 Linux 性能优化总结!1
Linux 性能优化总结!1

性能优化
性能指标
高并发和响应快对应着性能优化的两个核心指标:吞吐和延时

- 应用负载角度:直接影响了产品终端的用户体验
- 系统资源角度:资源使用率、饱和度等
性能问题的本质就是系统资源已经到达瓶颈,但请求的处理还不够快,无法支撑更多的请求。性能分析实际上就是找出应用或系统的瓶颈,设法去避免或缓解它们。
- 选择指标评估应用程序和系统性能
- 为应用程序和系统设置性能目标
- 进行性能基准测试
- 性能分析定位瓶颈
- 性能监控和告警
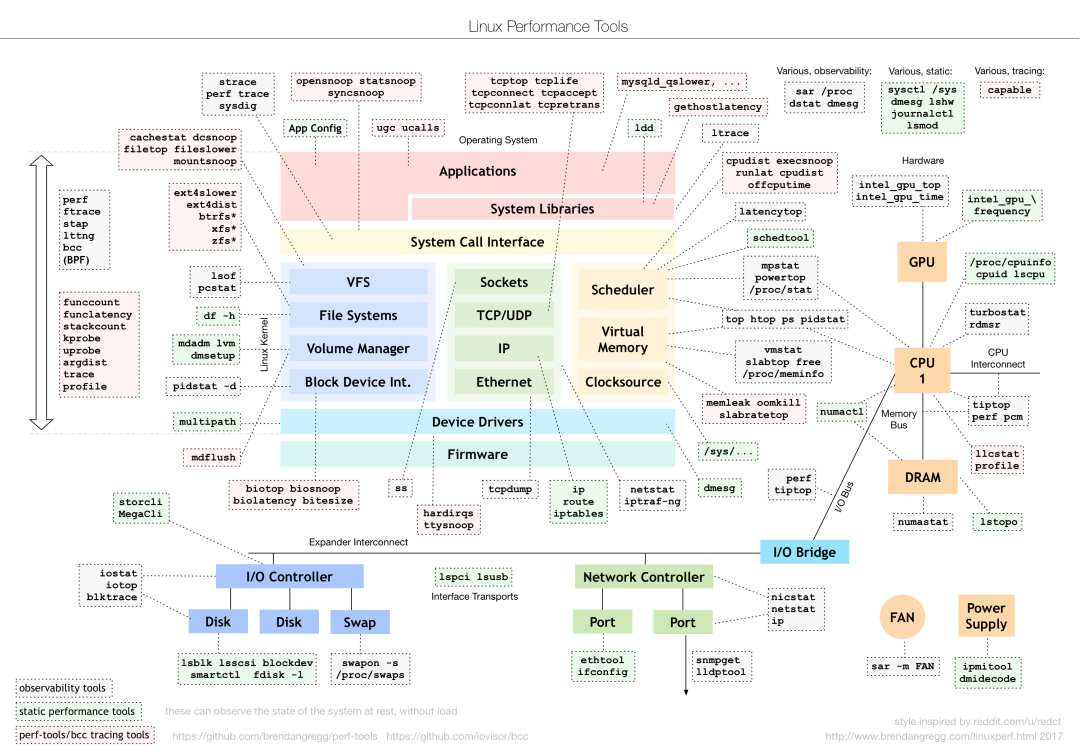
对于不同的性能问题要选取不同的性能分析工具。下面是常用的Linux Performance Tools以及对应分析的性能问题类型。
到底应该怎么理解”平均负载”
平均负载 :单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数。它和我们传统意义上理解的CPU使用率并没有直接关系。
其中不可中断进程是正处于内核态关键流程中的进程(如常见的等待设备的I/O响应)。不可中断状态实际上是系统对进程和硬件设备的一种保护机制。
平均负载多少时合理
实际生产环境中将系统的平均负载监控起来,根据历史数据判断负载的变化趋势。当负载存在明显升高趋势时,及时进行分析和调查。当然也可以当设置阈值(如当平均负载高于CPU数量的70%时)
现实工作中我们会经常混淆平均负载和CPU使用率的概念,其实两者并不完全对等:
- CPU 密集型进程,大量 CPU 使用会导致平均负载升高,此时两者一致
- I/O 密集型进程,等待 I/O 也会导致平均负载升高,此时 CPU 使用率并不一定高
- 大量等待 CPU 的进程调度会导致平均负载升高,此时 CPU 使用率也会比较高
平均负载高时可能是 CPU 密集型进程导致,也可能是 I/O 繁忙导致。具体分析时可以结合 mpstat/pidstat 工具辅助分析负载来源。
CPU
CPU上下文切换(上)
CPU 上下文切换,就是把前一个任务的 CPU 上下文(CPU 寄存器和 PC)保存起来,然后加载新任务的上下文到这些寄存器和程序计数器,最后再跳转到程序计数器所指的位置,运行新任务。其中,保存下来的上下文会存储在系统内核中,待任务重新调度执行时再加载,保证原来的任务状态不受影响。
按照任务类型,CPU 上下文切换分为:
- 进程上下文切换
- 线程上下文切换
- 中断上下文切换
进程上下文切换
Linux 进程按照等级权限将进程的运行空间分为内核空间和用户空间。从用户态向内核态转变时需要通过系统调用来完成。
一次系统调用过程其实进行了两次 CPU 上下文切换:
- CPU 寄存器中用户态的指令位置先保存起来,CPU 寄存器更新为内核态指令的位置,跳转到内核态运行内核任务;
- 系统调用结束后,CPU 寄存器恢复原来保存的用户态数据,再切换到用户空间继续运行。
系统调用过程中并不会涉及虚拟内存等进程用户态资源,也不会切换进程。和传统意义上的进程上下文切换不同。因此系统调用通常称为特权模式切换。
进程是由内核管理和调度的,进程上下文切换只能发生在内核态。因此相比系统调用来说,在保存当前进程的内核状态和CPU寄存器之前,需要先把该进程的虚拟内存,栈保存下来。再加载新进程的内核态后,还要刷新进程的虚拟内存和用户栈。
进程只有在调度到CPU上运行时才需要切换上下文,有以下几种场景:CPU时间片轮流分配,系统资源不足导致进程挂起,进程通过sleep函数主动挂起,高优先级进程抢占时间片,硬件中断时CPU上的进程被挂起转而执行内核中的中断服务。
线程上下文切换
线程上下文切换分为两种:
- 前后线程同属于一个进程,切换时虚拟内存资源不变,只需要切换线程的私有数据,寄存器等;
- 前后线程属于不同进程,与进程上下文切换相同。
同进程的线程切换消耗资源较少,这也是多线程的优势。
中断上下文切换
中断上下文切换并不涉及到进程的用户态,因此中断上下文只包括内核态中断服务程序执行所必须的状态(CPU寄存器,内核堆栈,硬件中断参数等)。
中断处理优先级比进程高,所以中断上下文切换和进程上下文切换不会同时发生
CPU上下文切换(下)
通过 vmstat 可以查看系统总体的上下文切换情况
vmstat 5 #每隔5s输出一组数据procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 1 0 0 103388 145412 511056 0 0 18 60 1 1 2 1 96 0 0 0 0 0 103388 145412 511076 0 0 0 2 450 1176 1 1 99 0 0 0 0 0 103388 145412 511076 0 0 0 8 429 1135 1 1 98 0 0 0 0 0 103388 145412 511076 0 0 0 0 431 1132 1 1 98 0 0 0 0 0 103388 145412 511076 0 0 0 10 467 1195 1 1 98 0 0 1 0 0 103388 145412 511076 0 0 0 2 426 1139 1 0 99 0 0 4 0 0 95184 145412 511108 0 0 0 74 500 1228 4 1 94 0 0 0 0 0 103512 145416 511076 0 0 0 455 723 1573 12 3 83 2 0- cs (context switch) 每秒上下文切换次数
- in (interrupt) 每秒中断次数
- r (runnning or runnable)就绪队列的长度,正在运行和等待CPU的进程数
- b (Blocked) 处于不可中断睡眠状态的进程数
要查看每个进程的详细情况,需要使用pidstat来查看每个进程上下文切换情况
pidstat -w 514时51分16秒 UID PID cswch/s nvcswch/s Command14时51分21秒 0 1 0.80 0.00 systemd14时51分21秒 0 6 1.40 0.00 ksoftirqd/014时51分21秒 0 9 32.67 0.00 rcu_sched14时51分21秒 0 11 0.40 0.00 watchdog/014时51分21秒 0 32 0.20 0.00 khugepaged14时51分21秒 0 271 0.20 0.00 jbd2/vda1-814时51分21秒 0 1332 0.20 0.00 argusagent14时51分21秒 0 5265 10.02 0.00 AliSecGuard14时51分21秒 0 7439 7.82 0.00 kworker/0:214时51分21秒 0 7906 0.20 0.00 pidstat14时51分21秒 0 8346 0.20 0.00 sshd14时51分21秒 0 20654 9.82 0.00 AliYunDun14时51分21秒 0 25766 0.20 0.00 kworker/u2:114时51分21秒 0 28603 1.00 0.00 python3- cswch 每秒自愿上下文切换次数(进程无法获取所需资源导致的上下文切换)
- nvcswch 每秒非自愿上下文切换次数(时间片轮流等系统强制调度)
vmstat 1 1 #新终端观察上下文切换情况此时发现cs数据明显升高,同时观察其他指标:r列:远超系统CPU个数,说明存在大量CPU竞争us和sy列:sy列占比80%,说明CPU主要被内核占用in列:中断次数明显上升,说明中断处理也是潜在问题说明运行/等待CPU的进程过多,导致大量的上下文切换,上下文切换导致系统的CPU占用率高
pidstat -w -u 1 #查看到底哪个进程导致的问题从结果中看出是 sysbench 导致 CPU 使用率过高,但是 pidstat 输出的上下文次数加起来也并不多。分析 sysbench 模拟的是线程的切换,因此需要在 pidstat 后加 -t 参数查看线程指标。
另外对于中断次数过多,我们可以通过 /proc/interrupts 文件读取
watch -d cat /proc/interrupts发现次数变化速度最快的是重调度中断(RES),该中断用来唤醒空闲状态的CPU来调度新的任务运行。分析还是因为过多任务的调度问题,和上下文切换分析一致。
某个应用的CPU使用率达到100%,怎么办?
Linux作为多任务操作系统,将CPU时间划分为很短的时间片,通过调度器轮流分配给各个任务使用。为了维护CPU时间,Linux通过事先定义的节拍率,触发时间中断,并使用全局变了jiffies记录开机以来的节拍数。时间中断发生一次该值+1.
CPU使用率,除了空闲时间以外的其他时间占总CPU时间的百分比。可以通过/proc/stat中的数据来计算出CPU使用率。因为/proc/stat时开机以来的节拍数累加值,计算出来的是开机以来的平均CPU使用率,一般意义不大。可以间隔取一段时间的两次值作差来计算该段时间内的平均CPU使用率。性能分析工具给出的都是间隔一段时间的平均CPU使用率,要注意间隔时间的设置。
CPU使用率可以通过top 或 ps来查看。分析进程的CPU问题可以通过perf,它以性能事件采样为基础,不仅可以分析系统的各种事件和内核性能,还可以用来分析指定应用程序的性能问题。
perf top / perf record / perf report (-g 开启调用关系的采样)
sudo docker run --name nginx -p 10000:80 -itd feisky/nginxsudo docker run --name phpfpm -itd --network container:nginx feisky/php-fpm
ab -c 10 -n 100 http://XXX.XXX.XXX.XXX:10000/ #测试Nginx服务性能发现此时每秒可承受请求给长少,此时将测试的请求数从100增加到10000。在另外一个终端运行top查看每个CPU的使用率。发现系统中几个php-fpm进程导致CPU使用率骤升。
接着用perf来分析具体是php-fpm中哪个函数导致该问题。
perf top -g -p XXXX #对某一个php-fpm进程进行分析发现其中 sqrt 和 add_function 占用 CPU 过多, 此时查看源码找到原来是sqrt中在发布前没有删除测试代码段,存在一个百万次的循环导致。将该无用代码删除后发现nginx负载能力明显提升
系统的CPU使用率很高,为什么找不到高CPU的应用?
sudo docker run --name nginx -p 10000:80 -itd feisky/nginx:spsudo docker run --name phpfpm -itd --network container:nginx feisky/php-fpm:spab -c 100 -n 1000 http://XXX.XXX.XXX.XXX:10000/ #并发100个请求测试实验结果中每秒请求数依旧不高,我们将并发请求数降为5后,nginx负载能力依旧很低。
此时用top和pidstat发现系统CPU使用率过高,但是并没有发现CPU使用率高的进程。
出现这种情况一般时我们分析时遗漏的什么信息,重新运行top命令并观察一会。发现就绪队列中处于Running状态的进行过多,超过了我们的并发请求次数5. 再仔细查看进程运行数据,发现nginx和php-fpm都处于sleep状态,真正处于运行的却是几个stress进程。
下一步就利用pidstat分析这几个stress进程,发现没有任何输出。用ps aux交叉验证发现依旧不存在该进程。说明不是工具的问题。再top查看发现stress进程的进程号变化了,此时有可能时以下两种原因导致:
- 进程不停的崩溃重启(如段错误/配置错误等),此时进程退出后可能又被监控系统重启;
- 短时进程导致,即其他应用内部通过 exec 调用的外面命令,这些命令一般只运行很短时间就结束,很难用top这种间隔较长的工具来发现
可以通过pstree来查找 stress 的父进程,找出调用关系。
pstree | grep stress发现是php-fpm调用的该子进程,此时去查看源码可以看出每个请求都会调用一个stress命令来模拟I/O压力。之前top显示的结果是CPU使用率升高,是否真的是由该stress命令导致的,还需要继续分析。代码中给每个请求加了verbose=1的参数后可以查看stress命令的输出,在中断测试该命令结果显示stress命令运行时存在因权限问题导致的文件创建失败的bug。
此时依旧只是猜测,下一步继续通过perf工具来分析。性能报告显示确实时stress占用了大量的CPU,通过修复权限问题来优化解决即可。
系统中出现大量不可中断进程和僵尸进程怎么办?
进程状态
R Running/Runnable,表示进程在CPU的就绪队列中,正在运行或者等待运行;
D Disk Sleep,不可中断状态睡眠,一般表示进程正在跟硬件交互,并且交互过程中不允许被其他进程中断;
Z Zombie,僵尸进程,表示进程实际上已经结束,但是父进程还没有回收它的资源;
S Interruptible Sleep,可中断睡眠状态,表示进程因为等待某个事件而被系统挂起,当等待事件发生则会被唤醒并进入R状态;
I Idle,空闲状态,用在不可中断睡眠的内核线程上。该状态不会导致平均负载升高;
T Stop/Traced,表示进程处于暂停或跟踪状态(SIGSTOP/SIGCONT, GDB调试);
X Dead,进程已经消亡,不会在top/ps中看到。
对于不可中断状态,一般都是在很短时间内结束,可忽略。但是如果系统或硬件发生故障,进程可能会保持不可中断状态很久,甚至系统中出现大量不可中断状态,此时需注意是否出现了I/O性能问题。
僵尸进程一般多进程应用容易遇到,父进程来不及处理子进程状态时子进程就提前退出,此时子进程就变成了僵尸进程。大量的僵尸进程会用尽PID进程号,导致新进程无法建立。
磁盘O_DIRECT问题
sudo docker run --privileged --name=app -itd feisky/app:iowaitps aux | grep '/app'可以看到此时有多个app进程运行,状态分别时Ss+和D+。其中后面s表示进程是一个会话的领导进程,+号表示前台进程组。
其中进程组表示一组相互关联的进程,子进程是父进程所在组的组员。会话指共享同一个控制终端的一个或多个进程组。
用top查看系统资源发现:1)平均负载在逐渐增加,且1分钟内平均负载达到了CPU个数,说明系统可能已经有了性能瓶颈;2)僵尸进程比较多且在不停增加;3)us和sys CPU使用率都不高,iowait却比较高;4)每个进程CPU使用率也不高,但有两个进程处于D状态,可能在等待IO。
分析目前数据可知:iowait过高导致系统平均负载升高,僵尸进程不断增长说明有程序没能正确清理子进程资源。
用dstat来分析,因为它可以同时查看CPU和I/O两种资源的使用情况,便于对比分析。
dstat 1 10 #间隔1秒输出10组数据可以看到当wai(iowait)升高时磁盘请求read都会很大,说明iowait的升高和磁盘的读请求有关。接下来分析到底时哪个进程在读磁盘。
之前 Top 查看的处于 D 状态的进程号,用 pidstat -d -p XXX 展示进程的 I/O 统计数据。发现处于 D 状态的进程都没有任何读写操作。在用 pidstat -d 查看所有进程的 I/O统计数据,看到 app 进程在进行磁盘读操作,每秒读取 32MB 的数据。进程访问磁盘必须使用系统调用处于内核态,接下来重点就是找到app进程的系统调用。
sudo strace -p XXX #对app进程调用进行跟踪报错没有权限,因为已经时 root 权限了。所以遇到这种情况,首先要检查进程状态是否正常。ps 命令查找该进程已经处于Z状态,即僵尸进程。
这种情况下top pidstat之类的工具无法给出更多的信息,此时像第5篇一样,用 perf record -d和 perf report 进行分析,查看app进程调用栈。
看到 app 确实在通过系统调用 sys_read() 读取数据,并且从 new_sync_read和 blkdev_direct_IO看出进程时进行直接读操作,请求直接从磁盘读,没有通过缓存导致iowait升高。
通过层层分析后,root cause 是 app 内部进行了磁盘的直接I/O。然后定位到具体代码位置进行优化即可。
僵尸进程
上述优化后 iowait 显著下降,但是僵尸进程数量仍旧在增加。首先要定位僵尸进程的父进程,通过pstree -aps XXX,打印出该僵尸进程的调用树,发现父进程就是app进程。
查看app代码,看看子进程结束的处理是否正确(是否调用wait()/waitpid(),有没有注册SIGCHILD信号的处理函数等)。
碰到iowait升高时,先用dstat pidstat等工具确认是否存在磁盘I/O问题,再找是哪些进程导致I/O,不能用strace直接分析进程调用时可以通过perf工具分析。
对于僵尸问题,用pstree找到父进程,然后看源码检查子进程结束的处理逻辑即可。
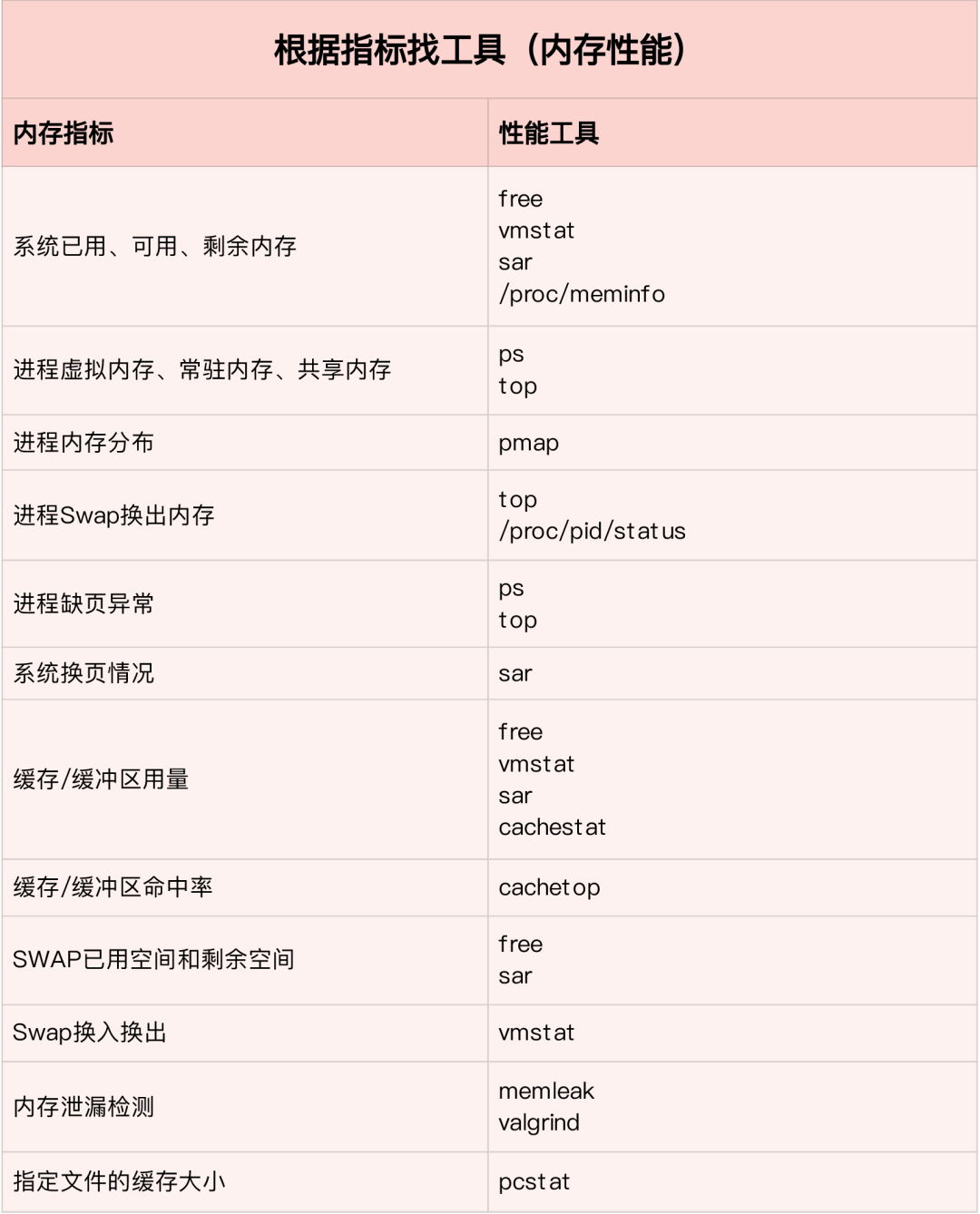
CPU性能指标
- CPU使用率
- 用户CPU使用率, 包括用户态(user)和低优先级用户态(nice). 该指标过高说明应用程序比较繁忙.
- 系统CPU使用率, CPU在内核态运行的时间百分比(不含中断). 该指标高说明内核比较繁忙.
- 等待I/O的CPU使用率, iowait, 该指标高说明系统与硬件设备I/O交互时间比较长.
- 软/硬中断CPU使用率, 该指标高说明系统中发生大量中断.
- steal CPU / guest CPU, 表示虚拟机占用的CPU百分比.
- 平均负载
- 理想情况下平均负载等于逻辑CPU个数,表示每个CPU都被充分利用. 若大于则说明系统负载较重.
- 进程上下文切换
- 包括无法获取资源的自愿切换和系统强制调度时的非自愿切换. 上下文切换本身是保证Linux正常运行的一项核心功能. 过多的切换则会将原本运行进程的CPU时间消耗在寄存器,内核占及虚拟内存等数据保存和恢复上
- CPU缓存命中率
- CPU缓存的复用情况,命中率越高性能越好. 其中L1/L2常用在单核,L3则用在多核中
性能工具
- 平均负载案例
- 先用uptime查看系统平均负载
- 判断负载在升高后再用mpstat和pidstat分别查看每个CPU和每个进程CPU使用情况.找出导致平均负载较高的进程.
- 上下文切换案例
- 先用vmstat查看系统上下文切换和中断次数
- 再用pidstat观察进程的自愿和非自愿上下文切换情况
- 最后通过pidstat观察线程的上下文切换情况
- 进程CPU使用率高案例
- 先用top查看系统和进程的CPU使用情况,定位到进程
- 再用perf top观察进程调用链,定位到具体函数
- 系统CPU使用率高案例
- 先用top查看系统和进程的CPU使用情况,top/pidstat都无法找到CPU使用率高的进程
- 重新审视top输出
- 从CPU使用率不高,但是处于Running状态的进程入手
- perf record/report发现短时进程导致 (execsnoop工具)
- 不可中断和僵尸进程案例
- 先用top观察iowait升高,发现大量不可中断和僵尸进程
- strace无法跟踪进程系统调用
- perf分析调用链发现根源来自磁盘直接I/O
- 软中断案例
- top观察系统软中断CPU使用率高
- 查看/proc/softirqs找到变化速率较快的几种软中断
- sar命令发现是网络小包问题
- tcpdump找出网络帧的类型和来源,确定SYN FLOOD攻击导致
根据不同的性能指标来找合适的工具:
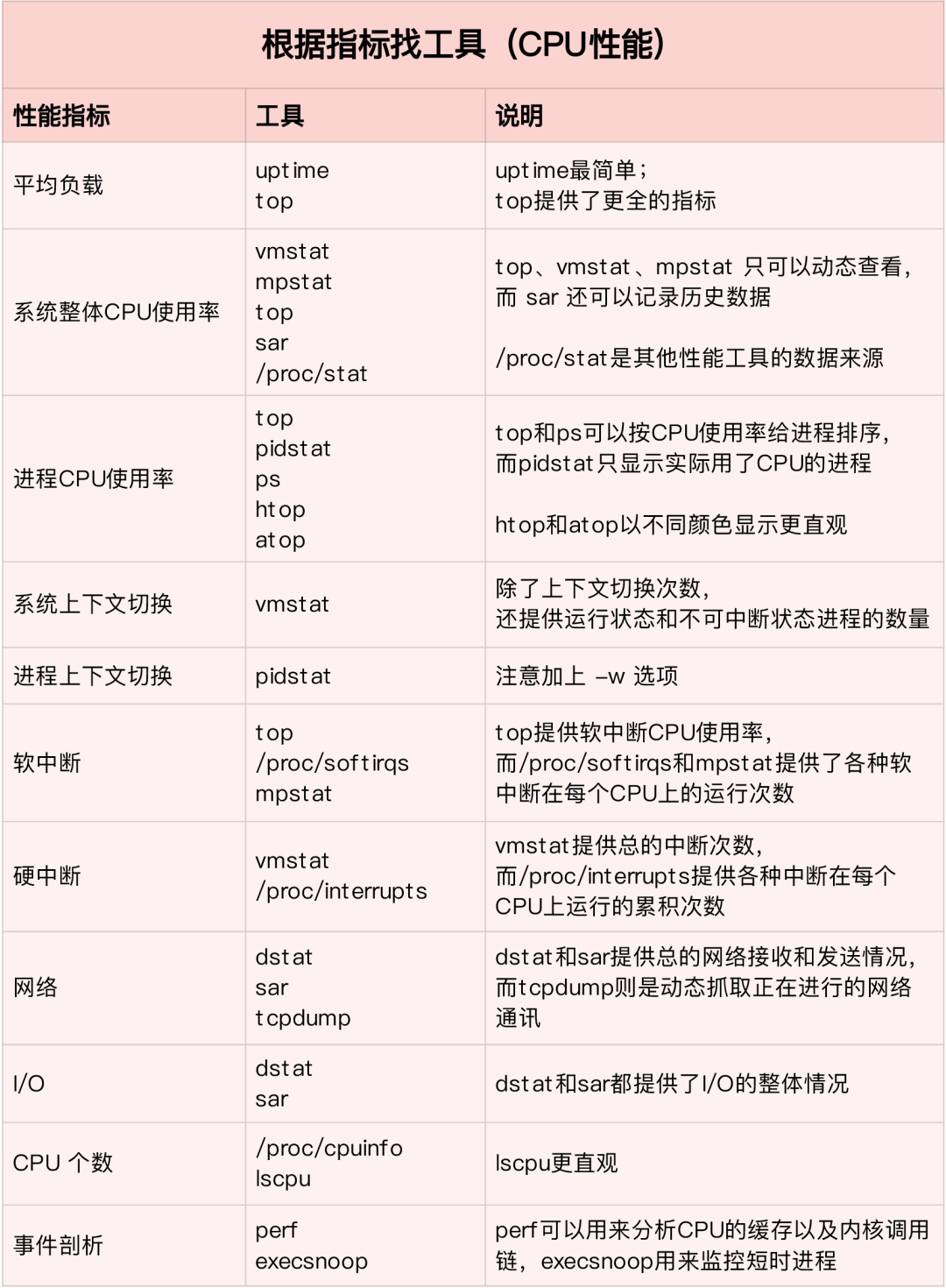
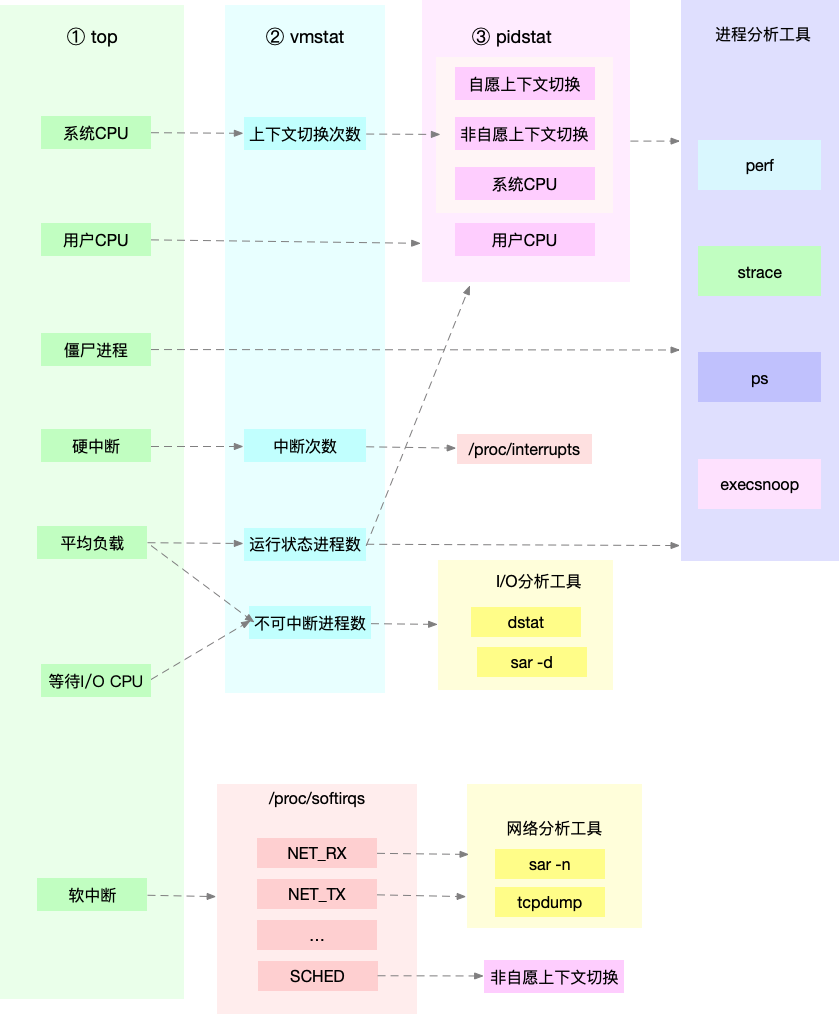
先运行几个支持指标较多的工具,如 top/vmstat/pidstat,根据它们的输出可以得出是哪种类型的性能问题。定位到进程后再用 strace/perf 分析调用情况进一步分析。如果是软中断导致用 /proc/softirqs
CPU优化
- 应用程序优化
- 编译器优化:编译阶段开启优化选项,如gcc -O2
- 算法优化
- 异步处理:避免程序因为等待某个资源而一直阻塞,提升程序的并发处理能力。(将轮询替换为事件通知)
- 多线程代替多进程:减少上下文切换成本
- 善用缓存:加快程序处理速度
- 系统优化
- CPU绑定:将进程绑定要1个/多个CPU上,提高CPU缓存命中率,减少CPU调度带来的上下文切换
- CPU独占:CPU亲和性机制来分配进程
- 优先级调整:使用nice适当降低非核心应用的优先级
- 为进程设置资源显示: cgroups设置使用上限,防止由某个应用自身问题耗尽系统资源
- NUMA优化: CPU尽可能访问本地内存
- 中断负载均衡: irpbalance,将中断处理过程自动负载均衡到各个CPU上
- TPS、QPS、系统吞吐量的区别和理解
-
QPS(TPS)
-
并发数
-
响应时间
-
QPS(TPS)=并发数/平均相应时间
-
用户请求服务器
-
服务器内部处理
-
服务器返回给客户
QPS 类似 TPS,但是对于一个页面的访问形成一个 TPS,但是一次页面请求可能包含多次对服务器的请求,可能计入多次 QPS
-
QPS(Queries Per Second)每秒查询率,一台服务器每秒能够响应的查询次数.
-
TPS(Transactions Per Second)每秒事务数,软件测试的结果.
-
- 系统吞吐量,包括几个重要参数:
-
Linux
+关注
关注
88文章
11869浏览量
219939 -
性能
+关注
关注
0文章
276浏览量
19740 -
i/o
+关注
关注
0文章
40浏览量
4886
发布评论请先 登录
HBase性能优化方法总结
Linux系统的性能优化策略
基于Linux的Socket网络编程的性能优化



Linux CPU的性能应该如何优化
Linux的基础学习笔记资料总结

Linux 性能优化总结!2
Linux内核slab性能优化的核心思想



评论