 GTC23 | China AI Day 演讲回顾:NVIDIA CUDA 技术助力网易瑶台神经隐式曲面建模 20 倍加速
GTC23 | China AI Day 演讲回顾:NVIDIA CUDA 技术助力网易瑶台神经隐式曲面建模 20 倍加速

NVIDIA GTC 2023 春季大会成功落下帷幕,超过 30 万名注册用户参与到 650 多场演讲中,深入了解最新的 AI 技术和丰富的应用场景。
在本届 GTC 特别活动 China AI Day 上,网易伏羲视觉计算负责人李林橙以《NVIDIA CUDA 技术助力网易瑶台神经隐式曲面建模 20 倍加速》为题,分享了 AIGC 趋势下其创新性的神经隐式曲面建模解决方案,以及项目过程中的实践经验和心得。以下为演讲内容概要。
网易瑶台项目背景
网易瑶台是网易伏羲旗下沉浸式活动平台,致力于用人工智能和科技创新打造数字空间新模式。网易瑶台在底层的 AI 算法上,支持虚拟角色、虚拟场景的创建驱动;在底层的平台上,有 ACE 分布式引擎来支持达到万人级别的同屏实时互动,同时借助网易雷火游戏的美术积累,实现业内一流的 3D 美术制作和渲染管线。
作为一个提供一站式元宇宙营销服务的元宇宙产品,网易瑶台已经被广泛地应用于会议活动、虚拟展会、在线展厅、社交娱乐等多元丰富的场景,为美国、日本、新加坡等一百多个国家的用户举办累积两百余场沉浸式虚拟活动,获得了客户的一致好评。
图一
在这个过程中,我们了解到客户的一个刚需是场景的数字化建模。一部分客户希望重新打造一个虚拟场景,但更多的时候客户希望复刻一个真实世界的场景,在虚拟的元宇宙中做到数字孪生。如图一所示,左边是网易瑶台与河南省文化和旅游厅联合推出的三维虚拟空间“元豫宙”之黄帝故里场景案例,我们运用数字科技复刻了物理世界场景,把黄帝故里等河南文旅 IP 景区重现在以网易瑶台为数字基座的数字空间;右边是浙江大学求是会议厅,我们也在网易瑶台里做了一个 1:1 的数字孪生复刻。这样的需求很多,但是复刻的过程一方面依赖很多实地测绘,需要现场拍很多照片和测量;另一方面也需要很大的人工工作量,用建模软件一步一步地雕刻出一个个场景,然后把它们组合起来。这是一个很大的工作量,也不利于我们做规模化的数字孪生。
所以引出了网易瑶台想要做到的方案,即如何快速便捷地建模数字化场景。我们想让使用网易瑶台的用户用手机拍摄物体,能够自动化且快速地做数字化建模,并且导入网易瑶台的云会场,这是这个项目希望实现的目标。
融合 NVIDIA instant-ngp 和 NeuS 优势的
神经隐式曲面建模方案
第二部分介绍一下我们奔着这个目标,做了怎样的技术选型。从技术的角度,这是一个多视角三维场景重建的问题,希望从多视角照片中重建高精度的 3D 模型。这个方案的采集成本比较低,只需要智能手机就可以,适用于大众来进行拍摄,同时做自动化的建模来提升 3D 内容数字孪生的生产效率。但是技术难点在于,和常见的多视角 3D 场景重建的各种方案不同的是,网易瑶台的要求略有些特殊,要求高质量 Mesh 与贴图,并且要求高效率,不让用户等的时间过长。目前已有的常见算法在效率和精度上通常无法兼顾。
图二
3D 重建算法的本质都是输入 2D 图像,先计算相机位姿,之后再进一步重建 3D 模型。模型的表示可以是隐式的,比如使用 SDF、体密度来表示,也可以是显式的,用传统的点云、深度图、Mesh 这些方式来表示。
这里我们对现有算法作了一个简单的分类,如图二。最左边,近年来比较经典的一类方法是神经体渲染,代表方法是 NeRF,用 MLP 来表示神经隐式场。对用户输入的每一个三维点,从每一个方向的观察,都输出一个 RGB 和体密度,每一个点的颜色通过沿着一条射线积分 RGB 和体密度来得到。在这个方向上,去年 NVIDIA instant-ngp 也是完成了特别显著的加速优化。
图的中间示意,第二类是神经隐式曲面,把经典的体密度表示,换成了用 SDF 表示的方式,每个点表示了当前这个点到空间中的三维曲面的距离。这种表示方式可以获得更加平滑的曲面,代表方法是 IDR 和 NeuS。
图的右侧,第三类是从传统的 MVS 方法发展过来,先用传统的特征匹配或者用神经网络来预测一个深度图,然后再将多帧的深度图进行融合得到三维的曲面,这几年比较好用的方式其中之一是 CasMVSNet。
下面我将逐一介绍网易瑶台在这三个方向上的探索以及结果。
一,NeRF。NVIDIA instant-ngp 在 NeRF 的基础上提出了多尺度的哈希编码。传统的编码是用正余弦编码来表示每一个顶点频域分量,瑶台的方案,是用一个网络去生成哈希编码来表达空间中每一个位置,同时也使用了球谐编码,这种方式做到了显著的加速。在实现的过程中,还用了 NVIDIA 的 tiny-cuda-nn 加速技术。把这些技术整合在一起之后,在训练时间上从 NeRF 的 10 个小时大幅度提升到了 10 分钟之内,可以做到高质量的 2D 视角生成。但不足之处在于,只能输出相对低质量的 mesh 和纹理。本质原因在于,这种方式是为了 2D 的视角合成而不是为了 3D 的 mesh 生成设计的。
二,NeuS。用 SDF 取代体密度渲染,得到了更高的 mesh 重建的精度。它把场景分成了球内和球外,在球内用 SDF 生成一个前景的神经隐式场,在球外还是沿用了 NeRF 生成比较好的 2D 背景,编码还是正常的正余弦编码。这个方法的优势是可以得到一个很高质量的 mesh,同时因为 mesh 比较精细,纹理对应的也可以是高质量的纹理,顺便也可以做到比较高质量的 2D 视角合成。但是它的训练时间很慢,和标准的 NeRF 一样,训练时间也要 10 个小时以上,同时需要每张图手动截取物体边框作为输入。
三,深度图融合的方式,代表方法是 CasMVSNet。它是通过多尺度级联的深度估计网络,先预测低分辨率的深度图,再逐渐增加分辨率到高分辨率的深度图,以达到预测速度和预测精度之间的 tradeoff。然后在多视角深度融合中用一致性过滤噪点,得到一个最终的 3D 点云。这个方法借助多尺度深度图融合之后,推理时间可以做到两分钟,是很快的速度,同时能输出高质量的点云。但因为是从深度图融合后过滤的,被过滤掉的地方就变成了空洞。简单来说,在准的地方很准,但是在有些区域是没有信息的,即变成空洞。如果让用户拍出这样的结果直接放到元宇宙的应用里,不能满足用户需求。而且深度图的方法还需要有数据集的监督训练,也是一个比较受限制的条件。

图三
总结一下,如图三所示。前面这几类比较经典的方法,NeRF 是开山鼻祖,运行时间很长,但是给后续的方法提供了一个完全全新的思路。NVIDIA instant-ngp 在 NeRF 的基础上做到了大幅的加速,做到了很理想的运行时间,但是还是沿用了 NeRF 的 2D 视角合成任务,没有专门去关注 3Dmesh 生成任务,和我们的需求没有完全匹配。NeuS 针对高质量的 3Dmesh 做了很好的优化,但是它的运行时间又回到了 10 个小时以上。CasMVSNet 速度非常快,但是生成的 3D 点云有些空洞。
图四
针对这个技术现状,我们分别提取 instant-ngp 和 NeuS 的优势做了整合,设计了我们自己的整体流程(如图四所示)。这个流程在大的框架上还是标准的模块,如视频抽帧、位姿估计、边框估计、物体分割、到神经渲染重建、纹理贴图等模块。下方的图是这个流程重建出来的部分结果。
神经隐式曲面建模方案工作流程
下面我们针对每个模块展开具体的介绍。首先介绍和神经隐式场无关的位姿估计和预处理的模块。
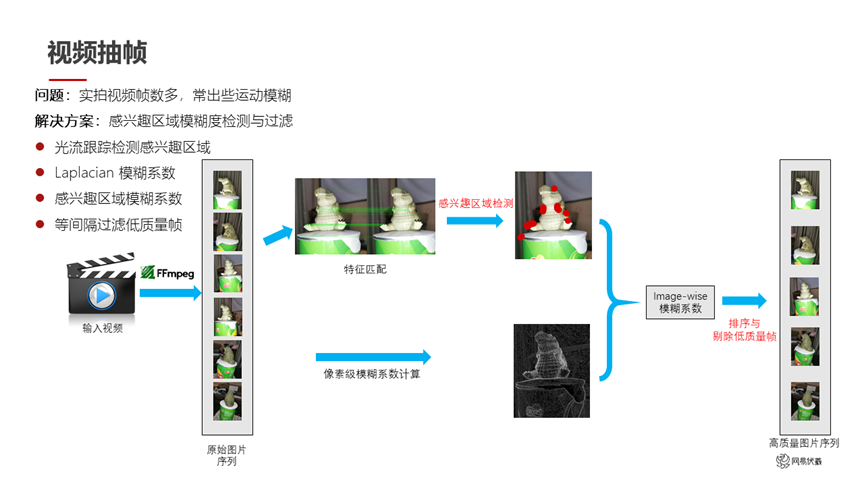
图五
如图五所示,我们输入的是一个用户拍摄的视频,视频帧数很多,而且会出现一些运动模糊。我们希望筛选出高质量帧,踢掉模糊帧,保留视角相对合适的帧。因为用户拍的内容一般是针对感兴趣的区域进行拍摄,所以我们针对用户拍摄的图片做特征匹配之后,能够提取出用户感兴趣的区域。同时我们用模糊检测的方法预测每一帧的模糊系数,从而剔除一些帧,得到高质量的图片序列。
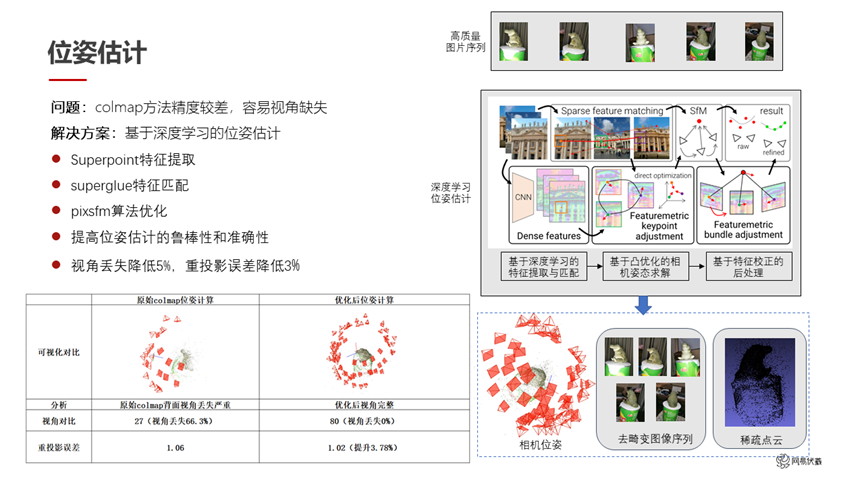
图六
在位姿估计方面,传统的 colmap 已经是比较成熟而且比较好用的方法。但是它也存在两点问题,一是估计位姿的精度会差一些,二是视角容易缺失。我们用了一系列方法去优化这两个问题。具体来说,我们使用 Superpoint 作为特征提取,使用 Superglue 作为特征匹配,使用 Pixsfm 作为算法的优化。这样在特征的提取、匹配、优化的过程中各自做了一些改进和替换之后,我们提高了位姿估计的鲁棒性和准确性。如图六所示,左下角是原始的 colmap 和我们优化之后的对比,可以看到右侧的结果位姿的丢失比较少。同时我们的重投影误差也有了 3.7%的提升,从 1.06 提升到了 1.02。

图七
在物体边框估计方面,如果直接引用 NVIDIA instant-ngp 的话,物体边框的估计出来会比较大。这里我们用位姿估计和稀疏的 3D 点估计结果去缩小这个边框。首先进行噪点的过滤,然后估计出物体的中心:用最小二乘法计算各个视角交点,就可以认为是用户感兴趣的物体的中心。之后计算各个视角的最小深度,把各相机沿主轴平移到这个最小深度上,平移后的相机包围框就是我们缩小之后的物体边框。如图七,右边是一个对比,原始的 NVIDIA instant-ngp 是绿色框,我们把它优化到了红色框里,这样能减少一些计算资源。
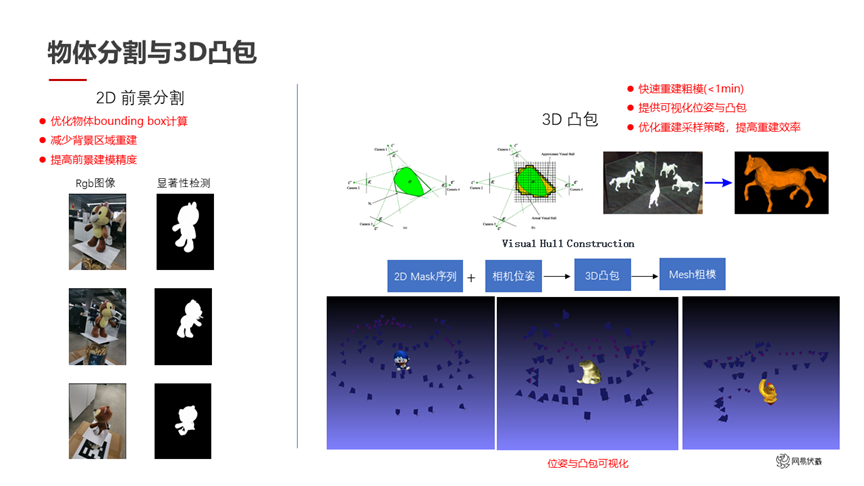
图八
在物体分割方面,我们首先利用显著性检测,对用户图片进行前景分割,因为用户拍摄的画面中间那个东西,大概率是他感兴趣的东西,而且是一个独立的物体。我们在优化显著性检测之后,得到了左边的结果。这个结果还能进一步互相校正,因为我们已经知道了每帧的位姿。检测了 2D 分割后,我们可以根据位姿投影得到 3D 分割,也就是 3D 凸包,比如图八右边的展示。这些 3D 凸包一方面可以给用户实现快速的预览功能,只要不到一分钟的时间就可以生成 3D 凸包,这些凸包相当于一个粗糙的模型。看到这个模型之后,用户就知道后面的进一步细化会基于目前的这个粗糙状态下进行,提前有一个预览。同时这些 3D 凸包可以互相校正,一些 2D 显著性检测结果有分割错误的地方,在 3D 凸包上可以纠正回来。
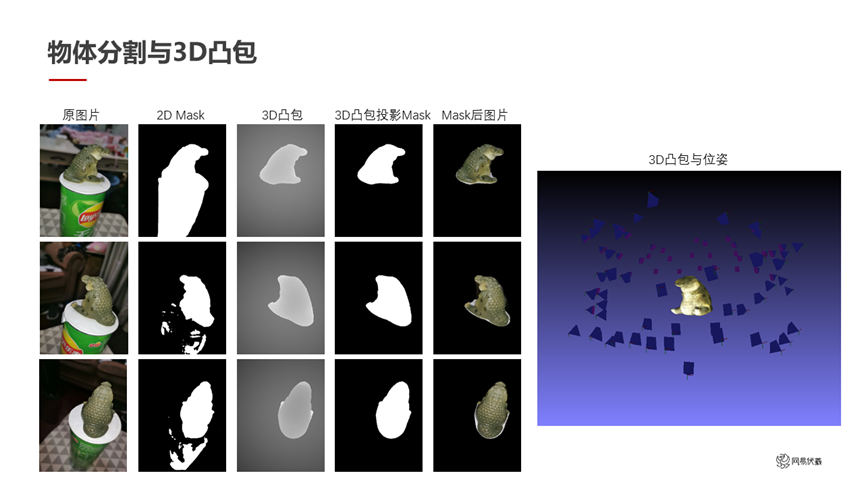
图九
图九是互相校正的例子。从左到右每一列依次是原图、2D 显著性分割的 mask,做了 3D 凸包的结果,互相校正之后得到的比较精确的 mask、最后是 mask 之后的图片。右边是一个粗糙的 3D 凸包,其实对于一些要求不高的物体来说,这个 3D 凸包可以直接作为重建结果使用,也可以指导后续的优化。
建模速度从 10 小时优化到了 10-20 分钟
下面介绍一下我们对神经隐式曲面建模,进行了一些加速的操作(如图十所示)。

图十
整体来说,我们融合了 NVIDIA instant-ngp 和 NeuS 两个方案的优点,同时借助 CasMVSNet 做先验的指导。主要做了两个方面工作,一方面是对编码进行优化和网络压缩,另一方面是调整训练策略。下面分别展开讨论。
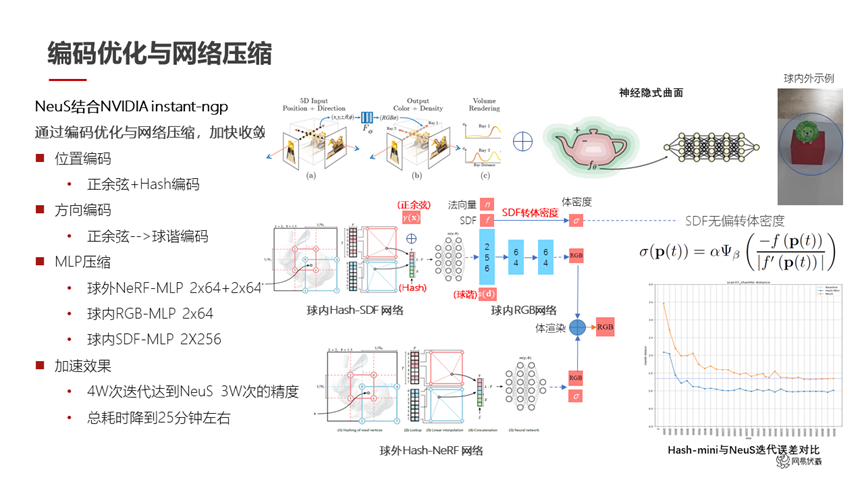
图十一
针对编码优化和网络压缩(如图十一所示),我们做了以下工作:
首先位置编码还是正常的正余弦编码,再加上了 NVIDIA instant-ngp 的哈希编码。这边我们有一个操作:NVIDIA instant-ngp 把编码改成了哈希编码,我们在它的基础上叠加了正余弦编码 concat 上去。这个操作其实在数学上并不是一个特别优雅的方案,但是我们实验下来能够解决哈希编码的一些问题。比如说哈希编码会带来一些空洞问题,通过这个正余弦编码的叠加可以很大程度上的缓解。方向编码我们沿用了 NVIDIA instant-ngp 的球谐编码。在整体的 MLP 上,我们使用 NeuS 的 SDF 形式来表示三维场景,然后对 NeuS 的 MLP 进行了很大幅度的压缩。球外是 2*64 这样的小网络,球内也是 2*64 和 2*256 这样比较快速的网络。
经过一系列的优化之后,我们这个小网络的四万次迭代就达到了 NeuS 这个大网络的三十万次迭代的精度。右下角图里,橙色的线是 NeuS 的迭代误差,蓝色的线是我们的迭代误差。同样的迭代误差下,我们用比较快的速度达到了 NeuS 相同的结果,总耗时也降到了 25 分钟左右。
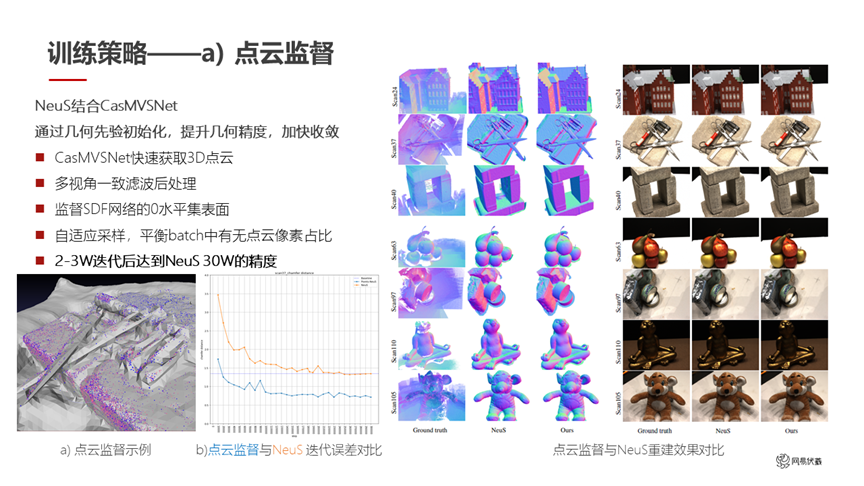
图十二
在训练策略上,我们首先借助 CasMVSNet 做点云的监督(如图十二所示)。我们先通过 CasMVSNet 得到一个比较稀疏的点云,再对这个稀疏点云进行多视角一致性滤波,得到一个完成后处理的结果。这个结果可以用于监督 SDF 网络训练过程中的采样,在有这个点云的附近多采一些点,在远离这些点云的地方可以少采一些点,因为点云大概率代表了实际的 3D 网格就在它附近。同时我们做了一个自适应的采样,平衡每一个 batch 中点云像素的占比,因为点云是稀疏排布的,部分地方没有点云。
在以上操作之后,我们在两到三万次迭代后达到了 NeuS 三十万次迭代的精度。如图十二显示,左下角这张图里,蓝色是我们用点云监督之后的结果,黄色是 NeuS 的原始结果。我们在很快的速度下达到了 NeuS 同样精度的水平。右边是我们用了点云监督之后和 NeuS 的重建结果对比,除了速度大幅提高之外,我们在精度上也有了一定的提高。比如第一行房子的屋顶上,我们的结果在屋顶上的凹陷就没有了,但是 NeuS 的结果还有;在第四行的苹果上,最上面那个苹果我们也得到更精确的细节。
我们的第二个策略是做了多尺度和多视角的监督(如图十三所示)。多尺度是一个比较容易想到的方案:用图像金字塔进行重建,先做一个低分辨率的结果,然后逐渐扩大得到高分辨率的结果。这种方案可以增强局部的连续性,而且总的迭代次数减少为 NeuS 的 43%,进一步提升了计算速度。

图十三
如图十三所示,右上角是我们在原图和二分之一图训练的一个对比。我们还做了多视角的监督。单步多视角是指我们在训练时的 batchsize 可以设得很大,因为我们前面做了很多操作,网络很小,batchsize 可以从 512 扩大到 2560 来尽量加快训练速度。但是如果直接扩大 batchsize 会导致空洞的增多,就像右下角的第三个图片,在白色的盆上出现了空洞。我们的做法是在单步训练中使用 10 个视角。原来是每个 step 在一张输入图片上采一个 batch 的点去做训练,我们改成了每个 step 从 10 个视角去采样,在 10 张图上总共采样这么多点去做训练。这种方式可以避免训练过程中的空洞,比如右下角最右边这张图,用 10 个视角监督之后白色的盆上不再有这些空洞。相比小的 batch,我们用 17 分钟就可以达到 NeuS 用 10 个小时的精度。
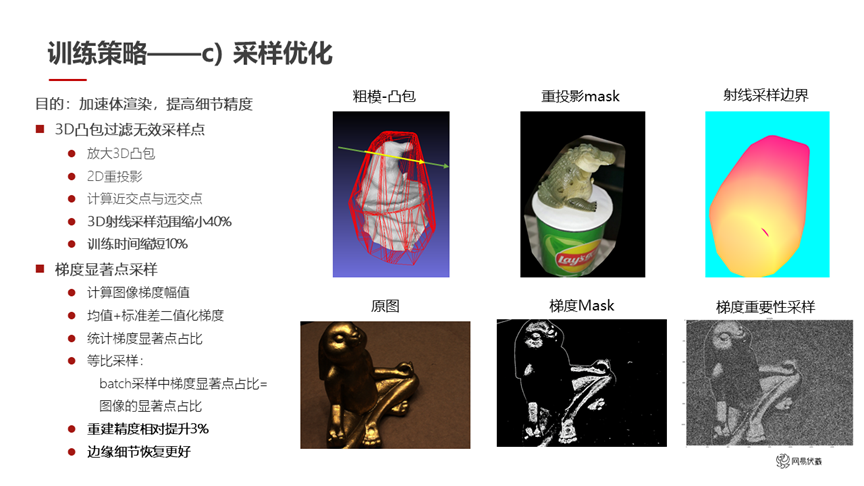
图十四
我们还做了采样的优化(如图十四所示)。这部分目标是加速体渲染,提高细节的精度。因为我们有了一个比较精确的 3D 凸包,它可以过滤无效的采样点,所以基于这个 3D 凸包和 2D 重投影,就可以算出来每个射线在 3D 凸包内的近交点和远交点,那么我们采样的范围只需要在凸包内部就可以。采样范围直接缩小 40%,训练时间也缩短了 10%。
另外我们做了梯度显著点采样。考虑到做采样的时候,可能出问题的更多是在物体的边缘附近,我们希望在物体边缘多采一些点,在物体内部少采一些点。于是我们先统计梯度的显著点,然后再根据这些显著点去做采样。同时我们做了等比采样,batch 采样中显著点的占比要等于图像中的显著点占比。通过这个步骤重建精度进一步提升了 3%。因为边缘的细节做得更好,非边缘梯度较弱的地方简单采样也没有太大问题,所以进一步提高了精度。
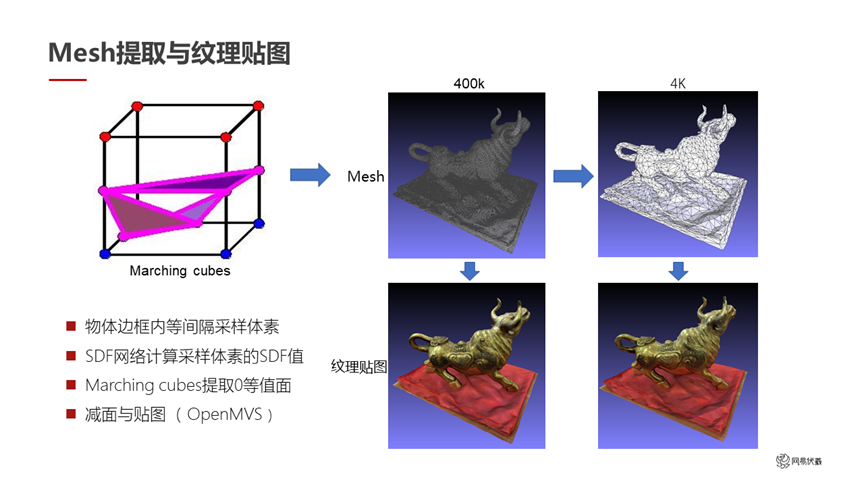
图十五
做了这一系列工作之后,最后把 SDF 转成 mesh 和纹理是比较常规的操作,如图十五所示。我们直接计算每一个采样体素的 SDF 值,用 marching cubes 提取零等值面,就直接输出了 3D mesh。在这个 mesh 上,我们借助 OpenMVS 做减面和贴图操作。右边这组图里最初输出的是 40 万面的 mesh,减面之后变成了 4000 面的 mesh。减面之后的 mesh 比较适合放在游戏引擎里去做元宇宙的应用。下面是两种方式的纹理贴图的对比,虽然减到了 4000 面,但是视觉效果看起来。这是我们最终输出的小体积的重建结果,最后我们把它放到了网易瑶台产品里。

图十六
经过前面这些操作之后,我们总结一下目前达到的状态。在 NVIDIA instant-ngp 和 tiny-cuda-nn 的帮助下,网易瑶台神经隐式曲面建模的速度从一开始的 10 个小时,优化到了 10 到 20 分钟。这个速度在用户的使用过程中是可以接受的。

图十七
图十七是我们重建精度的对比。我们和一个商业软件 RealityCapture 做了对比。
RealityCapture 是一个传统的基于特征匹配做 MVS 重建的算法。上面的是网易瑶台的输出,下面的是 RealityCapture 的输出。在视角不丢失的情况下,两个方法的精度都是很好的。比如这个鳄鱼或者最左边的熊,在看得到或者说视角没丢的那半边其实是可以的,但视角丢了的那半边没有重建出来,而且会有一些噪声导致在视角丢失的时候连到很大的区域上去。这种精度的结果就给人工修复带来很大的工作量。相比之下我们的结果重建出来就可以直接放到网易瑶台里使用。这是另外的一个优势,除了视角丢失需要修复之外,我们在重建成功的区域的精度上也有一些优势。
小结

图十八
以上是网易瑶台神经隐式曲面建模项目目前的进展。后续我们希望持续地提升建模的质量和效率,进一步提升纹理贴图的质量。同时 NVIDIA 在 Text-to-3D 方面做了一个很好的榜样,我们后面会和 NVIDIA 一起探索 Text-to-3D 技术,基于大模型进行文本生成三维模型,从而让用户更快的生成更多数字孪生的物体和场景,放到网易瑶台这个数字孪生应用中。
注:本文字实录由网易伏羲语音识别技术辅助提供。
本文署名作者:

李林橙
网易伏羲视觉计算负责人,浙江大学校外导师,专注计算机视觉研究。

张永强
网易伏羲视觉计算组,人工智能研究员,研究方向为神经渲染与多视角三维重建。
彩蛋:
近期,在计算机视觉和模式识别领域的顶级学术会议 CVPR 中,网易瑶台 2 篇 3D 重建相关技术论文成功入选。感兴趣的朋友们可以查阅进一步了解相关信息:
[1] Towards Unbiased Volume Rendering of Neural Implicit Surfaces with Geometry Priors, CVPR 2023
[2] NeFII: Inverse Rendering for Reflectance Decomposition with Near-Field Indirect Illumination, CVPR 2023
扫描海报二维码,或点击“阅读原文”,即可观看 NVIDIA 创始人兼首席执行官黄仁勋 GTC23 主题演讲重播!
原文标题:GTC23 | China AI Day 演讲回顾:NVIDIA CUDA 技术助力网易瑶台神经隐式曲面建模 20 倍加速
文章出处:【微信公众号:NVIDIA英伟达】欢迎添加关注!文章转载请注明出处。
-
英伟达
+关注
关注
23文章
4128浏览量
99776
原文标题:GTC23 | China AI Day 演讲回顾:NVIDIA CUDA 技术助力网易瑶台神经隐式曲面建模 20 倍加速
文章出处:【微信号:NVIDIA_China,微信公众号:NVIDIA英伟达】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
[VirtualLab] 平面和曲面标准具的建模
丽台科技携NVIDIA专业视听方案亮相InfoComm China 2026
NVIDIA GTC 2026展示推动物理AI时代的虚拟世界
NVIDIA携手微软加速机器人和物理AI的发展
神雲科技于GTC 2026展示一站式解决方案与弹性NVIDIA MGX,加速次世代AI发展
NVIDIA携手全球工业软件巨头构建AI智能体加速设计与工程开发流程
研华科技受邀亮相NVIDIA GTC 2026
NVIDIA加速计算平台助力从地球到太空的AI应用
益登科技携手生态伙伴亮相NVIDIA GTC 2026

益登科技邀您相约NVIDIA GTC 2026
NVIDIA CEO 黄仁勋与全球技术领导者在 GTC 2026 大会共话 AI 时代

NVIDIA CUDA Tile的创新之处、工作原理以及使用方法




评论