 一种用于AI视觉处理芯片的验证加速方案
一种用于AI视觉处理芯片的验证加速方案

介绍
本文中所涉及的AI边缘推断视觉处理芯片的实际用例都较为复杂,而且也需要牵扯到多个模块参与,例如摄像头输入、多通道数据的媒体编解码、图像处理、多显示支持等。要去协调这么多的模块,还要将它们与神经网络算法结合构建用例。
由于对系统中各个硬件要素的协调调度要求较多,AI视觉处理芯片需要更多使用固件去进行测试,这对于从IP/子系统层的测试用例到系统层的移植、以及在早期阶段获得较为准确的性能数据和功耗数据都提出了要求。这篇论文提供了一个作者在功能、性能和功耗这三个方面的硬件加速验证方案。
问题阐述
不同于常见的SoC在数据传输和控制上的测试方案,AI视觉处理芯片往往需要结合多个高带宽的多媒体控制器发起多个数据帧,模拟真实应用。而这么大的数据处理量,仿真往往会受制于仿真性能无法有较好的表现,所以在AI芯片验证方面,如果想要测试真实场景,那么就需要将固件在硬件加速器(emulator)上去处理。
由于功能、性能、功耗三个方面的验证在工具层面都缺少统一的平台做处理,而且不同形式的测试向量和方法学也让这些测试场景无法做到自动化映射。从工程实现角度考虑,一个需求是把功能测试的数据能够给到性能分析和功耗评估,另外一个需求是将IP/子系统层面的测试用例能够给到SoC层面测试。
功能验证方案
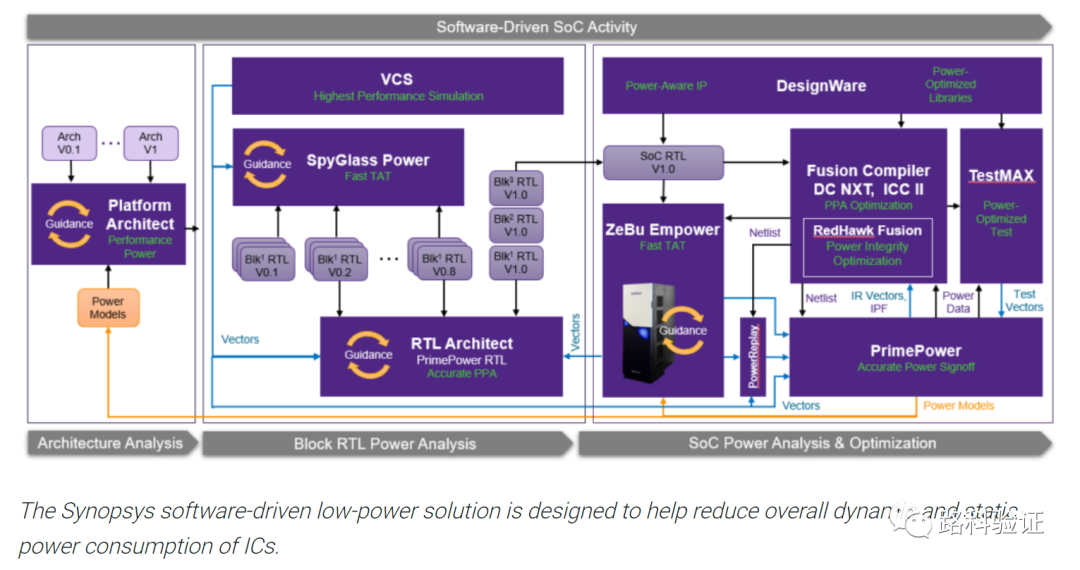
下方给出了在采用固件验证的情况下的测试方案。固件在早期验证中,可能使用的是例如SystemC/C++这类的纯软件测试平台,在此基础上他们可以提供早期的固件和十六进制文件(在后期的硬件加速测试中使用)。同时,在IP/子系统硬件加速测试中,可以根据测试文件(二进制文件和log文件)做后处理继而获得测试中的硬件配置数据和图形文件。
在接下来的SoC emulation,可以将从早期软件测试中固件、IP/子系统emulation中提取的硬件配置、图形文件共同作为SoC测试中的元素,让他们用来尽可能实现从IP/子系统到SoC的测试场景移植。 接下来可以利用emulator中的总线监测组件,获得总线传输数据,并将这些数据信息交由Python脚本去做处理,以便达到数据比较、性能监测等目的。
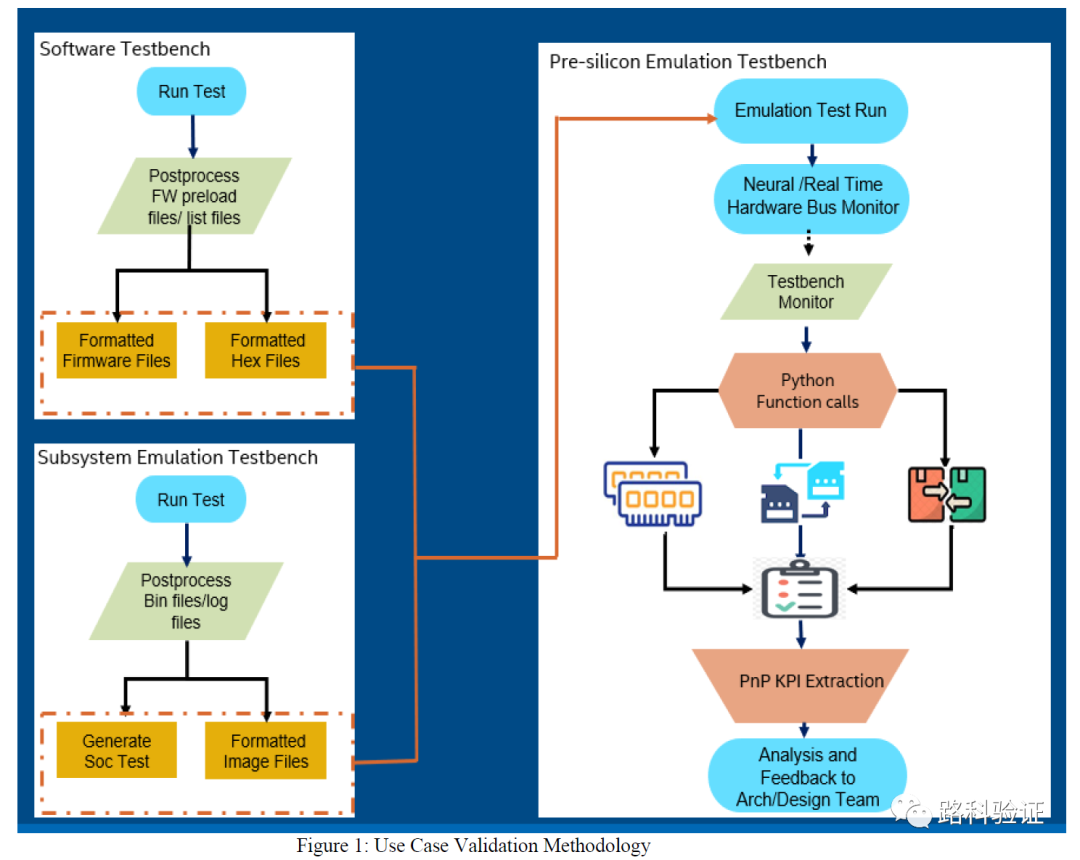
这个方案意味着测试从大的层面来看,是以最终通过固件测试为目的,也就是说从一开始构建测试场景时,就需要固件的人参与其中。这就不得不考虑在开发AI视觉芯片时的验证分工协作的场景不单单是simulation、emulation参与在内,也同样需要固件。尽管一开始硬件可能还不稳定,需要simulation/emulation让硬件逐步稳定,但固件的人只要前期有SystemC/C++这样的模型在的话也可以在早期做固件有关的测试准备。
这一点挺重要的,如果固件的人直到emulation阶段才参与进来的话,那么也就没有上面方案里的Software Testbench部分了,所有的信息都只能等到IP/子系统emulation阶段得出。更甚至,如果在IP/子系统emulation阶段没有固件参与的话,那么在SoC层面去做固件相关的测试,从开发固件测试用例到做参考比较都会延缓测试进度。更为推荐的是固件也有条件在某个测试平台(software testbench、IP/subsys emulation testbench)完成测试。
还有一点,在IP/subsys阶段的测试,方案中是通过测试中的bin文件、log文件来做后处理,继而生成SoC层面可以使用的配置。这一点不同于我们以往所理解的将测试文件从IP/subsys到SoC阶段的修改移植。可能是为了实现准确的、自动化的配置参数,它是按照后处理的方式,提取出来对目标硬件做的各项配置,这些提取的信息可能按照某个格式做了中间信息的保存,并且结合SoC的结构特征,做了自动化的配置测试生成。
在SoC emulation阶段,利用的是内置的总线监测(可能有多个),周期性地获得数据,并完成数据完整性检查(可能在测试中或者测试后通过Python脚本完成)。
性能分析方案
在性能分析时,也需要利用测试场景的移植(porting)和分析时的多个深度。从IP/subsys到SoC的移植,就性能分析而言分为了3个阶段。 第1阶段即是将IP/subsys的传输数据移植到SoC层面,这一点可以利用IP/subsys emulation过程中log文件的后处理来获得。 第2阶段是将IP/subsys的固件移植到SoC层面,这一点也可以利用“功能验证方案”中已有的“software testbench”信息。 第3阶段是为了让多个多媒体控制器、接口的数据信息能够并行运行以期达到真实的、大规模的数据吞吐。这种场景需要文中提到的一个特殊的混合方法(unique hybrid methodology),共同利用数据网络(network)和固件,将多个多媒体控制器充分并行调动,构建复杂的测试场景。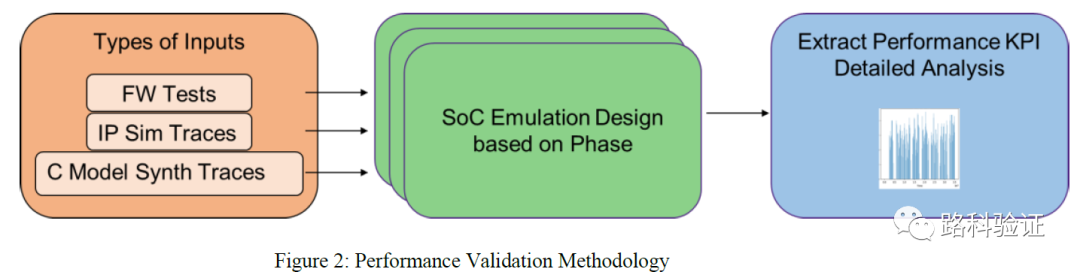
功耗估测方案
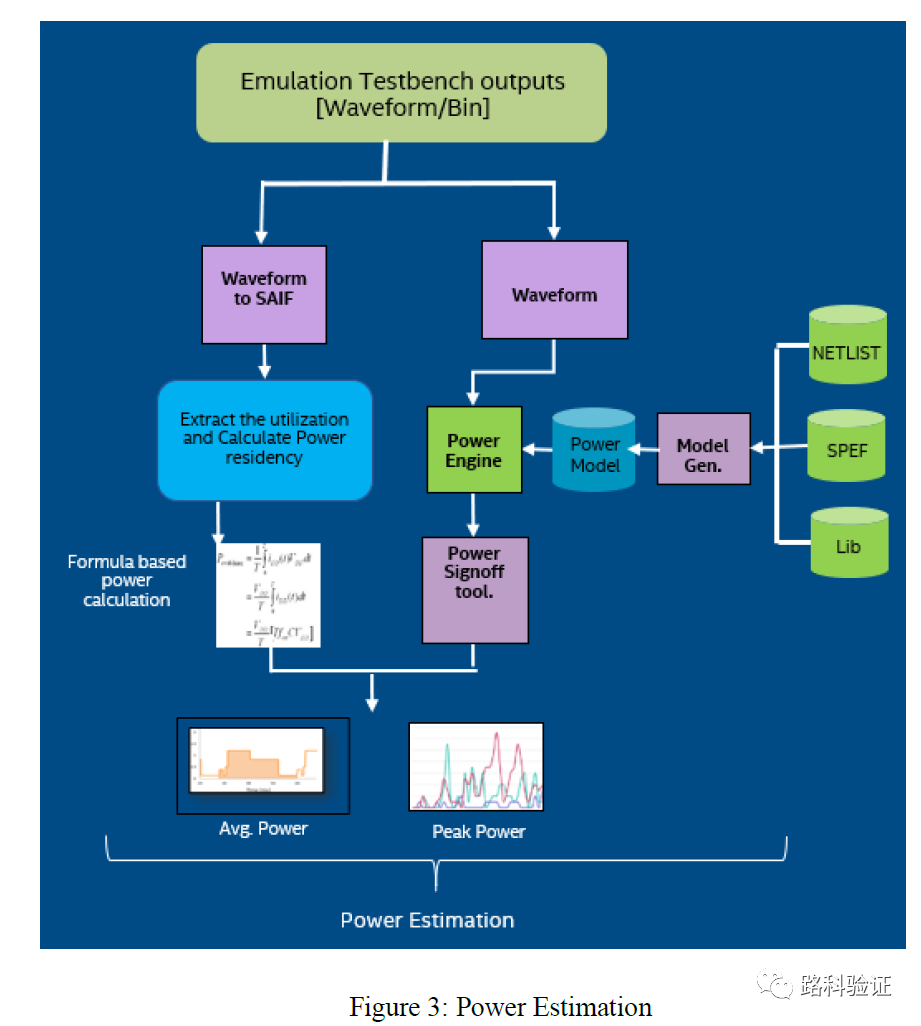
在功耗估测中,需要考虑的是相比于通常在仿真中收集功耗有关数据,如何在emulation中收集数据,并且做到准确的、快速的功耗分析。在下面的方案中,利用了波形数据获得开关信息文件SAIF,并结合power engine去获得平均功耗和峰值功耗(论文并没有就power engine给出详细的信息)。 这里附赠一篇文章: 《Using Emulators For Power/Performance Tradeoffs》 https://semiengineering.com/using-emulators-for-power-performance-tradeoffs/
结果分析
受益于可以从IP/subsys层将测试用例有关的数据自动迁移到SoC级,使得与VPU(视觉处理单元)、DMA、ISP(Image Signal Processing)有关的测试用例能够在4周的时间完成交付。这里的测试用例迁移我们应该吸取文章中的经验,那就是它不是从测试用例自身文本的迁移去实现的,而是通过log/bin文件的后处理,获得某种中间型的标准信息文件,再结合系统测试的环境配置数据,最终生成SoC测试用例。
从发现的bug类型来看,有接近40%来自于固件级别的测试,这也突出了AI类芯片在测试时需要结合实际场景的需求,毕竟整个系统的调动牵扯很多模块,需要固件人员在早期就能够参与进来。这也进一步突出了如何规划一个跨平台的方案在系统级测试上面有多么重要,我们不应该被SV/UVM/C所限制,也应该考虑如何让这个测试平台能够被更多的人所使用。

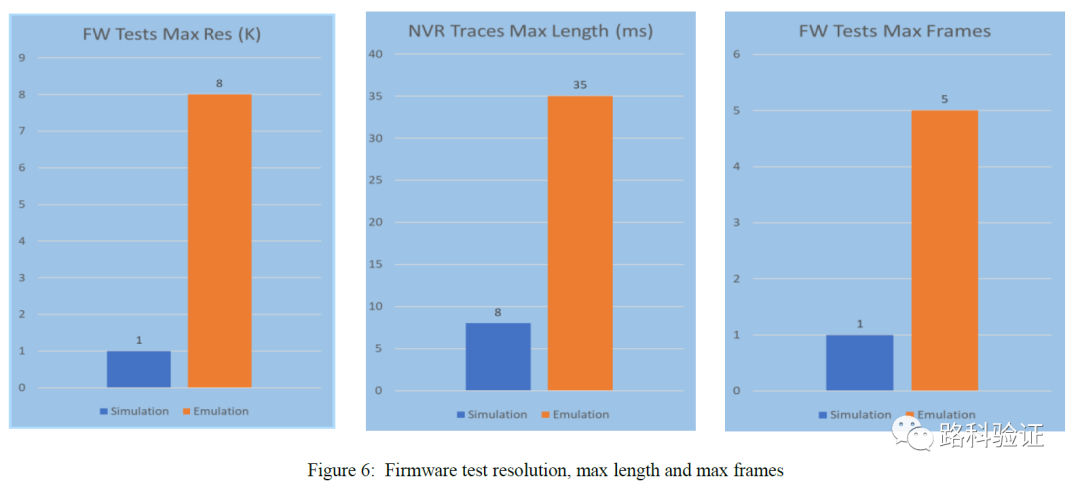
相比于SoC仿真动辄需要用2天左右的时间完成某一个固件级的测试用例,emulation仅需要大概90分钟的时间即能够完成测试,并且更快地将性能数据反馈给架构组合设计组。在将simulation与emulation对比过程中,无论是固件测试用例数量、可支持数据帧的数目还是数据保存时间窗口,emulation的优势都更为明显。
而在功耗评估中,emualtion的功耗评估数据准确度与传统的功耗分析工具差别大致在5%以内,而所消耗的时间则显著缩短(大致是传统功耗分析工具的125倍)。论文这里仍然没有给出消耗时间的计算方式,是否包含了每个测试用例在simulation与emulation的耗时差别,还是只是包含了两种工具用于功耗评估的时间。如果是后者的话,那么文中的power engine可能是内部开发的工具了,线索在文章的引文中(有一篇“pre-silicon power estimation methodology using emulation”,也一并在论文下载链接中提供)。
给出的参考论文来自于SNUG India 2020,而在2021年的时候Synopsys推出了业界第一款用来对运行真实软件做功耗验证(hardware+software)的工具ZeBu Empower。 https://www.synopsys.com/verification/emulation/zebu-empower.html
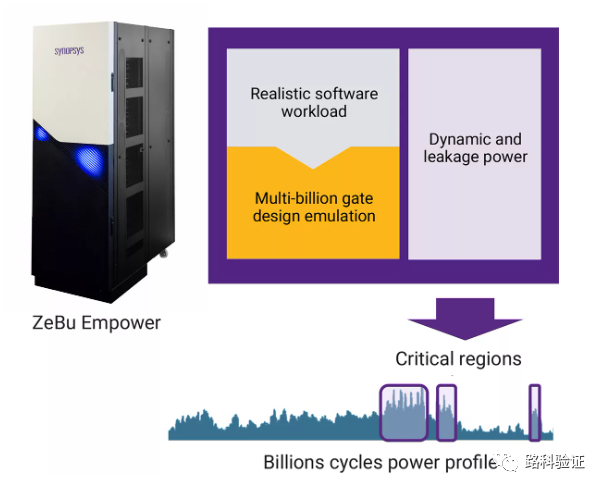

Fastest Power Emulation for Hardware-Software Power Verification
审核编辑:刘清
-
控制器
+关注
关注
114文章
17915浏览量
195814 -
soc
+关注
关注
40文章
4658浏览量
230575 -
AI
+关注
关注
91文章
41967浏览量
303061 -
硬件加速器
+关注
关注
0文章
43浏览量
13556 -
视觉处理芯片
+关注
关注
2文章
12浏览量
6765
原文标题:DVCon文赏-2023w14 一种用于AI视觉处理芯片的验证加速方案
文章出处:【微信号:Rocker-IC,微信公众号:路科验证】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
RZ/V2MA:高效能视觉AI芯片的技术剖析与应用指南
京微齐力推出全新高性能AI视觉处理FPGA芯片产品
NVIDIA 发布开放物理 AI 数据工厂 Blueprint,加速机器人、视觉 AI 智能体和智能汽车开发

Cadence 推出 ChipStack™ AI Super Agent,开辟芯片设计与验证新纪元
瑞芯微SOC智能视觉AI处理器
RK3576驱动高端显控系统升级:多屏拼控与AI视觉融合解决方案
AI眼镜视觉处理芯片:从图像感知到智能增强的技术跃迁

极细同轴线在AI+FPGA视觉加速方案中的应用




评论