 PyTorch教程-10.7. 用于机器翻译的编码器-解码器 Seq2Seq
PyTorch教程-10.7. 用于机器翻译的编码器-解码器 Seq2Seq

在所谓的 seq2seq 问题中,如机器翻译(如 第 10.5 节所述),其中输入和输出均由可变长度的未对齐序列组成,我们通常依赖编码器-解码器架构(第10.6 节)。在本节中,我们将演示编码器-解码器架构在机器翻译任务中的应用,其中编码器和解码器均作为 RNN 实现( Cho等人,2014 年,Sutskever等人,2014 年)。
在这里,编码器 RNN 将可变长度序列作为输入并将其转换为固定形状的隐藏状态。稍后,在 第 11 节中,我们将介绍注意力机制,它允许我们访问编码输入,而无需将整个输入压缩为单个固定长度的表示形式。
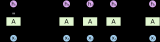
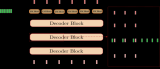
然后,为了生成输出序列,一次一个标记,由一个单独的 RNN 组成的解码器模型将在给定输入序列和输出中的前一个标记的情况下预测每个连续的目标标记。在训练期间,解码器通常会以官方“ground-truth”标签中的前面标记为条件。然而,在测试时,我们希望根据已经预测的标记来调节解码器的每个输出。请注意,如果我们忽略编码器,则 seq2seq 架构中的解码器的行为就像普通语言模型一样。图 10.7.1说明了如何在机器翻译中使用两个 RNN 进行序列到序列学习。

图 10.7.1使用 RNN 编码器和 RNN 解码器进行序列到序列学习。
在图 10.7.1中,特殊的“”标记标志着序列的结束。一旦生成此令牌,我们的模型就可以停止进行预测。在 RNN 解码器的初始时间步,有两个特殊的设计决策需要注意:首先,我们以特殊的序列开始“”标记开始每个输入。其次,我们可以在每个解码时间步将编码器的最终隐藏状态输入解码器(Cho等人,2014 年)。在其他一些设计中,例如Sutskever等人。( 2014 ),RNN 编码器的最终隐藏状态仅在第一个解码步骤用于启动解码器的隐藏状态。
import collections import math import torch from torch import nn from torch.nn import functional as F from d2l import torch as d2l
import collections import math from mxnet import autograd, gluon, init, np, npx from mxnet.gluon import nn, rnn from d2l import mxnet as d2l npx.set_np()
import collections import math from functools import partial import jax import optax from flax import linen as nn from jax import numpy as jnp from d2l import jax as d2l
import collections import math import tensorflow as tf from d2l import tensorflow as d2l
10.7.1。教师强迫
虽然在输入序列上运行编码器相对简单,但如何处理解码器的输入和输出则需要更加小心。最常见的方法有时称为 教师强制。在这里,原始目标序列(标记标签)作为输入被送入解码器。更具体地说,特殊的序列开始标记和原始目标序列(不包括最终标记)被连接起来作为解码器的输入,而解码器输出(用于训练的标签)是原始目标序列,移动了一个标记: “”,“Ils”,“regardent”,“。” →“Ils”、“regardent”、“.”、“”(图 10.7.1)。
我们在10.5.3 节中的实施为教师强制准备了训练数据,其中用于自监督学习的转移标记类似于9.3 节中的语言模型训练。另一种方法是将来自前一个时间步的预测标记作为当前输入提供给解码器。
下面,我们 将更详细地解释图 10.7.1中描绘的设计。我们将在第 10.5 节中介绍的英语-法语数据集上训练该模型进行机器翻译 。
10.7.2。编码器
回想一下,编码器将可变长度的输入序列转换为固定形状的上下文变量 c(见图 10.7.1)。
考虑一个单序列示例(批量大小 1)。假设输入序列是x1,…,xT, 这样xt是个 tth令牌。在时间步t, RNN 变换输入特征向量xt为了xt 和隐藏状态ht−1从上一次进入当前隐藏状态ht. 我们可以使用一个函数f表达RNN循环层的变换:
(10.7.1)ht=f(xt,ht−1).
通常,编码器通过自定义函数将所有时间步的隐藏状态转换为上下文变量q:
(10.7.2)c=q(h1,…,hT).
例如,在图 10.7.1中,上下文变量只是隐藏状态hT对应于编码器 RNN 在处理输入序列的最终标记后的表示。
在这个例子中,我们使用单向 RNN 来设计编码器,其中隐藏状态仅取决于隐藏状态时间步和之前的输入子序列。我们还可以使用双向 RNN 构建编码器。在这种情况下,隐藏状态取决于时间步长前后的子序列(包括当前时间步长的输入),它编码了整个序列的信息。
现在让我们来实现 RNN 编码器。请注意,我们使用嵌入层来获取输入序列中每个标记的特征向量。嵌入层的权重是一个矩阵,其中行数对应于输入词汇表的大小 ( vocab_size),列数对应于特征向量的维度 ( embed_size)。对于任何输入令牌索引i,嵌入层获取ith权矩阵的行(从 0 开始)返回其特征向量。在这里,我们使用多层 GRU 实现编码器。
def init_seq2seq(module): #@save """Initialize weights for Seq2Seq.""" if type(module) == nn.Linear: nn.init.xavier_uniform_(module.weight) if type(module) == nn.GRU: for param in module._flat_weights_names: if "weight" in param: nn.init.xavier_uniform_(module._parameters[param]) class Seq2SeqEncoder(d2l.Encoder): #@save """The RNN encoder for sequence to sequence learning.""" def __init__(self, vocab_size, embed_size, num_hiddens, num_layers, dropout=0): super().__init__() self.embedding = nn.Embedding(vocab_size, embed_size) self.rnn = d2l.GRU(embed_size, num_hiddens, num_layers, dropout) self.apply(init_seq2seq) def forward(self, X, *args): # X shape: (batch_size, num_steps) embs = self.embedding(X.t().type(torch.int64)) # embs shape: (num_steps, batch_size, embed_size) outputs, state = self.rnn(embs) # outputs shape: (num_steps, batch_size, num_hiddens) # state shape: (num_layers, batch_size, num_hiddens) return outputs, state
class Seq2SeqEncoder(d2l.Encoder): #@save
"""The RNN encoder for sequence to sequence learning."""
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = d2l.GRU(num_hiddens, num_layers, dropout)
self.initialize(init.Xavier())
def forward(self, X, *args):
# X shape: (batch_size, num_steps)
embs = self.embedding(d2l.transpose(X))
# embs shape: (num_steps, batch_size, embed_size)
outputs, state = self.rnn(embs)
# outputs shape: (num_steps, batch_size, num_hiddens)
# state shape: (num_layers, batch_size, num_hiddens)
return outputs, state
class Seq2SeqEncoder(d2l.Encoder): #@save
"""The RNN encoder for sequence to sequence learning."""
vocab_size: int
embed_size: int
num_hiddens: int
num_layers: int
dropout: float = 0
def setup(self):
self.embedding = nn.Embed(self.vocab_size, self.embed_size)
self.rnn = d2l.GRU(self.num_hiddens, self.num_layers, self.dropout)
def __call__(self, X, *args, training=False):
# X shape: (batch_size, num_steps)
embs = self.embedding(d2l.transpose(X).astype(jnp.int32))
# embs shape: (num_steps, batch_size, embed_size)
outputs, state = self.rnn(embs, training=training)
# outputs shape: (num_steps, batch_size, num_hiddens)
# state shape: (num_layers, batch_size, num_hiddens)
return outputs, state
class Seq2SeqEncoder(d2l.Encoder): #@save
"""The RNN encoder for sequence to sequence learning."""
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0):
super().__init__()
self.embedding = tf.keras.layers.Embedding(vocab_size, embed_size)
self.rnn = d2l.GRU(num_hiddens, num_layers, dropout)
def call(self, X, *args):
# X shape: (batch_size, num_steps)
embs = self.embedding(tf.transpose(X))
# embs shape: (num_steps, batch_size, embed_size)
outputs, state = self.rnn(embs)
# outputs shape: (num_steps, batch_size, num_hiddens)
# state shape: (num_layers, batch_size, num_hiddens)
return outputs, state
下面用一个具体的例子来说明上述编码器的实现。下面,我们实例化一个隐藏单元数为 16 的两层 GRU 编码器。给定一个小批量序列输入X (批量大小:4,时间步数:9),最后一层在所有时间步的隐藏状态(enc_outputs由编码器的循环层返回)是一个形状的张量(时间步数、批量大小、隐藏单元数)。
vocab_size, embed_size, num_hiddens, num_layers = 10, 8, 16, 2 batch_size, num_steps = 4, 9 encoder = Seq2SeqEncoder(vocab_size, embed_size, num_hiddens, num_layers) X = torch.zeros((batch_size, num_steps)) enc_outputs, enc_state = encoder(X) d2l.check_shape(enc_outputs, (num_steps, batch_size, num_hiddens))
vocab_size, embed_size, num_hiddens, num_layers = 10, 8, 16, 2 batch_size, num_steps = 4, 9 encoder = Seq2SeqEncoder(vocab_size, embed_size, num_hiddens, num_layers) X = np.zeros((batch_size, num_steps)) enc_outputs, enc_state = encoder(X) d2l.check_shape(enc_outputs, (num_steps, batch_size, num_hiddens))
vocab_size, embed_size, num_hiddens, num_layers = 10, 8, 16, 2 batch_size, num_steps = 4, 9 encoder = Seq2SeqEncoder(vocab_size, embed_size, num_hiddens, num_layers) X = jnp.zeros((batch_size, num_steps)) (enc_outputs, enc_state), _ = encoder.init_with_output(d2l.get_key(), X) d2l.check_shape(enc_outputs, (num_steps, batch_size, num_hiddens))
vocab_size, embed_size, num_hiddens, num_layers = 10, 8, 16, 2 batch_size, num_steps = 4, 9 encoder = Seq2SeqEncoder(vocab_size, embed_size, num_hiddens, num_layers) X = tf.zeros((batch_size, num_steps)) enc_outputs, enc_state = encoder(X) d2l.check_shape(enc_outputs, (num_steps, batch_size, num_hiddens))
由于我们在这里使用 GRU,因此最终时间步的多层隐藏状态的形状为(隐藏层数、批量大小、隐藏单元数)。
d2l.check_shape(enc_state, (num_layers, batch_size, num_hiddens))
d2l.check_shape(enc_state, (num_layers, batch_size, num_hiddens))
d2l.check_shape(enc_state, (num_layers, batch_size, num_hiddens))
d2l.check_len(enc_state, num_layers) d2l.check_shape(enc_state[0], (batch_size, num_hiddens))
10.7.3。解码器
给定一个目标输出序列y1,y2,…,yT′对于每个时间步t′(我们用t′为了与输入序列时间步长区分开来),解码器为在步骤中出现的每个可能标记分配一个预测概率yt′+1以目标中的先前标记为条件y1,…,yt′和上下文变量c, IE, P(yt′+1∣y1,…,yt′,c).
预测后续令牌t′+1在目标序列中,RNN 解码器采用上一步的目标标记 yt′,前一时间步的隐藏 RNN 状态 st′−1, 和上下文变量 c作为其输入,并将它们转换为隐藏状态st′在当前时间步。我们可以使用一个函数g表达解码器隐藏层的变换:
(10.7.3)st′=g(yt′−1,c,st′−1).
在获得解码器的隐藏状态后,我们可以使用输出层和 softmax 操作来计算预测分布 p(yt′+1∣y1,…,yt′,c) 在随后的输出令牌上t′+1.
按照图 10.7.1,在如下实现解码器时,我们直接使用编码器最后一个时间步的隐藏状态来初始化解码器的隐藏状态。这要求 RNN 编码器和 RNN 解码器具有相同的层数和隐藏单元。为了进一步合并编码的输入序列信息,上下文变量在所有时间步都与解码器输入连接在一起。为了预测输出标记的概率分布,我们使用全连接层来转换 RNN 解码器最后一层的隐藏状态。
class Seq2SeqDecoder(d2l.Decoder):
"""The RNN decoder for sequence to sequence learning."""
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = d2l.GRU(embed_size+num_hiddens, num_hiddens,
num_layers, dropout)
self.dense = nn.LazyLinear(vocab_size)
self.apply(init_seq2seq)
def init_state(self, enc_all_outputs, *args):
return enc_all_outputs
def forward(self, X, state):
# X shape: (batch_size, num_steps)
# embs shape: (num_steps, batch_size, embed_size)
embs = self.embedding(X.t().type(torch.int32))
enc_output, hidden_state = state
# context shape: (batch_size, num_hiddens)
context = enc_output[-1]
# Broadcast context to (num_steps, batch_size, num_hiddens)
context = context.repeat(embs.shape[0], 1, 1)
# Concat at the feature dimension
embs_and_context = torch.cat((embs, context), -1)
outputs, hidden_state = self.rnn(embs_and_context, hidden_state)
outputs = self.dense(outputs).swapaxes(0, 1)
# outputs shape: (batch_size, num_steps, vocab_size)
# hidden_state shape: (num_layers, batch_size, num_hiddens)
return outputs, [enc_output, hidden_state]
class Seq2SeqDecoder(d2l.Decoder):
"""The RNN decoder for sequence to sequence learning."""
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = d2l.GRU(num_hiddens, num_layers, dropout)
self.dense = nn.Dense(vocab_size, flatten=False)
self.initialize(init.Xavier())
def init_state(self, enc_all_outputs, *args):
return enc_all_outputs
def forward(self, X, state):
# X shape: (batch_size, num_steps)
# embs shape: (num_steps, batch_size, embed_size)
embs = self.embedding(d2l.transpose(X))
enc_output, hidden_state = state
# context shape: (batch_size, num_hiddens)
context = enc_output[-1]
# Broadcast context to (num_steps, batch_size, num_hiddens)
context = np.tile(context, (embs.shape[0], 1, 1))
# Concat at the feature dimension
embs_and_context = np.concatenate((embs, context), -1)
outputs, hidden_state = self.rnn(embs_and_context, hidden_state)
outputs = self.dense(outputs).swapaxes(0, 1)
# outputs shape: (batch_size, num_steps, vocab_size)
# hidden_state shape: (num_layers, batch_size, num_hiddens)
return outputs, [enc_output, hidden_state]
class Seq2SeqDecoder(d2l.Decoder):
"""The RNN decoder for sequence to sequence learning."""
vocab_size: int
embed_size: int
num_hiddens: int
num_layers: int
dropout: float = 0
def setup(self):
self.embedding = nn.Embed(self.vocab_size, self.embed_size)
self.rnn = d2l.GRU(self.num_hiddens, self.num_layers, self.dropout)
self.dense = nn.Dense(self.vocab_size)
def init_state(self, enc_all_outputs, *args):
return enc_all_outputs
def __call__(self, X, state, training=False):
# X shape: (batch_size, num_steps)
# embs shape: (num_steps, batch_size, embed_size)
embs = self.embedding(d2l.transpose(X).astype(jnp.int32))
enc_output, hidden_state = state
# context shape: (batch_size, num_hiddens)
context = enc_output[-1]
# Broadcast context to (num_steps, batch_size, num_hiddens)
context = jnp.tile(context, (embs.shape[0], 1, 1))
# Concat at the feature dimension
embs_and_context = jnp.concatenate((embs, context), -1)
outputs, hidden_state = self.rnn(embs_and_context, hidden_state,
training=training)
outputs = self.dense(outputs).swapaxes(0, 1)
# outputs shape: (batch_size, num_steps, vocab_size)
# hidden_state shape: (num_layers, batch_size, num_hiddens)
return outputs, [enc_output, hidden_state]
class Seq2SeqDecoder(d2l.Decoder):
"""The RNN decoder for sequence to sequence learning."""
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0):
super().__init__()
self.embedding = tf.keras.layers.Embedding(vocab_size, embed_size)
self.rnn = d2l.GRU(num_hiddens, num_layers, dropout)
self.dense = tf.keras.layers.Dense(vocab_size)
def init_state(self, enc_all_outputs, *args):
return enc_all_outputs
def call(self, X, state):
# X shape: (batch_size, num_steps)
# embs shape: (num_steps, batch_size, embed_size)
embs = self.embedding(tf.transpose(X))
enc_output, hidden_state = state
# context shape: (batch_size, num_hiddens)
context = enc_output[-1]
# Broadcast context to (num_steps, batch_size, num_hiddens)
context = tf.tile(tf.expand_dims(context, 0), (embs.shape[0], 1, 1))
# Concat at the feature dimension
embs_and_context = tf.concat((embs, context), -1)
outputs, hidden_state = self.rnn(embs_and_context, hidden_state)
outputs = tf.transpose(self.dense(outputs), (1, 0, 2))
# outputs shape: (batch_size, num_steps, vocab_size)
# hidden_state shape: (num_layers, batch_size, num_hiddens)
return outputs, [enc_output, hidden_state]
为了说明实现的解码器,下面我们使用与上述编码器相同的超参数对其进行实例化。正如我们所见,解码器的输出形状变为(批量大小、时间步数、词汇量大小),其中张量的最后一个维度存储预测的标记分布。
decoder = Seq2SeqDecoder(vocab_size, embed_size, num_hiddens, num_layers) state = decoder.init_state(encoder(X)) dec_outputs, state = decoder(X, state) d2l.check_shape(dec_outputs, (batch_size, num_steps, vocab_size)) d2l.check_shape(state[1], (num_layers, batch_size, num_hiddens))
decoder = Seq2SeqDecoder(vocab_size, embed_size, num_hiddens, num_layers) state = decoder.init_state(encoder(X)) dec_outputs, state = decoder(X, state) d2l.check_shape(dec_outputs, (batch_size, num_steps, vocab_size)) d2l.check_shape(state[1], (num_layers, batch_size, num_hiddens))
decoder = Seq2SeqDecoder(vocab_size, embed_size, num_hiddens, num_layers)
state = decoder.init_state(encoder.init_with_output(d2l.get_key(), X)[0])
(dec_outputs, state), _ = decoder.init_with_output(d2l.get_key(), X,
state)
d2l.check_shape(dec_outputs, (batch_size, num_steps, vocab_size))
d2l.check_shape(state[1], (num_layers, batch_size, num_hiddens))
decoder = Seq2SeqDecoder(vocab_size, embed_size, num_hiddens, num_layers) state = decoder.init_state(encoder(X)) dec_outputs, state = decoder(X, state) d2l.check_shape(dec_outputs, (batch_size, num_steps, vocab_size)) d2l.check_len(state[1], num_layers) d2l.check_shape(state[1][0], (batch_size, num_hiddens))
总而言之,上述 RNN 编码器-解码器模型中的层如图 10.7.2所示。

图 10.7.2 RNN 编码器-解码器模型中的层。
10.7.4。用于序列到序列学习的编码器-解码器
将它们全部放在代码中会产生以下结果:
class Seq2Seq(d2l.EncoderDecoder): #@save
"""The RNN encoder-decoder for sequence to sequence learning."""
def __init__(self, encoder, decoder, tgt_pad, lr):
super().__init__(encoder, decoder)
self.save_hyperparameters()
def validation_step(self, batch):
Y_hat = self(*batch[:-1])
self.plot('loss', self.loss(Y_hat, batch[-1]), train=False)
def configure_optimizers(self):
# Adam optimizer is used here
return torch.optim.Adam(self.parameters(), lr=self.lr)
class Seq2Seq(d2l.EncoderDecoder): #@save
"""The RNN encoder-decoder for sequence to sequence learning."""
def __init__(self, encoder, decoder, tgt_pad, lr):
super().__init__(encoder, decoder)
self.save_hyperparameters()
def validation_step(self, batch):
Y_hat = self(*batch[:-1])
self.plot('loss', self.loss(Y_hat, batch[-1]), train=False)
def configure_optimizers(self):
# Adam optimizer is used here
return gluon.Trainer(self.parameters(), 'adam',
{'learning_rate': self.lr})
class Seq2Seq(d2l.EncoderDecoder): #@save
"""The RNN encoder-decoder for sequence to sequence learning."""
encoder: nn.Module
decoder: nn.Module
tgt_pad: int
lr: float
def validation_step(self, params, batch, state):
l, _ = self.loss(params, batch[:-1], batch[-1], state)
self.plot('loss', l, train=False)
def configure_optimizers(self):
# Adam optimizer is used here
return optax.adam(learning_rate=self.lr)
class Seq2Seq(d2l.EncoderDecoder): #@save
"""The RNN encoder-decoder for sequence to sequence learning."""
def __init__(self, encoder, decoder, tgt_pad, lr):
super().__init__(encoder, decoder)
self.save_hyperparameters()
def validation_step(self, batch):
Y_hat = self(*batch[:-1])
self.plot('loss', self.loss(Y_hat, batch[-1]), train=False)
def configure_optimizers(self):
# Adam optimizer is used here
return tf.keras.optimizers.Adam(learning_rate=self.lr)
10.7.5。带掩蔽的损失函数
在每个时间步,解码器预测输出标记的概率分布。与语言建模一样,我们可以应用 softmax 来获得分布并计算交叉熵损失以进行优化。回想一下10.5 节,特殊的填充标记被附加到序列的末尾,因此不同长度的序列可以有效地加载到相同形状的小批量中。但是,填充令牌的预测应排除在损失计算之外。为此,我们可以用零值屏蔽不相关的条目,以便任何不相关的预测与零的乘积等于零。
@d2l.add_to_class(Seq2Seq) def loss(self, Y_hat, Y): l = super(Seq2Seq, self).loss(Y_hat, Y, averaged=False) mask = (Y.reshape(-1) != self.tgt_pad).type(torch.float32) return (l * mask).sum() / mask.sum()
@d2l.add_to_class(Seq2Seq) def loss(self, Y_hat, Y): l = super(Seq2Seq, self).loss(Y_hat, Y, averaged=False) mask = (Y.reshape(-1) != self.tgt_pad).astype(np.float32) return (l * mask).sum() / mask.sum()
@d2l.add_to_class(Seq2Seq)
@partial(jax.jit, static_argnums=(0, 5))
def loss(self, params, X, Y, state, averaged=False):
Y_hat = state.apply_fn({'params': params}, *X,
rngs={'dropout': state.dropout_rng})
Y_hat = Y_hat.reshape((-1, Y_hat.shape[-1]))
Y = Y.reshape((-1,))
fn = optax.softmax_cross_entropy_with_integer_labels
l = fn(Y_hat, Y)
mask = (Y.reshape(-1) != self.tgt_pad).astype(jnp.float32)
return (l * mask).sum() / mask.sum(), {}
@d2l.add_to_class(Seq2Seq) def loss(self, Y_hat, Y): l = super(Seq2Seq, self).loss(Y_hat, Y, averaged=False) mask = tf.cast(tf.reshape(Y, -1) != self.tgt_pad, tf.float32) return tf.reduce_sum(l * mask) / tf.reduce_sum(mask)
10.7.6。训练
现在我们可以创建和训练一个 RNN 编码器-解码器模型,用于机器翻译数据集上的序列到序列学习。
data = d2l.MTFraEng(batch_size=128)
embed_size, num_hiddens, num_layers, dropout = 256, 256, 2, 0.2
encoder = Seq2SeqEncoder(
len(data.src_vocab), embed_size, num_hiddens, num_layers, dropout)
decoder = Seq2SeqDecoder(
len(data.tgt_vocab), embed_size, num_hiddens, num_layers, dropout)
model = Seq2Seq(encoder, decoder, tgt_pad=data.tgt_vocab[''],
lr=0.005)
trainer = d2l.Trainer(max_epochs=30, gradient_clip_val=1, num_gpus=1)
trainer.fit(model, data)

data = d2l.MTFraEng(batch_size=128)
embed_size, num_hiddens, num_layers, dropout = 256, 256, 2, 0.2
encoder = Seq2SeqEncoder(
len(data.src_vocab), embed_size, num_hiddens, num_layers, dropout)
decoder = Seq2SeqDecoder(
len(data.tgt_vocab), embed_size, num_hiddens, num_layers, dropout)
model = Seq2Seq(encoder, decoder, tgt_pad=data.tgt_vocab[''],
lr=0.005)
trainer = d2l.Trainer(max_epochs=30, gradient_clip_val=1, num_gpus=1)
trainer.fit(model, data)

data = d2l.MTFraEng(batch_size=128)
embed_size, num_hiddens, num_layers, dropout = 256, 256, 2, 0.2
encoder = Seq2SeqEncoder(
len(data.src_vocab), embed_size, num_hiddens, num_layers, dropout)
decoder = Seq2SeqDecoder(
len(data.tgt_vocab), embed_size, num_hiddens, num_layers, dropout)
model = Seq2Seq(encoder, decoder, tgt_pad=data.tgt_vocab[''],
lr=0.005, training=True)
trainer = d2l.Trainer(max_epochs=30, gradient_clip_val=1, num_gpus=1)
trainer.fit(model, data)

data = d2l.MTFraEng(batch_size=128)
embed_size, num_hiddens, num_layers, dropout = 256, 256, 2, 0.2
with d2l.try_gpu():
encoder = Seq2SeqEncoder(
len(data.src_vocab), embed_size, num_hiddens, num_layers, dropout)
decoder = Seq2SeqDecoder(
len(data.tgt_vocab), embed_size, num_hiddens, num_layers, dropout)
model = Seq2Seq(encoder, decoder, tgt_pad=data.tgt_vocab[''],
lr=0.005)
trainer = d2l.Trainer(max_epochs=30, gradient_clip_val=1)
trainer.fit(model, data)

10.7.7。预言
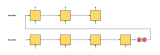
为了预测每一步的输出序列,将前一时间步的预测标记作为输入馈入解码器。一个简单的策略是对解码器在每一步预测时分配最高概率的令牌进行采样。与训练一样,在初始时间步,序列开始(“”)标记被送入解码器。这个预测过程如图 10.7.3所示 。当预测到序列结尾(“”)标记时,输出序列的预测就完成了。

图 10.7.3使用 RNN 编码器-解码器逐个标记地预测输出序列标记。
在下一节中,我们将介绍基于波束搜索的更复杂的策略(第 10.8 节)。
@d2l.add_to_class(d2l.EncoderDecoder) #@save
def predict_step(self, batch, device, num_steps,
save_attention_weights=False):
batch = [a.to(device) for a in batch]
src, tgt, src_valid_len, _ = batch
enc_all_outputs = self.encoder(src, src_valid_len)
dec_state = self.decoder.init_state(enc_all_outputs, src_valid_len)
outputs, attention_weights = [tgt[:, 0].unsqueeze(1), ], []
for _ in range(num_steps):
Y, dec_state = self.decoder(outputs[-1], dec_state)
outputs.append(Y.argmax(2))
# Save attention weights (to be covered later)
if save_attention_weights:
attention_weights.append(self.decoder.attention_weights)
return torch.cat(outputs[1:], 1), attention_weights
@d2l.add_to_class(d2l.EncoderDecoder) #@save
def predict_step(self, batch, device, num_steps,
save_attention_weights=False):
batch = [a.as_in_context(device) for a in batch]
src, tgt, src_valid_len, _ = batch
enc_all_outputs = self.encoder(src, src_valid_len)
dec_state = self.decoder.init_state(enc_all_outputs, src_valid_len)
outputs, attention_weights = [np.expand_dims(tgt[:, 0], 1), ], []
for _ in range(num_steps):
Y, dec_state = self.decoder(outputs[-1], dec_state)
outputs.append(Y.argmax(2))
# Save attention weights (to be covered later)
if save_attention_weights:
attention_weights.append(self.decoder.attention_weights)
return np.concatenate(outputs[1:], 1), attention_weights
@d2l.add_to_class(d2l.EncoderDecoder) #@save
def predict_step(self, params, batch, num_steps,
save_attention_weights=False):
src, tgt, src_valid_len, _ = batch
enc_all_outputs, inter_enc_vars = self.encoder.apply(
{'params': params['encoder']}, src, src_valid_len, training=False,
mutable='intermediates')
# Save encoder attention weights if inter_enc_vars containing encoder
# attention weights is not empty. (to be covered later)
enc_attention_weights = []
if bool(inter_enc_vars) and save_attention_weights:
# Encoder Attention Weights saved in the intermediates collection
enc_attention_weights = inter_enc_vars[
'intermediates']['enc_attention_weights'][0]
dec_state = self.decoder.init_state(enc_all_outputs, src_valid_len)
outputs, attention_weights = [jnp.expand_dims(tgt[:,0], 1), ], []
for _ in range(num_steps):
(Y, dec_state), inter_dec_vars = self.decoder.apply(
{'params': params['decoder']}, outputs[-1], dec_state,
training=False, mutable='intermediates')
outputs.append(Y.argmax(2))
# Save attention weights (to be covered later)
if save_attention_weights:
# Decoder Attention Weights saved in the intermediates collection
dec_attention_weights = inter_dec_vars[
'intermediates']['dec_attention_weights'][0]
attention_weights.append(dec_attention_weights)
return jnp.concatenate(outputs[1:], 1), (attention_weights,
enc_attention_weights)
@d2l.add_to_class(d2l.EncoderDecoder) #@save
def predict_step(self, batch, device, num_steps,
save_attention_weights=False):
src, tgt, src_valid_len, _ = batch
enc_all_outputs = self.encoder(src, src_valid_len, training=False)
dec_state = self.decoder.init_state(enc_all_outputs, src_valid_len)
outputs, attention_weights = [tf.expand_dims(tgt[:, 0], 1), ], []
for _ in range(num_steps):
Y, dec_state = self.decoder(outputs[-1], dec_state, training=False)
outputs.append(tf.argmax(Y, 2))
# Save attention weights (to be covered later)
if save_attention_weights:
attention_weights.append(self.decoder.attention_weights)
return tf.concat(outputs[1:], 1), attention_weights
10.7.8。预测序列的评估
我们可以通过将预测序列与目标序列(ground-truth)进行比较来评估预测序列。但是,比较两个序列之间的相似性的适当衡量标准究竟是什么?
BLEU (Bilingual Evaluation Understudy) 虽然最初是为评估机器翻译结果而提出的 ( Papineni et al. , 2002 ),但已广泛用于测量不同应用的输出序列质量。原则上,对于任何n-grams 在预测序列中,BLEU 评估是否这n-grams 出现在目标序列中。
表示为pn的精度n-grams,即匹配数量的比值n-grams 在预测和目标序列中的数量n-预测序列中的克。解释一下,给定一个目标序列A,B, C,D,E,F, 和一个预测序列 A,B,B,C,D, 我们有 p1=4/5,p2=3/4,p3=1/3, 和 p4=0. 此外,让lenlabel和 lenpred分别是目标序列和预测序列中的标记数。那么,BLEU 被定义为
(10.7.4)exp(min(0,1−lenlabellenpred))∏n=1kpn1/2n,
在哪里k是最长的n-grams 用于匹配。
根据(10.7.4)中BLEU的定义,每当预测序列与目标序列相同时,BLEU为1。而且,由于匹配时间较长n-grams 更难,BLEU 给更长的时间赋予更大的权重n-克精度。具体来说,当pn是固定的,pn1/2n增加为n增长(原始论文使用pn1/n). 此外,由于预测较短的序列往往会获得更高的 pn值, (10.7.4)中乘法项之前的系数 惩罚较短的预测序列。例如,当k=2, 给定目标序列A,B, C,D,E,F和预测序列 A,B, 虽然p1=p2=1, 惩罚因子 exp(1−6/2)≈0.14降低 BLEU。
我们按如下方式实施 BLEU 措施。
def bleu(pred_seq, label_seq, k): #@save
"""Compute the BLEU."""
pred_tokens, label_tokens = pred_seq.split(' '), label_seq.split(' ')
len_pred, len_label = len(pred_tokens), len(label_tokens)
score = math.exp(min(0, 1 - len_label / len_pred))
for n in range(1, min(k, len_pred) + 1):
num_matches, label_subs = 0, collections.defaultdict(int)
for i in range(len_label - n + 1):
label_subs[' '.join(label_tokens[i: i + n])] += 1
for i in range(len_pred - n + 1):
if label_subs[' '.join(pred_tokens[i: i + n])] > 0:
num_matches += 1
label_subs[' '.join(pred_tokens[i: i + n])] -= 1
score *= math.pow(num_matches / (len_pred - n + 1), math.pow(0.5, n))
return score
最后,我们使用经过训练的 RNN 编码器-解码器将一些英语句子翻译成法语,并计算结果的 BLEU。
engs = ['go .', 'i lost .', 'he's calm .', 'i'm home .']
fras = ['va !', 'j'ai perdu .', 'il est calme .', 'je suis chez moi .']
preds, _ = model.predict_step(
data.build(engs, fras), d2l.try_gpu(), data.num_steps)
for en, fr, p in zip(engs, fras, preds):
translation = []
for token in data.tgt_vocab.to_tokens(p):
if token == '':
break
translation.append(token)
print(f'{en} => {translation}, bleu,'
f'{bleu(" ".join(translation), fr, k=2):.3f}')
go . => ['va', '!'], bleu,1.000 i lost . => ["j'ai", 'perdu', '.'], bleu,1.000 he's calm . => ['nous', '', '.'], bleu,0.000 i'm home . => ['je', 'suis', 'chez', 'moi', '.'], bleu,1.000
engs = ['go .', 'i lost .', 'he's calm .', 'i'm home .']
fras = ['va !', 'j'ai perdu .', 'il est calme .', 'je suis chez moi .']
preds, _ = model.predict_step(
data.build(engs, fras), d2l.try_gpu(), data.num_steps)
for en, fr, p in zip(engs, fras, preds):
translation = []
for token in data.tgt_vocab.to_tokens(p):
if token == '':
break
translation.append(token)
print(f'{en} => {translation}, bleu,'
f'{bleu(" ".join(translation), fr, k=2):.3f}')
go . => ['va', '!'], bleu,1.000 i lost . => ["j'ai", 'perdu', '.'], bleu,1.000 he's calm . => ['je', 'le', 'refuse', '.'], bleu,0.000 i'm home . => ['je', 'suis', 'chez', 'moi', '.'], bleu,1.000
engs = ['go .', 'i lost .', 'he's calm .', 'i'm home .']
fras = ['va !', 'j'ai perdu .', 'il est calme .', 'je suis chez moi .']
preds, _ = model.predict_step(trainer.state.params, data.build(engs, fras),
data.num_steps)
for en, fr, p in zip(engs, fras, preds):
translation = []
for token in data.tgt_vocab.to_tokens(p):
if token == '':
break
translation.append(token)
print(f'{en} => {translation}, bleu,'
f'{bleu(" ".join(translation), fr, k=2):.3f}')
go . => ['', '.'], bleu,0.000 i lost . => ["j'ai", 'perdu', '.'], bleu,1.000 he's calm . => ['il', 'est', 'mouillé', '.'], bleu,0.658 i'm home . => ['je', 'suis', 'chez', 'moi', '.'], bleu,1.000
engs = ['go .', 'i lost .', 'he's calm .', 'i'm home .']
fras = ['va !', 'j'ai perdu .', 'il est calme .', 'je suis chez moi .']
preds, _ = model.predict_step(
data.build(engs, fras), d2l.try_gpu(), data.num_steps)
for en, fr, p in zip(engs, fras, preds):
translation = []
for token in data.tgt_vocab.to_tokens(p):
if token == '':
break
translation.append(token)
print(f'{en} => {translation}, bleu,'
f'{bleu(" ".join(translation), fr, k=2):.3f}')
go . => ['va', '!'], bleu,1.000 i lost . => ['je', 'l’ai', 'vu', '.'], bleu,0.000 he's calm . => ['il', '', '.'], bleu,0.000 i'm home . => ['je', 'suis', ' ', '.'], bleu,0.512
10.7.9。概括
按照编码器-解码器架构的设计,我们可以使用两个 RNN 来设计序列到序列学习的模型。在编码器-解码器训练中,teacher forcing 方法将原始输出序列(与预测相反)馈送到解码器。在实现编码器和解码器时,我们可以使用多层 RNN。我们可以使用掩码来过滤掉不相关的计算,比如在计算损失时。至于评估输出序列,BLEU 是一种流行的衡量方法,通过匹配n-预测序列和目标序列之间的克。
10.7.10。练习
你能调整超参数来改善翻译结果吗?
在损失计算中不使用掩码重新运行实验。你观察到什么结果?为什么?
如果编码器和解码器的层数或隐藏单元数不同,我们如何初始化解码器的隐藏状态?
在训练中,用将前一时间步的预测输入解码器来代替教师强制。这对性能有何影响?
用 LSTM 替换 GRU 重新运行实验。
还有其他方法可以设计解码器的输出层吗?
-
解码器
+关注
关注
9文章
1202浏览量
42860 -
pytorch
+关注
关注
2文章
813浏览量
14696
发布评论请先 登录
机器翻译不可不知的Seq2Seq模型
神经机器翻译的方法有哪些?
在机器学习中如何进行基本翻译
神经机器翻译的编码-解码架构有了新进展, 具体要怎么配置?
这款名为Seq2Seq-Vis的工具能将人工智能的翻译过程进行可视化
如此强大的机器翻译架构内部的运行机制究竟是怎样的?
一文看懂NLP里的模型框架 Encoder-Decoder和Seq2Seq
浅析Google Research的LaserTagger和Seq2Edits

PyTorch教程-10.6. 编码器-解码器架构

PyTorch教程-11.4. Bahdanau 注意力机制

基于transformer的编码器-解码器模型的工作原理
基于 Transformers 的编码器-解码器模型
神经编码器-解码器模型的历史





 工商网监
工商网监
评论