 详细介绍注意力机制中的掩码
详细介绍注意力机制中的掩码

注意力机制的掩码允许我们发送不同长度的批次数据一次性的发送到transformer中。在代码中是通过将所有序列填充到相同的长度,然后使用“attention_mask”张量来识别哪些令牌是填充的来做到这一点,本文将详细介绍这个掩码的原理和机制。
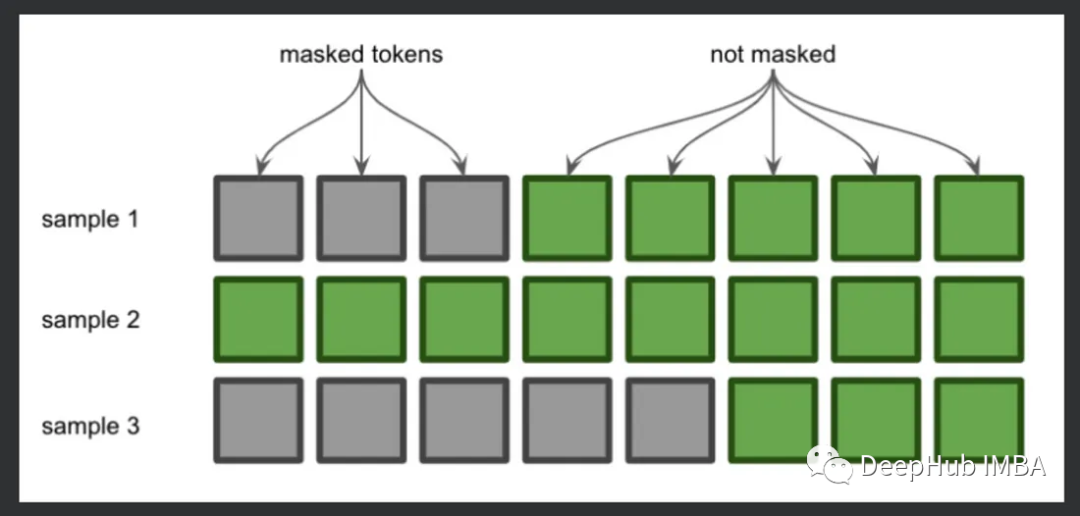
我们先介绍下如果不使用掩码,是如何运行的。这里用GPT-2每次使用一个序列来执行推理,因为每次只有一个序列,所以速度很慢:
from transformers import GPT2LMHeadModel, GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
gpt2 = GPT2LMHeadModel.from_pretrained('gpt2')
context = tokenizer('It will rain in the', return_tensors='pt')
prediction = gpt2.generate(**context, max_length=10)
tokenizer.decode(prediction[0])
# prints 'It will rain in the morning, and the rain'
在显存允许的情况下,使用批处理输入的速度更快,因为我们在一次推理的过程可以同时处理多个序列。对许多样本执行推理要快得多,但也稍微复杂一些,下面是使用transformer库进行推理的代码:
tokenizer.padding_side = "left"
tokenizer.pad_token = tokenizer.eos_token
sentences = ["It will rain in the",
"I want to eat a big bowl of",
"My dog is"]
inputs = tokenizer(sentences, return_tensors="pt", padding=True)
output_sequences = gpt2.generate(**inputs)
for seq in output_sequences:
print(tokenizer.decode(seq))
transformer库帮我们处理了很多细节,我们现在详细的介绍它里面到底做了什么。
我们将令牌输入到语言模型中,如GPT-2和BERT,作为张量进行推理。张量就像一个python列表,但有一些额外的特征和限制。比如说,对于一个2+维的张量,该维中的所有向量必须是相同的长度。例如,
from torch import tensor
tensor([[1,2], [3,4]]) # ok
tensor([[1,2], [3]]) # error!
当我们对输入进行标记时,它将被转换为序列的张量,每个整数对应于模型词表中的一个项。以下是GPT-2中的标记化示例:

如果我们想在输入中包含第二个序列:

因为这两个序列有不同的长度,所以不能把它们组合成一个张量。这时就需要用虚拟标记填充较短的序列,以便每个序列具有相同的长度。因为我们想让模型继续向序列的右侧添加,我们将填充较短序列的左侧。

这就是注意力掩码的一个应用。注意力掩码告诉模型哪些令牌是填充的,在填充令牌的位置放置0,在实际令牌的位置放置1。现在我们理解了这一点,让我们逐行查看代码。
tokenizer.padding_side = "left"
这一行告诉标记器从左边开始填充(默认是右边),因为最右边标记的logits将用于预测未来的标记。
tokenizer.pad_token = tokenizer.eos_token
这一行指定将使用哪个令牌进行填充。选择哪一个并不重要,这里我们选择的是“序列结束”标记。
sentences = ["It will rain in the",
"I want to eat a big bowl of",
"My dog is"]
上面这三个序列在标记时都有不同的长度,我们使用下面的方法填充:
inputs = tokenizer(sentences, return_tensors="pt", padding=True)
在进行表计划和添加填充后,得到了以下的结果:
{'input_ids': tensor([
[50256, 50256, 50256, 1026, 481, 6290, 287, 262],
[ 40, 765, 284, 4483, 257, 1263, 9396, 286],
[50256, 50256, 50256, 50256, 50256, 3666, 3290, 318]
]),
'attention_mask': tensor([
[0, 0, 0, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 1, 1, 1]
])}
可以看到,第一个和第三个序列在开始时进行了填充,并且attention_mask参数标记了这个填充的位置。
现在让我们将这个输入传递给模型来生成新的文本:
output_sequences = gpt2.generate(**inputs)
如果你不熟悉函数调用的**kwargs语法,它是将输入字典作为命名参数传入,使用键作为参数名,并使用值作为相应的实参值。
我们只需要循环遍历每个生成的序列并以人类可读的形式打印出结果,使用decode()函数将令牌id转换为字符串。
for seq in output_sequences:
print(tokenizer.decode(seq))
在注意力掩码中,我们的输入是0和1,但是在最终的计算时,会将在将无效位置的注意力权重设置为一个很小的值,通常为负无穷(-inf),以便在计算注意力分数时将其抑制为接近零的概率。
这时因为,在计算注意力权重时,需要进行Softmax的计算:
Softmax函数的性质:注意力机制通常使用Softmax函数将注意力分数转化为注意力权重,Softmax函数对输入值进行指数运算,然后进行归一化。当输入值非常小或负无穷时,经过指数运算后会接近零。因此,将掩码设置为负无穷可以确保在Softmax函数计算时,对应位置的注意力权重趋近于零。
排除无效位置的影响:通过将无效位置的注意力权重设置为负无穷,可以有效地将这些位置的权重压低。在计算注意力权重时,负无穷的权重会使对应位置的注意力权重接近于零,从而模型会忽略无效位置的影响。这样可以确保模型更好地关注有效的信息,提高模型的准确性和泛化能力。
但是负无穷并不是唯一的选择。有时也可以选择使用一个很大的负数,以达到相似的效果。具体的选择可以根据具体的任务和模型的需求来确定。
-
处理器
+关注
关注
68文章
20339浏览量
255254 -
虚拟机
+关注
关注
1文章
975浏览量
30709 -
python
+关注
关注
58文章
4889浏览量
90324
发布评论请先 登录
注意力机制的诞生、方法及几种常见模型
注意力机制或将是未来机器学习的核心要素
基于注意力机制的深度学习模型AT-DPCNN

基于多层CNN和注意力机制的文本摘要模型





评论