 生成式AI带火的不止GPU,网络芯片迎来下一轮大战
生成式AI带火的不止GPU,网络芯片迎来下一轮大战

电子发烧友网报道(文/周凯扬)在生成式AI的热度之下,横向扩展AI训练与推理性能成了每个云服务厂商、数据中心以及互联网厂商追求的目标,这点从前段时间的GPU抢购潮就能看出来,庞大的GPU基数在当下几乎可以和强大的AI算力画上等号。
然而,真正将这些GPU连接起来的,还是靠以太网交换机、路由这类网络芯片。随着数据中心解耦趋势愈发明显,相继认识到这一点的网络芯片厂商都开始新一轮的军备竞赛,诸如博通、美满和思科等厂商都已经加快了新品推出的节奏。
博通Tomahawk
作为在数据中心网络芯片耕耘了12年以上的博通,从640G的Trident系列到25.6T的Tomahawk4系列,已经完成了多次设计迭代,显著提高了网络芯片的带宽。今年三月,博通终于发布了Tomahawk 5系列网络芯片,也是市面上首个量产51.2Tbps交换带宽的芯片。
新的Tomahawk 5系列无疑是在暴涨的AI需求下诞生的,我们从其设计中也能看出。由于做到了更高的端口密度,Tomahawk 5可以实现256高性能AI/ML加速器之间的单跳连接,且每个都能做到200Gbps的网络带宽。这对于数据中心的AI训练和推理的负载来说,无疑提高了吞吐效率,尤其是日益流行且愈发复杂的生成式AI模型。
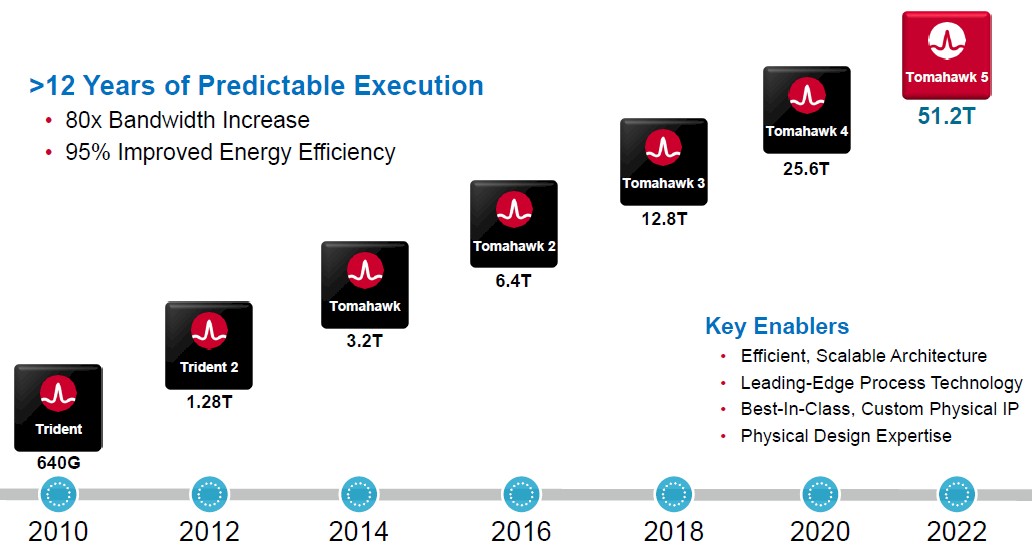
Trident和Tomahawk芯片路线图 / 博通
在物理设计上,Tomahawk 5采用了如今已经趋近成熟的共封装光学(CPO)方案,相较过去的光模块在前端面板插拔的方案,CPO选择将网络交换芯片和光模块封装在一起。这一封装方案结合5nm的芯片工艺,将功耗进一步降低了30%。
另外值得一提的是,博通的第三条网络芯片产品线,Jericho,也在近期迎来了新品Jericho3-AI。相比以高带宽为重心的Tomahawk产品线,和主打更多功能性的Trident产品线,Jericho往往以较低带宽、深度缓存和高可编程性著称。
而Jericho3-AI虽然确实是28.8T的以太网交换机芯片,却针对AI训练负载做了特殊的优化,更高的端口密度使得Jericho3-AI可以在单个集群中连接32000个GPU,并做到800Gbps的连接带宽表现。博通甚至将其与英伟达自己的InfiniBand方案对比,Jericho3-AI在完成时间上有着10%左右的优势。这也是Jericho系列独有的优势,实现标准以太网芯片无法实现却在AI或HPC应用上被看重的灵活功能。
思科Silicon One
其实早在2019年思科首次推出Silicon One网络芯片时,博通CEO霍克·谭就表示:“思科在该市场的参与,恰巧验证了我们推进的这一行业趋势,也就是数据中心的解耦。我们很高兴自己再次押对了,也欢迎更多的竞争。”要知道,之前的思科可是博通的优质客户之一,如今身份的转变已经对网络芯片的市场格局产生了不小的影响。

Silicon One芯片路线图 / 思科
在第一代自研芯片Silicon One发布三年半之后,思科在近日终于推出了该产品线的第四代产品,以太网交换机芯片G200和G202。其中G200专注于统一架构和基于以太网的AI/ML应用部署,这个采用 5nm工艺打造的芯片,基于512个112Gbps SerDes打造,同样可以做到51.2Tbps的交换带宽。
而G202则是针对想要继续使用50G SerDes的客户打造的,同样基于5nm的工艺,G202采用了512x56Gbps SerDes的配置,其特性与G200完全一致,只不过交换性能只有G200的一半。
根据思科的说法,由于单设备512个100GE以太网端口的超高端口密度,客户可以在一个双层网络上构建由32000个400G GPU组成的AI/ML集群。借助G200打造这样一个庞大的网络,却依然可以省去50%的光学组件、40%左右的交换机,极大减少这类集群的碳足迹,每年最高可以省下900万kWh的耗能。据了解,G200已经送样给六大云服务商中的五家进行测试了。
美满Teralynx
在收购由几位前博通高管打造的芯片初创公司Innovium后,美满也开始了他们的网络芯片逆袭。同样是在今年3月,美满也推出了自己的51.2Tbps交换机芯片,Teralynx 10。相比其他两家,美满为Teralynx 10选择的定位是超低延迟的可编程交换机芯片,这也是此前Innovium的设计目标。
不过直至目前为止,美满并没有将Teralynx并入自己的Prestera产品线内,看来Prestera应该还是主打企业与边缘数据中心市场,而面向云端数据中心的Teralynx系列继续沿用原来的产品线名称。
除了用到业界顶级的112G SerDes IP和先进的工艺实现低功耗的系统设计以外,美满电子宣称Teralynx 10可以提供1.7倍的延迟优势,这对于生成式AI这种看重完成时间和网络传输时间的应用来说至关重要。
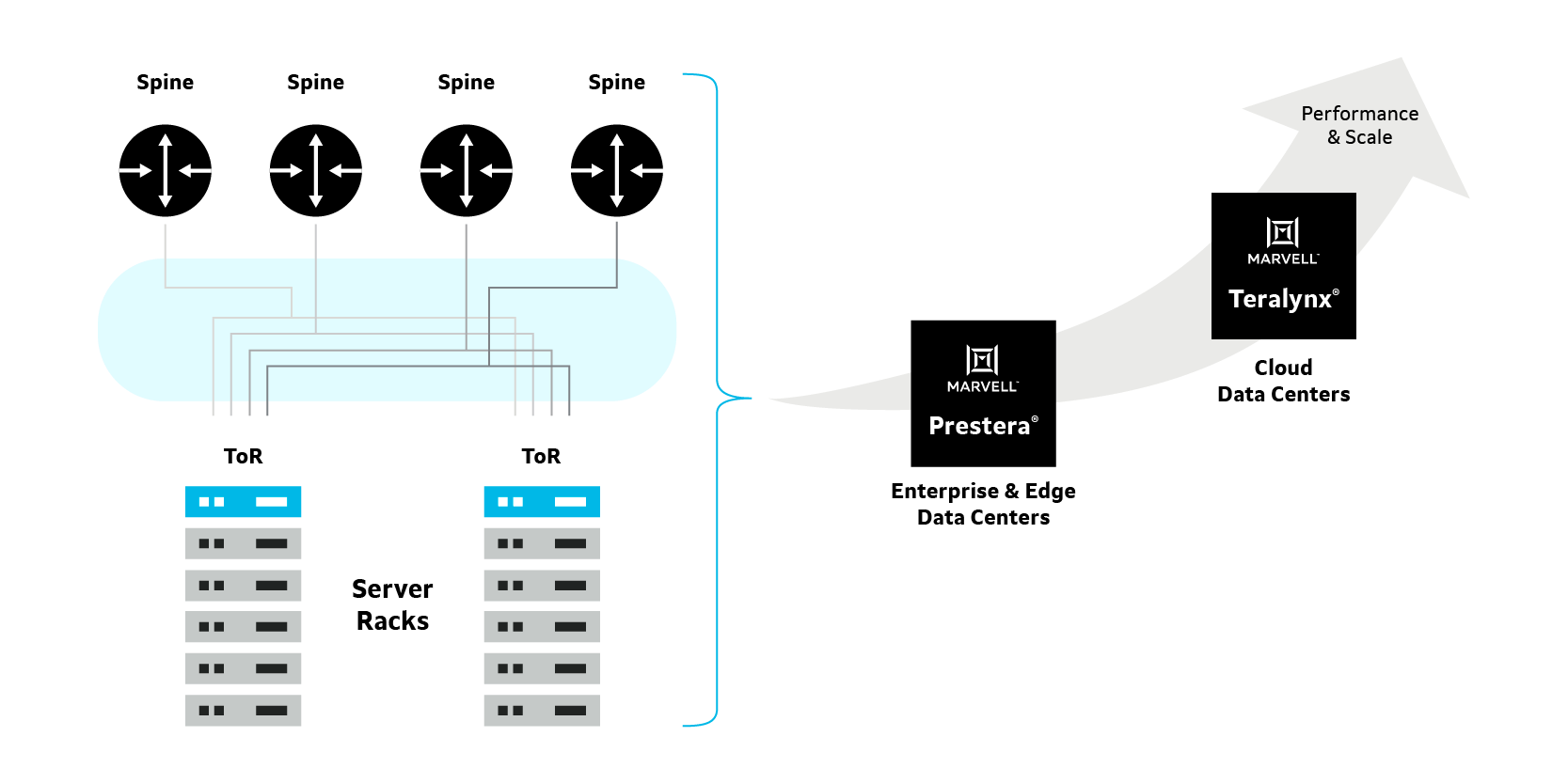
企业与数据中心的交换芯片方案 / 美满
还有一点与其他两家不同的是,Teralynx 10可以驱动128个400Gbps端口、64个800Gbps端口和32个1.6Tbps端口,1.6Tbps的端口驱动能力可以说是放眼未来了,这也意味着Teralynx 10可以直接在1RU大小的机柜中实现51.2Tbps的性能。
为此,美满也推出了Nova这一业界首个做到1.6Tbps的PAM4电光平台,Nova基于美满的200Gbps/lambda光DSP打造,足以为1.6Tbps的可插拔光模块提供支持。由于DSP的带宽翻倍,基于Nova的光模块不仅减少了所需激光和相关光学组件的数量,相较其他的方案来说稳定性也同样加倍。虽然800Gbps的光模块仍在普及中,但要想在下一代数据中心交换网络中抢占先机,1.6Tbps的光模块也该尽快提上日程了。
写在最后
之所以这些厂商都能这么快推出下一代高性能网络芯片,其实还是靠EDA/IP和封装技术打好了第一波基础,厂商们先一步推出了完善的以太网IP和共封装光学方案。不过这也意味着过去数据中心交换硬件很可能迎来新一波的换代,从目前来看应该是只有大型云服务厂商有这个资本进行大规模替换。
但除了这些网络芯片公司之间的斗争之外,他们也需要提防英伟达这样既有GPU业务又有网络芯片业务的厂商。以上提到的这三家在推出的新品上都有剑指英伟达InfiniBand的意思,毕竟后者从一开始就是为了HPC和AI打造的通信标准,而它们则是刚从Web Scaling转向AI Scaling,从外部网络交换转为内部网络交换,仍需要不断提升产品性能才能在这个竞争激烈的市场上存活下去。
不过这也可以看出AI带来的热度,因为无论是从软件还是从硬件上,产品的迭代速度都有了成倍提升。800GbE时代的到来,也导致所有想在服务器市场创造增长的厂商纷纷趋之若鹜,好在这样的趋势恰恰是服务器市场急需的一剂强心剂。
-
gpu
+关注
关注
28文章
5335浏览量
136240 -
AI
+关注
关注
91文章
42161浏览量
303149 -
生成式AI
+关注
关注
0文章
538浏览量
1149
发布评论请先 登录
AD7124多通道连续读取一轮数据之后,与下一轮存在80ms时间差,为什么?
AI Ceph 分布式存储教程资料大模型学习资料2026
自研算/存/电/连,AI算力芯片黑马宣布完成新一轮融资

嵌入式AI开发必看:杜绝幻觉,才是工业级IDE的核心底气
深兰科技国际业务迎来新一轮布局推进
星融元完成新一轮融资,携手产业资本加速AI网络市场布局






评论