Infiniband。适用于Hadoop和Mapreduce环境。
Remote Cluster Mount Model要求GPFS提供在多个GPFS集群间共享数据的服务,GPFS在其他集群mount本集群的资源,其访问磁盘和本地访问磁盘体验类似,这种跨集群访问可以是在一个数据中心也可以是跨远距离的WAN。在一个多集群配置中每个集群可以进行分别的管理,在简化管理的同时提供一个多组织数据访问的视图。前端通信协议为10GE或Infiniband,后端通信协议为FC或Infiniband,适用于同城或异地部署环境。
混合组网环境下,GPFS允许在一个集群中混合部署多种组网环境,例如集群中部分主机采用Storage Area Network (SAN) Model,部分主机采用Network Shared Disk (NSD) Server Model方式进行组网。当多个组网类型同时存在于一个集群中时,影响的只是集群使用NSD的方式,对于上层主机对数据的访问没有影响。
GPFS应用场景
在传统DB2数据库双活方案GDPC的使用场景中,为了实现跨站点的双活+容灾,底层存储方案选用GPFS,双站点架构中,两个站点均配备主机和存储资源,每个站点的存储形成一个failure group, 远程访问对端存储采用nsd server的方式访问,两个failure group间完全冗余,任何一个站点出现故障都不影响文件系统的正常使用,并通过第三方站点的一台服务器和nsd作为仲裁节点,是真正意义上的双活。
GPFS可以用来替代HDFS作为大数据的底层存储,GPFS FPO+Symphony作为相对Mapreduce更领先的分布式计算框架,可以更灵活和支持和对接企业的IT使用场景。
在IBM的部分企业级云产品中,GPFS FPO也被用来作为私有云产品的底层存储来使用,用来存储虚机镜像和介质,这一点上使用和CEPH也极为相似。
3.CEPH的发展之路
作为云计算的三架马车,网络,存储,管理平台,业界的开源方案里,网络层面SDN日渐成熟,管理平台上,Openstack已经创造了一个时代,而CEPH,无疑成为存储最犀利的开源解决方案。谈起它的架构之前,我们有必要先来了解以下这些概念,同时为了更加形象化,我们将部分组件对应到GPFS的组件上来理解,但请注意实际的功能和结构仍然差别巨大。
CEPH架构解藕
a) Ceph monitor——对应quorum + cluster manager:保存CEPH的集群状态映射,维护集群的健康状态。它分别为每个组件维护映射信息,包括OSD map、MON map、PG map和CRUSH map。所有群集节点都向MON节点汇报状态信息,并分享它们状态中的任何变化。Ceph monitor不存储数据,这是OSD的任务。
b) OSD——对应NSD: CEPH的对象存储设备,只要应用程序向Ceph集群发出写操作,数据就会被以对象形式存储在OSD中。这是Ceph集群中唯一能存储用户数据的组件,同时用户也可以发送读命令来读取数据。通常,一个OSD守护进程会被绑定到集群中的一块物理磁盘,一块磁盘启动一个OSD进程,可以对应GPFS的NSD概念。
c) Pool:是存储对象的逻辑分区,它规定了数据冗余的类型和对应的副本分布策略,副本支持两种类型:副本(replicated)和 纠删码(Erasure Code)
d) PG(placement group)——对应Chunk:是一个放置策略组,它是对象的集合,该集合里的所有对象都具有相同的放置策略;简单点说就是相同PG内的对象都会放到相同的硬盘上;PG是ceph的核心概念, 服务端数据均衡和恢复的最小粒度就是PG;
e) MDS——对应Filesystem manager:Ceph元数据服务器,MDS只为CephFS文件系统跟踪文件的层次结构和存储元数据。Ceph块设备和RADOS并不需要元数据,因此也不需要Ceph MDS守护进程。MDS不直接提供数据给客户端,从而消除了系统中的故障单点。
f) RADOS:RADOS是Ceph存储集群的基础。在Ceph中,所有数据都以对象形式存储,并且无论是哪种数据类型,RADOS对象存储都将负责保存这些对象。RADOS层可以确保数据始终保持一致。要做到这一点,须执行数据复制、故障检测和恢复,以及数据迁移和在所有集群节点实现再平衡。g) RBD:RADOS块设备,提供持久块存储,它是自动精简配置并可调整大小的,而且将数据分散存储在多个OSD上。RBD服务已经被封装成了基于librados的一个原生接口。
h) RGW:RADOS网关接口,RGW提供对象存储服务。它使用librgw和librados,允许应用程序与Ceph对象存储建立连接。RGW提供了与Amazon S3和OpenStack Swift兼容的RESTful API。
i) CephFS——对应GPFS文件系统:Ceph文件系统提供了一个使用Ceph存储集群存储用户数据的与POSIX兼容的文件系统。和RBD、RGW一样,CephFS服务也基于librados封装了原生接口。
同样,如果把上述元素和概念按照逻辑进行拼接,可以得到以下这张CEPH的基本架构图,图中反映了各个组件的逻辑关系。
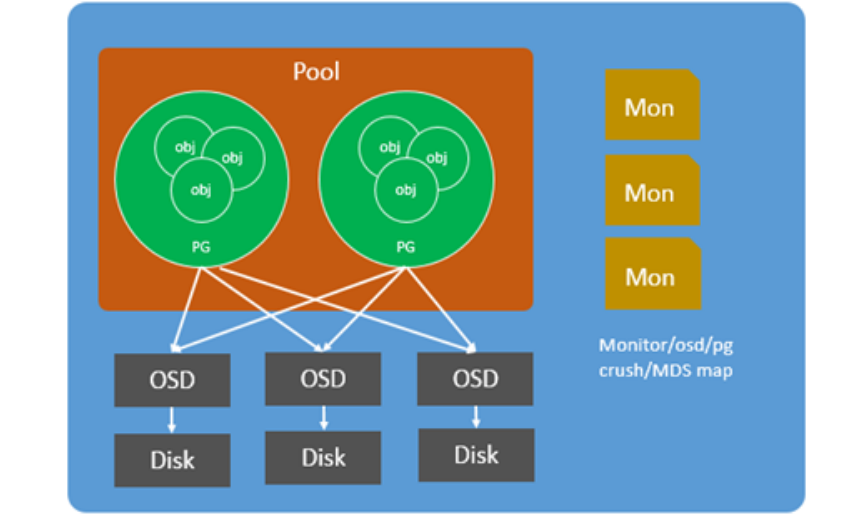
CEPH提供了一个理论上无限扩展的集群,客户端和ceph osd进程通过crush算法来计算数据位置,而不必依赖一个中心查找表,我们知道凡是网络设备都有并发连接数据的限制,集中式/单体式的存储系统,对于大规模部署来说,很容易达到物理极限,在CEPH的数据访问机制中,客户端和osd进程直接通信,提高了性能和系统总容量,消除了单点故障,CEPH客户端仅在需要时与osd进程建立一个会话。
osd进程加入一个集群,并且报告他们的状态,分为up和down两种状态,代表是否可以响应ceph客户端的需求,如果osd进程失败,则无法通知ceph monitor它已经down掉,ceph通过周期性的ping OSD进程,确保它正在运行,CEPH授权OSD进程,确定授信的OSD进程是否已关闭,更新cluster map,并报告给CEPH Monitor。
OSD进程也通过crush算法,计算对象的副本应该存放的位置,在一个写场景中,客户端使用crush算法计算应该在哪里存放对象,并将对象映射到一个pool和placement group,然后查询crush map来定位placement group中的主OSD进程。
客户端将对象写入主osd的placement group中,然后主osd使用它自己的crush map来找到第二、三个OSD,并且将对象副本写入第二、第三OSD的placement group中,主OSD在确认对象存储成功后会给客户端一个回应。OSD进程完成数据的复制,不需要ceph客户端参与,保证了数据的高可用性和数据安全。
CephFS从数据中分离出元数据并保存在MDS中,而文件数据保存在CEPH存储集群的objects中,ceph-mds作为一个进程单独运行,也可以分布在多个物理主机上,达到高可用和扩展性。
CEPH使用方案
了解了架构和原理,该怎么使用呢?Ceph主要用于完全分布式操作,没有单点故障,可扩展到exabyte级别,完全免费使用。其采用的位置感知算法和数据复制机制使其具有容错能力,并且不需要特定的硬件支持,也成为他天生骄傲的资本,大大降低了使用门槛,在贫瘠的物理介质上就可以野蛮生长。一般来说,CEPH主要提供三种使用场景,rbd(block device),对象存储和CephFS文件系统方式,如下图所示:
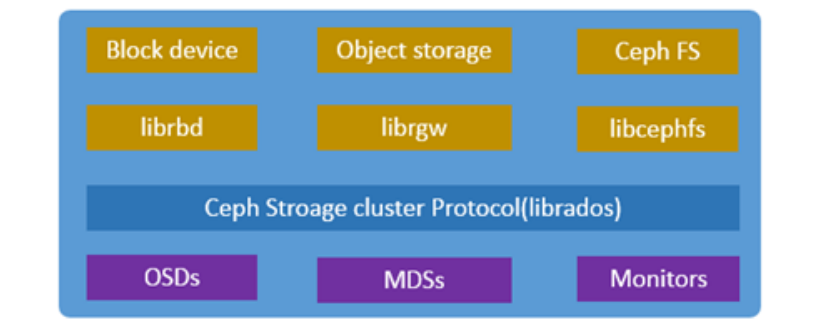
CEPH客户端使用原生协议与CEPH存储集群进行交互,CEPH将这些功能打包成librados库,因此你可以创建自己的CEPH客户端,CEPH作为分布式存储,对外提供各类型的标准存储服务。
CEPH block device的快照功能对于虚拟化和云计算来讲很有吸引力,在虚拟机场景中,极具典型的是在Qemu/KVM使用rbd网络存储驱动部署CEPH block device,宿主机使用librbd向客户机提供块设备服务。而在K8S管理的容器平台中,Ceph也可以提供标准rbd设备的动态供给和共享存储空间。
Scrub是Ceph集群进行的副本间的数据扫描操作,以检测副本间的数据一致性,包括Scrub和Deep-Scrub,其中Scrub只是对元数据信息进行扫描,相对比较快,而Deep-Scrub不仅对元数据进行扫描,还会对存储的数据进行扫描,相对比较慢。Ceph集群会定期进行Scrub操作。
当然,Ceph Scrub机制存在的问题。在发现不一致对象后,缺少策略来自动矫正错误,比如如果多数副本达成一致,那么少数副本对象会被同化。Scrub 机制并不能及时解决存储系统端到端正确的问题,很有可能上层应用早已经读到错误数据,下面一起来看看Scrub的工作流程:
① OSD 会以 PG 为粒度触发 Scrub流程,触发的频率可以通过选项指定,而一个PG的Scrub启动都是由该 PG 的 Master 角色所在OSD启动。
② 一个PG在普通的环境下会包含几千个到数十万个不等的对象,因为Scrub流程需要提取对象的校验信息然后跟其他副本的校验信息对比,这期间被校验对象的数据是不能被修改的。因此一个PG的Scrub流程每次会启动小部分的对象校验,Ceph 会以每个对象名的哈希值的部分作为提取因子,每次启动对象校验会找到符合本次哈希值的对象,然后进行比较。这也是 Ceph称其为Chunky Scrub的原因。
③ 在找到待校验对象集后,发起者需要发出请求来锁定其他副本的这部分对象集。因为每个对象的Master和Replicate节点在实际写入到底层存储引擎的时间会出现一定的差异。这时候,待校验对象集的发起者会附带一个版本发送给其他副本,直到这些副本节点与主节点同步到相同版本。
④ 在确定待校验对象集在不同节点都处于相同版本后,发起者会要求所有节点都开始计算这个对象集的校验信息并反馈给发起者。
⑤ 该校验信息包括每个对象的元信息如大小、扩展属性的所有键和历史版本信息等等,在Ceph 中被称为 ScrubMap。
⑥ 发起者会比较多个ScrubMap并发现不一致的对象,不一致对象会被收集最后发送给 Monitor,最后用户可以通过Monitor了解Scrub的结果信息。
另外,当用户在发现出现不一致的对象时,可以通过“ceph pgrepair [pg_id]”的方式来启动修复进程,目前的修复仅仅会将主节点的对象全量复制到副本节点,因此目前要求用户手工确认主节点的对象是“正确副本”。此外,Ceph允许Deep Scrub模式来全量比较对象信息来期望发现 Ceph 本身或者文件系统问题,这通常会带来较大的IO负担,因此在实际生产环境中很难达到预期效果。
通过上述Scrub流程,大家也会发现目前的 Scrub机制还存在以下2个问题:
① 在发现不一致对象后,缺少策略来自动矫正错误,比如如果多数副本达成一致,那么少数副本对象会被同化。
② Scrub 机制并不能及时解决存储系统端到端正确的问题,很有可能上层应用早已经读到错误数据。
对于第一个问题,目前Ceph已经有Blueprint来加强Scrub的修复能力,用户启动Repair时会启动多数副本一致的策略来替代目前的主副本同步策略。
4、GlusterFS和Ceph对比
GlusterFS和Ceph是两个灵活的存储系统,有着相似的数据分布能力,在云环境中表现非常出色。在尝试了解GlusterFS与Ceph架构之后,我们来看看两者之间的简单对比。
纵向扩展和横向扩展:在云环境中,必须可以很容易地向服务器添加更多存储空间以及扩展可用存储池。Ceph和GlusterFS都可以通过将新存储设备集成到现有存储产品中,满足扩充性能和容量的要求。
高可用性:GlusterFS和Ceph的复制是同时将数据写入不同的存储节点。这样做的结果是,访问时间增加,数据可用性也提高。在Ceph中,默认情况下将数据复制到三个不同的节点,以此确保备份始终可用性。
商品化硬件:GlusterFS和Ceph是在Linux操作系统之上开发的。因此,对硬件唯一的要求是这些产品具有能够运行Linux的硬件。任何商品化硬件都可以运行Linux操作系统,结果是使用这些技术的公司可以大大减少在硬件上的投资——如果他们这样做的话。然而,实际上,许多公司正在投资专门用于运行GlusterFS或Ceph的硬件,因为更快的硬件可以更快地访问存储。
去中心化:在云环境中,永远不应该有中心点故障。对于存储,这意味着不应该用一个中央位置存储元数据。GlusterFS和Ceph实现了元数据访问去中心化的解决方案,从而降低了存储访问的可用性和冗余性。
现在再来谈谈GlusterFS与Ceph的差异。顾名思义,GlusterFS是来自Linux世界的文件系统,并且遵守所有Portable Operating System Interface标准。尽管你可以将GlusterFS轻松集成到面向Linux的环境中,但在Windows环境中集成GlusterFS很难。
Ceph是一种全新的存储方法,对应于Swift对象存储。在对象存储中,应用程序不会写入文件系统,而是使用存储中的直接API访问写入存储。因此,应用程序能够绕过操作系统的功能和限制。如果已经开发了一个应用程序来写入Ceph存储,那么使用哪个操作系统无关紧要。结果表明Ceph存储在Windows环境中像在Linux环境中一样容易集成。
基于API的存储访问并不是应用程序可以访问Ceph的唯一方式。为了最佳的集成,还有一个Ceph块设备,它可以在Linux环境中用作常规块设备,使你可以像访问常规Linux硬盘一样来使用Ceph。Ceph还有CephFS,它是针对Linux环境编写的Ceph文件系统。
为了比较GlusterFS与Ceph哪个更快已经进行了几项测试,但迄今为止没有确切的结论。GlusterFS存储算法更快,并且由于GlusterFS以砖组织存储的方式实现了更多的分层,这在某些场景下(尤其是使用非优化Ceph)可能导致更快的速度。另一方面,Ceph提供了足够的定制功能来使其与GlusterFS一样快。
然而,实践表明Ceph访问存储的不同方法使其成为更流行的技术。更多的公司正在考虑Ceph技术而不是GlusterFS,而且GlusterFS仍然与Red Hat密切相关。例如,SUSE还没有GlusterFS的商业实施,而Ceph已经被开源社区广泛采用,市场上有各种不同的产品。在某种意义上来说,Ceph确实已经胜过GlusterFS。
5.分布式存储未来
未来的IT架构是生态之争,赢生态者得天下,就像开放的安卓赢得了众多开发者的亲赖,繁荣的产品生态也成就了安卓。运维自动化和智能化运维建设,要求底层IT环境实现高度整合,自主可控更是对开放性的要求,开放是一个产品的亲和力,意味着可以更灵活的融入当前IT环境,当前云计算的存储标准接口仍然有开放席位,静待新的有生力量入驻。
不管是存储,还是网络等基础架构,都在试图屏蔽底层物理硬件的差异,实现硬件的标准化管理,用软件定义一切,分布式存储就是在这样的趋势下,赢得了蓬勃发展的契机,开放的产品接口,丰富的插件,与当前环境的兼容耦合性,都将成为分布式存储领域制胜的关键,未来分布式存储在安全性、产品化建设、兼容性、可管理性、稳定性上的不懈努力,将是引领分布式存储占领数据中心存储江山的重要砝码。
审核编辑:刘清
-
驱动器
+关注
关注
54文章
9012浏览量
153336 -
MDS
+关注
关注
0文章
6浏览量
8326 -
分布式存储
+关注
关注
4文章
182浏览量
20106 -
Linux操作系统
+关注
关注
0文章
54浏览量
11715 -
NSD
+关注
关注
0文章
5浏览量
5974
原文标题:分布式存储:GPFS对话Ceph(收藏)
文章出处:【微信号:架构师技术联盟,微信公众号:架构师技术联盟】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
【节能学院】Acrel-1000DP分布式光伏监控系统在奉贤平高食品 4.4MW 分布式光伏中应用

分布式光伏发电监测系统技术方案

一键部署无损网络:EasyRoCE助力分布式存储效能革命

Ceph分布式存储系统解析
华为分布式存储荣膺2025年Gartner“客户之选”
曙光存储领跑中国分布式存储市场
兆芯+图云创智—可信分布式存储系统解决方案





 工商网监
工商网监
评论