 Auto-GPT是如何工作的?
Auto-GPT是如何工作的?

Auto-GPT 究竟是一个开创性的项目,还是一个被过度炒作的 AI 实验?本文为我们揭开了喧嚣背后的真相,并揭示了 Auto-GPT 不适合实际应用的生产局限性。
背景介绍
这两天,Auto-GPT,一款让最强语言模型 GPT-4 能够自主完成任务的模型,一夜成名,让整个 AI 圈疯了。短短八天时间,它就在 GitHub 上获得了惊人 Star 数量,目前已经突破 8 万,并吸引了无数开源社区的关注。
此前爆火的 ChatGPT,唯一不太好用的地方,就是需要人类输入 Prompt。而 Auto-GPT 的一大突破是,可以让 AI 自我提示,换句话说,AI 都完全不需要咱们人类了?
在为 Auto-GPT 狂欢的同时,我们也有必要退一步审视其潜在的不足之处,探讨这个「AI 神童」所面临的局限和挑战。
接下来,肖涵博士将和我们深入探讨Auto-GPT 究竟是一个开创性的项目,还是另一个被过度炒作的人工智能实验。
Auto-GPT 是如何工作的?
不得不说,Auto-GPT 在 AI 领域掀起了巨大的波澜,它就像是赋予了 GPT-4 记忆和实体一样,让它能够独立应对任务,甚至从经验中学习,不断提高自己的性能。
为了便于理解 Auto-GPT 是如何工作的,让我们可以用一些简单的比喻来分解它。
首先,想象 Auto-GPT 是一个足智多谋的机器人。
我们每分配一个任务,Auto-GPT 都会给出一个相应的解决计划。比如,需要浏览互联网或使用新数据,它便会调整其策略,直到任务完成。这就像拥有一个能处理各种任务的私人助手,如市场分析、客户服务、市场营销、财务等。
具体来说,想让 Auto-GPT 运行起来,就需要依靠以下 4 个组件:
1. 架构
Auto-GPT 是使用强大的 GPT-4 和 GPT-3.5 大型语言模型构建的,它们充当机器人的大脑,帮助它思考和推理。
2. 自主迭代
这就像机器人从错误中学习的能力。Auto-GPT 可以回顾它的工作,在以前的努力的基础上再接再厉,并利用它的历史来产生更准确的结果。
3. 内存管理
与向量数据库(一种内存存储解决方案)集成,使 Auto-GPT 能够保留上下文并做出更好的决策。这就像给机器人配备了长时记忆,可以记住过去的经历。
4. 多功能性
Auto-GPT 的文件操作、网页浏览和数据检索等功能使其用途广泛。这就像赋予机器人多种技能来处理更广泛的任务。
然而,这些诱人的前景可能还尚未转化为 Auto-GPT 真正可以实现的能力。
天价成本
想要在现实的生产环境中使用 Auto-GPT,首先面临的障碍便是其高昂的成本。
由于任务需要通过一系列的思维迭代来完成,为了提供最好的推理和提示,模型每一步通常都会用尽所有 token。
然而,GPT-4 的 token 并不便宜。根据 OpenAI 的定价,具有 8K 上下文窗口的 GPT-4 模型,对于提示部分,每 1000 个 token 收费 0.03 美元;而对于结果部分,每 1000 个 token 收费 0.06 美元。而 1000 个 token 大概可以换算成 750 个英文单词。
让我们分解思维链中每一步的成本,假设每个动作都用尽了 8000 个 token 的上下文窗口,其中 80% 是提示(6400 个 token),20% 是结果(1600 个 token)。
提示成本:6400 个 token x 0.03 美元/1000 个 token = 0.192 美元
结果成本:1600 个 token x 0.06 美元/1000 个 token = 0.096 美元
因此,每个 Step 的成本就是:0.192 美元 + 0.096 美元 = 0.288 美元
平均而言,Auto-GPT 完成一项小任务需要 50 个 step。
因此,完成单个任务的成本就是:50 个 step x 0.288 美元/step = 14.4 美元
VUEGPTTHOUGHTS:Let'sstartbycheckingifthereareanyupdatestoVueJS.Ifthereare,wecanupdatetothelatestversionandproceed.Otherwise,wecanmoveontocreatingtheTODOlistwebsiteapplication. REASONING:Startingwiththemostupdatedandstableversionoftheframeworkwillensureourprojecthasthelatestfeatures,bugfixesandisproperlysupported.CreatingtheTODOlistwebsiteapplicationisourprimarygoal,sowecanmoveontothatiftherearenoupdates. PLAN: -CheckforVueJSupdates -Updatetolatestversionifthereareupdates -Ifnoupdates,moveontocreatingtheTODOlistwebsiteapplication CRITICISM:None NEXTACTION:COMMAND=googleARGUMENTS={'input':'VueJSlatestversionupdate'} Enter'y'toauthorisecommand,'y-N'torunNcontinuouscommands,'n'toexitprogram,orenterfeedbackforVueGPT...
以 VueGPT 为例:这是一个 Auto-GPT 创建的 AI,旨在使用 Vue JS 创建网站应用程序,我们来看看它在思维链中的一个步骤,而且这还是一次就能出结果的情况,如果需要重新生成,成本会更高。
从这个角度来看,Auto-GPT 目前对大部分用户和组织来说,都是不现实的。
开发到生产的难题
乍一看,花 14.4 美元来完成一项复杂的任务,好像并无不妥。
举个例子,我们首先让 Auto-GPT 制作一份圣诞节食谱。然后,再找它要一份感恩节食谱的话,猜猜会发生什么?
没错,Auto-GPT 会按照相同的思维链从头再做一遍,也就是说,我们需要再花 14.4 美元才行。
但实际上,这两个任务在「参数」的区别应该只有一个:节日。
既然我们已经花了 14.4 美元开发了一种创建食谱的方法,那么再用花相同的钱来调整参数,显然是不符合逻辑的。
想象一下,在玩《我的世界》(Minecraft),每次都要从头开始建造一切。显然,这会让游戏变得非常无趣。
而这便暴露了Auto-GPT 的一个根本问题:它无法区分开发和生产。
当 Auto-GPT 完成目标时,开发阶段就完成了。不幸的是,我们并没有办法将这一系列操作「序列化」为一个可重用的函数,从而投入生产。
因此,用户每次想要解决问题时都必须从开发的起点开始,不仅费时费力,而且还费钱。
这种低下的效率,引发了关于 Auto-GPT 在现实世界生产环境中实用性的质疑,也突显了 Auto-GPT 在为大型问题解决提供可持续、经济有效的解决方案方面的局限性。
循环泥潭
不过,如果 14.4 美元真的能解决问题,那么它仍然是值得的。
但问题在于,Auto-GPT 在实际使用时,经常会陷入到死循环里……


那么,为什么 Auto-GPT 会陷入这些循环?
要理解这一点,我们可以把 Auto-GPT 看作是依赖 GPT 来使用一种非常简单的编程语言来解决任务。
解决任务的成功取决于两个因素:编程语言中可用的函数范围和GPT 的分治法能力(divide and conquer),即 GPT 能够多好地将任务分解成预定义的编程语言。遗憾的是,GPT 在这两点上都是不足的。
Auto-GPT 提供的有限功能可以在其源代码中观察到。例如,它提供了用于搜索网络、管理内存、与文件交互、执行代码和生成图像的功能。然而,这种受限的功能集缩小了 Auto-GPT 能够有效执行的任务范围。
此外,GPT 的分解和推理能力仍然受到限制。尽管 GPT-4 相较于 GPT-3.5 有了显著的改进,但其推理能力远非完美,进一步限制了 Auto-GPT 的解决问题的能力。
这种情况类似于尝试使用 Python 构建像《星际争霸》这样复杂的游戏。虽然 Python 是一种强大的语言,但将《星际争霸》分解为 Python 函数极具挑战性。
本质上,有限功能集和 GPT-4 受限的推理能力的结合,最终造成了这个循环的泥潭,使 Auto-GPT 在许多情况下无法实现预期的结果。
人类与 GPT 的区别
分治法是 Auto-GPT 的关键。尽管 GPT-3.5/4 在前任基础上有了显著的进步,但在使用分治法时,其推理能力仍然无法达到人类水平。
1. 问题分解不充分
分治法的有效性在很大程度上取决于将复杂问题分解为较小、易于管理的子问题的能力。人类推理通常可以找到多种分解问题的方法,而 GPT-3.5/4 可能没有同样程度的适应性或创造力。
2. 识别合适基本案例的难度
人类可以直观地选择适当的基本案例以得到有效的解决方案。相比之下,GPT-3.5/4 可能难以确定给定问题的最有效基本案例,这会显著影响分治过程的整体效率和准确性。
3. 问题背景理解不充分
虽然人类可以利用其领域知识和背景理解来更好地应对复杂问题,但 GPT-3.5/4 受其预先训练的知识所限,可能缺乏用分治法有效解决某些问题所需的背景信息。
4. 处理重叠子问题
人类通常可以识别出解决重叠子问题时,并有策略地重用先前计算过的解决方案。而 GPT-3.5/4 可能没有同样程度的意识,可能会多次冗余地解决相同的子问题,从而导致解决方案的效率降低。
向量数据库:过度的解决方案
Auto-GPT 依赖向量数据库进行更快的 k-最近邻(kNN)搜索。这些数据库检索先前的思维链,并将它们融入到当前查询上下文中,以便为 GPT 提供一种记忆效果。
然而,考虑到 Auto-GPT 的约束和局限性,这种方法被批评为过度且不必要地消耗资源。其中,反对使用向量数据库的主要论点源于与 Auto-GPT 思维链相关的成本约束。
一个 50 步的思维链将花费 14.4 美元,而一个 1000 步的链将花费更多。因此,记忆大小或思维链的长度很少超过四位数。在这种情况下,对最近邻点进行穷举搜索(即 256 维向量与 10000 x 256 矩阵之间的点积)被证明是足够高效的,用时不到一秒钟。
相比之下,每个 GPT-4 调用大约需要 10 秒钟来处理,所以实际上限制系统处理速度的是 GPT,而非数据库。
尽管在特定场景下,向量数据库可能在某些方面具有优势,但在 Auto-GPT 系统中实现向量数据库以加速 kNN “长时记忆”搜索似乎是一种不必要的奢侈和过度的解决方案。
智能体机制的诞生
Auto-GPT 引入了一个非常有趣的概念,允许生成智能体(Agent)来委派任务。
虽然,这种机制还处于初级阶段,其潜力尚未被充分挖掘。不过,有多种方法可以增强和扩展当前的智能体系统,为更高效、更具动态性的互动提供新的可能性。
一个潜在的改进是引入异步智能体。通过结合异步等待模式,智能体可以并发操作而不会阻塞彼此,从而显著提高系统的整体效率和响应速度。这个概念受到了现代编程范式的启发,这些范式已经采用了异步方法来同时管理多个任务。
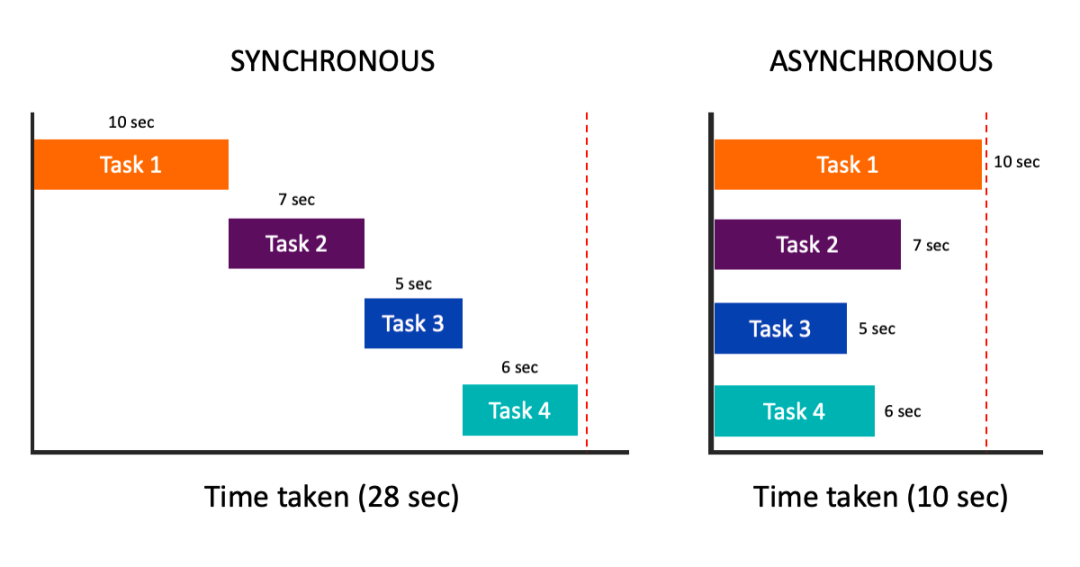
图源:https://scoutapm.com/blog/async-javascript
另一个有前景的方向是实现智能体之间的相互通信。通过允许智能体进行通信和协作,它们可以更有效地共同解决复杂问题。这种方法类似于编程中的 IPC 概念,其中多个线程/进程可以共享信息和资源以实现共同目标。
生成式智能体是未来的方向
随着 GPT 驱动的智能体不断发展,这种创新方法的未来似乎十分光明。
新的研究,如「Generative Agents: Interactive Simulacra of Human Behavior」,强调了基于智能体的系统在模拟可信的人类行为方面的潜力。
论文中提出的生成式智能体,可以以复杂且引人入胜的方式互动,形成观点,发起对话,甚至自主计划和参加活动。这项工作进一步支持了智能体机制在 AI 发展中具有前景的论点。
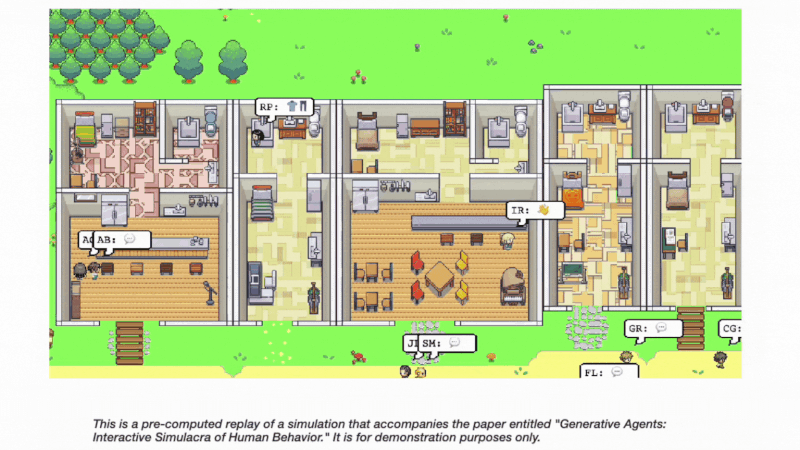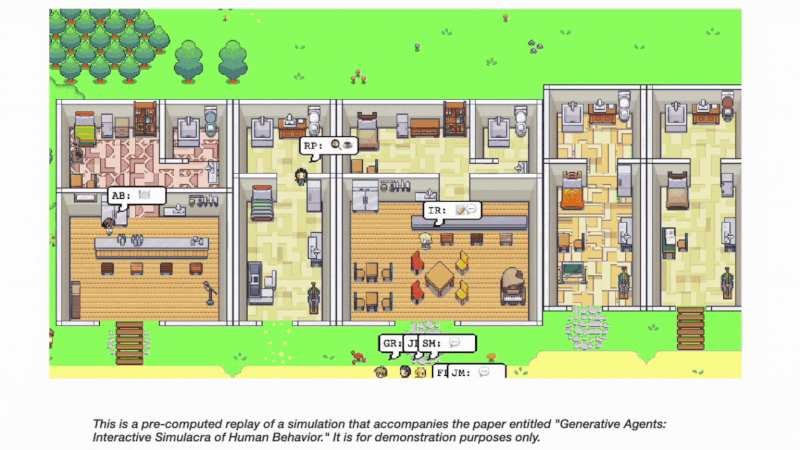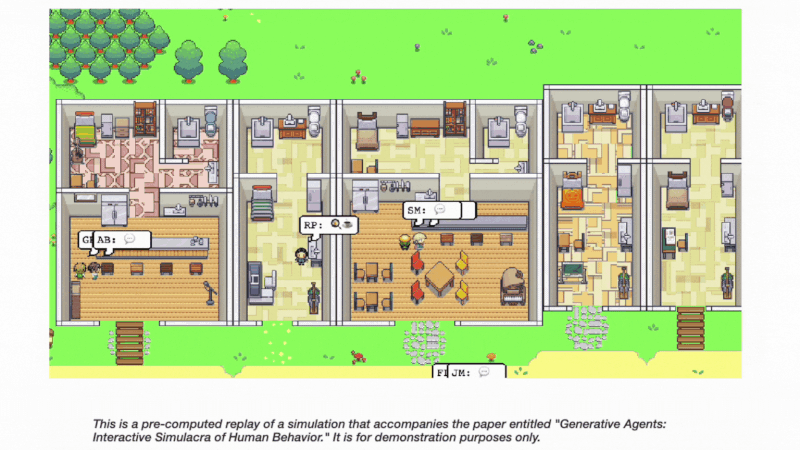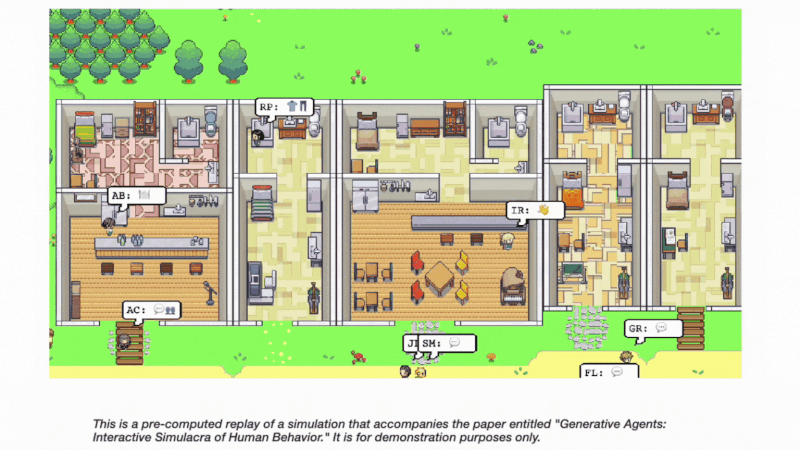
通过拥抱面向异步编程的范式转变并促进智能体间通信,Auto-GPT 可以为更高效和动态的问题解决能力开辟新可能。
将《生成式智能体》论文中引入的架构和交互模式融入其中,可以实现大型语言模型与计算、交互式智能体的融合。这种组合有可能彻底改变在 AI 框架内分配和执行任务的方式,并实现更为逼真的人类行为模拟。
智能体系统的开发和探索可极大地促进 AI 应用的发展,为复杂问题提供更强大且动态的解决方案。
总结
总之,围绕 Auto-GPT 的热议引发了关于 AI 研究现状以及公众理解在推动新兴技术炒作中的作用的重要问题。
正如上面所展示的,Auto-GPT 在推理能力方面的局限性、向量数据库的过度使用以及智能体机制的早期发展阶段,揭示了它距离成为实际解决方案还有很长的路要走。
围绕 Auto-GPT 的炒作,提醒我们肤浅的理解可能让期望过高,最终导致对 AI 真正能力的扭曲认识。
话虽如此,Auto-GPT 确实为 AI 的未来指明了一个充满希望的方向:生成式智能体系统。
最后,肖涵博士总结道:「让我们从 Auto-GPT 的炒作中吸取教训,培养关于 AI 研究的更为细致和知情的对话。」
这样,我们就可以利用生成式智能体系统的变革力量,继续推动 AI 能力的边界,塑造一个技术真正造福人类的未来。
审核编辑 :李倩
-
语言模型
+关注
关注
0文章
575浏览量
11384 -
智能体
+关注
关注
1文章
632浏览量
11667 -
ChatGPT
+关注
关注
31文章
1609浏览量
10463
原文标题:碾压ChatGPT、自主完成任务、Star数超8万的Auto-GPT,是炒作还是未来?
文章出处:【微信号:OSC开源社区,微信公众号:OSC开源社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
ADXL345配置成AUTO_SLEEP模式为什么无法进入正常工作?
使用TC21x的GPT实现1m计时器执行定时任务,怎么配置GTM和GPT?
GPT定时器基本知识详解
EPIT定时器与GPT定时器简单介绍
GPT高精度延时定时器简介
GPT2模块的相关资料推荐
GPT/GPT-2/GPT-3/InstructGPT进化之路
Auto GPT横空出世,力推算力设施
微软提出Control-GPT:用GPT-4实现可控文本到图像生成!

一文详解GPT tokenizer 的工作原理




评论