 AI芯片发展历史及最新趋势
AI芯片发展历史及最新趋势

想要玩边缘智慧(Edge Artificial Intelligence, Edge AI)前我们首先要先认识什么是类神经网络(Neural Network, NN)、深度学习(Deep Learning, DL)及为什么需要使用AI芯片,而AI芯片又有那些常见分类及未来可能发展方向。接下来就逐一为大家介绍不同类型的AI芯片用途及优缺点。
1. 什么是神经网络?
人工智能自1950年发展至今已经过多次起伏,从最简单的「符号逻辑」开始,历经「专家系统」、「机器学习」、「数据采矿」等多个时期。直到2012年Alex Krizhevsky和其导师Geoffrey Hinton推出基于类神经网络扩展出来的「卷积神经网络」(Convolutional Neural Network, CNN) 「AlexNet」,以超出第二名10%正确率的优异成绩赢得ImageNet大赛后,「深度学习」(DeepLearning, DL) 架构正式开启新一波的AI浪朝。
此后持续衍生出各种不同的网络架构,如能处理像声音、文章、感测信号这类和时间相关的「循环神经网络」(Recurrent Neural Network, RNN) ,或者能自动生成影像、风格转移(StyleTransfer)的「生成对抗网络」(Generative Adversarial Network, GAN) 等一系列网络架构。
这些网络(或称模型)都有一个特色,就是有大量的神经元(Neural)、神经连结权重(Weights)、层数(Layers)及复杂的网络结构(Network Architecture)。而其中最主要的运算方式就是矩阵(Matrix)计算,若再拆解成更小元素,即为 y = a * x + b ,又可称为「乘积累加运算」(Multiply–accumulate, MAC) 。
一个小型模型少则数千个神经元、数万个权重值,多则可能数十万个神经元、数十亿个权重值。以常见手写数字(0-9)辨识小型CNN模型LeNet5为例(如Fig.1所示),它约有6万多个权重,当模型推论(Inference)一次得到答案时,约需经过42万多次MAC运算。而像大型的VGG16模型则有1.38亿个权重,推论一次则约有150多亿次MAC计算。
一般来说模型的初始权重值通常都不太理想,所以根据推论后得到的答案,必须再反向修正所有权重值,使其更接近正确答案。但通常一次是很难到位的,所以要反复修正直到难以再调整出更接近正确答案为止,而这个过程就称为「模型训练」(Model Training) 。
通常这样修正的次数会随着数据集(Dataset)的大小、权重的数量及网络结构的复杂度,可能少则要几千次,多则要几万次、甚至更多次数才能收敛到满意的结果。由此得知训练模型所需的计算量有多么巨量了。
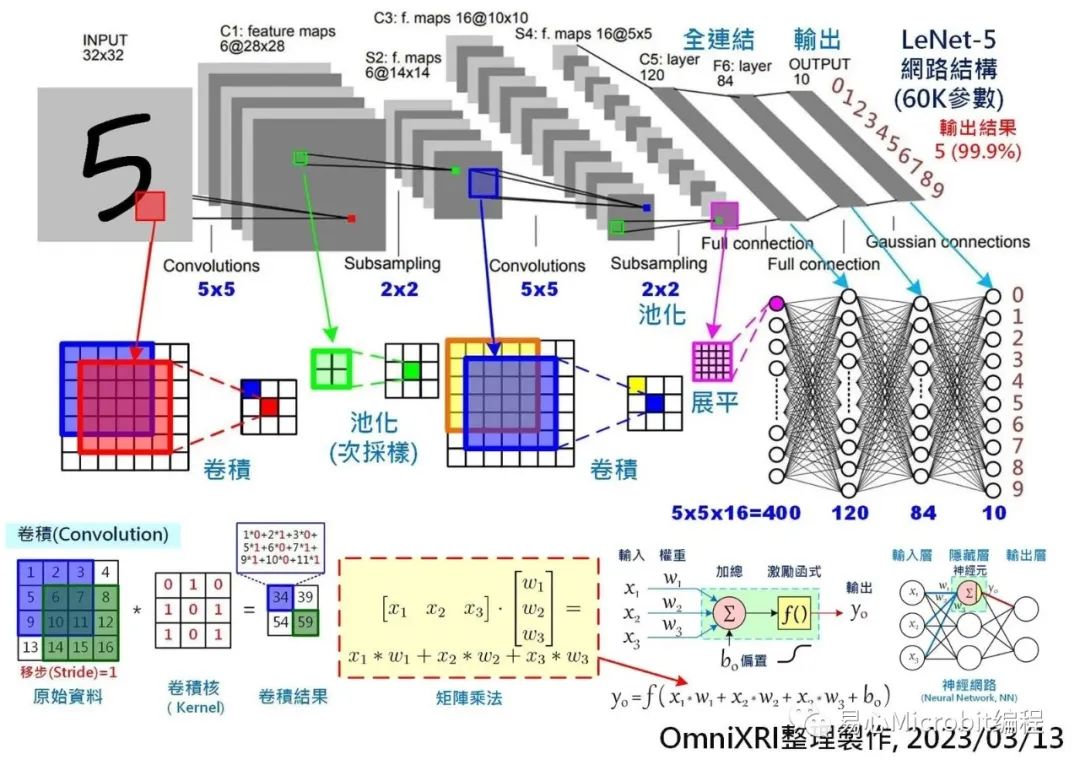
Fig. 1 手写数字辨识LeNet-5卷积神经网络模型及卷积、矩阵乘法示意图。
2. AI芯片类型
为了解决如此庞大且性质单一的计算量,于是就有了硬件加速计算的需求,通常会将此类硬件称呼为「AI芯片」(AI Chip) 或者「深度学习加速器」(Deep Learning Accelerator, DLA) 或者称为 「神经网络处理单元」(NeuralNetwork Processing Unit, NPU) 。
在AI芯片领域中主要分为训练用及推论用。前者重点在效能,所以功耗及成本就不太计较。而后者会依不同应用场合会有高效能、高推论精度、低功耗、低内存空间、低成本等不同需求。尤其在Edge AI上更强调低功耗、低记体体空间及低成本需求,而效能表现通常就只能迁就不同硬件表现。
近几年手机成长迅速,有很多芯片为了整体表现,因此整合了很多功能在同一颗芯片上称为SoC (System on Chip),包含CPU, DSP, GPU, NPU及像影音编译码的功能等。而FPGA的开发板也有反过来不过全部都自己设计,而把常用的CPU, DSP, AISC等整合进来,让使用者能更专心开发自己所需的特殊功能,包含AI等应用。
2.1 中央处理单元(CPU)
不论是像Arduino、小型IoT装置使用的单芯片(Micro-controller / Micro Controll Unit, MCU),如STM,Microchip, ESP32, Pi Pico, Arm Cortex-M, RISC-V等,或者是像树莓派、手机使用的微处理器(MicroProcessing Unit, MPU),如Arm Cortex-A系列、Qualcomm Snapdragon系列等,甚至是桌机、笔电常用的主芯片,如Intel, AMD x86系列等,都会有负责运算的中央处理单元(Central Processing Unit, CPU)。
CPU可运行各种形式的AI模型,不限矩阵运算类型,弹性极高,但一次只能执行一道运算指令,如一个乘法或一个加法或一个乘加指令,效能极低。若搭配单指令流多数据流(Single Instruction Multiple Data, SIMD)指令集,如INTEL的AVX、ARM的NEON、RISC-V的P扩充指令集,则可将32/64/128/256/512bit拆分成8/16/32 bit的运算,如此便能提高4~64倍的运算效能。另外亦可透过提高工作频率频率(MHz)或增加核心数来增加指令周期。
在MCU / MPU尚未有MAC及SIMD指令集前,当遇到需要对数字声音或影像进行时间域转频率域计算如快速傅立叶变换(Fast Fourier Transform, FFT),常会遇到大量定点数或浮点数的的矩阵计算,此时就需要专用数字信号处理器(Digital Signal Processor, DSP)来加速计算。
此类处理器在AI专用芯片未出现前,亦有很多被拿来当成浮点数矩阵加速计算使用,如Qualcomm Hexagon, Tensilica Xtensa, Arc EM9D等系列。它在开发上弹性颇高,价格居中,但仅适用于矩阵计算类的应用,在MCU / MPU开始加入MAC、SIMD指令集及GPU技术大量普及后,逐渐被取代,目前大多只有少数独立存在,大多依附于中大型微处理器中,或者整合至小型MCU芯片中代替NPU的工作。
2.3 图形处理器(GPU)
图形处理器(Graphics Processing Unit, GPU)是用于处理计算机上数字绘图用的专用芯片,而其中最主要的功能就是在处理矩阵运算,因此它能将CPU一次只能处理一个MAC的计算变成一次处理数百到数万个MAC来加速运算,同时可以分散CPU的计算负荷。早期有些科学家发现其特性,因此开发出GPGPU (General Purpose computing on Graphics Processing Units)函式库来加速科学运算。
2012年AlexNet透过GPU来加速训练深度学习模型,从此开启GPU即为AI芯片代名词的时代。目前主流GPU供货商包括Nvidia (GeForce, Quadro, Tesla, Tegra系列) , Intel (内显HD, Iris及外显Arc系列), Arm(Mali系列)等。
由于GPU原本是用于计算机绘图,有大量电路、处理时间、耗能是用来处理绘图程序,因此后续许多AI芯片的设计理念就是保留计算部份而去除绘图处理部份,来提升芯片面积的有效率。目前使用GPU开发的弹性尚佳,但不适用于非大量矩阵计算的模型及算法。
另外为了容纳更高的计算平行度,一次能处理更多的乘加运算,因此芯片的制程也随之越来越小(从数百nm到数nm)、晶体数量和芯片单价也越来越高,较适合大模型训练及高速推论用。
2.4 现场可程序化逻辑门阵列(FPGA)
一般开发如影像分类、声音辨识、对象侦测、影像分割等AI专用型应用甚至是MCU / MPU等通用型应用芯片前,为确保投入像台积电等晶圆代工厂生产前没有电路及计算功能的问题,通常除了会使用软件进行仿真分析外,亦会使用FPGA (Field Programmable Gate Array)来进行硬件验证。常见的供货商有Xilinx(已被AMD收购)、Altera(已被Intel收购)、Lattice等。
FPGA除了可以验证IC的功能外,另外由于其超高弹性,所以可以排列组合出超过CPU / DSP / GPU 功能的应用,且可以用最精简的电路来设计,以达到最低功耗、最高执行效能。但此类型的开发非常困难,需要非常专业的工程师才有办法设计,且需配合相当多的硅智财(Semiconductor intellectual property core,简称IP),因此大型FPGA的单价及开发成本是非常高的。
当使用FPGA验证后,就可以将特殊应用集成电路(Application Specific Integrated Circuit, ASIC)送到晶圆厂及封装厂加工了。完成后的芯片就可独立运作,优点是可大量生产让单价大幅降低,能满足市场需求,同时拥有极高的执行效能和最低的功耗。但缺点是没有任何修改弹性,万一设计功能有瑕疵时就有可能需要全部报废。因此当没有明确市场及需求量时,通常会使用如CPU或GPU或CPU+NPU等通用型解决方案来取代。
2.6 神经网络处理器(NPU, DLA)
「神经网络处理单元」 (Neural Network Processing Unit, NPU) 或称「深度学习加速器」(Deep Learning Accelerator, DLA) 是专门用于处理深度学习神经网络运算的特殊应用集成电路(ASIC)。它较接近GPU的用法,所以可以一次处理很多的乘加运算(MAC)。但因为只负责乘加计算,无法处理大量数据搬移及逻辑性计算,所以通常必须搭配CPU使用。
大多数的AI芯片都是属于这一类型,使用上较有弹性,可适合各式新模型的变化。不过由于NPU的软硬接口规格无法统一,因此在开发上能支持的AI框架(如TensorFlow, TensorFolw Lite, TensoFlow Lite for Micro, PyTorch等)或IDE(如JupyterNotebook, Arduino, OpenMV, 各厂商MCU专属IDE等)就有很大不同,选用前需考虑自身工程能力。
另外根据不同应用,小型NPU主要用于推论,可以放到MCU / MPU 或手机中,如Intel (Movidius) Myriad, Arm Ethos U55, Google Coral等,大型NPU则可以放到桌机、云端服务器中,如Nvidia GTX / Tesla / A100, Google TPU等。
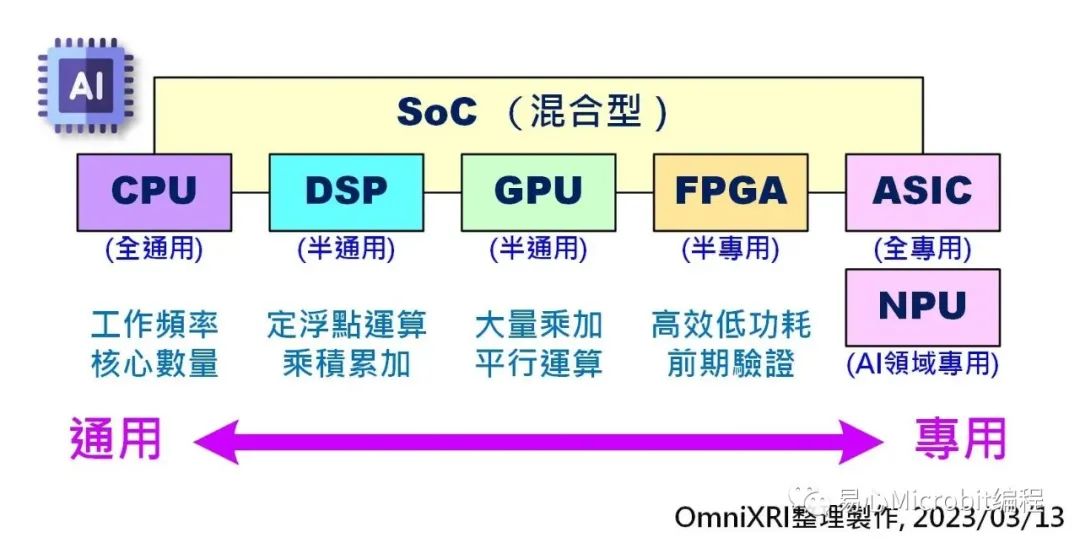
Fig. 2 不同类型AI芯片主要差异。
3. AI芯片最新趋势
目前AI应用越来越强大,模型权重数量已从数万个(如LeNet-5)激增到近一千多亿个(如GPT3),传统NPU、TPU及FPGA的速度已不够快,功耗也大的惊人,因此近来开始有厂商在开发新的解决方案,企图以更接近人脑运行方式或者减少在计算时权重大量搬移问题,甚至使用光子进行计算来进行改善。以下就简单介绍几种常见方案,如Fig. 3所示。
(1) 可重构型(Coarse GrainReconfigurable Architecture, CGRA):
可依不同需求以软件重构位宽度、MAC算子结构、矩阵计算结构、混合精度计算等。主要代表厂商如下:
•耐能(Kneron)
•Wave Computing
•清微智能
•云天励飞
•燧原科技
(2) 类脑芯片(Neuromophic神经型态):
主要模拟人类大脑神经脉冲计算方式。有以下几种方式及代表厂商:
•数位式:IBM TrueNorth, Intel Loihi, SpiNNaker
•模拟式:Neurogrid, BrainScales, ROLLS
•新材料式:Memristor
(3) 内存内记算(Compute inMemory, CIM)(也称为存算一体、存内计算):
主要将内存和计算单元整合在一起,减少计算时海量存储器搬移浪费的时间。主要括下列几种技术:
•静态(晶体管式)随机存取内存SRAM (挥发性内存)
•磁阻式随机存取内存MRAM (非挥发性内存)
•可变电阻式随机存取内存RRAM (非挥发性内存)
(4) 光子芯片:
主要以光子代替电子,以提升指令周期。代表厂商包括:
•Lightmatter
•曦智(Lightelligence)
小结
历经近十多年的发展,AI加速芯片不论是在云端服务器所需要的大型模型训练或是模型高速推论,或者边缘装置所需小而美、高性价比的推论单元,都已有长足的进步。相信随着半导体技术的提升,未来Edge AI能运行的模型大小、复杂度及所需的功耗都能有更棒的表现,能适用的AI应用也会更加宽广。
审核编辑:汤梓红
-
处理器
+关注
关注
68文章
20148浏览量
246942 -
神经网络
+关注
关注
42文章
4827浏览量
106768 -
人工智能
+关注
关注
1813文章
49734浏览量
261395 -
机器学习
+关注
关注
66文章
8541浏览量
136216 -
AI芯片
+关注
关注
17文章
2062浏览量
36558
原文标题:AI芯片发展历史及最新趋势
文章出处:【微信号:易心Microbit编程,微信公众号:易心Microbit编程】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录






 工商网监
工商网监
评论