 通俗理解文本生成的常用解码策略
通俗理解文本生成的常用解码策略

通俗理解文本生成的常用解码策略
General Understanding of Decoding Strategies Commonly Used in Text Generation
”
注意:这一篇文章只包含了常用的解码策略,未包含更新的研究成果。Note: this post contains only commonly used decoding strategies and does not include more recent research findings.
目录:
- 背景简介
- 解决的问题
- 解码策略
- Standard Greedy Search
- Beam Search
- Sampling
- Top-k Sampling
- Sampling with Temperature
- Top-p (Nucleus) Sampling
- 代码快览
- 总结
This post covers:
- Background
- Problem
- Decoding Strategies
- Standard Greedy Search
- Beam Search
- Sampling
- Top-k Sampling
- Sampling with Temperature
- Top-p (Nucleus) Sampling
- Code Tips
- Summary
1. 背景简介(Background)
“Autoregressive”语言模型的含义是:当生成文本时,它不是一下子同时生成一段文字(模型吐出来好几个字),而是一个字一个字的去生成。"Autoregressive" means that when a model generates text, it does not generate all the words in the text at once, but word by word.
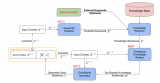
举例来说,图中(For example as shown in the figure):
1)小伙问了模型一个问题 (he asked the modal a question):Hello! How are you today?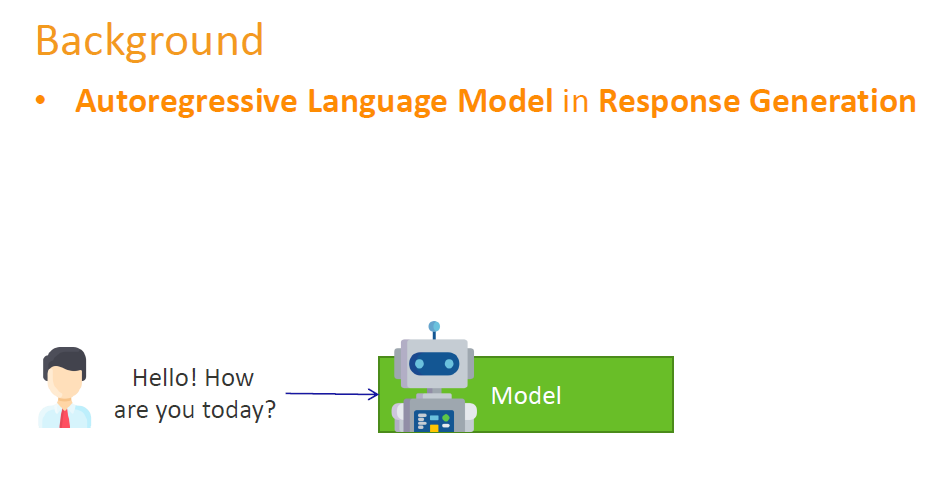
2)模型需要生成回复文本,它生成的第一个单词是(the first word in the response generated by the model is): “I”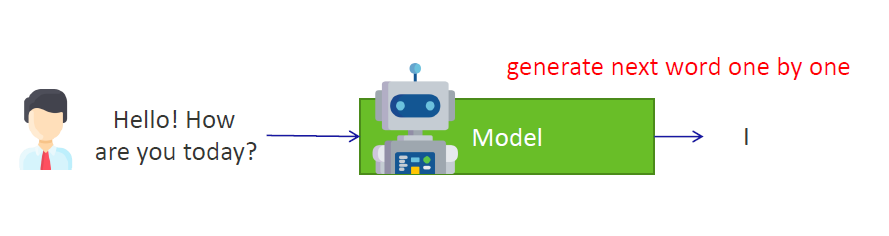
3)当生成“I”之后,模型根据目前得到的信息(小伙的问题 + “I”),继续生成下一个单词 (Once the "I" has been generated, the model continues to generate the next word based on the information, the question + "I", it has received so far): “am”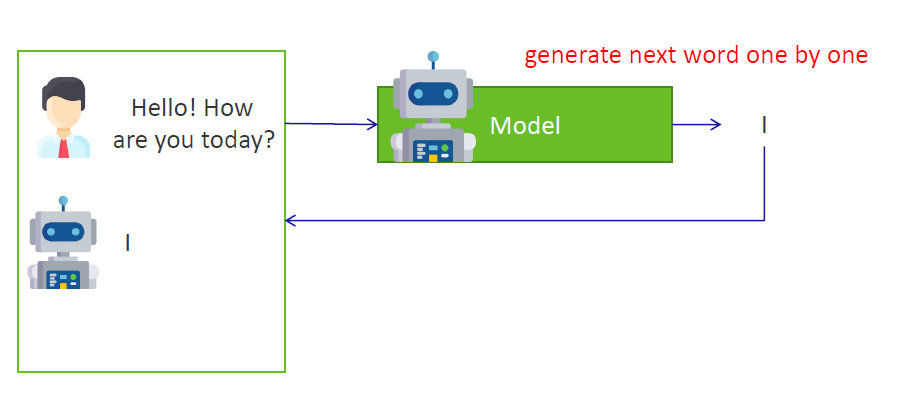
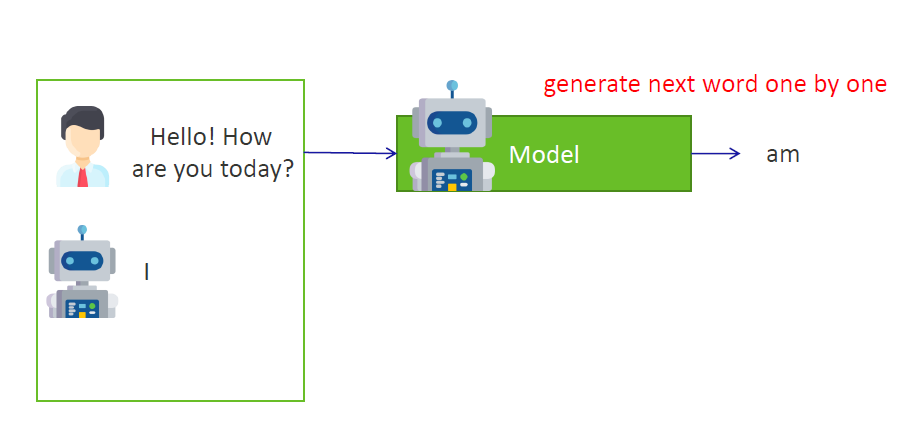
4)当生成“I am”之后,模型根据目前得到的信息(小伙的问题 + “I am”),继续生成下一个单词(Once "I am" is generated, the model continues to generate the next word based on the information, the question + "I am", it has received so far): “good”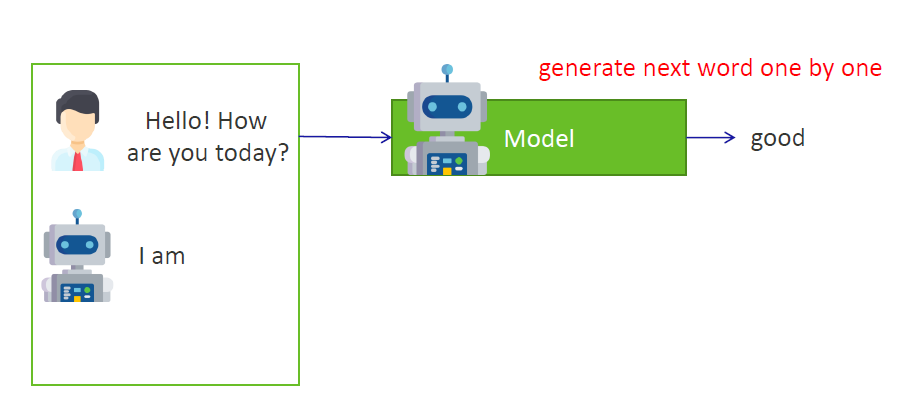
5)重复上面的步骤,直到生成一种特殊的词之后,表示这一次的文本生成可以停止了。在例子中,当生成“[EOS]”时表示这段文本生成完毕,(EOS = End of Sentence)。Repeat the above steps until a particular word is generated, which means that the text generation can be stopped for this time. In the example, the text is complete when the word "[EOS]" is generated.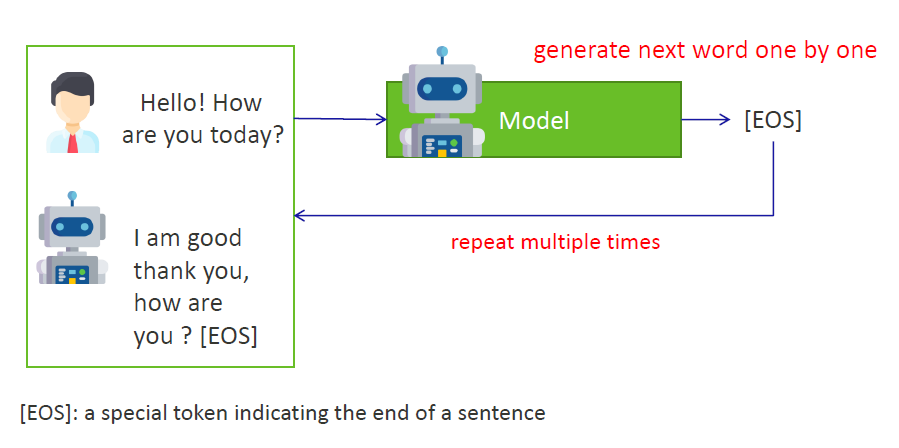
2. 解决的问题(Problem)
由于这种模型生成文本的方式是一个词一个词的输出,所以它是否能够产生好的文本取决于我们是否能够聪明地决定下一步应该输出哪一个词汇。Since this way of generating text is output word by word, its ability to produce goodtext depends on the text generation strategy being smart enough to decide which word should be output at each step.
“需要注意的是,在这篇文章中,对“好”的定义并不是指的这个模型在经过良好的训练之后,具备了接近人类并且高质量的表达能力。这里对“好”的定义是一个好的挑选输出词的策略。详细来说就是,在模型预测下一个词应该是什么的时候,它在任何状态下(也就是说不管模型是否经过了良好的训练),这个策略总是有一套自己的办法去尽全力挑选出来一个它认为最合理的词作为输出。It is important to note that the definition of 'good' in this post does not mean that the model is well-trained and has a high quality of expression close to that of a human. In this context, the definition of 'good' is a good strategy for selecting output words. In detail, this means that when the model is predicting what the next word should be, in any status (i.e. whether the model is well-trained or not), the strategy always have a way of doing its best to pick the word that the startegy think makes the most sense as an output.
”
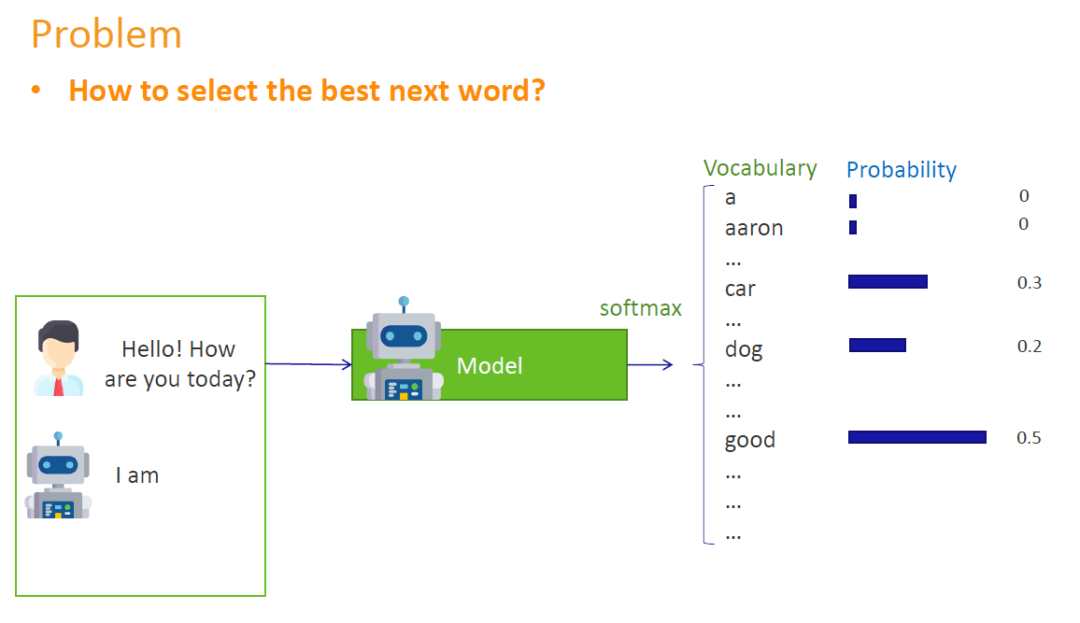
当选词策略将要对下一个输出词做选择的时候,在我们面前有一张巨大的表格。这张表格便是模型目前认为下一步应该输出哪一个词的概率。The word selection strategy refers to a large table when making decisions about what words to output. This table stores the probability of what the model currently thinks the next word should be.
3. 解码策略(Decoding Strategies)
3.1 Standard Greedy Search
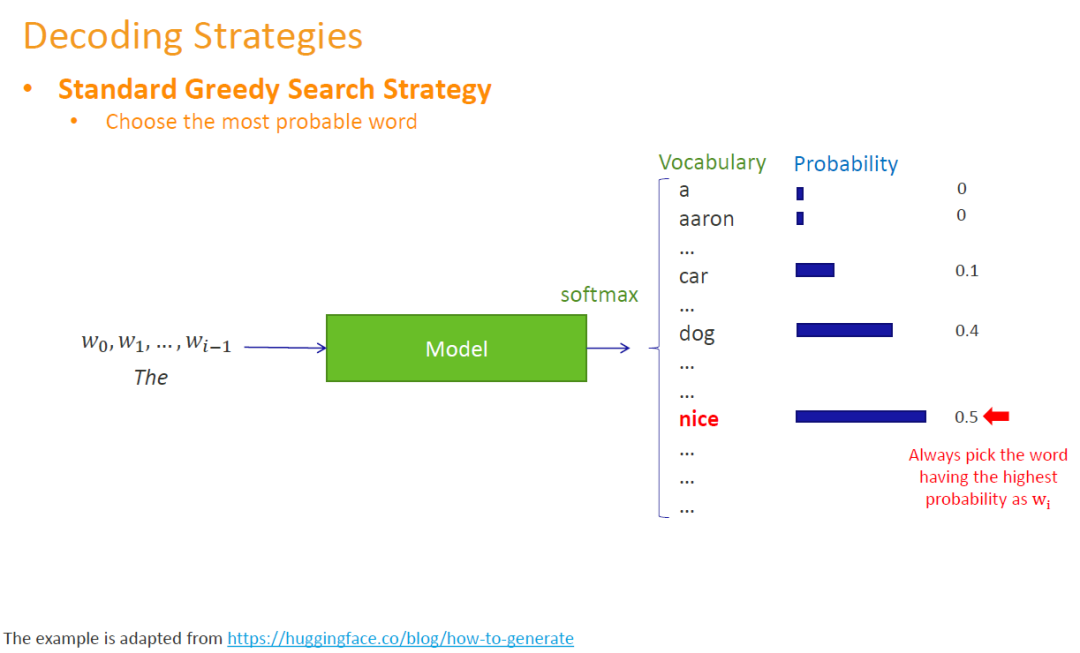 最简单朴素的方法是我们可以总是可以去挑选概率最高的词去输出。但是这样的方法会有一个潜在的问题,当整个句子(多个词汇)输出完毕的时候,我们不能保证这整个句子就是最好的。我们也有可能找到比它更好的句子。虽然我们在每一步输出的时候,选择了我们目前认为最好的选择,但从长远全局来看,这并不代表这些词组合出来的整个句子就是最好的。The simplest and most straightforward way is that we can always pick the word with the highest probability. But there will be a potential problem, when we get the whole sentence, we can't guarantee that the sentence is good. It is also possible that we will find a sentence that is better than it is. Although we choose what we think are the best words at each step, in the big picture this does not mean that the whole sentence resulting from the combination of these words is good.
最简单朴素的方法是我们可以总是可以去挑选概率最高的词去输出。但是这样的方法会有一个潜在的问题,当整个句子(多个词汇)输出完毕的时候,我们不能保证这整个句子就是最好的。我们也有可能找到比它更好的句子。虽然我们在每一步输出的时候,选择了我们目前认为最好的选择,但从长远全局来看,这并不代表这些词组合出来的整个句子就是最好的。The simplest and most straightforward way is that we can always pick the word with the highest probability. But there will be a potential problem, when we get the whole sentence, we can't guarantee that the sentence is good. It is also possible that we will find a sentence that is better than it is. Although we choose what we think are the best words at each step, in the big picture this does not mean that the whole sentence resulting from the combination of these words is good.
3.2 Beam Search
为了解决“大局观”这个问题,我们可以尝试Beam搜索这个策略。举个例子,如图所示(To solve the "big picture" problem, we can try the Beam search strategy. An example is shown in the figure):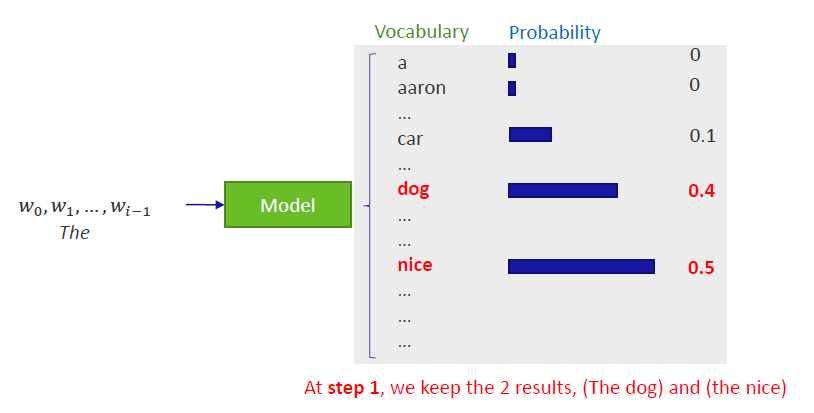 在3.1的策略中,我们的目光比较狭窄,因为我们只会关注我们认为最好的那1个输出。而在Beam搜索策略中,我们可以关注更多的“选手”(在图中我们关注了2个)。前期表现好的选手到最后不一定是最好的。如果你愿意的话,也可以同时关注更多的“选手”,只不过这样付出的代价就是你需要的运算资源更多了。In the strategy mentioned in section 3.1, we have a narrow focus, as we only focus on the 1 prediction we think is the best. Whereas in the Beam search strategy, we can focus on more options (in the figure we focus on 2). The text fragments with the highest scores in the early stages are not necessarily the best in the end. You can also focus on more text fragments at the same time if you wish, but this requires more computing resources.
在3.1的策略中,我们的目光比较狭窄,因为我们只会关注我们认为最好的那1个输出。而在Beam搜索策略中,我们可以关注更多的“选手”(在图中我们关注了2个)。前期表现好的选手到最后不一定是最好的。如果你愿意的话,也可以同时关注更多的“选手”,只不过这样付出的代价就是你需要的运算资源更多了。In the strategy mentioned in section 3.1, we have a narrow focus, as we only focus on the 1 prediction we think is the best. Whereas in the Beam search strategy, we can focus on more options (in the figure we focus on 2). The text fragments with the highest scores in the early stages are not necessarily the best in the end. You can also focus on more text fragments at the same time if you wish, but this requires more computing resources.
1)在上图中,当前的输入为“The” → Beam搜索策略需要根据输出的概率表格选择下一个输出词 → Beam选择关注最好的2位“选手”,即"The dog"和"The nice",他们的得分分别为0.4与0.5。In the above figure, the current input is "The" → Beam search strategy selects the next word based on the output probability table → Beam focuses on the best 2 choices, "The dog" and "The nice", which have scores of 0.4 and 0.5 respectively.

2)现在,在上图中,当前的输入为“The dog”和“The nice” → 当前的策略为这2个输入挑选出分数最高的输出→“The dog has”和“The nice woman”。Now, in the above figure, the current inputs are "The dog" and "The nice" → the current strategy picks the highest scoring output for these 2 inputs → "The dog has" and "The nice woman".
3)继续按照上面的思路,一直执行到最后你会得到2个得分最高的句子。Keep executing until the end and you will get the 2 highest-scoring sentences.

缺陷之一 (Shortcomings 1):但是这种策略生成的文本可能会有一个缺陷,容易重复的说一些话(如下图所示:“I'm not sure if I'll...”出现了2次)。一种补救办法是用简单的规则来限制生成的文本,比如同一小段文本(n-gram)不能出现2次。However, the text generated by this strategy may have the drawback of being prone to saying something over and over again (as shown below: "I'm not sure if I'll..." which appears 2 times). One remedy is to restrict the generated text with simple rules, such as the same text fragment (n-gram) not appearing twice.
缺陷之二 (Shortcomings 2):当我们想要的很大时(的含义是我们想要同时观察个分数最高的生成结果),相对应地对运算资源的需求也会变大。When we want to be large (in the sense that we want to observe thehighest scoring generated results simultaneously), the corresponding demand on computing resources becomes large.
缺陷之三 (Shortcomings 3):模型生成的文本比较枯燥、无趣。经过研究表明,在Beam搜索策略的引导下,模型虽然可以生成人类能够理解的句子,但是这些句子并没有给真正的人类带来惊喜。The text generated by the model is rather boring and uninteresting. It has been shown that guided by the Beam search strategy, the model can generate sentences that humans can understand, but these sentences do not surprise real humans.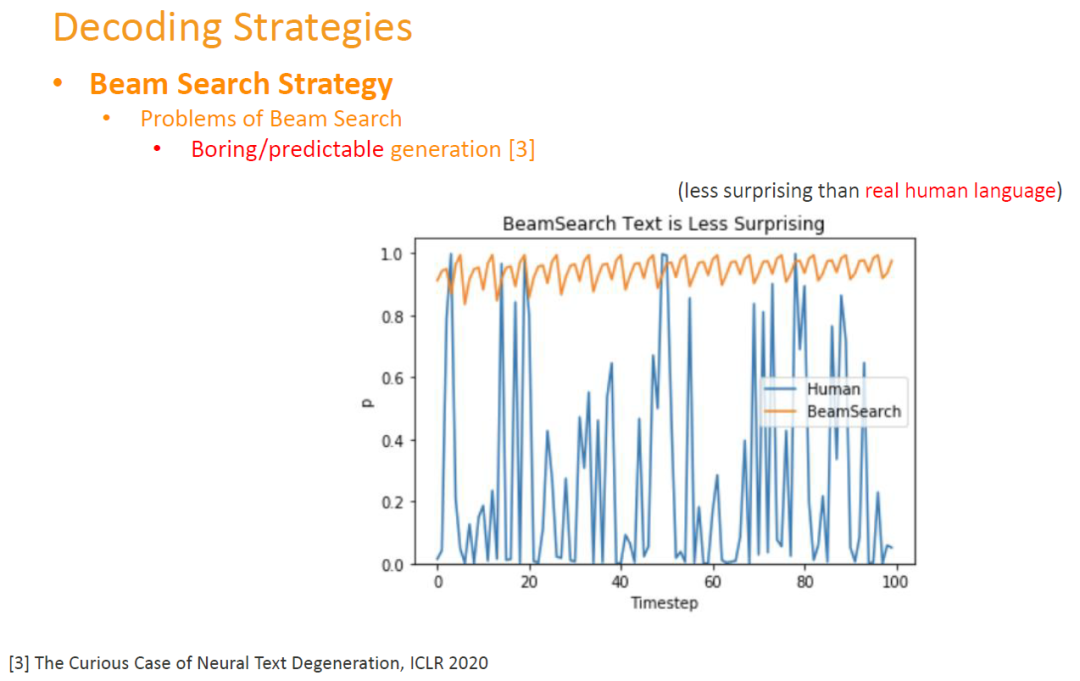
Beam搜索策略的变体 (More Variants of the Beam Search Strategy):
3.3 Sampling
使用采样的方法可以让生成的文本更加多样化。很朴素的一种方法就是按照当前的概率分布来进行采样。在模型的认知中,它认为合理的词(也就是概率大的词)就会有更大的几率被采样到。这种方法的缺陷是会有一定几率乱说话,或者生成的句子并不像人类话那般流利。The use of sampling allows for a greater variety of text to be generated. A very simple way of doing this is to sample according to the current probability distribution. Words with a high probability will have a higher chance of being sampled. The disadvantageof this approach is that there is a certain chance that incoherent words will be generated, or that the sentences generated will not be as fluent as in the language used by humans.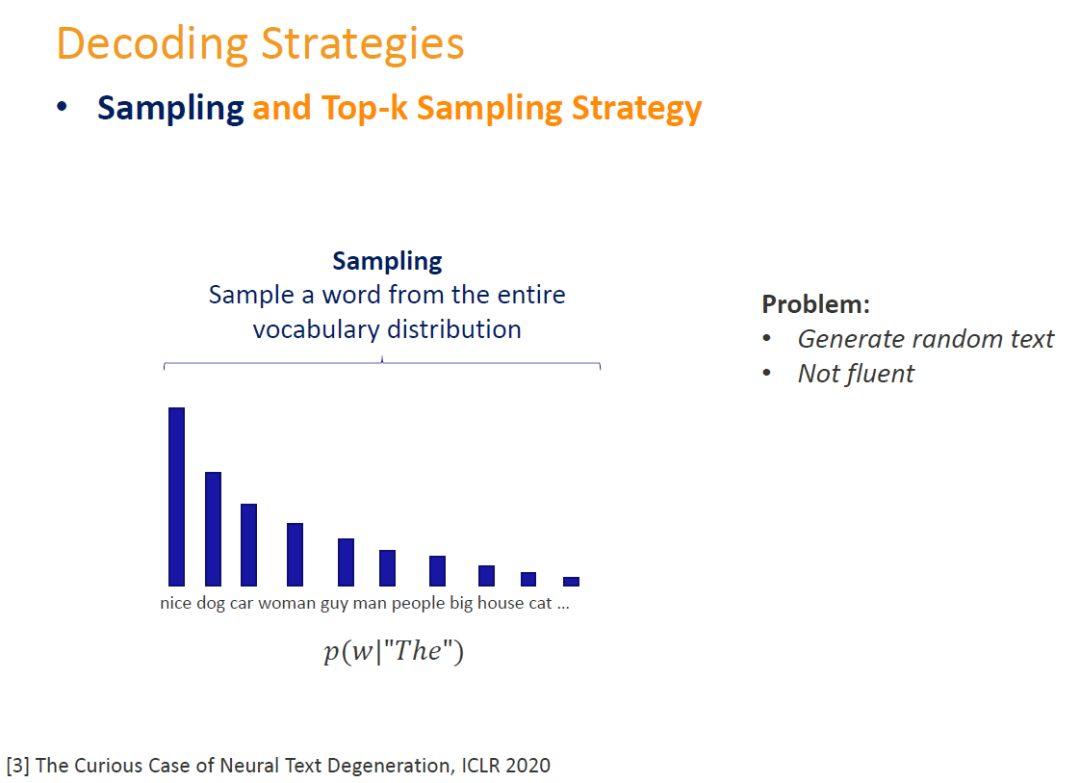
3.4 Top-k Sampling
为了缓解上述问题,我们可以限制采样的范围。例如我们可以每次只在概率表中的排名前个词中采样。To alleviate the above problem, we can limit the scope of sampling. For example, we could sample only the top words in the probability table at a time.
3.5 Sampling with Temperature
这种方法可以对当前的概率分布进行缩放,例如让概率大的更大、让小的变的更小,或者让大概率和小概率之间差别没那么明显等。而控制这种缩放力度的参数为[0,1)。在公式中,。This method allows the current probability distribution to be rescaled, for example by making larger probabilities larger, making smaller ones smaller, or making the difference between large and small probabilities less significant, etc. The parameter that controls the strength of this scaling is [0,1). In the equation,.
- 当变大时,模型在生成文本时更倾向于比较少见的词汇。越大,重新缩放后的分布就越接近均匀采样。As becomes larger, the model favours less common words when generating text. The largeris, the closer the rescaled distribution is to uniform sampling.
-
当变小时,模型在生成文本时更倾向于常见的词。越大,重新缩放后的分布就越接近我们最开始提到的贪婪生成方法(即总是去选择概率最高的那个词)。When becomes small, the model tends to favour common words when generating text. The largeris, the closer the rescaled distribution is to the greedy search strategy we mentioned at the beginning (i.e. always going for the word with the highest probability).

在Meena相关的论文中是这样使用这种策略的(This strategy is used in the relevant Meena paper in the following way):
- 针对同一段输入,论文让模型使用这种策略生成20个不同的文本回复。For the same input, the paper has the model generate 20 different text responses using this strategy.
-
然后从这20个句子中,挑选出整个句子概率最大的作为最终输出。Then from these 20 sentences, the one with the highest probability for the whole sentence is selected as the final output.
 使用上述方法生成的句子明显比使用Beam搜索策略生成的句子更加多样化、高质量。The sentences generated using the above method are significantly more diverse and of higher quality than those generated using the Beam search strategy.
使用上述方法生成的句子明显比使用Beam搜索策略生成的句子更加多样化、高质量。The sentences generated using the above method are significantly more diverse and of higher quality than those generated using the Beam search strategy.
3.6 Top-p (Nucleus) Sampling
在top-k采样的方法中,我们把可采样的范围的限制非常的严格。例如“Top-5”表示我们只能在排名前5位的词进行采样。这样其实会有潜在的问题 (In the top-k sampling method, we strictly limit the range of words that can be sampled. For example, "Top-5" means that we can only sample the top 5 words in the rankings. This has the potential to be problematic):
- 排在第5位之后的词也有可能是概率值并不算小的词,但是我们把这些词永远的错过了,而这些词很有可能也是非常不错的选择。Words after the 5th position are also likely to be words with high probability values, but we miss these words forever when they are likely to be good choices as well.
-
排在5位之内的词也有可能是概率值并不高的词,但是我们也把他们考虑进来了,而这些词很有可能会降低文本质量。Words ranked within the top 5 may also be words that do not have a high probability value, but we have taken them into account and they are likely to reduce the quality of the text.

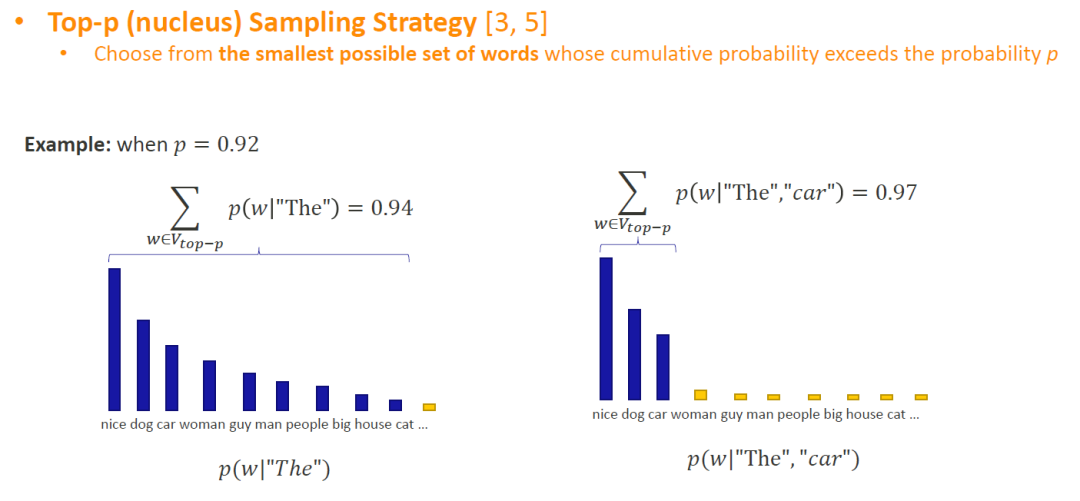
在Top-p这种方法中,我们通过设置一个阈值()来达到让取词的范围可以动态地自动调整的效果:我们把排序后的词表从概率值最高的开始算起,一直往后累加,一直到我们累加的概率总值超过阈值为止。在阈值内的所有词便是采样取词范围。In the Top-p method, we make the range of words taken dynamically adjustable by setting a threshold (): we add the probabilities in the word list starting with the highest probability value and keep adding them up until the total value of the probabilities we have accumulated exceeds the threshold. All words within the threshold are in the sampling range.
假设,我们设置的阈值为0.92(Suppose, we set a threshold of0.92):
- 在左图中,前9个词的概率加起来才超过了0.92。In the left figure, the probabilities of the first 9 words add up to more than 0.92.
-
在右图中,前3个词的概率和就可以超过0.92。In the right figure, the probabilities of the first 3 words can sum to more than 0.92.
4 代码快览(Code Tips)
图中展示了部分Huggingface接口示例。我们可以看的出来,尽管在这篇文章中提到了不同的方法,但是它们之间并不是完全孤立的。有些方法是可以混合使用的,这也是为什么我们可以在代码中可以同时设置多个参数。The figure shows a partial example of the Huggingface interface. As we can see, despite the different methods mentioned in this post, they are not completely separated from each other. Some of the methods are mixable, which is why we can have more than one argument in the code at the same time.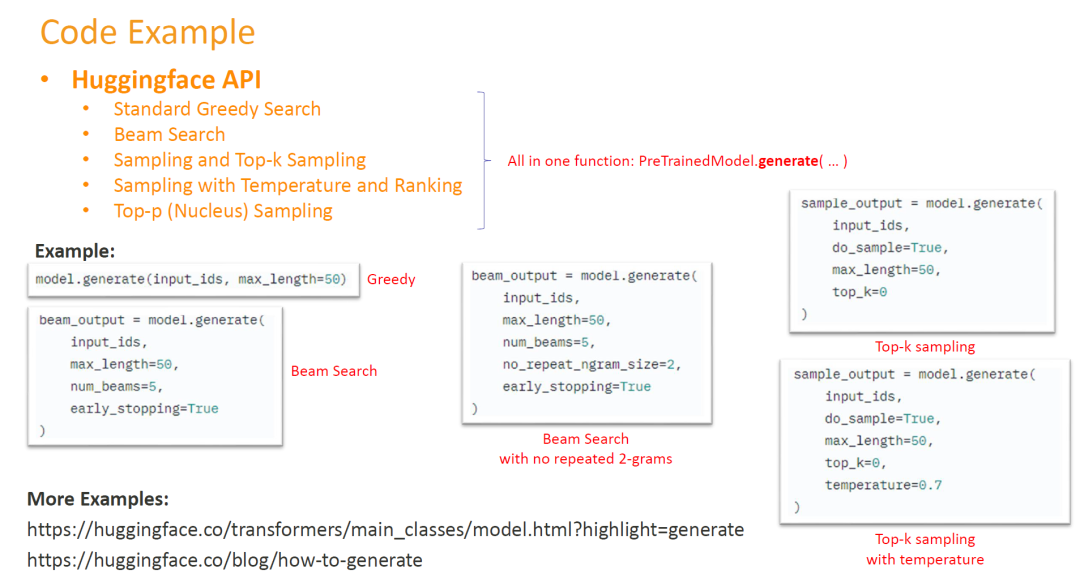
5 总结 (Summary)
文章中介绍了一些常用的解码策略,但是其实很难评价到底哪一个是最好的。Some common decoding strategies are described in the post, and it is actually difficult to evaluate which one is actually the best.
一般来讲,在开放领域的对话系统中,基于采样的方法是好于贪婪和Beam搜索策略的。因为这样的方法生成的文本质量更高、多样性更强。In general, sampling-based approaches are preferable to greedy and Beam search strategies in open-domain dialogue systems. This is because such an approach generates higher quality and more diverse text.
但这并不意味着我们彻底放弃了贪婪和Beam搜索策略,因为有研究证明,经过良好的训练,这两种方法是可以生成比Top-p采样策略更好的文本。However, this does not mean that we completely abandon the greedy and Beam search strategies, as it has been shown that, with proper training, these two methods are capable of generating better text than the Top-p sampling strategy.
自然语言处理之路还有很长很长,继续加油吧~ There is still a long, long way to go in natural language processing research. Keep working hard!
“小提醒 (Note):使用原创文章内容前请先阅读说明(菜单→所有文章)Please read the instructions before using any original post content (Menu → All posts) or contact me if you have any questions.
”
审核编辑 :李倩
-
解码
+关注
关注
0文章
187浏览量
28443 -
模型
+关注
关注
1文章
3648浏览量
51712 -
文本
+关注
关注
0文章
119浏览量
17742
原文标题:通俗理解文本生成的常用解码策略
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
高级检索增强生成技术(RAG)全面指南
如何构建文本生成器?如何实现马尔可夫链以实现更快的预测模型
循环神经网络卷积神经网络注意力文本生成变换器编码器序列表征
基于生成对抗网络GAN模型的陆空通话文本生成系统设计
基于生成器的图像分类对抗样本生成模型

基于生成式对抗网络的深度文本生成模型

文本生成任务中引入编辑方法的文本生成

受控文本生成模型的一般架构及故事生成任务等方面的具体应用
基于GPT-2进行文本生成
基于VQVAE的长文本生成 利用离散code来建模文本篇章结构的方法
ETH提出RecurrentGPT实现交互式超长文本生成

面向结构化数据的文本生成技术研究






 工商网监
工商网监
评论