 大语言模型,救不了“网络暴民”
大语言模型,救不了“网络暴民”
语言可以杀人——网络时代,相信没人会否认这一点。
语言攻击,是最具代表性的网络暴力之一。谩骂刚失去儿子的母亲,诋毁女孩的粉色头发,嘲笑男性的气质“太娘”,炮制莫须有的黄色谣言……无数侮辱性的语言,在网络间横行无阻,给他人带来了无穷无尽的精神伤害。
语言暴力,已经成为网络治理的全球性难题。
各种方案被使出,但都无法有效阻止“网络暴民”的增加和语言暴力的横行。其中,技术层面的解决思路,就是利用AI算法来自动检测有毒语言,按照攻击性来设定毒性评分,并对高毒性语言进行预防处理,比如屏蔽、心理干预等。
但由于语言的模糊性,此前的机器学习算法鲁棒性不强,很容易做出错误判断,导致识别和干预的结果并不理想,仍然需要大量人工审核员。不仅处理效率低下,而且长期阅读有毒语言也会伤害人类审核员的心理健康。
ChatGPT这类大语言模型,凭借强大的鲁棒性和泛化能力,展现出了前所未有的语言理解力。
按理说,本着“技术向善”的宗旨,大语言模型应该被用来更有效、高效地预防网络暴力,但为什么迄今为止,我们仍然没有见到相关应用?反倒是利用大语言模型生成更多有害内容的“技术作恶”大行其道。
大语言模型,也救不了“网络暴民”,难道我们注定只能在有毒网络环境下“数字化生存”吗?
大语言模型,内容检测技术的一大步
预防,是治理网络暴力最重要的环节。利用AI内容检测来预防网络暴力,相关研究已经有数年历史了。
2015年就有人提出,个体的情绪状态就与有害意图之间存在显著关联,使用机器学习来检测社交媒体中的有害行为,被认为是网络暴力检测的良好指标。
也就是说,一个人在生活遭遇了剧变、坎坷或感到低落、郁闷等情绪状态不佳时,就容易在网络上发出仇恨、攻击、诋毁等冒犯性语言。
2017年,谷歌的Jigsaw创建了Conversation AI,检测在线有毒评论。许多科技巨头,多年来一直在将算法纳入其内容审核中,都有一套对网络信息内容进行识别和过滤的手段。比如国內某短视频平台,就研发了100多个智能识别模型,来提前拦截辱骂内容,但该平台依然是网暴的“重灾区”。某问答平台,会对评论内容进行识别,对有风险的内容进行提醒,直到用户修改才允许发出。
但显而易见,这些AI检测算法也并没有根除网暴,网友对平台治理网暴的批评仍是“不作为”“没效果”。原因之一,是传统的机器学习算法,不能满足网络内容的审查需求:
1.理解力不够。有害语言非常难以区分,而AI算法的语义理解能力不够强,经常会将有害评论和无害评论给出相同的分数,没有真正过滤掉那些不尊重的评论,或者给中性句子更低的分数,过滤了不该过滤的正常评论,阻碍了博主和粉丝的交流。
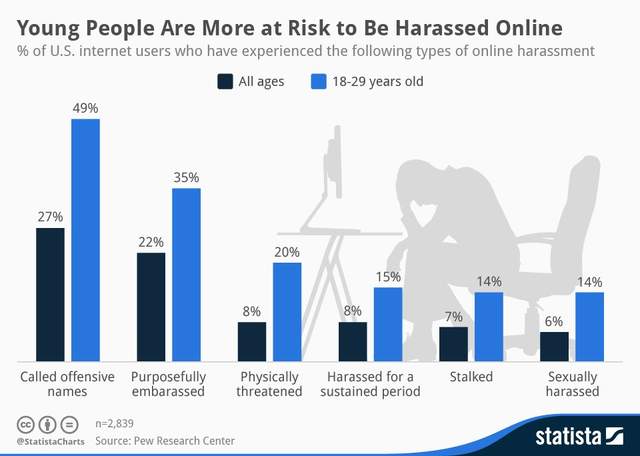
2.灵活性不够。某些网站可能要求检测攻击语言,但不需要检测谣言,而其他网站的要求可能恰好相反。传统的AI检测工具往往使用一个通用的“毒性评分”,不够灵活,无法满足不同平台的不同需求。
3.更新速度不够。很多检测算法是使用API来工作的,而这些模型通过大量网络数据进行训练,在与训练数据相似的示例上表现良好,一旦遇到不熟悉的有毒语言,比如涉及饭圈的讨论会有很多黑话、yyds之类的拼音简写,以及不断新造的词语,很可能就会失败。某社交媒体平台,一开始设置了一百多个禁发关键词,比如一些脏话、“绿茶婊”“怎么不去死”等,如今已经增加到了700多个。所以,AI模型缺乏高效实时的人类反馈,无法快速微调并迭代模型,从而导致自动化检测的效果不佳。
我们知道,大语言模型具备智能涌现、预训练、人类反馈的强化学习等特点,这就对传统方法带来了很大的助力,更强的语言理解能力,使用通用模型可以很快训练出精度更高的定制模型,同时借助人类反馈查漏补缺,获得更好更快的检测效果。
防范网络暴力,已经成为各国互联网治理的重点,平台也能因此建立起更良好的社区氛围,所以大语言模型在检测有害语言方面,应该能大展拳脚才对。
但为什么这一波大语言模型的浪潮中,我们很少见到将LLM用于预防网络暴力的探索呢?
AI,防范语言暴力的一小步
在AI技术体系内部来看,从传统NLP到大语言模型,是一个自然语言理解的飞跃式进步。但走到更大的现实中,AI的一大步,也只是将问题解决向前推进了一点点。
作用不能说没有,但也很有限。应对网络中的语言攻击,AI的力量仍然弱小。
首先,敌人数量太庞大。
康奈尔大学信息科学部门的丹尼斯库表示,很多时候,你我这样的普通人都会成为网络暴力的帮凶。当为数不少的网民自身积怨和不满得不到缓解之时,会对周围事物看不惯,在互联网上用语言攻击他人,来缓解负面情绪。
此前《三联生活周刊》有一篇报道,某位网络暴力受害者已经去世,作者联系到的一些施暴者则回应称“忘记自己当时做过了什么”。
许多网暴者平时看起来是非常正常的,会在某些时刻、某些偶然事件后,短暂地化身“语言恶魔”,然后“事了拂衣去,深藏身与名”,即使是AI,也很难及时准确地判定出,哪些人存在攻击可能。
此外,语言攻击越来越隐蔽。
AI自动检测技术发展到今天,一些明显有害的言论,比如威胁、隐晦、辱骂等,已经可以被直接屏蔽掉了,但人类用语言伤害人的“创造力”是很大的,很多在机器看来中性化的语言,也可能恶意满满。
比如此前校园事故中痛失孩子的母亲,就被大量评论“她怎么看起来不伤心”“她怎么还有心思打扮”,看似并没有什么侮辱性语言,但这些质疑累加在一起,却形成了对受害者的“道德审判”。
对于隐蔽的攻击性语言,目前的NLP模型还有比较大的局限性,语言背后的实际、细微的含义,很难被捕捉到,依然需要人工审核的干预。
而平台监测语言暴力,并没有一个通行的判定体系,往往是各个平台自己酌定。比如知乎会判定邪路隐私、辱骂脏话、扣帽子、贴负面标签等行为。豆瓣则会处理讽刺、抬杠、拱火、歧视偏见等。不过,这些标准都有很大的主观成分,所以大家会看到“挂一漏万”的现象,一些很正常的发言被毙掉,一些明显煽动情绪的发言没有被及时处理。
另外,网络信息的“巴尔干化”。
巴尔干化,指的是一些四分五裂的小国家,互相敌对或没有合作的情况。一项研究显示,互联网虽然消除了地理屏障,让不同地区的人可以低成本地相互交流,但却造成了观念上的“巴尔干化”,舆论上的分离割裂程度越来越严重。
网络信息的推送机制,算法设计还不够科学,偏好设置过于狭窄,采用关键词联想、通讯录关联、图网络等过滤方式,类似“吃了一个馒头=喜欢吃馒头=再来一百个馒头”“你妈爱吃馒头,你也一定爱吃”“馒头=更适合中国宝宝体质的吐司=看看吐司”。人们长期停留在有限的信息范围内,对自己感兴趣的内容之外的信息很少涉猎,和其他群体之间的观念间隙会越来越大。
信息获取机制的“巴尔干化”,会导致舆论“极化”,就是一个观点反复发酵,从而引发大规模的跟风行为,网暴风险也就提高了。
数量多、识别难、极化情绪严重,将互联网变成了一个负面语言的游乐场。
技术之外,做得更多
当然,AI防止网暴道阻且长,但咱们不能就此放弃努力。
大语言模型的出现,带来了更强大的自动检测潜力。媒体机构基于通用模型,可以训练出更高精度、识别能力更强的行业大模型,用人类专业知识来增强模型效果,创建具有人类智能的AI检测模型,从而支持更加复杂的内容理解和审核决策,提高有害内容的检测效率。
升级技术之外,必须做的更多。预防网络暴力,与其说是一个技术问题,不如说是一个社会问题。网络信息环境不改变,攻击语言还会不断变种,增加技术检测的难度与成本,这是用户、平台和社会所不堪承受的。
但此前,很多治理方法效果都不是很理想。
比如说,网络匿名是暴力的“隐身衣”,于是实名制成为一项重要的治理手段,但效果并不理想。韩国是第一个施行网络实名制的国家,于2005年10月提出要实行网络实名制,但按照韩国的统计,实名制之后,网络侵权行为从原来的13.9%降到了12.2%,仅降了1.7%。
立法也是被期待的一种。各国都在不断推出法规,韩国《刑法》对网络暴力最高判处七年有期徒刑,我国刑法、民法中也有相应的规定,治理网络暴力并非无法可依。但立法容易、执法难。
网络环境复杂,网暴攻击的发动者难以确定,网暴一般是由大量跟帖评论等攻击行为累加而成的,证据收集十分困难,容易灭失,“情节严重”难以认定,维权周期长,网暴受害者的维权成本太高,最后大多不了了之,很难对施暴者产生实际的惩罚,助长了“法不责众”的侥幸心理。
要改变“法不责众”的难题,治本的办法,是消除“无意识跟风”的“众”。
网暴不是一个人能完成的,除了少数发布者之外,大量攻击言论,都来自是上头了的跟风者,是网民集体非理性行动的结果。
报纸时代、电视时代的单向传播,只有少数群体有发言、评论的机会,而大众在线下面对面交流时,也不会轻易侮辱攻击别人。到了网络时代,随着智能手机的普及,所有人都可以直接在网络上表达自己的意见,一旦媒体素养跟不上,信息识别能力不够,那么面对真假难辨的网络信息,煽动性的语言,就很容易冲动失控,无意识地加入网暴大军。
很多人在评论时,并不一定经过了理性的思考和判断,只是看自己关注的博主那么说,或者很多人都在讨伐,就跟风批判,使网络暴力升级。
对此,指责“网暴者”的行为偏激,反而又会形成新的“网暴”。“用魔法打败魔法”,会严重扰乱了网络话语生态。很多偶发性的“语言暴力”,是可以通过个人媒体素养的提高去规避的。
这就需要专业媒体机构和有关部门,投入更多媒体资源,面对网络时代,帮助人们习得更高的媒体素养,实现更文明、友好的“数字化生存”。
每个人内心深处都有某种暴力冲动。正如罗翔老师所说,“我们远比自己想象的更伪善和幽暗,每个人心中都藏着一个张三”。
当理性上升,当一个人习得了自我控制的能力,那么“非理性”的暴力一定会减少。比起AI的缰绳,真正能消除网暴的,是每个人心中的道德律令。
-
AI
+关注
关注
87文章
26459浏览量
264083 -
大模型
+关注
关注
2文章
1532浏览量
1130
发布评论请先 登录
相关推荐
盘点一下史上最全大语言模型训练中的网络技术
【书籍评测活动NO.30】大规模语言模型:从理论到实践
大语言模型使用指南
大语言模型简介:基于大语言模型模型全家桶Amazon Bedrock

怎样使用FHE实现加密大语言模型?
腾讯发布混元大语言模型
训练大语言模型带来的硬件挑战

构建神经网络模型的常用方法 神经网络模型的常用算法介绍
神经网络模型用于解决什么样的问题 神经网络模型有哪些
语言模型的发展历程 基于神经网络的语言模型解析






 工商网监
工商网监
评论