 C语言实现单链表-增删改查
C语言实现单链表-增删改查

链表是由一连串节点组成的数据结构,每个节点包含一个数据值和一个指向下一个节点的指针。链表可以在头部和尾部插入和删除节点,因此可以在任何地方插入和删除节点,从而使其变得灵活和易于实现。
链表通常用于实现有序集合,例如队列和双向链表。链表的优点是可以快速随机访问节点,而缺点是插入和删除操作相对慢一些,因为需要移动节点。此外,链表的长度通常受限于内存空间,因此当链表变得很长时,可能需要通过分页或链表分段等方式来管理其内存。
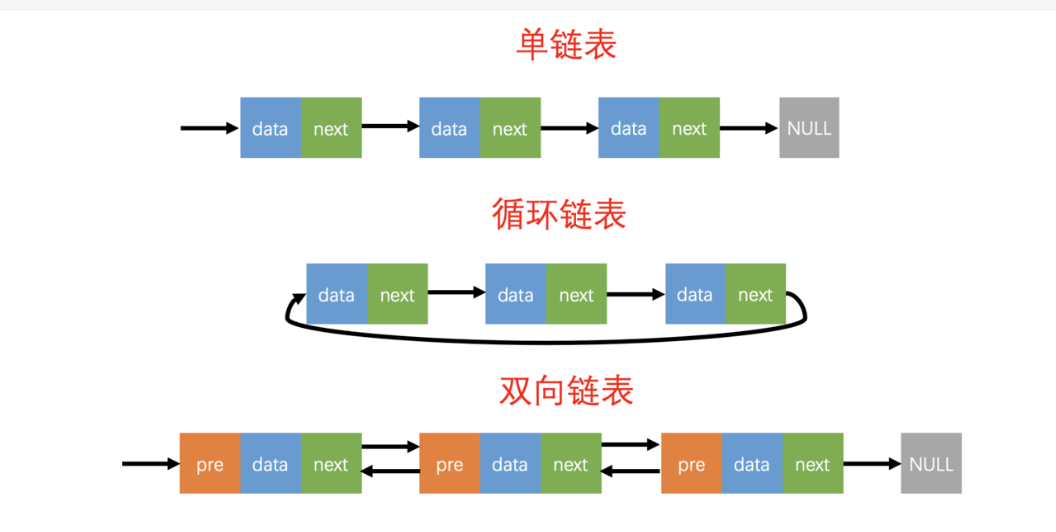
下面是一套封装好的单链表框架,包括创建链表、插入节点、删除节点、修改节点、遍历节点和清空链表等常见操作,其中每个节点存储一个结构体变量,该结构体中包含一个名为data的int类型成员。
#include
#include
// 链表节点结构体
typedef struct ListNode {
int data; // 节点数据
struct ListNode *next; // 下一个节点的指针
} ListNode;
// 创建一个新节点
ListNode *createNode(int data) {
ListNode *node = (ListNode*) malloc(sizeof(ListNode));
node->data = data;
node->next = NULL;
return node;
}
// 在链表头部插入一个新节点
ListNode *insertNodeAtHead(ListNode *head, int data) {
ListNode *node = createNode(data);
node->next = head;
return node;
}
// 在链表尾部插入一个新节点
ListNode *insertNodeAtTail(ListNode *head, int data) {
ListNode *node = createNode(data);
if(head == NULL) {
return node;
} else {
ListNode *current = head;
while(current->next != NULL) {
current = current->next;
}
current->next = node;
return head;
}
}
// 删除链表中第一个值为data的节点
ListNode *deleteNode(ListNode *head, int data) {
if(head == NULL) {
return NULL;
}
if(head->data == data) {
ListNode *current = head;
head = head->next;
free(current);
return head;
}
ListNode *current = head;
while(current->next != NULL && current->next->data != data) {
current = current->next;
}
if(current->next != NULL) {
ListNode *deleteNode = current->next;
current->next = deleteNode->next;
free(deleteNode);
}
return head;
}
// 修改链表中第一个值为oldData的节点的数据为newData
void updateNode(ListNode *head, int oldData, int newData) {
ListNode *current = head;
while(current != NULL) {
if(current->data == oldData) {
current->data = newData;
break;
} else {
current = current->next;
}
}
}
// 遍历链表
void traverseList(ListNode *head) {
ListNode *current = head;
while(current != NULL) {
printf("%d ", current->data);
current = current->next;
}
printf("
");
}
// 清空链表,释放所有节点的内存空间
void clearList(ListNode *head) {
while(head != NULL) {
ListNode *current = head;
head = head->next;
free(current);
}
}
// 示例程序
int main() {
ListNode *head = NULL;
head = insertNodeAtHead(head, 1);
head = insertNodeAtHead(head, 2);
head = insertNodeAtTail(head, 3);
traverseList(head);
head = deleteNode(head, 2);
traverseList(head);
updateNode(head, 1, 4);
traverseList(head);
clearList(head);
return 0;
}
在上述代码中,定义了一个节点结构体ListNode,其中包含一个int类型的data成员和一个指向下一个节点的指针。接着定义了用于创建新节点、插入节点、删除节点、修改节点、遍历节点和清空链表等操作的子函数,并在main函数中演示了这些操作的使用例子。在使用完链表后一定要调用clearList函数释放内存空间。
审核编辑:汤梓红
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
内存
+关注
关注
9文章
3234浏览量
76517 -
C语言
+关注
关注
183文章
7646浏览量
146167 -
函数
+关注
关注
3文章
4422浏览量
67848 -
指针
+关注
关注
1文章
484浏览量
71960 -
数据结构
+关注
关注
3文章
573浏览量
41683
发布评论请先 登录
相关推荐
热点推荐
Qt(C++)使用SQLite数据库完成数据增删改查
当前文章介绍的设计的主要功能是利用 SQLite 数据库实现宠物投喂器上传数据的存储,并且支持数据的增删改查操作。其中,宠物投喂器上传的数据包括投喂间隔时间、水温、剩余重量等参数。

Mybatis自动生成增删改查代码
使用 mybatis generator 自动生成代码,实现数据库的增删改查。 1 配置Mybatis插件 在pom文件添加依赖: pluginsplugin
Qt(C++)使用SQLite数据库完成数据增删改查
当前文章介绍的设计的主要功能是利用 SQLite 数据库实现宠物投喂器上传数据的存储,并且支持数据的增删改查操作。其中,宠物投喂器上传的数据包括投喂间隔时间、水温、剩余重量等参数。
SQLite数据库增删改查
SQLite数据库增删改查 SQLite是一种轻量级的RDBMS(关系型数据库管理系统),具有速度快、易用性高等优点。虽然SQLite数据库相对于一些大型数据库管理系统而言功能上存在较多的限制
mysql数据库的增删改查sql语句
MySQL是一种常用的关系型数据库管理系统,是许多网站和应用程序的首选数据库。在MySQL中,我们可以使用SQL(结构化查询语言)进行数据的增删改查操作。本文将详细介绍MySQL数据库的增删改
数据库mysql基本增删改查
MySQL是一种开源的关系型数据库管理系统,常用于Web应用程序的数据存储和管理。通过使用MySQL,用户可以进行数据的增删改查操作,从而实现对数据的有效管理。下面将详细介绍MySQL数据库



评论