 基于统计频率的 baseline 方法
基于统计频率的 baseline 方法

1引言
场景图是一种结构表示,它将图片中的对象表示为节点,并将它们的关系表示为边。最近,场景图已成功应用于不同的视觉任务,例如图像检索[3]、目标检测、语义分割、图像合成[4]和高级视觉-语言任务(如图像字幕[1]或视觉问答[2]等)。它是一种具有丰富信息量的整体场景理解方法,可以连接视觉和自然语言领域之间巨大差距的桥梁。
虽然从单个图像生成场景图(静态场景图生成)取得了很大进展,但从视频生成场景图(动态场景图生成)的任务是新的且更具挑战性。最流行的静态场景图生成方法是建立在对象检测器之上的,然后推断它们的关系类型以及它们的对象类。然而,物体在视频序列的每一帧中不一定是一致的,任意两个物体之间的关系可能会因为它们的运动而变化,具有动态的特点。在这种情况下,时间依赖性发挥了作用,因此,静态场景图生成方法不能直接应用于动态场景图生成,这在[5]中进行了充分讨论。
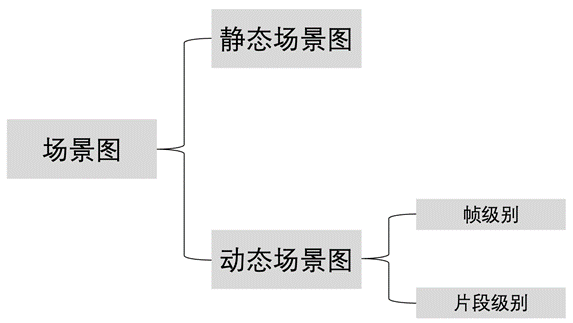
图1. 场景图分类
2 静态场景图
2.1 任务定义
静态场景图生成任务(Staticscene graph generation)目标是让计算机自动生成一种语义化的图结构(称为 scenegraph,场景图),作为图像的表示。图像中的目标对应 graph node,目标间的关系对应 graph edge(目标的各种属性,如颜色,有时会在图中表示)。 这种结构化表示方法相对于向量表示更加直观,可以看作是小型知识图谱,因此可以广泛应用于知识管理、推理、检索、推荐等。此外,该表示方法是模态无关的,自然语言、视频、语音等数据同样可以表示成类似结构,因此对于融合多模态信息很有潜力。
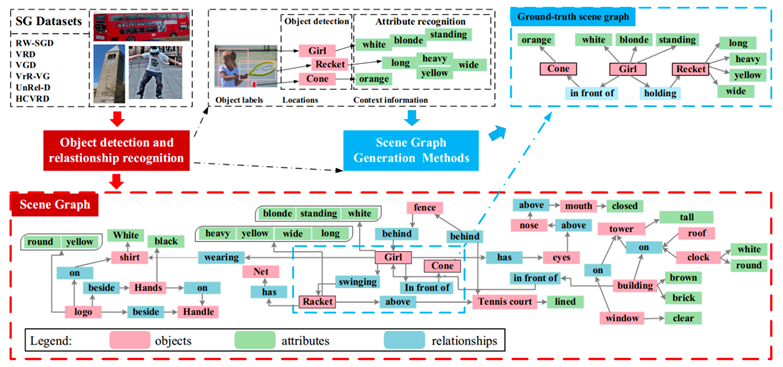
图2.静态场景图生成任务图例
2.2 数据集
Visual Genome(VG)[6]于2016年提出,是这个领域最常用的数据集,包含对超过 10W 张图片的目标、属性、关系、自然语言描述、视觉问答等的标注。与此任务相关的数据总结如下:
物体:表示为场景图中节点,使用bounding box标注物体的坐标信息,包含对应的类别信息。VG包含约17000种目标。
关系:表示为场景图中边,包含动作关系,空间关系,从属关系和动词等。VG中包含约13000种关系。
属性:可以是颜色,状态等。Visual Genome 包含约 155000 种属性。
2.3 方法分类
方法分类如下:
P(O,B,R | I) = P(O,B | I) * P(R| I,O,B),即先目标检测,再进行关系预测(有一个专门研究该子任务的领域,称为研究视觉关系识别,visual relationship detection)。最简单的方法是下文中基于统计频率的 baseline 方法,另外做视觉关系检测任务的大多数工作都可以应用到这里。
P(O,B,R | I) = P(B | I) * P(R,O| I,O,B),即先定位目标,然后将一张图片中所有的目标和关系看作一个未标记的图结构,再分别对节点和边进行类别预测。这种做法考虑到了一张图片中的各元素互为上下文,为彼此分类提供辅助信息。事实上,自此类方法提出之后[7],才正式有了 scenegraph generation 这个新任务名称(之前基本都称为visual relationship detection)。
2.4 评价指标
最常用的评价指标是 recall@topk, 即主谓宾关系三元组
3 动态场景图
3.1 任务定义
动态场景图与静态场景图不同,动态场景图以视频作为输入,输出分为两种情况:输出每一帧对应的场景图(帧级别场景图);输出每一段视频对应的场景图(片段级别场景图)。这种结构化的表示可以表征实体之间随时间变化的动作及状态。
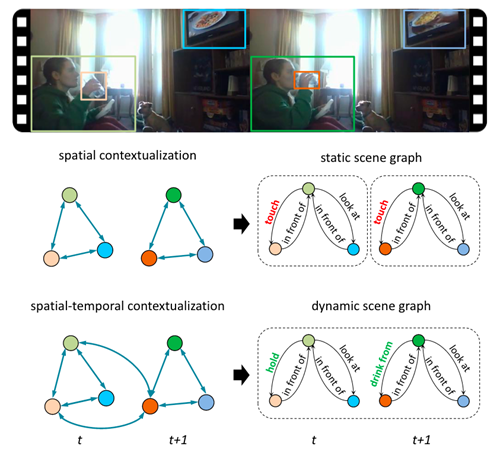
图3.静态/动态场景图区别示例
3.2 帧级别
3.2.1数据集
Action Genome该数据集是Visual Genome表示的带时间版本,然而,Visual Genome的目的是详尽的捕捉图中每一个区域的物体和关系,而Action Genome的目标是将动作分解,专注于对那些动作发生的视频片段进行标注,并且只标注动作涉及的对象。Action Genome基于Charades进行标注,该数据集包含157类别动作,144个是人类-物体活动。在Charades中,有很多动作可以同时发生。共有234253个frame,476229个bounding box,35个对象类别,1715568个关系,25个关系类别。
3.2.2 方法
Spatial-temporalTransformer(STTran)[8]:一种由两个核心模块组成的神经网络:一个空间编码器,它采用输入帧来提取空间上下文并推断帧内的视觉关系,以及一个时间解码器它将空间编码器的输出作为输入,以捕获帧之间的时间依赖性并推断动态关系。此外,STTran 可以灵活地将不同长度的视频作为输入而无需剪辑,这对于长视频尤为重要。
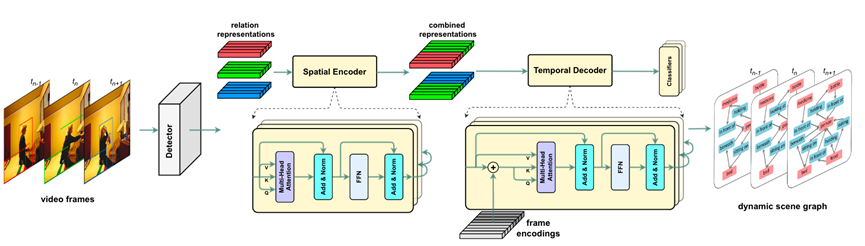
图4.STTrans模型结构
3.2.3 主实验结果

图5.STTrans模型实验结果
3.2.4 样例测试
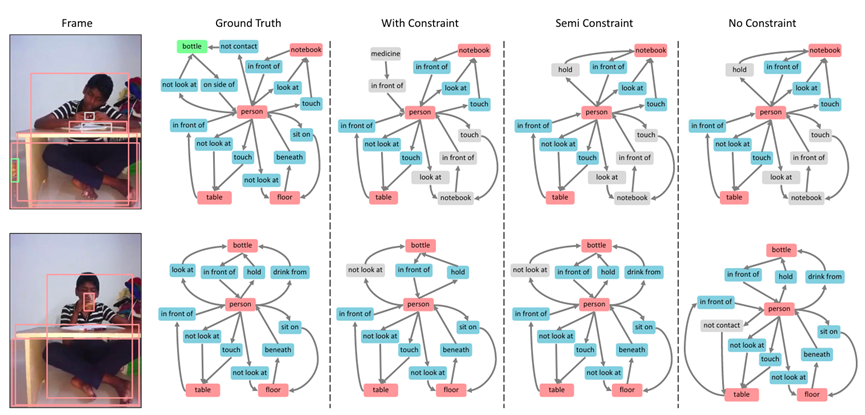
图6. 样例
3.3 片段级别
3.3.1 数据集
VidVRD提出了一个新颖的VidVRD任务,旨在探索视频中物体之间的各种关系,它提供了一个比ImgVRD更可行的VRD任务,通过目标轨迹建议、关系预测和贪婪关系关联来检测视频中的视觉关系,包含1000个带有手动标记的视觉关系的视频,被分解为30帧的片段,其中由15帧重叠,再进行谓词标记。30类+(人、球、沙发、滑板、飞盘)=35类(独立,没有对象之间的包含关系),14个及物动词、3个比较词、11个空间谓词,11个不及物动词,能够衍生160类谓词。
3.3.2 方法
VidSGG提出了一个新的框架,在此框架下,将视频场景图重新表述为时间二分图,其中实体和谓词是两类具有时隙的节点,边表示这些节点之间的不同语义角色。
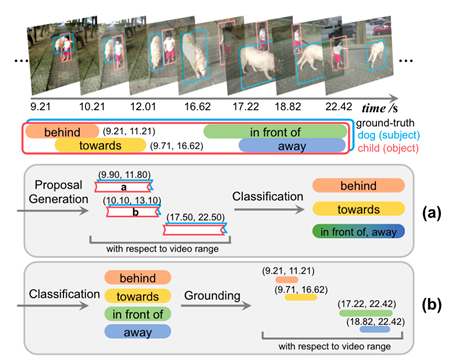
图7.VidVRD任务示例
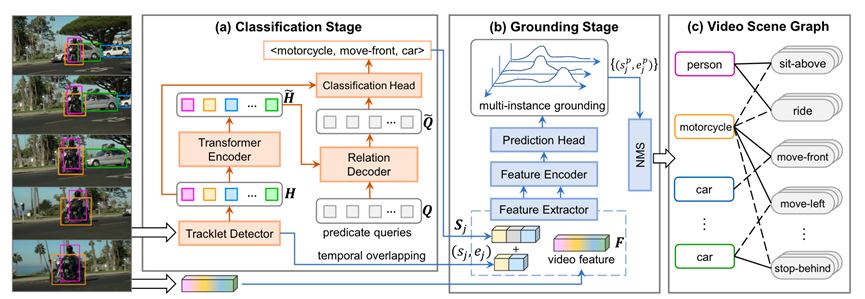
图8.BIG-C模型结构
3.3.3 主实验结果
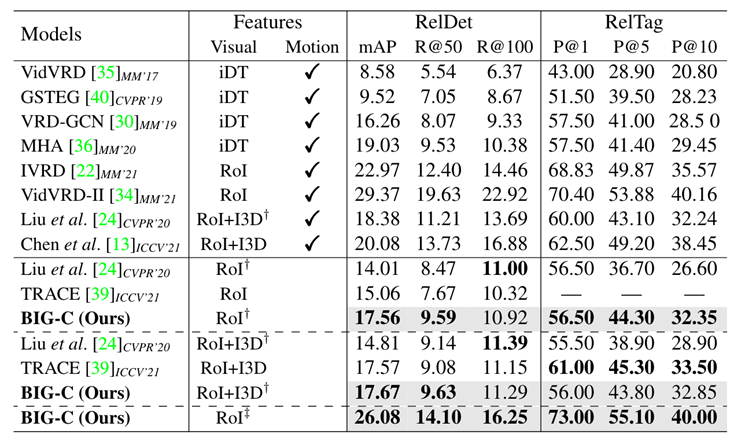
图9.BIG-C模型实验结果
3.3.4 样例测试
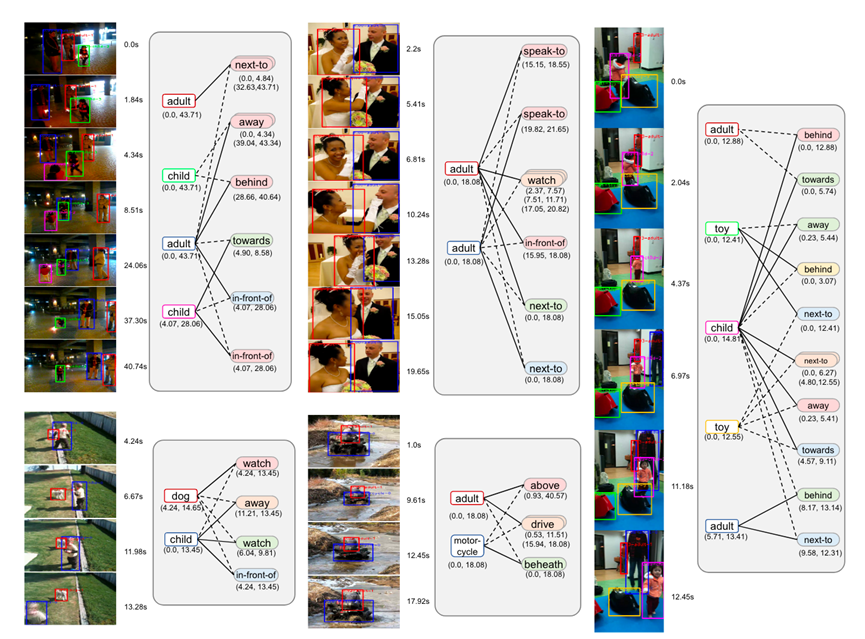
图10.对话情绪识别示例
-
检测器
+关注
关注
1文章
924浏览量
49656 -
Baseline
+关注
关注
0文章
3浏览量
7020 -
数据集
+关注
关注
4文章
1230浏览量
26046
原文标题:哈工大SCIR | 场景图生成简述
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
看门狗唤醒导致baseline降低的原因?
6678功耗计算工具中baseline功耗问题
8168编码的问题,如何编出baseline profile 3.1的H264码流
爱立信话务统计概述

支持Baseline和Extended Sequential
基于统计和理解的自动摘要方法

基于步数步幅统计的测距方法





 工商网监
工商网监
评论