 Go汇编基础知识
Go汇编基础知识

前言
我们知道 Go 语言的三位领导者中有两位来自 Plan 9 项目,这直接导致了 Go 语言的汇编采用了比较有个性的 Plan 9 风格。不过,我们不能因咽废食而放弃无所不能的汇编。
1、 Go 汇编基础知识
1.1、通用寄存器
不同体系结构的 CPU,其内部寄存器的数量、种类以及名称可能大不相同,这里我们只介绍 AMD64 的寄存器。AMD64 有 20 多个可以直接在汇编代码中使用的寄存器,其中有几个寄存器在操作系统代码中才会见到,而应用层代码一般只会用到如下三类寄存器。
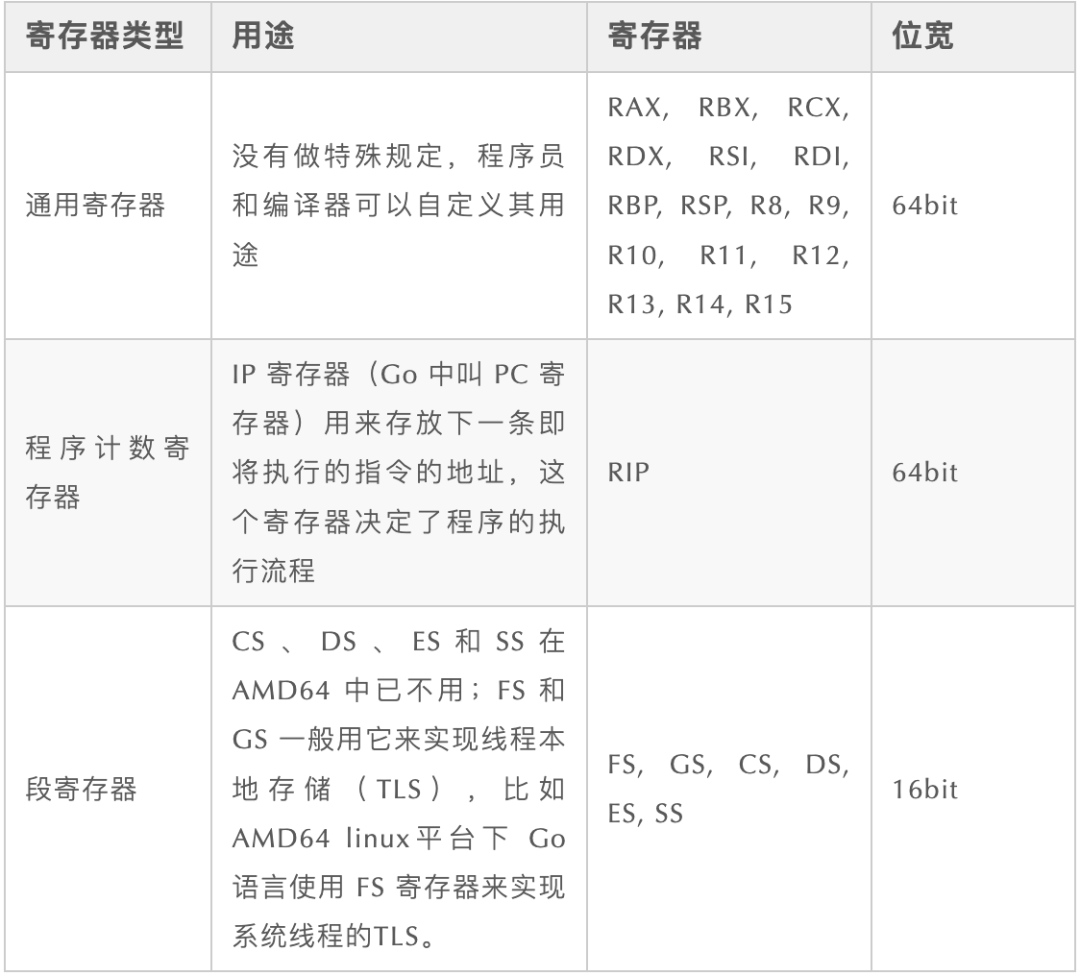
AMD64 的通用通用寄存器的名字在 plan9 中的对应关系:
| AMD64 | RAX | RBX | RCX | RDX | RDI | RSI | RBP | RSP | R8 | R9 | R10 | R11 | R12 | R13 | R14 | RIP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Plan9 | AX | BX | CX | DX | DI | SI | BP | SP | R8 | R9 | R10 | R11 | R12 | R13 | R14 | PC |
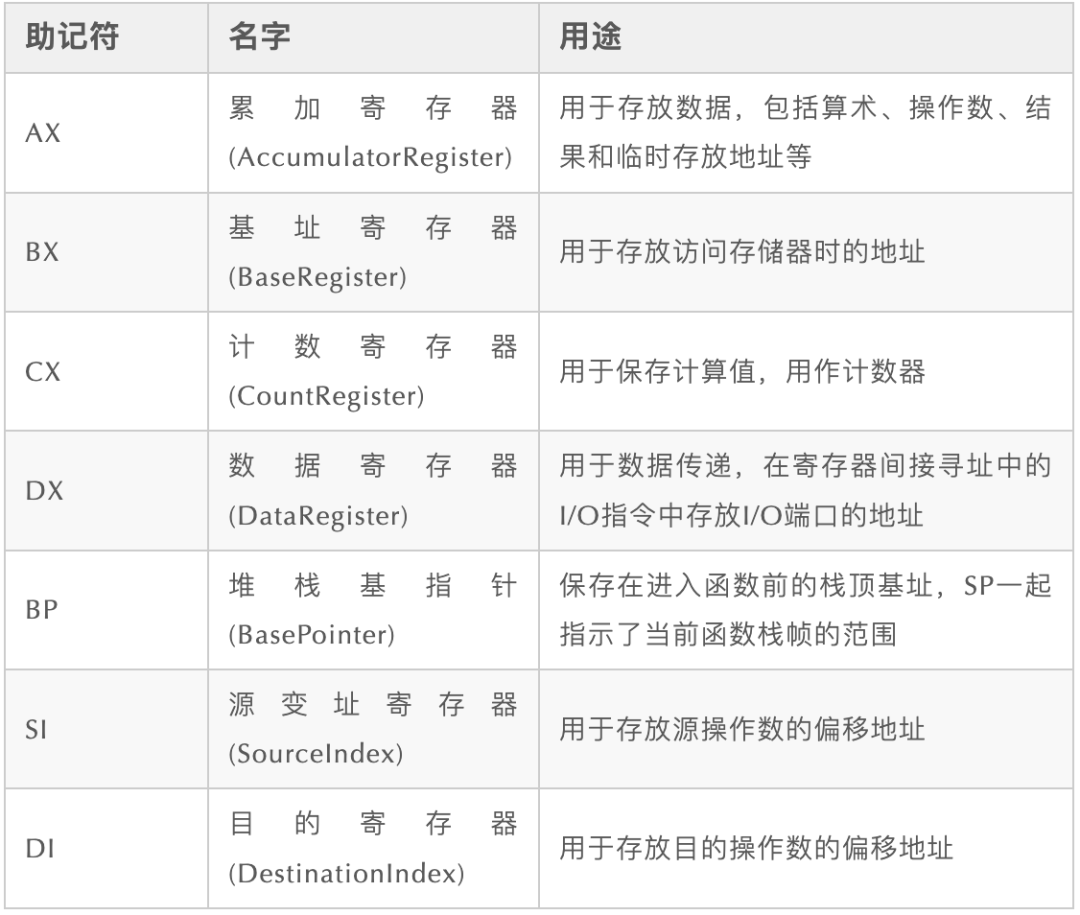
Go 语言中寄存器一般用途:
1.2、伪寄存器
伪寄存器是 plan9 伪汇编中的一个助记符, 也是 Plan9 比较有个性的语法之一。常见伪寄存器如下表所示:
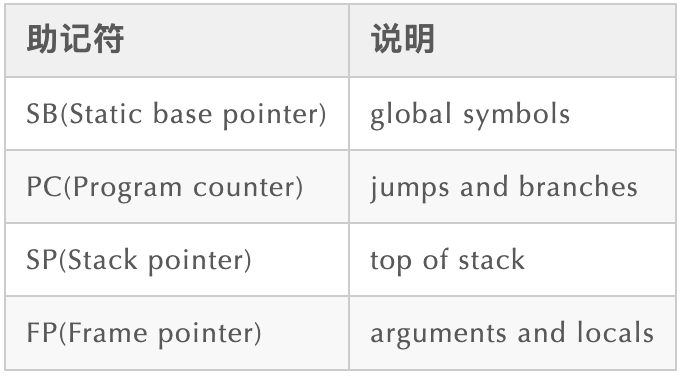
SB:指向全局符号表。相对于寄存器,SB 更像是一个声明标识,用于标识全局变量、函数等。通过 symbol(SB) 方式使用,symbol<>(SB)表示 symbol 只在当前文件可见,跟 C 中的 static 效果类似。此外可以在引用上加偏移量,如 symbol+4(SB) 表示 symbol+4bytes 的地址。
PC:程序计数器(Program Counter),指向下一条要执行的指令的地址,在 AMD64 对应 rip 寄存器。个人觉得,把他归为伪寄存器有点令人费解,可能是因为每个平台对应的物理寄存器名字不一样。
SP:SP 寄存器比较特殊,既可以当做物理寄存器也可以当做伪寄存器使用,不过这两种用法的使用语法不同。其中,伪寄存器使用语法是 symbol+offset(SP),此场景下 SP 指向局部变量的起始位置(高地址处);x-8(SP) 表示函数的第一个本地变量;物理 SP(硬件SP) 的使用语法则是 +offset(SP),此场景下 SP 指向真实栈顶地址(栈帧最低地址处)。
FP:用于标识函数参数、返回值。被调用者(callee)的 FP 实际上是调用者(caller)的栈顶,即 callee.SP(物理SP) == caller.FP;x+0(FP) 表示第一个请求参数(参数返回值从右到左入栈)。
实际上,生成真正可执行代码时,伪 SP、FP 会由物理 SP 寄存器加上偏移量替换。所以执行过程中修改物理 SP,会引起伪 SP、FP 同步变化,比如执行 SUBQ $16, SP 指令后,伪 SP 和伪 FP 都会 -16。而且,反汇编二进制而生成的汇编代码中,只有物理 SP 寄存器。即 go tool objdump/go tool compile -S 输出的汇编代码中,没有伪 SP 和 伪 FP 寄存器,只有物理 SP 寄存器。
另外还有 1 个比较特殊的伪寄存器:TLS:存储当前 goroutine 的 g 结构体的指针。实际上,X86 和 AMD64 下的 TLS 是通过段寄存器 FS 或 GS 实现的线程本地存储基地址,而当前 g 的指针是线程本地存储的第一个变量。
比如 github.com/petermattis/goid.Get 函数的汇编实现如下:
//funcGet()int64
TEXT·Get(SB),NOSPLIT,$0-8
MOVQ(TLS),R14
MOVQg_goid(R14),R13
MOVQR13,ret+0(FP)
RET
编译成二进制之后,再通过 go tool objdump 反编译成汇编(Go 1.18),得到如下代码:
TEXTgithub.com/petermattis/goid.Get.abi0(SB)/Users/bytedance/go/pkg/mod/github.com/petermattis/goid@v0.0.0-20221215004737-a150e88a970d/goid_go1.5_amd64.s
goid_go1.5_amd64.s:280x108adc0654c8b342530000000MOVQGS:0x30,R14
goid_go1.5_amd64.s:290x108adc94d8bae98000000MOVQ0x98(R14),R13
goid_go1.5_amd64.s:300x108add04c896c2408MOVQR13,0x8(SP)
goid_go1.5_amd64.s:310x108add5c3RET
可以知道 MOVQ (TLS), R14 指令最终编译成了 MOVQ GS:0x30, R14 ,使用了 GS 段寄存器实现相关功能。
操作系统对内存的一般划分如下图所示:
高地址+------------------+
||
|内核空间|
||
--------------------
||
|栈|
||
--------------------
||
|.......|
||
--------------------
||
|堆|
||
--------------------
|全局数据|
|------------------|
||
|静态代码|
||
|------------------|
|系统保留|
低地址|------------------|
这里提个疑问,我们知道协程分为有栈协程和无栈协程,go 语言是有栈协程。那你知道普通 gorutine 的调用栈是在哪个内存区吗?
1.3、函数调用栈帧
我们先熟悉几个名词。
caller:函数调用者。callee:函数被调用者。比如函数 main 中调用 sum 函数,那么 main 就是 caller,而 sum 函数就是 callee。栈帧:stack frame,即执行中的函数所持有的、独立连续的栈区段。一般用来保存函数参数、返回值、局部变量、返回 PC 值等信息。golang 的 ABI 规定,由 caller 管理函数参数和返回值。
下图是 golang 的调用栈,源于曹春晖老师的 github 文章《汇编 is so easy》 ,做了简单修改:
caller
+------------------+
||
+---------------------->+------------------+
|||
||callerparentBP|
|BP(pseudoSP)+------------------+
|||
||LocalVar0|
|+------------------+
|||
||.......|
|+------------------+
|||
||LocalVarN|
+------------------+
callerstackframe||
|calleearg2|
|+------------------+
|||
||calleearg1|
|+------------------+
|||
||calleearg0|
|SP(RealRegister)->+------------------+--------------------------+FP(virtualregister)
||||
||returnaddr|parentreturnaddress|
+---------------------->+------------------+--------------------------+<-----------------------+
| caller BP | |
| (caller frame pointer) | |
BP(pseudo SP) +--------------------------+ |
| | |
| Local Var0 | |
+--------------------------+ |
| |
| Local Var1 |
+--------------------------+ callee stack frame
| |
| ..... |
+--------------------------+ |
| | |
| Local VarN | |
High SP(Real Register) +--------------------------+ |
^ | | |
| | | |
| | | |
| | | |
| | | |
| +--------------------------+ <-----------------------+
Low
callee
需要指出的是,上图中的 CALLER BP 是在编译期由编译器在符合条件时自动插入。所以手写汇编时,计算 framesize 时不应包括 CALLER BP 的空间。是否插入 CALLER BP 的主要判断依据如下:
//Mustagreewithinternal/buildcfg.FramePointerEnabled.
constframepointer_enabled=GOARCH=="amd64"||GOARCH=="arm64"
以下是 Go 语言函数栈展开逻辑的一段代码,它侧面验证了 BP 插入的条件:
- 函数的栈帧大小大于 0;
- 常量 framepointer_enabled 值为 true。
//Forarchitectureswithframepointers,ifthere's
//aframe,thenthere'sasavedframepointerhere.
//
//NOTE:Thiscodeisnotasgeneralasitlooks.
//Onx86,theABIistosavetheframepointerwordatthe
//topofthestackframe,sowehavetobackdownoverit.
//Onarm64,theframepointershouldbeatthebottomof
//thestack(withR29(akaFP)=RSP),inwhichcasewewould
//notwanttodothesubtractionhere.Butwestartedoutwithout
//anyframepointer,andwhenwewantedtoaddit,wedidn't
//wanttobreakalltheassemblydoingdirectwritesto8(RSP)
//tosetthefirstparametertoacalledfunction.
//SowedecidedtowritetheFPlink*below*thestackpointer
//(withR29=RSP-8inGofunctions).
//ThisistechnicallyABI-compatiblebutnotstandard.
//Andithappenstoendupmimickingthex86layout.
//Otherarchitecturesmaymakedifferentdecisions.
ifframe.varp>frame.sp&&framepointer_enabled{
frame.varp-=goarch.PtrSize
}
//Mustagreewithinternal/buildcfg.FramePointerEnabled.
constframepointer_enabled=GOARCH=="amd64"||GOARCH=="arm64"
1.4、golang常用汇编指令
参考文档:
Go支持的 X86 指令
https://github.com/golang/arch/blob/v0.2.0/x86/x86.csv
Go支持的 ARM64 指令
https://github.com/golang/arch/blob/v0.2.0/arm64/arm64asm/inst.json
Go支持的 ARM 指令
https://github.com/golang/arch/blob/v0.2.0/arm/arm.csv
常用指令:
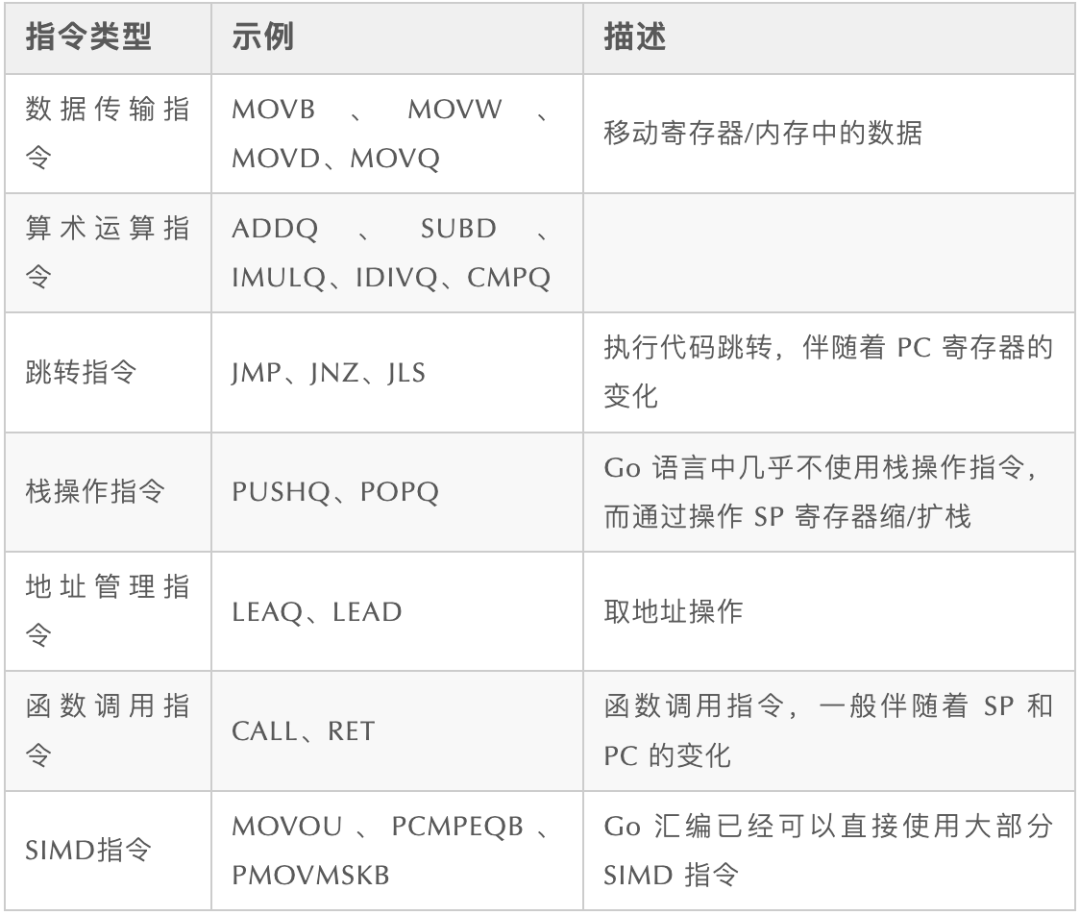
例如
MOVB$1, DI // 1 byte;将 DI 的第一个 Byte 的值设置为 1
MOVW$0x10,BX//2bytes
MOVD$1,DX//4bytes
MOVQ$-10,AX//8bytes
SUBQ$0x18,SP//对SP做减法,扩栈
ADDQ$0x18,SP//对SP做加法,缩栈
ADDQAX,BX//BX+=AX
SUBQAX,BX//BX-=AX
IMULQAX,BX//BX*=AX
JMPaddr//跳转到地址,地址可为代码中的地址,不过实际上手写一般不会出现
JMPlabel//跳转到标签,可以跳转到同一函数内的标签位置
JMP2(PC)//向前转2行
JMP-2(PC)//向后跳转2行
JNZtarget//如果zeroflag被set过,则跳转
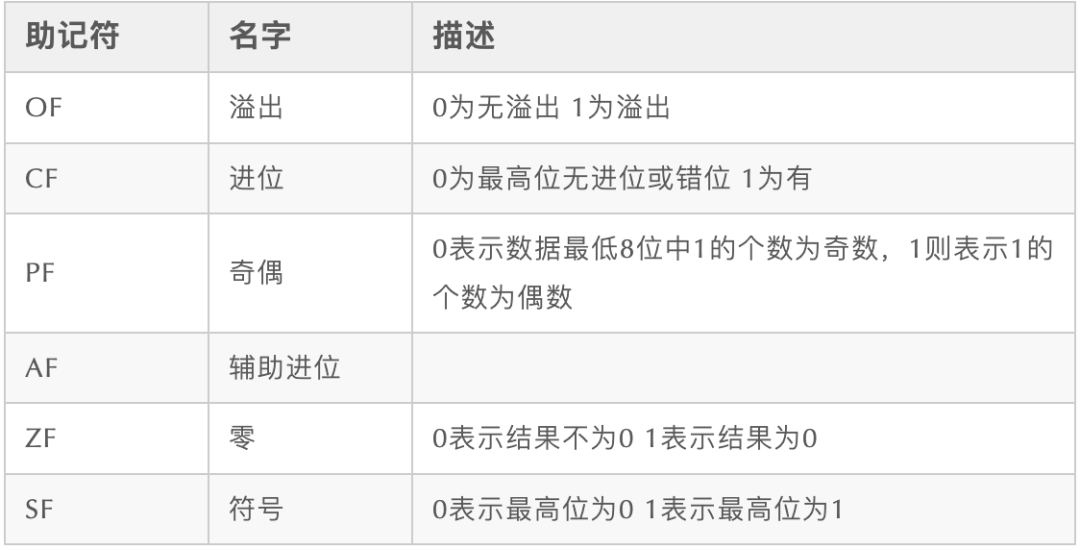
常用标志位:
1.5 全局变量
参考文档:《Go语言高级编程》的章节 3.3 常量和全局变量
https://github.com/chai2010/advanced-go-programming-book/blob/master/ch3-asm/ch3-03-const-and-var.md
1.5.1 使用语法
使用 GLOBL 关键字声明全局变量,用 DATA 定义指定内存的值:
//DATA汇编指令指定对应内存中的值;width必须是1、2、4、8几个宽度之一
DATAsymbol+offset(SB)/width,value//symbol+offset偏移量,width宽度,value初始值
//GLOBL指令声明一个变量对应的符号,以及变量对应的内存大小
GLOBLsymbol(SB),flag,width//名为symbol,内存宽度为width,flag可省略
例子:
DATAage+0x00(SB)/4,$18//age=18
GLOBLage(SB),RODATA,$4//声明全局变量age,占用4Byte内存空间
DATApi+0(SB)/8,$3.1415926
GLOBLpi(SB),RODATA,$8
DATAbio<>+0(SB)/8,$"hellowo"//<>表示只在当前文件生效
DATAbio<>+8(SB)/8,$"old!!!!"//bio="helloworld!!!!"
GLOBLbio<>(SB),RODATA,$16
其中 flag 的字面量定义在 Go 标准库下 src/runtime/textflag.h 文件中,需要在汇编文件中 #include "textflag.h",其类型有有如下几个:
| flag | value | 说明 |
|---|---|---|
| NOPROF | 1 | (TEXT项使用) 不优化NOPROF标记的函数。这个标志已废弃。(For TEXT items.) Don't profile the marked function. This flag is deprecated. |
| DUPOK | 2 | 在二进制文件中允许一个符号的多个实例。链接器会选择其中之一。It is legal to have multiple instances of this symbol in a single binary. The linker will choose one of the duplicates to use. |
| NOSPLIT | 4 | (TEXT项使用) 不插入检测栈分裂(扩张)的前导指令代码(减少开销,一般用于叶子节点函数(函数内部不调用其他函数))。程序的栈帧中,如果调用其他函数会增加栈帧的大小,必须在栈顶留出可用空间。用来保护程序,例如堆栈拆分代码本身。(For TEXT items.) Don't insert the preamble to check if the stack must be split. The frame for the routine, plus anything it calls, must fit in the spare space at the top of the stack segment. Used to protect routines such as the stack splitting code itself. |
| RODATA | 8 | (DATA和GLOBAL项使用) 将这个数据放在只读的块中。(For DATA and GLOBL items.) Put this data in a read-only section. |
| NOPTR | 16 | (用于DATA和GLOBL项目)这个数据不包含指针所以就不需要垃圾收集器来扫描。(For DATA and GLOBL items.) This data contains no pointers and therefore does not need to be scanned by the garbage collector. |
| WRAPPER | 32 | (TEXT项使用)这是包装函数 (For TEXT items.) This is a wrapper function and should not count as disabling recover. |
| NEEDCTXT | 64 | (TEXT项使用)此函数是一个闭包,因此它将使用其传入的上下文寄存器。(For TEXT items.) This function is a closure so it uses its incoming context register. |
| TLSBSS | 256 | (用于DATA和GLOBL项目)将此数据放入线程本地存储中。Allocate a word of thread local storage and store the offset from the thread local base to the thread local storage in this variable. |
| NOFRAME | 512 | (TEXT项使用)不要插入指令为此函数分配栈帧。仅在声明帧大小为0的函数上有效。(函数必须是叶子节点函数,且以0标记堆栈函数,没有保存帧指针(或link寄存器架构上的返回地址))TODO(mwhudson):目前仅针对 ppc64x 实现。Do not insert instructions to allocate a stack frame for this function. Only valid on functions that declare a frame size of 0. TODO(mwhudson): only implemented for ppc64x at present. |
| REFLECTMETHOD | 1024 | 函数可以调用 reflect.Type.Method 或 reflect.Type.MethodByName。Function can call reflect.Type.Method or reflect.Type.MethodByName. |
| TOPFRAME | 2048 | (TEXT项使用)函数是调用堆栈的顶部。栈回溯应在此功能处停止。Function is the outermost frame of the call stack. Call stack unwinders should stop at this function. |
| ABIWRAPPER | 4096 | 函数是一个 ABI 包装器。Function is an ABI wrapper. |
其中 NOSPLIT 需要特别注意,它表示该函数运行不会导致栈分裂,用户也可以使用 //go:nosplit 强制给 go 函数指定 NOSPLIT 属性。例如:
//go:nosplit
funcsomeFunc(){
}
汇编中直接给函数标记 NOSPLIT 即可:
//表示someFunc函数执行时最多需要24字节本地变量和8字节参数空间
TEXT·someFunc(SB),NOSPLIT,$24-8
RET
链接器认为标记为 NOSPLIT 的函数,最多需要使用 StackLimit 字节空间,所以不需要插入栈分裂(溢出)检查,函数调用损耗更小。不过,使用该标志的时候要特别小心,万一发生意外容易导致栈溢出错误,溢出时会在执行期报 nosplit stack overflow 错。Go 1.18 标准库下 go/src/runtime/HACKING.md 中有如下说明:
nosplitfunctions
MostfunctionsstartwithaprologuethatinspectsthestackpointerandthecurrentG'sstackboundandcallsmorestackifthestackneedstogrow.
Functionscanbemarked//go:nosplit(orNOSPLITinassembly)toindicatethattheyshouldnotgetthisprologue.Thishasseveraluses:
-Functionsthatmustrunontheuserstack,butmustnotcallintostackgrowth,forexamplebecausethiswouldcauseadeadlock,orbecausetheyhaveuntypedwordsonthestack.
-Functionsthatmustnotbepreemptedonentry.
-FunctionsthatmayrunwithoutavalidG.Forexample,functionsthatruninearlyruntimestart-up,orthatmaybeenteredfromCcodesuchascgocallbacksorthesignalhandler.
Splittablefunctionsensurethere'ssomeamountofspaceonthestackfornosplitfunctionstoruninandthelinkerchecksthatanystaticchainofnosplitfunctioncallscannotexceedthisbound.
Anyfunctionwitha//go:nosplitannotationshouldexplainwhyitisnosplitinitsdocumentationcomment.
另外,当函数处于调用链的叶子节点,且栈帧小于 StackSmall(128)字节时,则自动标记为 NOSPLIT。此逻辑的代码如下:
//constStackSmall=128
ifctxt.Arch.Family==sys.AMD64&&autoffset< objabi.StackSmall && !p.From.Sym.NoSplit() {
leaf := true
LeafSearch:
forq:=p;q!=nil;q=q.Link{
switchq.As{
caseobj.ACALL:
//Treatcommonruntimecallsthattakenoarguments
//thesameasduffcopyandduffzero.
if!isZeroArgRuntimeCall(q.To.Sym){
leaf=false
breakLeafSearch
}
fallthrough
caseobj.ADUFFCOPY,obj.ADUFFZERO:
ifautoffset>=objabi.StackSmall-8{
leaf=false
breakLeafSearch
}
}
}
ifleaf{
p.From.Sym.Set(obj.AttrNoSplit,true)
}
}
1.5.2 Go 语言中的常用用法
在汇编代码中使用 go 变量:
#include"textflag.h"
TEXT·get(SB),NOSPLIT,$0-8
MOVQ·a(SB),AX//把go代码定义的全局变量读到AX中
MOVQAX,ret+0(FP)//把AX的值写入返回值位置
RET
packagemain
vara=999
funcget()intfuncmain(){
println(get())
}
go 代码中使用汇编定义的变量:
// string 定义形式 1:在 String 结构体后多分配一个[n]byte 数组存放静态字符串
DATA·Name+0(SB)/8,$·Name+16(SB)//StringHeader.Data
DATA·Name+8(SB)/8,$6//StringHeader.Len
DATA·Name+16(SB)/8,$"gopher"//[6]byte{'g','o','p','h','e','r'}
GLOBL·Name(SB),NOPTR,$24//struct{Datauintptr,Lenint,str[6]byte}
// string 定义形式 2:独立分配一个仅当前文件可见的[n]byte 数组存放静态字符串
DATAstr<>+0(SB)/8,$"HelloWo"//str[0:8]={'H','e','l','l','o','','W','o'}
DATAstr<>+8(SB)/8,$"rld!"//str[9:12]={'r','l','d','!''}
GLOBLstr<>(SB),NOPTR,$16//定义全局数组varstr<>[16]byte
DATA·Helloworld+0(SB)/8,$str<>(SB)//StringHeader.Data=&str<>
DATA·Helloworld+8(SB)/8,$12//StringHeader.Len=12
GLOBL·Helloworld(SB),NOPTR,$16//struct{Datauintptr,Lenint}
varName,Helloworldstring
funcdoSth(){
fmt.Printf("Name:%s
",Name)//读取汇编中初始化的变量Name
fmt.Printf("Helloworld:%s
",Helloworld)//读取汇编中初始化的变量Helloworld
}
//输出:
//Name:gopher
//Helloworld:HelloWorld!
1.6 函数调用
1.6.1 使用语法
Go 语言汇编中,函数声明格式如下:
告诉汇编器该数据放到TEXT区
^静态基地址指针(告诉汇编器这是基于静态地址的数据)
|^
||标签函数入参+返回值占用空间大小
||^^
||||
TEXTpkgname·funcname(SB),TAG,$16-24
^^^^
||||
函数所属包名函数名表示ABI类型函数栈帧大小(本地变量占用空间大小)

一些说明:
- 栈帧大小包括局部变量和可能需要的额外调用函数的参数空间的总大小,但不不包含调用其他函数时的 ret address 的大小。
- 汇编文件中,函数名以 '·' 开头或连接 pkgname 是固定格式。
- go 函数采用的是 caller-save 模式,被调用者的参数、返回值、栈位置都由调用者维护。
go 语言编译成汇编:
gotoolcompile-Sxxx.go
gobuild-gcflags-Sxxx.go
从二进制反编译为汇编:
gotoolobjdump-s"main.main"main.out>main.S
1.6.2 使用例子
Go 函数调用汇编函数:
//add.go
packagemain
import"fmt"
funcadd(x,yint64)int64
funcmain(){
fmt.Println(add(2,3))
}
//add_amd64.s
//add(x,y)->x+y
TEXT·add(SB),NOSPLIT,$0
MOVQx+0(FP),BX
MOVQy+8(FP),BP
ADDQBP,BX
MOVQBX,ret+16(FP)
RET
汇编调用 go 语言函数:
packagemain
import"fmt"
funcadd(x,yint)int{
returnx+y
}
funcoutput(a,bint)int
funcmain(){
s:=output(10,13)
fmt.Println(s)
}
#include"textflag.h"
//funcoutput(a,bint)int
TEXT·output(SB),NOSPLIT,$24-24
MOVQa+0(FP),DX//arga
MOVQDX,0(SP)//argx
MOVQb+8(FP),CX//argb
MOVQCX,8(SP)//argy
CALL·add(SB)//在调用add之前,已经把参数都通过物理寄存器SP搬到了函数的栈顶
MOVQ16(SP),AX//add函数会把返回值放在这个位置
MOVQAX,ret+16(FP)//returnresult
RET
1.6.1 汇编函数中用到的一些特殊命令(伪指令)
GO_RESULTS_INITIALIZED:如果 Go 汇编函数返回值含指针,则该指针信息必须由 Go 源文件中的函数的 Go 原型提供,即使对于未直接从 Go 调用的汇编函数也是如此。如果返回值将在调用指令期间保存实时指针,则该函数中应首先将结果归零, 然后执行伪指令 GO_RESULTS_INITIALIZED。表明该堆栈位置应该执行进行 GC 扫描,避免其指向的内存地址呗 GC 意外回收。
NO_LOCAL_POINTERS: 就是字面意思,表示函数没有指针类型的局部变量。
PCDATA: Go 语言生成的汇编,利用此伪指令表明汇编所在的原始 Go 源码的位置(file&line&func),用于生成 PC 表格。runtime.FuncForPC 函数就是通过 PC 表格得到结果的。一般由编译器自动插入,手动维护并不现实。
FUNCDATA: 和 PCDATA 的格式类似,用于生成 FUNC 表格。FUNC 表格用于记录函数的参数、局部变量的指针信息,GC 依据它来跟踪栈中指针指向内存的生命周期,同时栈扩缩容的时候也是依据它来确认是否需要调整栈指针的值(如果指向的地址在需要扩缩容的栈中,则需要同步修改)。
1.7 条件编译
Go 语言仅支持有限的条件编译规则:
- 根据文件名编译。
- 根据 build 注释编译。
根据文件名编译类似 *_test.go,通过添加平台后缀区分,比如: asm_386.s、asm_amd64.s、asm_arm.s、asm_arm64.s、asm_mips64x.s、asm_linux_amd64.s、asm_bsd_arm.s 等.
根据 build 注释编译,就是在源码中加入区分平台和编译器版本的注释。比如:
//go:build(darwin||freebsd||netbsd||openbsd)&&gc
//+builddarwinfreebsdnetbsdopenbsd
//+buildgc
Go 1.17 之前,我们可以通过在源码文件头部放置 +build 构建约束指示符来实现构建约束,但这种形式十分易错,并且它并不支持&&和||这样的直观的逻辑操作符,而是用逗号、空格替代,下面是原 +build 形式构建约束指示符的用法及含义:
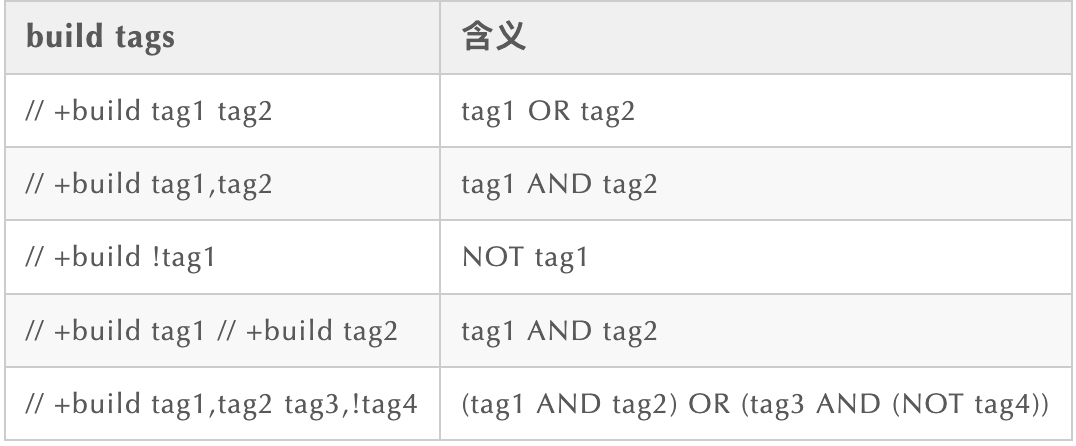
Go 1.17 引入了 //go:build 形式的构建约束指示符,支持&&和||逻辑操作符,如下代码所示:
//go:buildlinux&&(386||amd64||arm||arm64||mips64||mips64le||ppc64||ppc64le)
//go:buildlinux&&(mips64||mips64le)
//go:buildlinux&&(ppc64||ppc64le)
//go:buildlinux&&!386&&!arm
考虑到兼容性,Go 命令可以识别这两种形式的构建约束指示符,但推荐 Go 1.17 之后都用新引入的这种形式。
gofmt 可以兼容处理两种形式,处理原则是:如果一个源码文件只有 // +build 形式的指示符,gofmt 会将与其等价的 //go:build 行加入。否则,如果一个源文件中同时存在这两种形式的指示符行,那么 //+build 行的信息将被 //go:build 行的信息所覆盖。
2、 go 语言 ABI
参考文档:
Go internal ABI specification
https://go.googlesource.com/go/+/refs/heads/dev.regabi/src/cmd/compile/internal-abi.md
Proposal: Create an undefined internal calling convention
https://go.googlesource.com/proposal/+/master/design/27539-internal-abi.md
名词解释:ABI: application binary interface, 应用程序二进制接口,规定了程序在机器层面的操作规范和调用规约。调用规约: calling convention, 所谓“调用规约”是调用方和被调用方对于函数调用的一个明确的约定,包括:函数参数与返回值的传递方式、传递顺序。只有双方都遵守同样的约定,函数才能被正确地调用和执行。如果不遵守这个约定,函数将无法正确执行。
Go 从1.17.1版本开始支持多 ABI:1. 为了兼容性各平台保持通用性,保留历史版本 ABI,并更名为 ABI0。2. 为了更好的性能,增加新版本 ABI 取名 ABIInternal。ABI0 遵循平台通用的函数调用约定,实现简单,不用担心底层cpu架构寄存器的差异;ABIInternal 可以指定特定的函数调用规范,可以针对特定性能瓶颈进行优化,在多个 Go 版本之间可以迭代,灵活性强,支持寄存器传参提升性能。Go 汇编为了兼容已存在的汇编代码,保持使用旧的 ABI0。
Go 为什么在有了 ABI0 之后,还要引入 ABIInternal?当然是为了性能!据官方测试,寄存器传参可以带来 5% 的性能提升。
我们看一个例子:
packagemain
import_"fmt"
funcPrint(deltastring)
funcmain(){
Print("hello")
}
#include"textflag.h"
TEXT·Print(SB),NOSPLIT,$8
CALLfmt·Println(SB)
RET
运行上面代码会报错:main.Print: relocation target fmt.Println not defined for ABI0 (but is defined for ABIInternal)
原因是,fmt·Println 函数默认使用的 ABI 标准是 ABIInternal,而 Go 语言手写的汇编使用的 ABI 格式是 ABI0,二者标准不一样不能直接调用。不过 Go 语言可以通过 //go:linkname 的方式为 ABIInternal 生成 ABI0 包装。
packagemain
import(
"fmt"
)
//go:linknamePrintlnfmt.Println
funcPrintln(a...any)(nint,errerror)
funcPrint(deltainterface{})funcmain(){
Print("hello")
}
#include"textflag.h"
TEXT·Print(SB),NOSPLIT,$48-16
LEAQstrp+0(FP),AX
MOVQAX,0(SP)//[]interface{}slice的pointer
MOVQ$1,BX
MOVQBX,8(SP)//slice的len
MOVQBX,16(SP)//slice的cap
CALLfmt·Println(SB)////go:linkname为fmt.Println生成一个ABI0包装后,汇编可以直接调用
RET
简单说明:函数 fmt.Println 是一个变参函数,变参(a ...any)实际上是 (a []any)的语法糖。参数中,slice 占 24Byte,int 占 8Byte,error 是 interface 类型,占 16Byte,加起来是 48 Byte。所以,调用此函数时,caller 需要再栈上准备 24Byte 空间。而 Print 的入参刚好是一个 interface{} 类型,和 any 一致,所以只要把 Print 函数的入参的地址赋给 a 的指针,并把 a 的 len 和 cap 设置为 1,就可以调用 fmt·Println 函数了。如以上代码所示。
3、内存管理和 GC 对汇编的影响
3.1 调用栈扩缩容对汇编的影响
为了减少对内存的占用,goroutine 启动时 runtime 只给它分配了很少的栈内存。所有函数(标记 go:nosplit 的除外)的序言部分(启动指令)会插入分段检查,当发现栈溢出(栈空间不足)时,就会调用 runtime.morestack,执行栈拓展逻辑:
- 旧版本的 Go 编译器采用了分段栈机制实现栈拓展,当一个 goroutine 的执行栈溢出时,就增加一个栈内存作为调用栈的补充,新旧栈彼此没有连续。这种设计的缺陷很容易破坏缓存的局部性原理,从而降低程序的运行时性能。
- Go 1.3 版本开始,引入了连续栈(拷贝栈)机制,并把 goroutine 的初始栈大小由 8KB 降低到了 2KB。当一个执行栈发生溢出时,新建一个两倍于原栈大小的新栈,并将原栈整个拷贝到新栈上,保证整个栈是连续的。
栈的拷贝有些副作用:
- 如果栈上存在指向当前被拷贝栈的指针,当栈拷贝执行完成后,这个指针还是指向原栈,需要更新。
- goroutine 的 g 结构体上的 gobuf 成员也还是指向旧的栈,也需要更新。
除了正在拷贝的栈中可能存在指向自己的的指针外,还有没有其他存活中的内存有指向即将失效的栈空间的指针呢?答案在 go 逃逸分析源码 中,代码如下:
//Escapeanalysis.
//
//HereweanalyzefunctionstodeterminewhichGovariables
//(includingimplicitallocationssuchascallsto"new"or"make",
//compositeliterals,etc.)canbeallocatedonthestack.Thetwo
//keyinvariantswehavetoensureare:(1)pointerstostackobjects
//cannotbestoredintheheap,and(2)pointerstoastackobject
//cannotoutlivethatobject(e.g.,becausethedeclaringfunction
//returnedanddestroyedtheobject'sstackframe,oritsspaceis
//reusedacrossloopiterationsforlogicallydistinctvariables).
//
其中 “(1) pointers to stack objects cannot be stored in the heap” 表明指向栈对象的指针不能存储在堆中。
拷贝栈理论上没有上限,但是一般都设置了上限。当新的栈大小超过了 maxstacksize 就会抛出”stack overflow“的异常。maxstacksize 是在 runtime.main 中设置的。64 位系统下栈的最大值 1GB、32 位系统是 250MB。参考代码:
ifnewsize>maxstacksize||newsize>maxstackceiling{
ifmaxstacksize< maxstackceiling {
print("runtime:goroutinestackexceeds",maxstacksize,"-bytelimit
")
}else{
print("runtime:goroutinestackexceeds",maxstackceiling,"-bytelimit
")
}
print("runtime:sp=",hex(sp),"stack=[",hex(gp.stack.lo),",",hex(gp.stack.hi),"]
")
throw("stackoverflow")
}
由拷贝栈的原理可知,拷贝栈对 Go 汇编是透明的。
3.2 GC 对汇编的影响
由于 GC 会动态回收没有被引用的堆内存,而 goroutine 的调用栈在堆空间,所以如果调用栈中存了堆内存的指针,就需要告诉 GC 栈中含指针。上文中说到的伪指令 FUNCDATA、GO_RESULTS_INITIALIZED、NO_LOCAL_POINTERS 就是干这个事的。由于 FUNCDATA 伪指令几乎只能由编译器维护,所以在手写的汇编函数本地内存栈中保存指向动态内存的指针几乎是一种奢望。
4、 函数内联和汇编
参考文档:
Go: Inlining Strategy & Limitation
https://medium.com/a-journey-with-go/go-inlining-strategy-limitation-6b6d7fc3b1be
4.1 查看内联情况
可以通过执行以下命令,输出被内联的函数:
gobuild-gcflags="-m"main.go
#输出结果:
#./op.go6:caninlineadd
#./op.go6:caninlinesub
#./main.go11:inliningcalltosub
#./main.go11:inliningcalltoadd
#./main.go12:inliningcalltofmt.Printf
或者使用参数 -gflags="-m -m" 运行,查看编译器的详细优化策略:
gobuild-gcflags="-m-m"main.go
输出很详细:
#command-line-arguments
./main.go6:cannotinlinemain:functiontoocomplex:cost106exceedsbudget80
./main.go12:inliningcalltofmt.Printf
./main.go6:caninlinetoEfacewithcost0as:func(){}
./main.go2:shlxescapestoheap:
./main.go2:flow:i=&{storageforshlx}:
./main.go2:fromshlx(spill)at./main.go2
./main.go2:fromi=shlx(assign)at./main.go4
./main.go2:flow:{storagefor...argument}=i:
./main.go2:from...argument(slice-literal-element)at./main.go12
./main.go2:flow:fmt.a=&{storagefor...argument}:
./main.go2:from...argument(spill)at./main.go12
./main.go2:fromfmt.format,fmt.a:="%+v",...argument(assign-pair)at./main.go12
./main.go2:flow:{heap}=*fmt.a:
./main.go2:fromfmt.Fprintf(io.Writer(os.Stdout),fmt.format,fmt.a...)(callparameter)at./main.go12
./main.go2:xescapestoheap:
./main.go2:flow:i=&{storageforx}:
./main.go2:fromx(spill)at./main.go2
./main.go2:fromi=x(assign)at./main.go4
./main.go2:flow:{storagefor...argument}=i:
./main.go2:from...argument(slice-literal-element)at./main.go12
./main.go2:flow:fmt.a=&{storagefor...argument}:
./main.go2:from...argument(spill)at./main.go12
./main.go2:fromfmt.format,fmt.a:="%+v",...argument(assign-pair)at./main.go12
./main.go2:flow:{heap}=*fmt.a:
./main.go2:fromfmt.Fprintf(io.Writer(os.Stdout),fmt.format,fmt.a...)(callparameter)at./main.go12
./main.go2:xescapestoheap
./main.go2:shlxescapestoheap
./main.go12:...argumentdoesnotescape
Go 编译器默认将进行内联优化,可以通过 -gcflags="-l" 选项全局禁用内联,与一个-l禁用内联相反,如果传递两个或两个以上的-l则会打开内联,并启用更激进的内联策略。例如以下代码:
//3.1:varclosure=NewClosure()
funcmain(){
//3.2:varclosurefunc()int
varclosure=NewClosure()
closure()
//3.3:closure=NewClosure()
closure()
}
funcNewClosure()func()int{
i:=0returnfunc()int{
i++
returni
}
}
命令 go build -gcflags="-m" main.go 和 go build -gcflags="-m -l -l" main.go 都是输出:
./main.go6:caninlineNewClosure
./main.go9:caninlineNewClosure.func1
./main.go26:inliningcalltoNewClosure
./main.go9:caninlinemain.func1
./main.go9:inliningcalltomain.func1
./main.go9:inliningcalltomain.func1
./main.go26:funcliteraldoesnotescape
./main.go2:movedtoheap:i
./main.go9:funcliteralescapestoheap
命令 go build -gcflags="-m" main.go 输出:
./main.go2:movedtoheap:i
./main.go9:funcliteralescapestoheap
4.2 内联前后性能对比
首先,看一下函数内联与非内联的性能差异。内联可以避免函数调用过程中的一些开销:创建栈帧,读写寄存器。不过,对函数体进行拷贝也会增大二进制文件的大小。据 Go 官方宣传,内联大概会有 5~6% 的性能提升。
//go:noinline
funcmaxNoinline(a,bint)int{
ifa< b {
returnb
}
returna
}
funcmaxInline(a,bint)int{
ifa< b {
returnb
}
returna
}
funcBenchmarkInline(b*testing.B){
x,y:=1,2
b.Run("BenchmarkNoInline",func(b*testing.B){
b.ResetTimer()
fori:=0;i< b.N; i++ {
maxNoinline(x, y)
}
})
b.Run("BenchmarkInline",func(b*testing.B){
b.ResetTimer()
fori:=0;i< b.N; i++ {
maxInline(x, y)
}
})
}
在程序代码中,想要禁止编译器内联优化很简单,在函数定义前一行添加 //go:noinline 即可。以下是性能对比结果:
BenchmarkInline/BenchmarkNoInline-128861373981.248ns/op0B/op0allocs/op
BenchmarkInline/BenchmarkInline-1210000000000.2506ns/op0B/op0allocs/op
因为函数体内部的执行逻辑非常简单,此时内联与否的性能差异主要体现在函数调用的固定开销上。显而易见,该差异是非常大的。
4.3 内联条件
Go 语言代码函数内联的策略每个编译器版本都有细微差别,比如新版已支持含 for 和 闭包 的函数内联。1.18 版本的部分无法内联的规则如下:
- 函数标注 "go:noinline" 注释。
- 函数标注 "go:norace" 注释,且使用 "-gcflags=-d checkptr" 参数编译。
- 函数标注 "go:cgo_unsafe_args" 注释。
- 函数标注 "go:uintptrescapes" 注释。
- 函数只有声明而没有函数体:比如函数实体在汇编文件 xxx.s 中。
- 超过小代码量边界的函数:内联的小代码量边界是 80 个节点(抽象语法树AST的节点)。
- 函数中含某些关键字的函数:比如 select、defer、go、recover 等。
- 一些特殊的内部函数:比如 runtime.getcallerpc、runtime.getcallersp (这俩太特殊了)。
- 函数内部使用 type 关键字重定义了类型:比如 "type Int int" 或 "type Int = int"。
- 作为尾递归调用时。
此外,还有一些编译器觉得内联成本很低,所以必然内联的函数:
- "runtime" package 下的 "heapBits.nextArena" 和 "builtin" package 下的 "append"。
- "encoding/binary" package 下的:"littleEndian.Uint64", "littleEndian.Uint32", "littleEndian.Uint16","bigEndian.Uint64", "bigEndian.Uint32", "bigEndian.Uint16","littleEndian.PutUint64", "littleEndian.PutUint32", "littleEndian.PutUint16","bigEndian.PutUint64", "bigEndian.PutUint32", "bigEndian.PutUint16", "append"。
由规则 5 可知,Go 语言汇编是无法内联的。
此外,关于闭包内联是一个比较复杂的话题,据笔者测试,1.18 有如上规则:
- 满足条件的闭包可以内联。
- 闭包通用部分在内联统计的时候,占用函数的 15 个 AST 节点。
- 变量保存的闭包,如果是局部变量且没有重新赋值过,则可以被内联。
关于闭包内联的第 3 条规则,有如下例子:
//3.1:varclosure=NewClosure()
funcmain(){
//3.2:varclosurefunc()int
varclosure=NewClosure()
closure()
//3.3:closure=NewClosure()
closure()
}
funcNewClosure()func()int{
i:=0
returnfunc()int{
i++
returni
}
}
执行 go build -gcflags="-m" ./ 输出如下
./main.go6:caninlineNewClosure
./main.go9:caninlineNewClosure.func1
./main.go26:inliningcalltoNewClosure
./main.go9:caninlinemain.func1
./main.go9:inliningcalltomain.func1
./main.go9:inliningcalltomain.func1
./main.go26:funcliteraldoesnotescape
./main.go2:movedtoheap:i
./main.go9:funcliteralescapestoheap
表明闭包 closure 可以内联。如果把 3.1 或 3.2 或 3.3 的注释打开,则将会输出:
./main.go6:caninlineNewClosure
./main.go9:caninlineNewClosure.func1
./main.go22:inliningcalltoNewClosure
./main.go22:funcliteraldoesnotescape
./main.go2:movedtoheap:i
./main.go9:funcliteralescapestoheap
表明闭包 closure 无法内联。
此外,如果想禁用闭包内联,可以使用 -gcflags="-d=inlfuncswithclosures=0" 或-gcflags="-d inlfuncswithclosures=0" 参数编译。
gobuild-gcflags="-d=inlfuncswithclosures=0"main.go
gobuild-gcflags="-dinlfuncswithclosures=0"main.go
如果想了解 go 1.18 的内联检查逻辑,可以看这个源码:inline.CanInline 和 (*inline.hairyVisitor).doNode。其调用顺序是:inline.CanInline --> inline.hairyVisitor.tooHairy --> inline.hairyVisitor.doNode。
//CanInlinedetermineswhetherfnisinlineable.
//Ifso,CanInlinesavescopiesoffn.Bodyandfn.Dclinfn.Inl.
//fnandfn.Bodywillalreadyhavebeentypechecked.
funcCanInline(fn*ir.Func){
...
//Ifmarked"go:noinline",don'tinline
iffn.Pragma&ir.Noinline!=0{
reason="markedgo:noinline"
return
}
//Ifmarked"go:norace"and-racecompilation,don'tinline.
ifbase.Flag.Race&&fn.Pragma&ir.Norace!=0{
reason="markedgo:noracewith-racecompilation"
return
}
//Ifmarked"go:nocheckptr"and-dcheckptrcompilation,don'tinline.
ifbase.Debug.Checkptr!=0&&fn.Pragma&ir.NoCheckPtr!=0{
reason="markedgo:nocheckptr"
return
}
//Ifmarked"go:cgo_unsafe_args",don'tinline,sincethe
//functionmakesassumptionsaboutitsargumentframelayout.
iffn.Pragma&ir.CgoUnsafeArgs!=0{
reason="markedgo:cgo_unsafe_args"
return
}
//Ifmarkedas"go:uintptrescapes",don'tinline,sincethe
//escapeinformationislostduringinlining.
iffn.Pragma&ir.UintptrEscapes!=0{
reason="markedashavinganescapinguintptrargument"
return
}
//Thenowritebarrierreccheckercurrentlyworksatfunction
//granularity,soinliningyeswritebarrierrecfunctionscan
//confuseit(#22342).Asaworkaround,disallowinlining
//themfornow.
iffn.Pragma&ir.Yeswritebarrierrec!=0{
reason="markedgo:yeswritebarrierrec"
return
}
//Iffnhasnobody(isdefinedoutsideofGo),cannotinlineit.
iflen(fn.Body)==0{
reason="nofunctionbody"
return
}
...
visitor:=hairyVisitor{
budget:inlineMaxBudget,//inlineMaxBudget==80
extraCallCost:cc,
}
ifvisitor.tooHairy(fn){
reason=visitor.reason
return
}
...
}
func(v*hairyVisitor)tooHairy(fn*ir.Func)bool{
v.do=v.doNode//cacheclosure
ifir.DoChildren(fn,v.do){
returntrue
}
...
}
func(v*hairyVisitor)doNode(nir.Node)bool{
...
caseir.OSELECT,
ir.OGO,
ir.ODEFER,
ir.ODCLTYPE,//can'tprintyet
ir.OTAILCALL:
v.reason="unhandledop"+n.Op().String()
returntrue
...
}
5、 有哪些有意思的使用场景
5.1、 获取 goid
goid 即 goroutine id,最常用三方库应该就是 petermattis/goid, 里通过汇编获取 goid 的代码关键逻辑如下:
runtime_go1.9.go 代码:
//go:buildgc&&go1.9//+buildgc,go1.9packagegoid
typestackstruct{
louintptr
hiuintptr
}
typegobufstruct{
spuintptr
pcuintptr
guintptr
ctxtuintptr
retuintptr
lruintptr
bpuintptr
}
typegstruct{
stackstack
stackguard0uintptr
stackguard1uintptr
_panicuintptr
_deferuintptr
muintptr
schedgobuf
syscallspuintptr
syscallpcuintptr
stktopspuintptr
paramuintptr
atomicstatusuint32
stackLockuint32
goidint64//Hereitis!
}
goid_go1.5_amd64.go 代码:
//go:build(amd64||amd64p32)&&gc&&go1.5//+buildamd64amd64p32//+buildgc//+buildgo1.5packagegoid
funcGet()int64
goid_go1.5_amd64.s 代码:
//go:build(amd64||amd64p32)&&gc&&go1.5
//+buildamd64amd64p32
//+buildgc
//+buildgo1.5
#include"go_asm.h"
#include"textflag.h"
//funcGet()int64
TEXT·Get(SB),NOSPLIT,$0-8
MOVQ(TLS),R14
MOVQg_goid(R14),R13
MOVQR13,ret+0(FP)
RET
不过这样获取 goid 有一个局限性,就是如果当前处于 g0 调用栈(系统调用或CGO函数中)时,拿到的不是当前 g 的 goid,而是 是 g0 的 goid。在这种情况下 g.m.curg.goid 才是当前 g 的 goid。参考Go1.18 标准库下go/src/runtime/HACKING.md 文件里的说明:
getg()andgetg().m.curg
Togetthecurrentuserg,usegetg().m.curg.
getg()alonereturnsthecurrentg,butwhenexecutingonthesystemorsignalstacks,thiswillreturnthecurrentM's"g0"or"gsignal",respectively.Thisisusuallynotwhatyouwant.
Todetermineifyou'rerunningontheuserstackorthesystemstack,usegetg()==getg().m.curg.
除了 goid,pid也可以用汇编获取:choleraehyq/pid 是一个 fork petermattis/goid 的仓库,里面增加了获取 pid 的实现,实现代码如下:
p_m_go1.19.go 代码:
//go:buildgc&&go1.19&&!go1.21//+buildgc,go1.19,!go1.21packagegoid
typepstruct{
idint32//Hereispid
}
typemstruct{
g0uintptr//goroutinewithschedulingstack
morebufgobuf//gobufargtomorestack
divmoduint32//div/moddenominatorforarm-knowntoliblink
_uint32//Fieldsnotknowntodebuggers.
prociduint64//fordebuggers,butoffsetnothard-coded
gsignaluintptr//signal-handlingg
goSigStackgsignalStack//Go-allocatedsignalhandlingstack
sigmasksigset//storageforsavedsignalmask
tls[6]uintptr//thread-localstorage(forx86externregister)
mstartfnfunc()
curguintptr//currentrunninggoroutine
caughtsiguintptr//goroutinerunningduringfatalsignal
p*p//attachedpforexecutinggocode(nilifnotexecutinggocode)
}
pid_go1.5.go 代码:
//go:build(amd64||amd64p32||arm64)&&!windows&&gc&&go1.5//+buildamd64amd64p32arm64//+build!windows//+buildgc//+buildgo1.5packagegoid
//go:nosplitfuncgetPid()uintptr//go:nosplitfuncGetPid()int{
returnint(getPid())
}
pid_go1.5_amd64.s 代码:
//+buildamd64amd64p32
//+buildgc,go1.5
#include"go_asm.h"
#include"textflag.h"
//funcgetPid()int64
TEXT·getPid(SB),NOSPLIT,$0-8
MOVQ(TLS),R14
MOVQg_m(R14),R13
MOVQm_p(R13),R14
MOVLp_id(R14),R13
MOVQR13,ret+0(FP)
RET
不过,通过这种方式获取的 pid 也有一个局限性:在持有 pid 之后的时间里,可能当前 goroutine 已经被调度到其他 P 上了,也就是在使用 pid 的时候当前 pid 已经改变了。如果想要持有在持有 pid 的过程中持续帮当当前 P,可以使用一下方式:
import"unsafe"
var_=unsafe.Sizeof(0)
//go:linknameprocPinruntime.procPin
//go:nosplit
funcprocPin()int
//go:linknameprocUnpinruntime.procUnpin
//go:nosplit
funcprocUnpin()
runtime.procPin 和 runtime.procUnpin的实现代码在Go 标准库下的 src/runtime/proc.go 文件中:
//go:nosplit
funcprocPin()int{
_g_:=getg()
mp:=_g_.m
mp.locks++//锁定P的调度
returnint(mp.p.ptr().id)
}
//go:nosplit
funcprocUnpin(){
_g_:=getg()
_g_.m.locks--
}
通过 procPin 函数锁定 P 的调度后再使用 pid,然后通过 procUnpin 释放 P。不过这里也需要谨慎使用,使用不当会对性能产生严重影响。
以上获取 goid 的方式还有一个比较大的缺点,就是如果 Go 编译器修改了 g 的结构体,就需要重新适配。
《Go语言高级编程》第三章第8节 的实现可以避免这个问题。其原理是,通过汇编构建一个 g 类型的 interface{},然后通过反射获取 goid 成员的偏移量。根据原理,可以如下实现:
funcGetg()int64funcgetgi()interface{}
varg_goid_offsetuintptr=func()uintptr{
g:=getgi()
iff,ok:=reflect.TypeOf(g).FieldByName("goid");ok{
returnf.Offset
}
panic("cannotfindg.goidfield")
}()
TEXT·Getg(SB),NOSPLIT,$0-8
MOVQ(TLS),AX
ADDQ·g_goid_offset(SB),AX
MOVQ(AX),BX
MOVQBX,ret+0(FP)
RET
//funcgetgi()interface{}
TEXT·getgi(SB),NOSPLIT,$32-16
NO_LOCAL_POINTERS
MOVQ$0,ret_type+0(FP)
MOVQ$0,ret_data+8(FP)
GO_RESULTS_INITIALIZED
//getruntime.g
//MOVQ(TLS),AX
MOVQ$0,AX
//getruntime.gtype
MOVQ$type·runtime·g(SB),BX
//MOVQBX,·runtime_g_type(SB)
//returninterface{}
MOVQBX,ret_type+0(FP)
MOVQAX,ret_data+8(FP)
RET
实际上还可以继续简化:
varruntime_g_typeuint64//go源码中声明
vargGoidOffsetuintptr=func()uintptr{//nolint
varifaceinterface{}
typeefacestruct{
_typeuint64
dataunsafe.Pointer
}
//结构iface后,修改他的类型为g
(*eface)(unsafe.Pointer(&iface))._type=runtime_g_type
iff,ok:=reflect.TypeOf(iface).FieldByName("goid");ok{
returnf.Offset
}
panic("cannotfindg.goidfield")
}()
GLOBL·runtime_g_type(SB),NOPTR,$8
DATA·runtime_g_type+0(SB)/8,$type·runtime·g(SB)//汇编中初始化。汇编中可以访问 package 的私有变量
5.2、Monkey Patch
Go 语言实现猴子打点的 package 不一定需要使用汇编,比如 bouk/monkey 和 go-kiss/monkey。不过字节开源的 monkey 和 内部的 mockito 都使用了汇编。他们有一个同源的依赖库,分别在 mockey/internal/monkey 目录和 mockito/monkey 目录下。
其 Patch() 的调用路径如下:Build() -> Patch() -> PatchValue() -> WriteWithSTW() -> Write() -> do_replace_code() 其中 do_replace_code() 是汇编实现的,作用是使用 mprotect 系统调用来修改内存权限(mprotect系统调用是修改内存页属性的)。原因是:可执行代码区是只读的,需要修改为可读写后才能修改,修改为可执行后才能执行(有想用 Go 写病毒的,可以参考一下)。
func(builder*MockBuilder)Build()*Mocker{
mocker:=Mocker{target:reflect.ValueOf(builder.target),builder:builder}
mocker.buildHook(builder)
mocker.Patch()
return&mocker
}
func(mocker*Mocker)Patch()*Mocker{
mocker.lock.Lock()
defermocker.lock.Unlock()
ifmocker.isPatched{
returnmocker
}
mocker.patch=monkey.PatchValue(mocker.target,mocker.hook,reflect.ValueOf(mocker.proxy),mocker.builder.unsafe)
mocker.isPatched=true
addToGlobal(mocker)
mocker.outerCaller=tool.OuterCaller()
returnmocker
}
//PatchValuereplacethetargetfunctionwithahookfunction,andstoresthetargetfunctionintheproxyfunction//forfuturerestore.Targetandhookarevaluesoffunction.Proxyisavalueofproxyfunctionpointer.funcPatchValue(target,hook,proxyreflect.Value,unsafebool)*Patch{
tool.Assert(hook.Kind()==reflect.Func,"'%s'isnotafunction",hook.Kind())
tool.Assert(proxy.Kind()==reflect.Ptr,"'%v'isnotafunctionpointer",proxy.Kind())
tool.Assert(hook.Type()==target.Type(),"'%v'and'%s'mismatch",hook.Type(),target.Type())
tool.Assert(proxy.Elem().Type()==target.Type(),"'*%v'and'%s'mismatch",proxy.Elem().Type(),target.Type())
targetAddr:=target.Pointer()
//ThefirstfewbytesofthetargetfunctioncodeconstbufSize=64
targetCodeBuf:=common.BytesOf(targetAddr,bufSize)
//constructthebranchinstruction,i.e.jumptothehookfunction
hookCode:=inst.BranchInto(common.PtrAt(hook))
//searchthecuttingpointofthetargetcode,i.e.theminimumlengthoffullinstructionsthatislongerthanthehookCode
cuttingIdx:=inst.Disassemble(targetCodeBuf,len(hookCode),!unsafe)
//constructtheproxycode
proxyCode:=common.AllocatePage()
//savetheoriginalcodebeforethecuttingpointcopy(proxyCode,targetCodeBuf[:cuttingIdx])
//constructthebranchinstruction,i.e.jumptothecuttingpointcopy(proxyCode[cuttingIdx:],inst.BranchTo(targetAddr+uintptr(cuttingIdx)))
//injecttheproxycodetotheproxyfunction
fn.InjectInto(proxy,proxyCode)
tool.DebugPrintf("PatchValue:hookcodelen(%v),cuttingIdx(%v)
",len(hookCode),cuttingIdx)
//replacetargetfunctioncodesbeforethecuttingpoint
mem.WriteWithSTW(targetAddr,hookCode)
return&Patch{base:targetAddr,code:proxyCode,size:cuttingIdx}
}
//WriteWithSTWcopiesdatabytestothetargetaddressandreplacestheoriginalbytes,duringwhichitwillstopthe//world(onlythecurrentgoroutine'sPisrunning).funcWriteWithSTW(targetuintptr,data[]byte){
common.StopTheWorld()
defercommon.StartTheWorld()
err:=Write(target,data)
tool.Assert(err==nil,err)
}
而 Write 函数的实现在 github.com/bytedance/mockey/internal/monkey/mem/write_linux.go,其代码如下:
packagemem
import(
"syscall""github.com/bytedance/mockey/internal/monkey/common"
)
funcWrite(targetuintptr,data[]byte)error{
do_replace_code(target,common.PtrOf(data),uint64(len(data)),syscall.SYS_MPROTECT,
syscall.PROT_READ|syscall.PROT_WRITE,syscall.PROT_READ|syscall.PROT_EXEC))
returnnil
}
funcdo_replace_code(
_uintptr,//void*addr
_uintptr,//void*data
_uint64,//size_tsize
_uint64,//intmprotect
_uint64,//intprot_rw
_uint64,//intprot_rx
)
do_replace_code 函数的汇编实现在 github.com/bytedance/mockey/internal/monkey/mem/write_linux_amd64.s,代码如下:
#include"textflag.h"
#defineNOP8BYTE$0x90;BYTE$0x90;BYTE$0x90;BYTE$0x90;BYTE$0x90;BYTE$0x90;BYTE$0x90;BYTE$0x90;
#defineNOP64NOP8;NOP8;NOP8;NOP8;NOP8;NOP8;NOP8;NOP8;
#defineNOP512NOP64;NOP64;NOP64;NOP64;NOP64;NOP64;NOP64;NOP64;
#defineNOP4096NOP512;NOP512;NOP512;NOP512;NOP512;NOP512;NOP512;NOP512;
#defineaddrarg+0x00(FP)
#definedataarg+0x08(FP)
#definesizearg+0x10(FP)
#definemprotectarg+0x18(FP)
#defineprot_rwarg+0x20(FP)
#defineprot_rxarg+0x28(FP)
#defineCMOVNEQ_AX_CX
BYTE$0x48
BYTE$0x0f
BYTE$0x45
BYTE$0xc8
TEXT·do_replace_code(SB),NOSPLIT,$0x30-0
JMPSTART
NOP4096
START:
MOVQaddr,DI
MOVQsize,SI
MOVQDI,AX
ANDQ$0x0fff,AX
ANDQ$~0x0fff,DI
ADDQAX,SI
MOVQSI,CX
ANDQ$0x0fff,CX
MOVQ$0x1000,AX
SUBQCX,AX
TESTQCX,CX
CMOVNEQ_AX_CX
ADDQCX,SI
MOVQDI,R8
MOVQSI,R9
MOVQmprotect,AX
MOVQprot_rw,DX
SYSCALL
MOVQaddr,DI
MOVQdata,SI
MOVQsize,CX
REP
MOVSB
MOVQR8,DI
MOVQR9,SI
MOVQmprotect,AX
MOVQprot_rx,DX
SYSCALL
JMPRETURN
NOP4096
RETURN:
RET
5.3、 优化获取行号性能
笔者另一篇掘金文章 《golang文件行号探索》 中有详细说明,代码如下:
//stack_amd64.gotypeLineuintptrfuncNewLine()Line
varrcuCacheunsafe.Pointer=func()unsafe.Pointer{
m:=make(map[Line]string)
returnunsafe.Pointer(&m)
}()
func(lLine)LineNO()(linestring){
mPCs:=*(*map[Line]string)(atomic.LoadPointer(&rcuCache))
line,ok:=mPCs[l]
if!ok{
file,n:=runtime.FuncForPC(uintptr(l)).FileLine(uintptr(l))
line=file+":"+strconv.Itoa(n)
mPCs2:=make(map[Line]string,len(mPCs)+10)
mPCs2[l]=line
for{
p:=atomic.LoadPointer(&rcuCache)
mPCs=*(*map[Line]string)(p)
fork,v:=rangemPCs{
mPCs2[k]=v
}
swapped:=atomic.CompareAndSwapPointer(&rcuCachep,unsafe.Pointer(&mPCs2))
ifswapped{
break
}
}
}
return
}
#stack_amd64.s
TEXT·NewLine(SB),NOSPLIT,$0-8
MOVQretpc-8(FP),AX
SUBQ$1,AX//注意,这里要-1
MOVQAX,ret+0(FP)
RET
该代码除了使用汇编获取行号外,还是用了无锁的 RCU(Read-copy update) 算法提升并发查询速度。还有一点要注意的,retpc-8(FP) 是函数返回地址,也就是调用指令 CALL 的下一行指令, 所以需要 -1 才能得到 CALL 指令的 pc,参考Go 源码 src/runtime/traceback.g 的这段注释:
//file/lineinformationusingpc-1,becausethatisthepcofthe
//callinstruction(moreprecisely,thelastbyteofthecallinstruction).
//Callersexpectthepcbuffertocontainreturnaddressesanddothe
//same-1themselves,sowekeeppcunchanged.
//Whenthepcisfromasignal(e.g.profilerorsegv)thenwewant
//tolookupfile/lineinformationusingpc,andwestorepc+1inthe
//pcbuffersocallerscanunconditionallysubtract1beforelookingup.
//Seeissue34123.
//Thepccanbeatfunctionentrywhentheframeisinitializedwithout
//actuallyrunningcode,likeruntime.mstart.
5.4、 优化获取调用栈性能
笔者另一篇掘金文章 《关于 golang 错误处理的一些优化想法》 中有详细说明。stack_amd64.go 代码:
//go:buildamd64//+buildamd64packageerrors
import(
_"unsafe"
)
funcbuildStack(s[]uintptr)int
stack_amd64.s 代码:
//go:buildamd64||amd64p32||arm64
//+buildamd64amd64p32arm64
#include"go_asm.h"
#include"textflag.h"
#include"funcdata.h"
//funcbuildStack(s[]uintptr)int
TEXT·buildStack(SB),NOSPLIT,$24-8
NO_LOCAL_POINTERS
MOVQcap+16(FP),DX//s.cap
MOVQp+0(FP),AX//s.ptr
MOVQ$0,CX//loop.i
loop:
MOVQ+8(BP),BX//lastpc->BX
SUBQ$1,BX
MOVQBX,0(AX)(CX*8)//s[i]=BX
ADDQ$1,CX//CX++/i++
CMPQCX,DX//ifs.len>=s.cap{return}
JAEreturn//无符号大于等于就跳转
MOVQ+0(BP),BP//lastBP;展开调用栈至上一层
CMPQBP,$0//if(BP)<= 0 { return}
JAloop//无符号大于就跳转
return:
MOVQCX,n+24(FP)//retn
RET
5.5、 字符串比较
Go 语言源码里的字符串比较函数,实际上使用了 SIMD 指令加速,由汇编实现。源码在 Go 源码文件中:src/cmd/compile/internal/typecheck/builtin/runtime.go :
funccmpstring(string,string)int
src/internal/bytealg/compare_amd64.s:
TEXT·Compare(SB),NOSPLIT,$0-56
//AX=a_base(wantinSI)
//BX=a_len(wantinBX)
//CX=a_cap(unused)
//DI=b_base(wantinDI)
//SI=b_len(wantinDX)
//R8=b_cap(unused)
MOVQSI,DX
MOVQAX,SI
JMPcmpbody<>(SB)
TEXTruntime·cmpstring(SB),NOSPLIT,$0-40
//AX=a_base(wantinSI)
//BX=a_len(wantinBX)
//CX=b_base(wantinDI)
//DI=b_len(wantinDX)
MOVQAX,SI
MOVQDI,DX
MOVQCX,DI
JMPcmpbody<>(SB)
//input:
//SI=a
//DI=b
//BX=alen
//DX=blen
//output:
//AX=output(-1/0/1)
TEXTcmpbody<>(SB),NOSPLIT,$0-0
CMPQSI,DI
...
loop:
CMPQR8,$16
JBE_0through16
MOVOU(SI),X0
MOVOU(DI),X1
PCMPEQBX0,X1
PMOVMSKBX1,AX
XORQ$0xffff,AX//convertEQtoNE
JNEdiff16//branchifatleastonebyteisnotequal
ADDQ$16,SI
ADDQ$16,DI
SUBQ$16,R8
JMPloop
···
这里 MOVOU、PCMPEQB、PMOVMSKB 等就是 SIMD 指令。如果想详细了解 SIMD 指令可以看一下 Intel 的官方文档 《Intel Intrinsics Guide》。另,据笔者的尝试,SSE 和 SSE2 指令是可以直接在 Go 语言会便利使用的。有想法的同学可以自己验证一下其他 SIMD 指令。
5.6、 字符串搜索
我们常用的字符串搜索函数 strings.Index,也使用了汇编实现的 SIMD 指令加速。代码在 Go 源码文件 src/strings/strings.go 下:
//Indexreturnstheindexofthefirstinstanceofsubstrins,or-1ifsubstrisnotpresentins.funcIndex(s,substrstring)int{
n:=len(substr)
switch{
casen==0:
return0casen==1:
returnIndexByte(s,substr[0])
casen==len(s):
ifsubstr==s{
return0
}
return-1casen>len(s):
return-1casen<= bytealg.MaxLen:
//Usebruteforcewhensandsubstrbotharesmalliflen(s)<= bytealg.MaxBruteForce {
returnbytealg.IndexString(s,substr)
...
}
//IndexBytereturnstheindexofthefirstinstanceofcins,or-1ifcisnotpresentins.funcIndexByte(sstring,cbyte)int{
returnbytealg.IndexByteString(s,c)
}
IndexByteString 函数声明在 src/internal/bytealg/indexbyte_native.go
//go:build386||amd64||s390x||arm||arm64||ppc64||ppc64le||mips||mipsle||mips64||mips64le||riscv64||wasm
packagebytealg
//go:noescape
funcIndexByte(b[]byte,cbyte)int
//go:noescape
funcIndexByteString(sstring,cbyte)int
src/internal/bytealg/index_native.go
//go:buildamd64||arm64||s390x||ppc64le||ppc64
packagebytealg
//go:noescape
//Indexreturnstheindexofthefirstinstanceofbina,or-1ifbisnotpresentina.
//Requires2<= len(b) <= MaxLen.
funcIndex(a,b[]byte)int
//go:noescape
//IndexStringreturnstheindexofthefirstinstanceofbina,or-1ifbisnotpresentina.
//Requires2<= len(b) <= MaxLen.
funcIndexString(a,bstring)int
汇编实现在 src/internal/bytealg/indexbyte_amd64.s
#include"go_asm.h"
#include"textflag.h"
TEXT·IndexByte(SB),NOSPLIT,$0-40
MOVQb_base+0(FP),SI
MOVQb_len+8(FP),BX
MOVBc+24(FP),AL
LEAQret+32(FP),R8
JMPindexbytebody<>(SB)
TEXT·IndexByteString(SB),NOSPLIT,$0-32
MOVQs_base+0(FP),SI
MOVQs_len+8(FP),BX
MOVBc+16(FP),AL
LEAQret+24(FP),R8
JMPindexbytebody<>(SB)
//input:
//SI:data
//BX:datalen
//AL:bytesought
//R8:addresstoputresult
TEXTindexbytebody<>(SB),NOSPLIT,$0
//ShuffleX0aroundsothateachbytecontains
//thecharacterwe'relookingfor.
MOVDAX,X0
PUNPCKLBWX0,X0
PUNPCKLBWX0,X0
PSHUFL$0,X0,X0
...
src/internal/bytealg/index_amd64.s
#include"go_asm.h"
#include"textflag.h"
TEXT·Index(SB),NOSPLIT,$0-56
MOVQa_base+0(FP),DI
MOVQa_len+8(FP),DX
MOVQb_base+24(FP),R8
MOVQb_len+32(FP),AX
MOVQDI,R10
LEAQret+48(FP),R11
JMPindexbody<>(SB)
TEXT·IndexString(SB),NOSPLIT,$0-40
MOVQa_base+0(FP),DI
MOVQa_len+8(FP),DX
MOVQb_base+16(FP),R8
MOVQb_len+24(FP),AX
MOVQDI,R10
LEAQret+32(FP),R11
JMPindexbody<>(SB)
//AX:lengthofstring,thatwearesearchingfor
//DX:lengthofstring,inwhichwearesearching
//DI:pointertostring,inwhichwearesearching
//R8:pointertostring,thatwearesearchingfor
//R11:address,wheretoputreturnvalue
//Note:WewantleninDXandAX,becausePCMPESTRIimplicitlyconsumesthem
TEXTindexbody<>(SB),NOSPLIT,$0
...
笔者验证了一下 IndexByte 和自定义通过 for 循环实现建的差别:
funcBenchmarkIndexByte(b*testing.B){
b.Run("IndexByte",func(b*testing.B){
b.ReportAllocs()
fori:=0;i< b.N; i++ {
str := testdata.TwitterJsonOut
n := 0
k:=0for{
j:=strings.IndexByte(str[k:],']')
ifj< 0{
break
}
n++
k+=j+1
}
_=n
}
b.SetBytes(int64(b.N))
b.StopTimer()
})
b.Run("for",func(b*testing.B){
b.ReportAllocs()
str:=testdata.TwitterJsonOut
fori:=0;i< b.N; i++ {
n := 0fori:=0;i< len(str);i++{
ifstr[i]==']'{
n++
}
}
_=n
}
b.SetBytes(int64(b.N))
b.StopTimer()
})
}
结果如下:
BenchmarkIndexByte/IndexByte
BenchmarkIndexByte/IndexByte-123072980387.5ns/op7929621.19MB/s0B/op0allocs/op
BenchmarkIndexByte/for
BenchmarkIndexByte/for-125166632417ns/op213777.66MB/s0B/op0allocs/op
由结果可知,SIMD 的加速性能还是挺好的。不过,实际上如果 strings.IndexByte() 字符串很短 或 所查找的字符在字符串中大量存在的话,性能甚至会比 for 循环慢。这个可以自行验证一下。
5.7、 自定义SIMD优化
如果感兴趣,可以照着 Go 编译器里的汇编抄,慢慢尝试。github 上也有许多项目可以抄,比如:minio/sha256-simd
5.8、 随意跳转
这段代码个人觉得很有意思,虽然有缺陷,但不失为一次大胆的尝试。笔者另一篇掘金文章《关于 golang 错误处理的一些优化想法》 中有详细说明,实现原理类似 C 语言的栈溢出攻击,就是替换函数的 RET 返回地址。
测试代码如下:
funcTestTagTry0(t*testing.T){
deferfunc(){
fmt.Printf("1->")
}()
tag,err1:=NewTag()//当tag.Try(err)时,跳转此处并返回err1
fmt.Printf("2->")
iferr1!=nil{
fmt.Printf("3->")
return
}
deferfunc(){
fmt.Printf("4->")//由于的缺陷:这里 debug 下 defer 不内联,会执行;release 下 defer 内联,不会执行
}()
fmt.Printf("5->")
err2:=errors.New("err2")
tag.Try(err2)//这里err2!=nil,则会跳转到tag创建处的下一行指令执行,即fmt.Printf("2->")
fmt.Printf("6->")
return
}
测试结果:
#release下defer内联,不会输出4
2->5->2->3->1->
#debug下defer不内联,会输出4
2->5->2->3->4->1
5.9 调用其他 package 的私有函数
通过过摆脱 golang 编译器的一些约束,调用其他 package 的私有函数。如这篇文章《How to call private functions (bind to hidden symbols) in GoLang》。
上面 goid 的例子的最后,也讲了通过汇编使用 package 私有的类型,即 DATA ·runtime_g_type+0(SB)/8,$type·runtime·g(SB) ,这里不在重复。
5.10 提高 CGO 调用的性能
我们知道,CGO 和系统调用时,Go 语言需要把 goroutine 的调用栈切换回 g0 调用栈,并使用 g0 调用,整个过程性能损耗比较大。实际上,我们可以通过汇编适配 C 语言的 ABI 来直接调用 C 语言的函数,参考 github 下的这个库: petermattis/fastcgo。不过,这么做也有很大的局限性,比如导致栈溢出、因 goroutine 无法被抢占而影响 GC 性能等。
审核编辑 :李倩
-
寄存器
+关注
关注
31文章
5589浏览量
129063 -
计数器
+关注
关注
32文章
2306浏览量
97571 -
Go
+关注
关注
0文章
45浏览量
12517
原文标题:5、 有哪些有意思的使用场景
文章出处:【微信号:OSC开源社区,微信公众号:OSC开源社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
汇编指令基础知识
通信基础知识教程
汇编语言学习课件_微处理器基础知识
汇编基础知识教程之数据类型与寄存器
汇编基础知识教程之ARM汇编简介






 工商网监
工商网监
评论