 HadaFS可扩展性和性能的优势
HadaFS可扩展性和性能的优势

本篇文章发表于顶级会议 FAST 2023,由无锡国家超级计算中心、清华大学、山东大学、中国工程院的学者为我们分享了他们在尖端超级计算机和高性能计算领域的最新的成果,提出了一种名为 HadaFS 的新型 Burst Buffer 文件系统,实现了可扩展性和性能的优势与数据共享和部署成本的优势的良好结合。
相关文章: 收藏:多家Burst Buffer存储技术解析(附下载) Burst Buffer技术为何在HPC如此盛行
一、背景
高性能计算(HPC)正在经历计算规模和数据爆发式增长的时代。为了满足 HPC 应用不断增长的 I/O 需求或突发流量 I/O 性能需求,研究人员提出 Burst Buffer(BB)技术,通过 SSD 等新型存储介质构建数据加速层,作为前端计算和后端存储之间的缓冲区,为 HPC 应用提供高速 I/O 服务,提高了系统的性能。
取决于 SSD 阵列的部署位置 ,BB可以分为两种类型:
1)本地BB,即SSD作为本地磁盘部署在每个计算节点上,专门为单个计算节点服务;
2)共享BB,即SSD部署在计算节点可以访问的专用节点上 (例如 I/O 转发节点),以支持共享数据访问。
本地 BB 具有良好的可扩展性和性能优势,系统性能可以随着计算节点的数量线性增长。但本地 BB 数据共享不友好,要么以静态数据迁移方式运行,要么需要应用程序通过计算节点迁移数据,迁移效率低下,造成计算资源浪费。本地 BB 还会造成严重的资源浪费,因为 HPC 应用程序之间 I/O 负载的差异巨大,数据密集型应用程序相对较少。未来随着超级计算机规模的迅速扩大,本地BB的部署成本将急剧上升。
共享 BB 天然具有数据共享和部署成本的优势,但难以为数十万规模的客户端提供高效的数据访问处理性能。如何统一本地BB和共享BB的优势,满足多样化的应用需求,降低BB的建设成本,支持大规模的BB数据管理和迁移,是亟待解决的问题。BB 虽然具有高性能的优势,但具有容量小的缺点,所以 BB 必须与 GFS(如 Lustre 等全局文件系统)协同工作才能满足容量要求。
SNS基于神威新一代异构高性能众核处理器和互联网络芯片构建,采用与神威太湖之光相似的架构。超级计算机由计算系统、互联网络系统、软件系统、存储系统、维护诊断系统、供电系统和冷却系统组成。下图显示了总体架构。
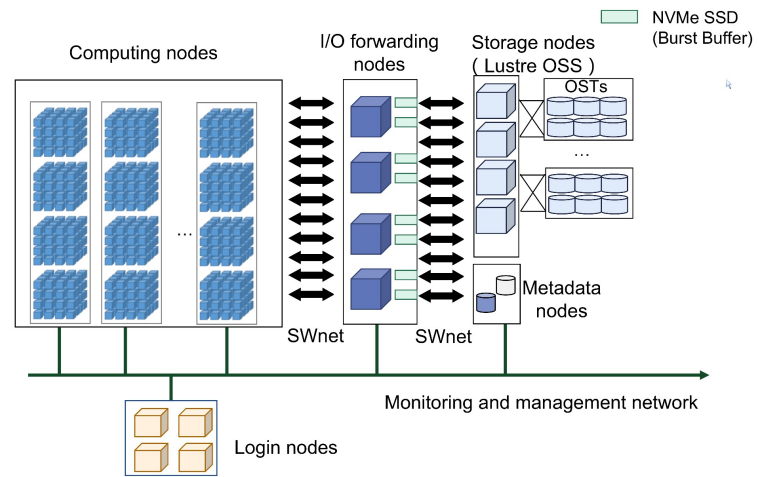
图1SNS的架构
二、动机问题
BB 技术已被广泛引入尖端超级计算机,但现有的主流 BB 技术仍然存在许多局限性。
问题1:
随着百亿亿级计算的壁垒被打破,超级计算机的 I/O 并发量可达数十万,同时 AI、工作流等数据共享应用占比提升导致 I/O 需求发生变化,大规模数据的高速共享存储对 BB 架构的可扩展性提出了挑战。
现有超级计算机计算机采用的方案各有优缺点,例如,Frontier 使用独立硬件分别构建本地 BB 和共享 BB,但这种方法需要很多加速设备(SSD),建设和维护成本高。
问题2:
传统的文件系统的文件管理在目录树结构中实现并且严格遵循 POSIX 协议,但在 HPC 中,计算节点通常负责读写数据,很少执行目录树访问,通过放宽 POSIX 协议也可以提高性能。不同应用程序对文件系统一致性的需求不同,一致性程度越高 ,它的适应性就越强,但代价是开销越大。灵活地选择一致性语义来平衡应用程序的需求并利用 BB 性能是一个很大的挑战。
问题3:
大多数应用程序都可以使用 BB 来加快 I/O 性能,但 BB 的利用率较低,需要为用户开发灵活的数据管理工具。BB 作为高速缓冲区,并不是应用程序持久化存储数据的地方,因此 BB 系统需要考虑高效便捷地在 BB 和 GFS 之间迁移数据。目前还不支持用户在应用运行过程中动态管理 BB 的数据迁移,非常不利于 BB 的高效利用。
从成本控制的角度出发,共享 BB 部署更适合未来的超大规模计算节点系统,因为共享 BB 可以部署在计算或数据转发节点上。为了解决上述问题,本文研究如何从共享 BB 模型开始,获得本地 BB 模型的优势,以更好地满足百亿亿级及以上 HPC 应用程序的需求。
三、HadaFS的设计与实现
HadaFS概述
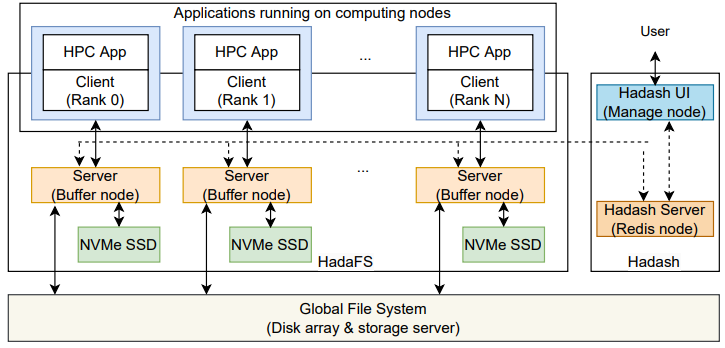
图2 HadaFS的架构
HadaFS 相当于是堆叠在磁盘阵列或存储服务器的全局文件系统上的一个分布式文件系统,HadaFS 的整体架构如上图所示,包括HadaFS 客户端、HadaFS 服务器、数据管理工具 Hadash。
•Hadash 运行在用户登录节点上,用于管理全局文件系统与 HadaFS 之间的数据迁移。
•HadaFS 客户端运行在计算节点上,作为一个静态/动态库,拦截应用程序的 POSIX I/O 请求并将其重定向到 HadaFS 服务器。
•HadaFS 服务器运行在部署 NVMe SSD 的专用突发缓冲节点上,提供全局数据和元数据分离的存储服务。
HadaFS 作为共享突发缓冲文件系统,可以为每个客户端提供全局视图。HadaFS 中的每个文件都与两种类型的服务器相关联。一种是数据存储服务器,通过 NVMe SSD 上的基础文件系统存储 HadaFS 文件的数据,另一种是元数据存储服务器,通过高性能数据库(RocksDB)存储 HadaFS 文件的元数据。
Localized Triage Architecture(LTA,本地化分流架构)
HadaFS 遵循绕过内核的思路,直接将客户端挂载到应用程序中使用,避免引入内核的I/O请求stage-in和stage-out开销。为了更好地给应用程序提高全局文件视图,HadaFS 提出了名为 LTA 的新方法,每个 HadaFS 客户端只连接一台HadaFS 服务器(桥接服务器),桥接服务器负责处理客户端产生的所有I/O请求,并将数据写入底层文件。当客户端需要访问另一台服务器上的数据时,必须通过桥接服务器进行转发。因此,服务器是一个全连接结构。
LTA 为每个计算节点匹配了一个桥接服务器以提供相当于本地 BB 的服务,并通过所有桥接服务器之间的全互联支持所有客户端的共享,结合了本地 BB 和共享 BB 的优点。
LTA 还提供了新的挂载接口,应用程序可以指定客户端到服务器的映射,这有助于减少数据转发。HadaFS 挂载后,应用程序可以通过与 POSIX 文件操作完全一样的接口进行 I/O 操作。
文件命名空间和元数据处理
在 HPC 中计算节点通常负责读写数据,很少执行目录树访问。为了提高可扩展性和性能,HadaFS 放弃了目录树的思想,采用了全路径索引方法。数据存储在生成该文件的 HadaFS 客户端对应的桥接服务器上,文件元数据以 key-value 方式存储,文件路径的哈希值是一个全局唯一ID(key)。
每个 HadaFS 服务器上都维护着两种元数据数据库,它们的数据结构如下图所示。
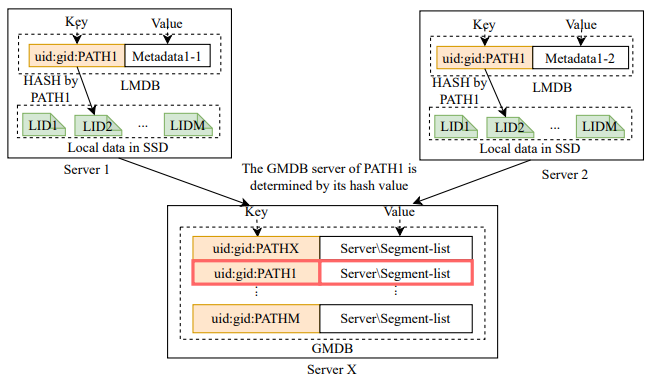
图3 HadaFS服务器上的两张K-V表
本地元数据数据库(LMDB)存储了文件在本地读写过程中会变化的一些元信息,全局元数据数据库(GMDB)存储文件在所有服务器读写访问过程中会变化的一些元信息。GMDB 负责维护文件数据段位置的全局列表,以支持 HadaFS 服务器之间数据的全局共享。注意:每个服务器都会维护本地文件的 GMDB。
元数据数据库的 key 由用户的 UID、GID 和 PATH 组成,GID 和 UID 用于控制字符串检索的范围,因为 HadaFS 使用字符串前缀匹配来检索文件。
数据管理工具 Hadash
Hadash 支持用户在目录树视图中检索和管理文件,按功能分为两类:元数据信息查询和数据迁移。
元数据信息查询主要提供 ls、du、find、grep 等命令,Hadash 从元数据库中获取这些查询类型操作的信息。其中 ls、find 支持目录树视图的文件信息查询,Hadash 采用前缀匹配的方式来呈现一个虚拟的目录树,前缀匹配的方式可以通过 LMDB 在本地执行。其他涉及数据迁移的命令,Hadash 通过特定的 Redis 管道将命令发送到 HadaFS 服务器上的数据管理模块执行。下图显示了从 HadaFS 到 GFS 的数据迁移流程示例。
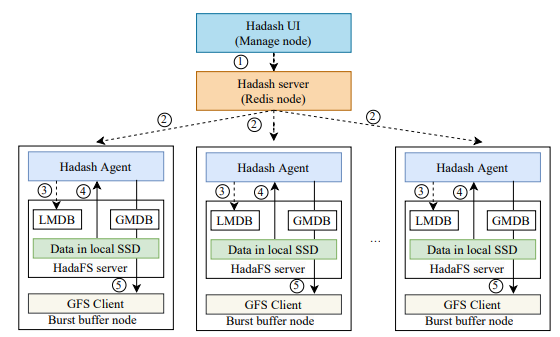
图4 Hadash的退出流程
HadaFS 其他的一些优化设计
HadaFS 采用了宽松的一致性语义,依赖于基本文件系统(ext4)的缓存机制来提高性能,其一致性语义主要依赖于元数据同步,不支持在客户端和服务端缓存数据。为此,HadaFS针对不同的应用场景提出了三种元数据同步策略。
•mode1: 是异步更新所有元数据(对应最终一致性语义)。文件的所有操作都先在桥接服务器本地执行,之后元数据会从 LMDB 异步更新到 GMDB,适用于无数据依赖的场景。
•mode2: 是同步更新部分元数据,异步更新部分元数据(对应会话一致性语义和提交一致性语义)。文件创建时同步更新元数据,文件读写时异步更新元数据,或者通过 flush 操作同步更新。
•mode3: 是在文件访问过程中同步所有打开、读取和写入操作的元数据(比强一致性语义略弱)。
HadaFS 没有使用分布式锁机制,因此HadaFS 本身很难保证数据的一致性,只有在第三种元数据同步策略下才支持原子写。为了保证数据的一致性,用户至少要了解应用程序的文件共享模式,可以通过 Darshan、Beacon 等获得,自行保证数据一致性。
众所周知,超级计算机上同时运行着很多作业。这些作业往往会争夺共享资源,从而导致 I/O 干扰。将客户端动态映射到服务器也有助于提高应用程序性能。得益于HadaFS灵活的设计,用户可以动态制定 HadaFS 客户端到 HadaFS 服务器的连接关系,可以有效帮助隔离不同应用的BB资源,解决作业间的 I/O 干扰,缺点是对运维人员的要求略高。
四、性能评估
本文在神威新一代超级计算机(SNS)上进行评估,以测试 HadaFS 的性能。下图显示了 HadaFS 的部署。SNS 包含超过 10 万个计算节点,每个节点最多可以启动 6 个 MPI 进程和 6 个 HadaFS 客户端。也就是说整机可以支持超过 60 万个 MPI 进程和 60 万个 HadaFS 客户端。共有 600 个 I/O 转发节点,每个 I/O 转发节点配置两块 3.2TB 的 NVMe SSD(每块NVMe SSD对应一台 HadaFS 服务器,支持 HadaFS 文件的数据和元数据的存储)。所有节点使用 SWnet 网络互连,HadaFS 使用基于 SWne t的 RDMA 协议传输数据。
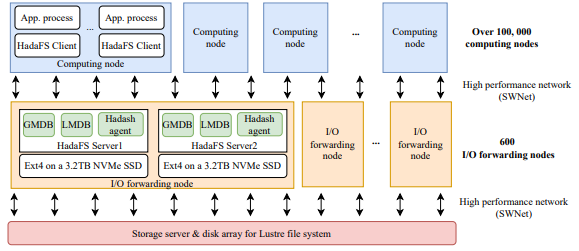
图5 HadaFS的部署
评估的对比对象为:BeeGFS(许多超级计算机用来管理 BB 的并行文件系统)和 GFS(SNS 中基于LWFS 和 Lustre 的传统并行文件系统)。
元数据访问性能评估
首先使用 MDTest(元数据性能评估基准)来比较 HadaFS、GFS 和 BeeGFS 在 1024、4096、16384 和 65536 个进程的并行规模下的元数据性能差异。下图(a)、(b) 和 (c) 分别显示了 Create、Stat 和 Remove 的 OPS 比较。Mode1 具有最高的性能,Mode2 的性能与 Mode3 相当,因为在 MDTest 设置中没有读/写操作。但 BeeGFS 无法扩展到 65536 个进程,需要挂载 16384 个客户端节点,但超过 10000 个节点后批量挂载不容易成功。由于 LWFS 数据转发造成的性能开销和 Lustre 的元数据服务器有限,传统文件系统 GFS 的性能最差。
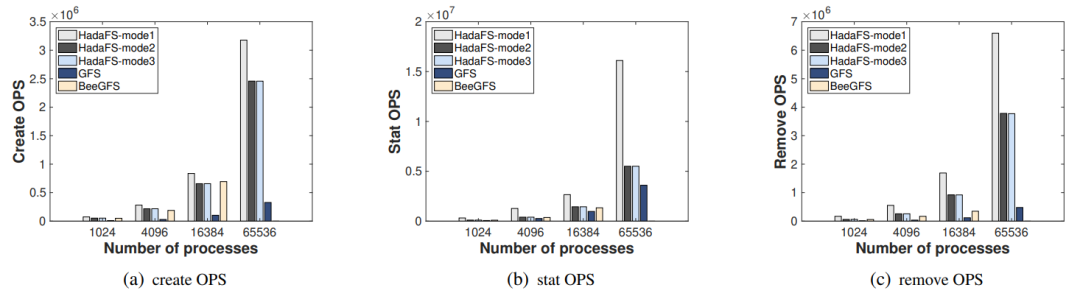
图6元数据性能比较
数据访问性能评估
接下来使用 IOR(数据性能评估基准)来比较并行规模为 1024、4096、16384 和 65536 进程的 HadaFS、GFS 和 BeeGFS 之间的 I/O 带宽差异。HadaFS 和 BeeGFS 分别使用 4、16、64、256 个 I/O 转发节点。下图显示了结果。对于 HadaFS,Mode1 性能最高,其次是 Mode2,最后是 Mode3。当规模达到 65536 个进程时,HadaFS 的性能比其他文件系统要好得多。对于读取操作,HadaFS 的表现十分接近 SSD 的理论性能极限。对于写操作,由于无法利用内核缓存机制,随机写不利于 HadaFS 的性能。BeeGFS 的性能表现略差于 HadaFS,但仍然无法扩展到 65536 个进程。由于转发开销和存储介质问题(数据存储由 HDD 构建),GFS 的性能依旧最低。
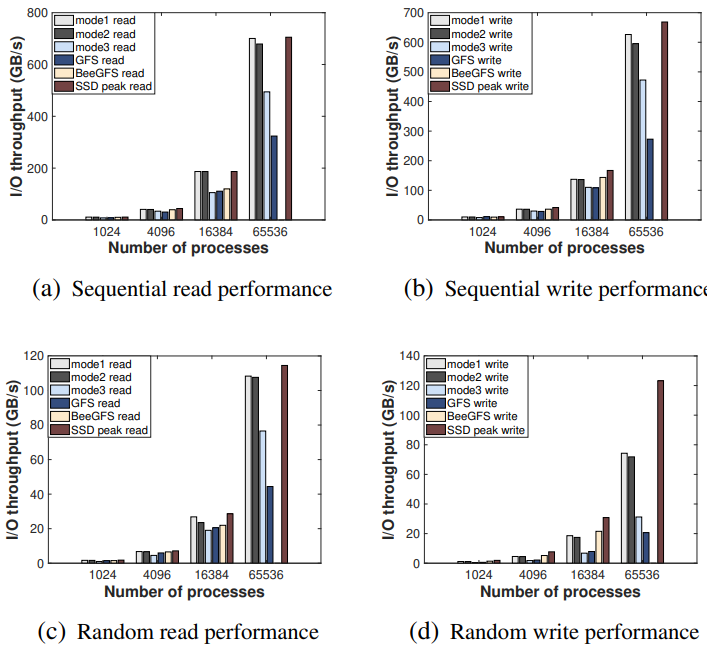
图7 IO吞吐量比较
数据迁移性能评估
接下来评估 Hadash 的 I/O 吞吐量和迁移超小文件的能力,对比对象是 Datawarp。HadaFS 配置了 256 台数据服务器和 256 台元数据服务器,Datawrap 配置了 4096 个数据迁移进程。
首先,使用 4096 个文件进行数据stage-in 和 stage-out实验,文件的总数据量在 256 MB 到 64 TB 之间。实验结果如下图所示,当需要迁移的文件总量较小时(stage-in 小于 64GB,stag-out 小于 16GB),Hadash 的性能略差于 Datawarp,因为单个文件较小会导致基于 Redis 管道的命令分发和结果获取机制占用了较大比例的时间。随着总体积和单个文件大小的变大,Hadash 的 I/O 吞吐量稳定在 100 GB/s(stage-in)和 140 GB/s(stage-out)左右,远高于 Datawarp。
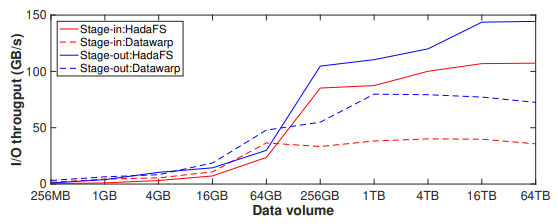
图8 数据迁移吞吐量比较
下图显示了使用不同数量的 4 KB 小文件进行数据 stage-in 和 stage-out 的实验结果。对于 stage-in,当小文件的数量超过 10000 时,Hadash 的性能明显优于 Datawarp,而 Datawarp 的性能变化较小。对于 stage-out,当小文件数量超过 100000 时,Hadash 明显优于 Datawarp。
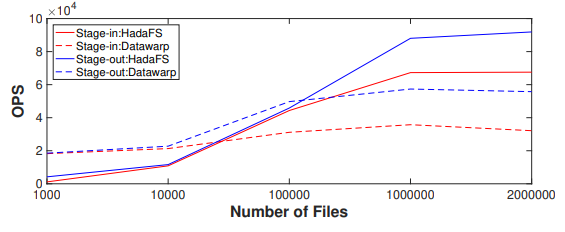
图9每秒迁移的文件数比较
可以看到 stage-out 性能明显优于 stage-in 性能。首先 GFS 的写性能和 BB 的读性能决定了 stage-out 的性能,而 GFS 的读性能和 BB 的写性能决定了 stage-in 的性能。因为 GFS(Lustre)客户端有写缓存,所以 GFS 的写性能高于读性能,BB 的读性能也高于写性能,这就导致了 stage-out 的性能更高。并且在 stage-in 流程中,Hadash 需要从GFS中读取单个目录下的所有文件,随着单个目录下文件数量的增加,这个过程需要的时间会更长。
综合来看,HadaFS 已经可以稳定服务于数百个应用程序,支持最大 600000 个客户端扩展,I/O 聚合带宽达到 3.1 TB/s。
五、总结
本文提出了一种名为 HadaFS 的新型 Burst Buffer 文件系统,基于共享 BB 架构为计算节点提供了本地 BB 式的访问,结合了本地 BB 的可扩展性和性能的优势与共享 BB 的数据共享和部署成本的优势。
HadaFS 提出的 LTA 架构通过桥接服务器处理计算节点的 I/O 请求,实现了与节点本地 BB 相当的可扩展性,并提供新的接口以减少单个服务器上大量连接带来的干扰。HadaFS 提出了三种元数据同步策略,以解决传统文件系统复杂的元数据管理与 HPC 应用程序的各种一致性语义需求之间的不匹配问题。此外,HadaFS内部集成了名为Hadash的数据管理工具,可以为用户提供全局的数据视图和高效的数据迁移。最后,HadaFS 已经部署在 SNS 上(超过 100000 个计算节点)并支持数百个应用程序,可以为多种超大规模应用提供稳定、高性能的I/O服务。
责任编辑:彭菁
-
服务器
+关注
关注
13文章
10092浏览量
90854 -
数据共享
+关注
关注
0文章
58浏览量
11120
原文标题:HadaFS:新型Burst Buffer文件系统
文章出处:【微信号:架构师技术联盟,微信公众号:架构师技术联盟】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
可扩展性的优点:从彼得·帕克(Peter Parker)到引脚复用
请问这两种机械手模型哪种实验性能更好,可扩展性更好
BeagleBoard,基于低成本OMAP3530 SoC OMAP处理器,可释放笔记本电脑般的性能和可扩展性
基于软件定义网络控制可扩展性研究
如何解决区块链的可扩展性问题
千兆位串行链路实现无限可扩展性应用
如何提高比特币的可扩展性
COM-HPC:无限的高速可扩展性
什么是可扩展性,为什么它很重要





 工商网监
工商网监
评论