 【AI简报20230310】知存科技再推存算一体芯片、微软:多模态大模型GPT-4就在下周
【AI简报20230310】知存科技再推存算一体芯片、微软:多模态大模型GPT-4就在下周

嵌入式 AI
AI 简报 20230310 期
1. 知存科技再推存算一体芯片,用AI技术推动助听器智能化
原文:
https://mp.weixin.qq.com/s/reQvUTJlOJSqEtHGKL4QbA
2022年3月,知存科技量产的国际首颗存内计算SoC芯片WTM2101正式投入市场。如今已在端侧实现商用,提供语音、视频等AI处理方案并帮助产品实现10倍以上的能效提升。WTM2101采用40nm工艺,是一颗拥有高算力存内计算核的芯片,相对于NPU、DSP、MCU计算平台、AI算力提升10-200倍,具备1.8MB权重、50Gops算力。
顾名思义,存内计算芯片采用存算一体架构,区别于传统计算架构冯诺伊曼以计算为中心的设计,改为以数据存储为中心的设计。由于冯诺伊曼架构存在一定的局限性,那就是随着CPU,或者运算单元的运算能力提高,数据传输并没有跟上CPU运算频率的同步递增,这样就出现存储墙。
知存科技FAE总监陆彤表示,存储墙会带来两个弊端,一是时延问题,因为由数据从memory 搬到计算单元里是需要时间的,当然也有不同的解决方法,比如采用更快的存储单元、更宽的数据通道,或者是采用分布式的方式进行存储。二是功耗问题,预计会占整个芯片功耗的50%-90%左右。
存算一体架构通过在存储体上采用不同的技术,或者叫重新设计,让存储器件单元能直接完成乘加计算,也能存储数据,极大程度上解决了存储墙的问题,从而大幅度提升芯片的运行效率,突破瓶颈。
WTM2101在助听器领域,能够提供增益调整、EDRC等助听基本功能,知存科技FAE总监陆彤介绍WTM2101在助听领域更突出的价值更多还是体现在AI 相关应用上,例如双麦BF+AI-ENC降噪实现智能融合降噪,能够做到11ms延时、20db降噪。WTM2101还加入了AI通透功能,能够选择性通透电视、音乐等有效声音。
防啸叫是助听器的刚需功能,为了实现该功能,WTM2101除了实施传统的啸叫算法,也添加了NN抗啸叫算法组合;在健康监测方面,还加入了低功耗NN心率算法,并且实现了超低功耗标准模式50uA、运动模式为80uA。
此外,由于助听器应用在耳道里面,没有什么按键或者其他的方式能够操作,因此自动环境识别也是助听器产品需要关注的重点,目前,业内有厂商计划采用语音控制的方式实现,或者基于AI深度学习/经典算法,进行环境音检测。WTM2101加入了关键词唤醒功能,算力约为10~20Mops。“如果从算力上来看,这些算法需要上百,甚至上G的OPS 算力需求,可能业内其他产品部署起来会有算力的压力。但WTM2101具备50Gops算力,是能够完成这些工作的”。
在低分辨率下,当信噪比到- 10db甚至-5db更低,佩戴者在使用助听器时就很难区分语音。而WTM2101具备人声增强功能,PESQ相对小算力AI算法和经典算法提高0.4和0.5.
据了解,飞利浦在去年推出飞利浦HearLink30平台助听器,引入了多种AI智能技术。不难发现,在技术的成熟下,越来越多AI技术的应用让助听器变得更加智能。“AI给助听器带来了很大的升级,AI在智能降噪、去啸叫和环境识别上面有很大优势”,知存科技相关负责人对电子发烧友网表示。目前已有多款助听器不仅仅是助听功能,还具备健康监测等更多功能,降噪功能也越来越强大。
2. 边缘人工智能芯片制造商Hailo推出Hailo-15
原文:
https://mp.weixin.qq.com/s/ClhnJZkU1P9cEGfJ7CZDHA
边缘人工智能(AI)处理器的先锋芯片制造商Hailo今天公布了突破性的新型Hailo-15系列高性能视觉处理器,该系列旨在直接集成到智能摄像机中,在边缘提供前所未有的视频处理和分析。
随着Hailo-15的推出,该公司正在重新定义智能摄像机类别,在计算机视觉和深度学习视频处理方面设立新标准,能够在不同行业的广泛应用中带来突破性的人工智能性能。
利用Hailo-15,智能城市运营商可以更迅速地检测和应对事件;制造商可以提高生产力和机器正常运行时间;零售商可以保护供应链并提高客户满意度;交通当局可以识别走失的儿童、事故、放错地方的行李等各种对象。
"Hailo-15代表着在使边缘人工智能更加可扩展和可负担方面迈出的重要一步。"Hailo首席执行官Orr Danon表示,"通过这次发布,我们正在利用我们在已被全球数百家客户部署的边缘解决方案方面的领先地位,我们的人工智能技术的成熟度以及我们全面的软件套件,从而以摄像机外形尺寸实现高性能人工智能。"
Hailo-15 VPU系列包括三个型号:Hailo-15H、Hailo-15M和Hailo-15,以满足智能摄像机制造商和AI应用提供商的不同处理需求和价格点。这个VPU系列的性能达到7 TOPS(每秒万亿次运算)至惊人的20 TOPS,比目前市场上的解决方案高出5倍以上,而价格相当。所有Hailo-15 VPU都支持4K分辨率的多输入流,将强大的CPU和DSP子系统与Hailo经过现场验证的AI核心相结合。
通过在摄像机中引入优异的人工智能功能,Hailo正在满足市场上对增强边缘视频处理和分析能力的日益增长的需求。凭借这种无与伦比的人工智能能力,搭载Hailo-15的摄像机可以进行明显更多的视频分析,并行运行多个人工智能任务,包括更快的高分辨率检测,从而能够识别更小、更远的对象,并具有更高的准确性和更少的错误警报。
例如,Hailo-15H能够在高输入分辨率(1280x1280)下以实时传感器速率运行最先进的对象检测模型YoloV5M6,或以非凡的700 FPS运行行业分类模型基准ResNet-50。
通过这个高性能人工智能视觉处理器系列,Hailo率先在摄像机中使用基于视觉的transformers进行实时对象检测。增加的人工智能能力还可用于视频增强和低光环境下的更优视频质量,实现视频稳定和高动态范围性能。
3. AI算力芯片:人工智能核心底座,7年空间13倍,国产替代之关键
原文:https://baijiahao.baidu.com/s?id=1759514012109489440&wfr=spider&for=pc
还记得这张把谷歌AI搞得团团转的经典梗图吗?
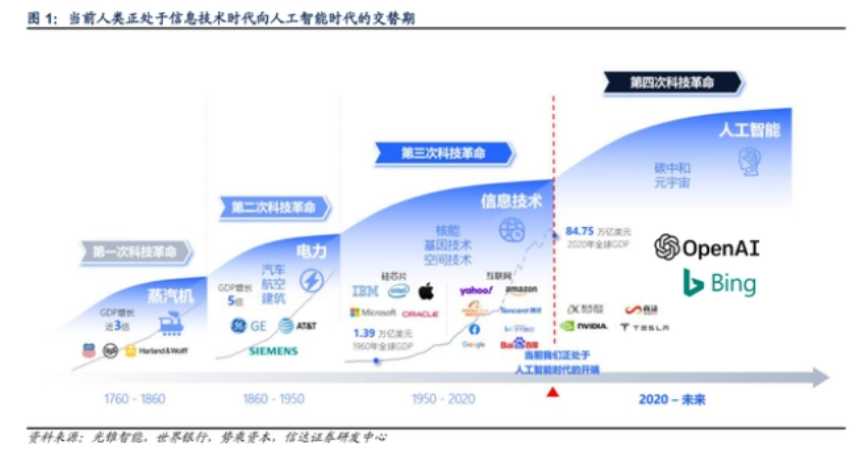
每一次科技创新浪潮都是突破某一项生产力要素,从而提升人类生产效率。
人工智能引领着新一轮科技革命,而生成式AI的出现,真正赋予了人工智能大规模落地的场景,有望在更高层次辅助甚至代替人类工作,提升人类生产效率。
今年,生成式AI代表产品ChatGPT所产生的鲶鱼效应持续发酵,引发市场广泛关注。
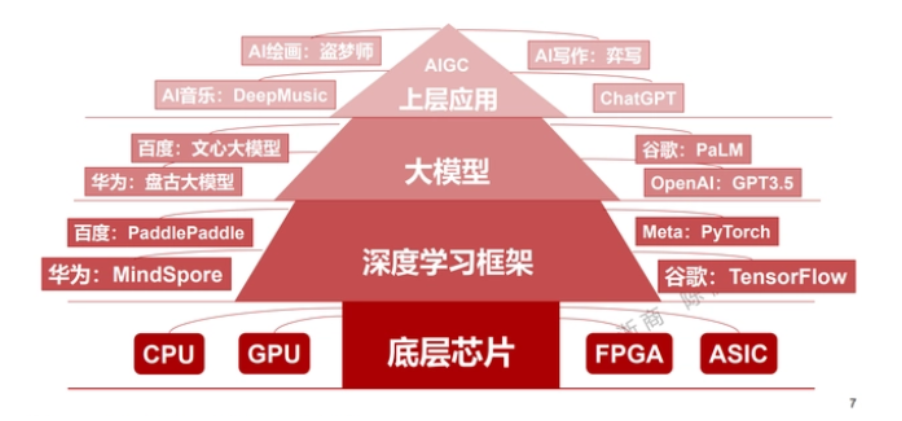
深入了解后能够发现,生成式AI竞争的焦点主要有两个,一是巨大参数量、超大规模的AI模型,二是提供超强算力的AI芯片,两者缺一不可。
市场也逐渐意识到,人工智能的竞争是巨头之间的竞争,巨额研发投入迫使小公司聚焦于上层应用,同时,底层算力支撑愈发关键,没有扎实的底盘,上层建筑皆是空中楼阁。
不仅在人工智能,在整个数字经济当中,下游技术应用的实现,都离不开算力。
算力,是国内的短板,而国际供应链问题愈发凸显,算力不足的问题可能显现,不仅对人工智能有影响,还将影响整个数字经济,所以,算力芯片成为突围关键点。
AI算力芯片需求激增
AI算力进入大模型时代,大模型的实现需要强大的算力来支撑训练和推理过程。比如Open AI,微软专门为其打造了一台超级计算机,专门用来在Azure公有云上训练超大规模的人工智能模型
这台超级计算机拥有28.5万个CPU核心,超过1万颗GPU(英伟达 V100 GPU),按此规格,如果自建IDC,以英伟达A100 GPU芯片替代V100 GPU芯片,依照性能换算,大约需要3000颗A100 GPU芯片。
想要了解更多内容,请点击查看原文。
4. 全方位分析大模型参数高效微调,清华研究登Nature子刊
原文:
https://mp.weixin.qq.com/s/wHc87AZafnRp8eMFOJxPoA
近年来,清华大学计算机系孙茂松团队深入探索语言大模型参数高效微调方法的机理与特性,与校内其他相关团队合作完成的研究成果 “面向大规模预训练语言模型的参数高效微调”(Parameter-efficient Fine-tuning of Large-scale Pre-trained Language Models)3 月 2 日在《自然・机器智能》(Nature Machine Intelligence)上发表。该研究成果由计算机系孙茂松、李涓子、唐杰、刘洋、陈键飞、刘知远和深圳国际研究生院郑海涛等团队师生共同完成,刘知远、郑海涛、孙茂松为该文章的通讯作者,清华大学计算机系博士生丁宁(导师郑海涛)与秦禹嘉(导师刘知远)为该文章的共同第一作者。
论文链接:https://www.nature.com/articles/s42256-023-00626-4
OpenDelta 工具包:https://github.com/thunlp/OpenDelta
2018 年以来,预训练语言模型 (PLM) 及其 “预训练 - 微调” 方法已成为自然语言处理(NLP)任务的主流范式,该范式先利用大规模无标注数据通过自监督学习预训练语言大模型,得到基础模型,再利用下游任务的有标注数据进行有监督学习微调模型参数,实现下游任务的适配。
随着技术的发展,PLM 已经毫无疑问地成为各种 NLP 任务的基础架构,而且在 PLM 的发展中,呈现出了一个似乎不可逆的趋势:即模型的规模越来越大。更大的模型不仅会在已知任务上取得更好的效果,更展现出了完成更复杂的未知任务的潜力。
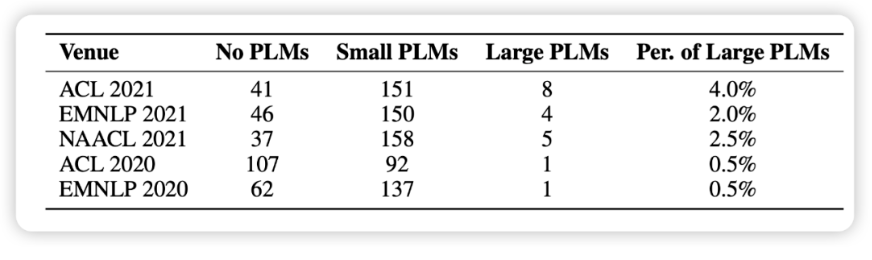
然而,更大的模型也在应用上面临着更大的挑战,传统方法对超大规模的预训练模型进行全参数微调的过程会消耗大量的 GPU 计算资源与存储资源,巨大的成本令人望而却步。这种成本也造成了学术界中的一种 “惯性”,即研究者仅仅在中小规模模型上验证自己的方法,而习惯性地忽略大规模模型。
在本文的统计中,我们随机选取了 1000 篇来自最近五个 NLP 会议的论文,发现使用预训练模型已经成为了研究的基本范式,但涉及大模型的却寥寥无几(如图 1 所示)。
在这样的背景下,一种新的模型适配方案,参数高效(Parameter-efficient) 方法逐渐受到关注,与标准全参数微调相比,这些方法仅微调模型参数的一小部分,而其余部分保持不变,大大降低了计算和存储成本,同时还有着可以媲美全参数微调的性能。我们认为,这些方法本质上都是在一个 “增量”(Delta Paremters)上进行调整,因此将它命名为 Delta Tuning。
在本文中,我们定义和描述了 Delta Tuning 问题,并且通过一个统一的框架对以往的研究进行梳理回顾。在这个框架中,现有的 Delta Tuning 方法可以被分为三组:增量式(Addition-based)、指定式(Specification-based)和重参数化(Reparameterization)的方法。
除去实践意义之外,我们认为它还具有非常重要的理论意义,Delta Tuning 在某种程度上昭示着大模型的背后机理,有助于我们进一步发展面向大模型甚至深度神经网络的理论。为此,我们从优化和最优控制两个角度,提出理论框架去讨论 Delta Tuning,以指导后续的结构和算法设计。此外,我们对代表性方法进行了全面的实验对比,并在超过 100 个 NLP 任务的结果展示了不同方法的综合性能比较。实验结果涵盖了对 Delta Tuning 的性能表现、收敛表现、高效性表现、Power of Scale、泛化表现、迁移性表现的研究分析。我们还开发了一个开源工具包 OpenDelta,使从业者能够高效、灵活地在 PLM 上实现 Delta Tuning。

方法优势:
快速训练与存储空间节省。Transformer 模型虽然本质上是可并行化的,但由于其庞大的规模,训练起来非常缓慢。尽管 Delta Tuning 的收敛速度可能比传统的全参数微调慢,但随着反向传播期间可微调参数的计算量显著减少,Delta Tuning 的训练速度也得到了显著提升。以前的研究已经验证了,使用 Adapter 进行下游调优可以将训练时间减少到 40%,同时保持与全参数微调相当的性能。由于轻量的特性,训练得到的 Delta 参数还可以节省存储空间,从而方便在从业者之间共享,促进知识迁移。
多任务学习。构建通用的人工智能系统一直是研究人员的目标。最近,超大型 PLM (例如 GPT-3) 已经展示了同时拟合不同数据分布和促进各种任务的下游性能的惊人能力。因此,在大规模预训练时代,多任务学习受到越来越多的关注。作为全参数微调方法的有效替代,Delta Tuning 具有出色的多任务学习能力,同时保持相对较低的额外存储。成功的应用包括多语言学习、阅读理解等。此外,Delta Tuning 也有望作为持续学习中灾难性遗忘的潜在解决方案。在预训练期间获得的语言能力存储在模型的参数中。因此,当 PLM 在一系列任务中按顺序进行训练时,在没有正则化的情况下更新 PLM 中的所有参数可能会导致严重的灾难性的遗忘。由于 Delta Tuning 仅调整最小参数,因此它可能是减轻灾难性遗忘问题的潜在解决方案。
中心化模型服务和并行计算。超大型 PLM 通常作为服务发布,即用户通过与模型提供者公布的 API 交互来使用大模型,而不是本地存储大模型。考虑到用户和服务提供商之间难以承受的通信成本,由于其轻量级的特性,Delta Tuning 显然是比传统全参数微调更具竞争力的选择。一方面,服务提供商可以支持训练多个用户所需的下游任务,同时消耗更少的计算和存储空间。此外,考虑到一些 Delta Tuning 算法本质上是可并行的(例如 Prompt Tuning 和 Prefix-Tuning 等),因此 Delta Tuning 可以允许在同一个 batch 中并行训练 / 测试来自多个用户的样本(In-batch Parallel Computing)。最近的工作还表明,大多数 Delta Tuning 方法,如果本质上不能并行化,也可以通过一些方法修改以支持并行计算。另一方面,当中心的达模型的梯度对用户不可用时,Delta Tuning 仍然能够通过无梯度的黑盒算法,仅调用模型推理 API 来优化大型 PLM。
更多的细节,请点击链接查看原文。
5. 目标检测中正负样本的问题经验分析
https://mp.weixin.qq.com/s/9C7mszKErCCoSs0sYB3YcA
1. 什么是正负样本?
对于像YOLO系列的结构,正负样本就是feature map上的每一个grid cell(或者说对应的anchor)。
对于像RCNN系列的结构,RPN阶段定义的正负样本其实和YOLO系列一样,也是每一个grid cell。RCNN阶段定义的正负样本是RPN模块输出的一个个proposals,即感兴趣区域(region of interesting,roi),最后会用RoIPooling或者RoIAlign对每一个proposal提取特征,变成区域特征,这和grid cell中的特征是不一样的。
对于DETR系列,正负样本就是Object Queries,与gt是严格的一对一匹配。而YOLO,RCNN是可以多对一的匹配。
通常情况下,检测问题会涉及到3种不同性质的样本:
正样本(positive)
对于positive,一旦判定某个grid cell或者proposal是正样本,你就需要对其负责cls+bbox的训练。
忽略样本(ignore)
ignore最大的用处就是可以处理模棱两可的样本,以及影响模型训练的样本。所以对于ignore,对其不负责任何训练,或者对其负责bbox的训练,但是不负责cls的训练。
负样本(negative)
对于negative,只负责cls的训练,不负责bbox的训练。
2. 怎么定义哪些是正样本/ignore/负样本
常规使用的方法:
借助每个grid cell中人为设置的anchor,计算其与所有gt(ground truth)的iou,通过iou的信息来判定每个grid cell属于positive/ignore/negative哪种。
以当前gt为中心的一定范围内,去判定每个grid cell属于哪种样本。
在具体的自动驾驶量产项目中,往往会根据实际需求,比如对precision和recall的要求,在与gt匹配的逻辑中,会从类别、大小等角度去考虑,另外还会考虑特殊标记的gt框(hard、dontcare)。
有以下几个原则:
-
数量少的类别A,为其尽可能匹配适当多一点的anchor,数量多的类别B,为其匹配少量且高质量的anchor。这样做目的是提高A的recall,提高B的precision,保证每个batch中,各类别间生成的正样本数量趋于1:1
-
为小目标匹配高质量的anchor,忽略其周围低质量的anchor。这样做是为了减少小目标的误检,可能在一定程度上牺牲了召回。
-
对于中大目标,就要考虑具体那个类别的数量了,数量少的类别匹配多一点,数量多就少匹配。
-
对于特殊标记的gt框,如hard、dontcare, 如果一些负样本和这些hard、dontcare强相关,那么把这些负样本变成ignore,避免让样本间产生歧义。
正负样本的定义过程是一个迭代的过程,会根据模型的实际训练过程以及测试效果来动态调整,比如模型对某个类recall偏低,那么此时我们就要增加该类生成正样本的数量了。
定义的过程就是将正负样本严格区分开,为后续的采样提供方便,如下图,将从正样本过渡到负样本的这些样本归入ignore。
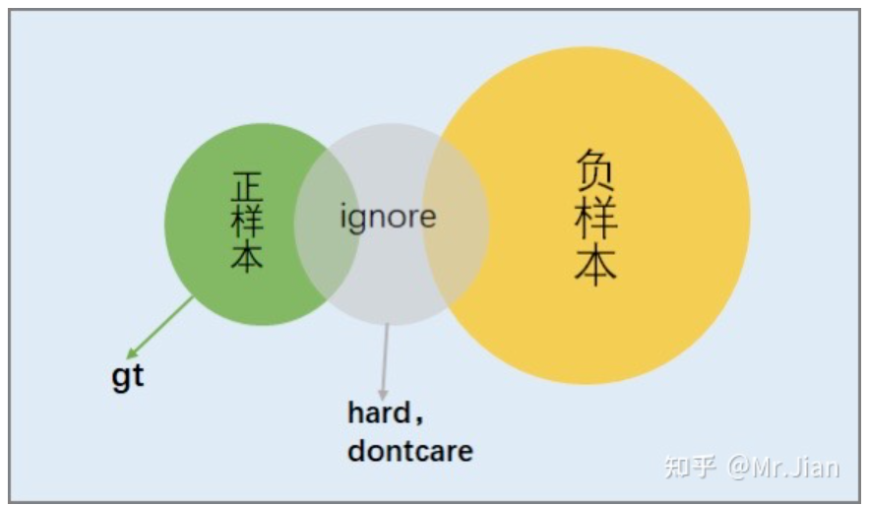
3. 采样哪些正负样本参与训练
个人认为:该部分是训练检测模型最为核心的部分,直接决定模型最后的性能。理解正负样本的训练,实质是理解正负样本的变化是如何影响precision和recall的。
我们先考虑3个基本问题,对于某个类别gt:
-
假设我们希望precision=1,不考虑recall,那么属于该gt的并且参与训练的正负样本理想情况会是什么样的?
正样本:数量越多越好,并且质量越高越好。
负样本:多样性越丰富越好,数量越多越好(实际已经满足数量多的情况)。
-
假设我们希望recall=1,不考虑precision呢?
正样本:数量越多越好。
负样本:数量为0最好。
-
现在我们希望precision=1, recall=1呢?
正样本:数量越多越好,并且质量越高越好。
负样本:多样性越丰富越好,并且数量越多越好。
从以上3个问题分析得到,对于某个类别的gt,属于该gt的正样本中,数量和质量是矛盾的。数量越多,那么质量必然下降,recall会偏高,precision会偏低。反之,数量越少,质量会高,但是recall会偏低,precision会偏高。对于负样本来说,要求它数量越多,并且多样性越丰富,这并不矛盾,实际是可以做到这点。
有人会问,不看mAP吗?
mAP是综合衡量了recall从0到1变化的过程中(实际recall达不到1),precision的变化曲线,mAP并不直观,实际把mAP当做其中一个衡量指标而已。
所以,我们采样的目标就是:
正样本:质量高,数量适当
负样本:多样性越丰富,数量适当(或者说是正样本数量的n倍,n一般取值[3,10])
一般情况下,定义的那些正样本都会采样参与训练,负样本就随机采样一些去训练。但在训练的过程中你需要考虑几点:
-
定义的那些正样本,模型真的都能搞定吗?
在量产级的数据集中,往往会有百千万量级的目标,虽然在定义正样本的时候考虑到了很多因素,但是面对百千万量级的目标,往往会存在一定比例的正样本,模型压根就学不会,训练后期模型loss就在一个小区间里震荡,所以我们就要对这些样本做进一步处理,把其归为ignore,减少他们对模型训练的影响。
对于FN(漏检),我们就要根据具体的需求分析这些FN到底是否需要检出,如果需要检出,就需要调整定义这些FN的正样本的匹配逻辑,让其产生适合训练的正样本。
-
面对数量众多的负样本,怎么针对性的采样(适应自己的项目)。
其实在项目前期,负样本的采样可以选择随机,但当你进行大量路采数据测试后,总结发现模型输出的FP,比如,发现模型输出大框背景的频次偏高,那么这个时候我们就要改变随机采样负样本的策略,就要针对性的增加小分辨率feature map上的负样本的采样。如果模型经常把特定背景(树尖,房屋)检测为目标,那么我们需要1. 检查gt的标注质量。2. 想办法采样到这类的负样本参与训练。
-
尽可能保证每个batch中,类别间采样的正样本比例为1:1。
在量产级数据中,因为是实车采集,往往会出现类别不均衡现象,随着数据量的不断增加,这种不均衡会被严重放大,如果直接采样全部正样本采样训练,模型很可能出现precision和recall偏向类别多的那个类,比如类A,这个时候就需要考虑适当降低类A的采样,同时考虑适当增加类B类C的采样训练,来达成类别间正样本的比例接近1:1。
所以,正负样本的采样是根据当前模型的检测效果来动态改变优化的,但是不管怎么改变,对正负样本的采样不会偏离理想状态的,只不过离理想状态的距离由自己手头的数据集标注质量决定。
6. 微软:多模态大模型GPT-4就在下周,撞车百度?
原文:
https://mp.weixin.qq.com/s/Se3xzcF6rtgcI7YXYgDZ8Q
我们知道,引爆如今科技界军备竞赛的 ChatGPT 是在 GPT-3.5 上改进得来的,OpenAI 很早就预告 GPT-4 将会在今年发布。最近各家大厂争相入局的行动似乎加快了这个进程。
最新消息是,万众期待的 GPT-4 下周就要推出了:在 3 月 9 日举行的一场名为「AI in Focus - Digital Kickoff」的线下活动中,四名微软德国员工展示了 GPT 系列等大型语言模型(LLM)的颠覆性力量,以及 OpenAI 技术应用于 Azure 产品的详细信息。
在活动中,微软德国首席技术官 Andreas Braun 表示 GPT-4 即将发布,自从 3 月初多模态模型 Kosmos-1 发布以来,微软一直在测试和调整来自 OpenAI 的多模态模型。
GPT-4,下周就出
「我们将在下周推出 GPT-4,它是一个多模态的模型,将提供完全不同的可能性 —— 例如视频(生成能力),」Braun 说道,他将语言大模型形容为游戏规则改变者,因为人们在这种方法之上让机器理解自然语言,机器就能以统计方式理解以前只能由人类阅读和理解的内容。
与此同时,这项技术已经发展到基本上「适用于所有语言」:你可以用德语提问,然后用意大利语得到答案。借助多模态,微软和 OpenAI 将使「模型变得全面」。
改变业界
微软德国公司首席执行官 Marianne Janik 全面谈到了人工智能对业界的颠覆性影响。Janik 强调了人工智能的价值创造潜力,并表示,当前的人工智能发展和 ChatGPT 是「iPhone 发布一样的时刻」。她表示,这不是要代替人类工作,而是帮助人们以不同于以往的方式完成重复性任务。
改变并不一定意味着失业。Janik 强调说,这意味着「许多专家会开始利用 AI 实现价值增长」。传统的工作行为正在发生变化,由于新的可能性出现,也会产生全新的职业。她建议公司成立内部「能力中心」,培训员工使用人工智能并将想法整合到项目中。
此外,Janik 还强调,微软不会使用客户的数据来训练模型(但值得注意是,根据 ChatGPT 的政策,这不会或至少不会适用于他们的研究合作伙伴 OpenAI)。

实际用例
微软的两位 AI 技术专家 Clemens Sieber 和 Holger Kenn 提供了关于 AI 实际使用的一些信息。他们的团队目前正在处理具体的用例,他们讲解了用例涉及的技术。
Kenn 解释了什么是多模态人工智能,它不仅可以将文本相应地翻译成图像,还可以翻译成音乐和视频。除了 GPT-3.5 模型之外,他还谈到了嵌入,用于模型中文本的内部表征。根据 Kenn 的说法,「负责任」的 AI 已经内置到微软的产品中,并且可以通过云将数百万个查询映射到 API 中。
Clemens Siebler 则用用例说明了今天已经成为可能的事情,例如可以把电话呼叫的语音直接记录成文本。根据 Siebler 的说法,这可以为微软在荷兰的一家大型客户每天节省 500 个工作小时。该项目的原型是在两个小时内创建的,一个开发人员在两周内完成了该项目。据他介绍,三个最常见的用例是回答只有员工才能访问的公司信息、AI 辅助文档处理和在呼叫中心处理口语的半自动化。
微软表示人们很快就会与其全新的 AI 工具见面。特别是在编程领域,Codex 和 Copilot 等模型可以更轻松地创建代码,令人期待。
当被问及操作可靠性和事实保真度时,Siebler 表示 AI 不会总是正确回答,因此有必要进行验证。微软目前正在创建置信度指标来解决此问题。通常,客户仅在自己的数据集上使用 AI 工具,主要用于阅读理解和查询库存数据,在这些情况下,模型已经相当准确。然而,模型生成的文本仍然是生成性的,因此不容易验证。Siebler 表示微软围绕生成型 AI 建立了一个反馈循环,包括赞成和反对,这是一个迭代的过程。
看来在 AI 大模型的竞争中,领先的一方也加快了脚步。微软在过去一周左右接连发布了展示多模态的语言大模型论文 Kosmos-1 和 Visual ChatGPT,这家公司显然非常支持多模态,希望能够做到使感知与 LLM 保持一致,如此一来就能让单个 AI 模型看文字图片,也能「说话」。
微软的下次 AI 活动选在了 3 月 16 日,CEO 萨蒂亚・纳德拉将亲自上台演讲,不知他们是否会在这次活动上发布 GPT-4。有趣的是,微软的活动和百度推出文心一言选在了同一天。
距离 3 月 16 日百度推出类 ChatGPT 聊天机器人还有一周时间,最近有报道称,百度正在抓紧时间赶在发布最后期限前完成任务。目前看来,百度打算分阶段推出文心一言的各项功能,并首先向部分用户开放公测。知情人士称,在春节假期过后,李彦宏就要求包括自动驾驶部门在内的全公司 AI 研究团队将英伟达 A100 支援给文心一言的开发。
7. 谷歌报复性砸出5620亿参数大模型!比ChatGPT更恐怖,机器人都能用,学术圈已刷屏
原文:https://mp.weixin.qq.com/s/Se3xzcF6rtgcI7YXYgDZ8Q
为应对新一轮技术竞赛,谷歌还在不断出后手。
这两天,一个名叫PaLM-E的大模型在AI学术圈疯狂刷屏。
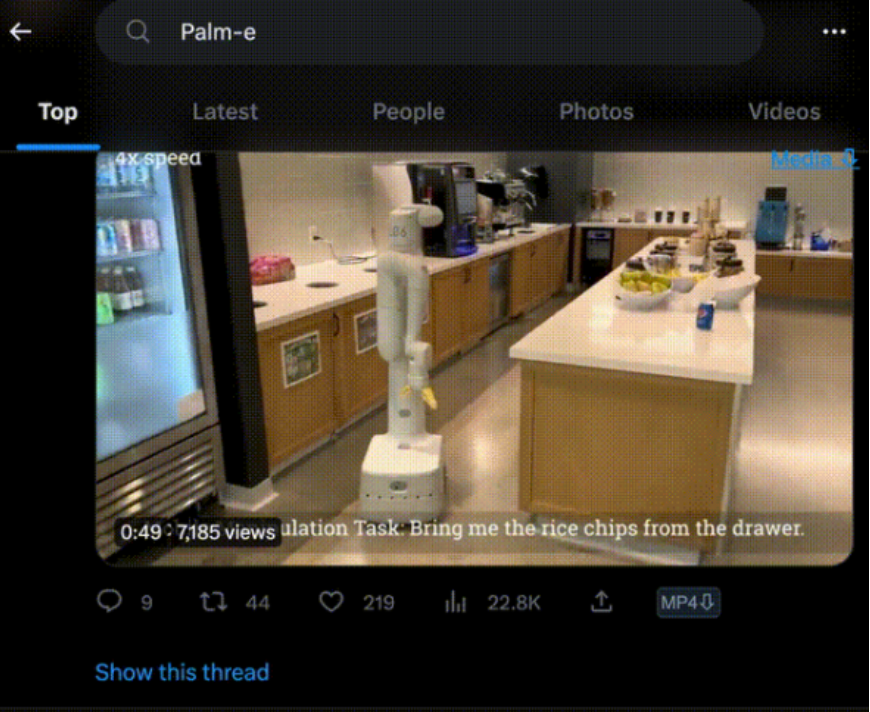
它能只需一句话,就让机器人去厨房抽屉里拿薯片。即便是中途干扰它,它也会坚持执行任务。
PaLM-E拥有5620亿参数,是GPT-3的三倍多,号称史上最大规模视觉语言模型。而它背后的打造团队,正是谷歌和柏林工业大学。
作为一个能处理多模态信息的大模型,它还兼具非常强的逻辑思维。
比如能从一堆图片里,判断出哪个是能滚动的。

还会看图做算数:

有人感慨:
这项工作比ChatGPT离AGI更近一步啊!
而另一边,微软其实也在尝试ChatGPT指挥机器人干活。
这么看,谷歌是凭借PaLM-E一步到位了?
逻辑性更强的大模型
PaLM-E是将PaLM和ViT强强联合。
5620亿的参数量,其实就是如上两个模型参数量相加而来(5400亿+220亿)。
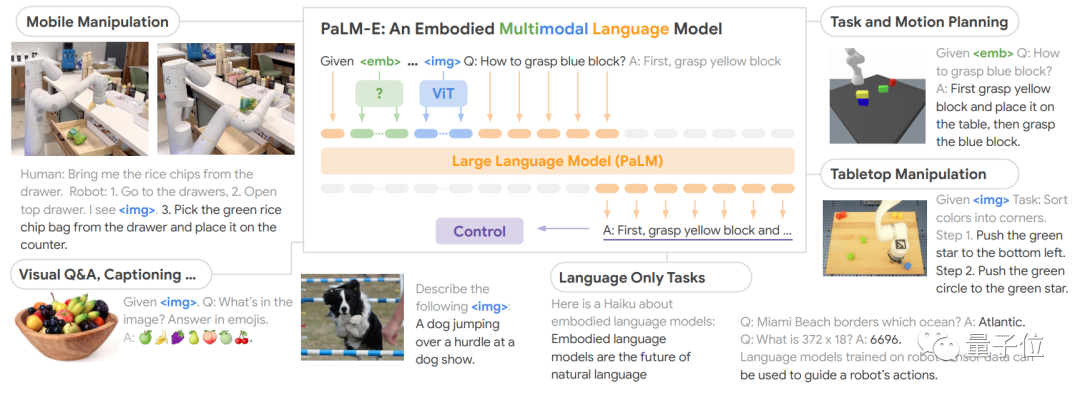
PaLM是谷歌在22年发布的语言大模型,它是Pathways架构训练出来的,能通过“思考过程提示”获得更准确的逻辑推理能力,减少AI生成内容中的错误和胡言乱语。
Pathways是一种稀疏模型架构,是谷歌AI这两年重点发展方向之一,目标就是训练出可执行成千上百种任务的通用模型。
ViT是计算机视觉领域的经典工作了,即Vision Transformer。
两者结合后,PaLM-E可以处理多模态信息。包括:
-
语言
-
图像
-
场景表征
-
物体表征
通过加一个编码器,模型可以将图像或传感器数据编码为一系列与语言标记大小相同的向量,将此作为输入用于下一个token预测,进行端到端训练。
具体能力方面,PaLM-E表现出了比较强的逻辑性。
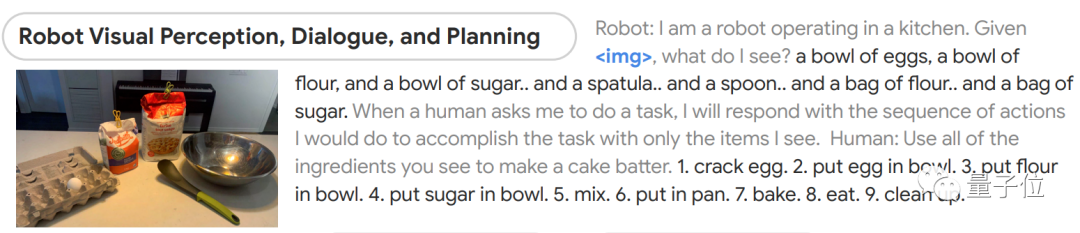
比如给它一张图片,然后让它根据所看到的做出蛋糕。
模型能先判断出图像中都有什么,然后分成9步讲了该如何制作蛋糕,从最初的磕鸡蛋到最后洗碗都包括在内。
再次验证大力出奇迹
目前这项研究已引发非常广泛的讨论。
主要在于以下几个方面:
1、一定程度上验证了“大力出奇迹”
2、比ChatGPT更接近AGI?
一方面,作为目前已知的规模最大的视觉语言模型,PaLM-E的表现已经足够惊艳了。
去年,DeepMind也发布过一个通才大模型Gota,在604个不同的任务上接受了训练。
但当时有很多人认为它并不算真正意义上的通用,因为研究无法证明模型在不同任务之间发生了正向迁移。
论文作者表示,这或许是因为模型规模还不够大。
如今,PaLM-E似乎完成了这一论证。

不过也有声音担心,这是不是把卷参数从NLP引到了CV圈?
另一方面,是从大趋势上来看。
有人表示,这项工作看上去要比ChatGPT更接近AGI啊。
的确,用ChatGPT还只是提供文字建议,很多具体动手的事还要自己来。
但PaLM-E属于把大模型能力拉入到具象化层面,AI和物理世界之间的结界要被打破了。
而且这个趋势显然也是大家都在琢磨的,微软前不久也发布了一项非常相似的工作——让ChatGPT指挥机器人。
除此之外,还有很多人表示,这再一次验证了多模态是未来。
不过,这项成果现在只有论文和demo发布,真正能力有待验证。
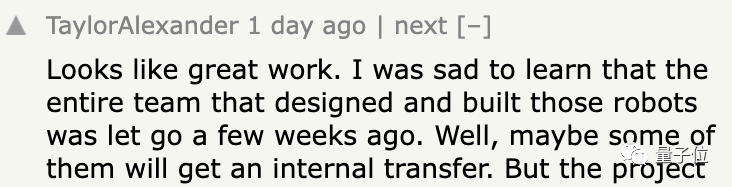
此外还有人发现,模型驱动的机器人,背后的开发团队在几周前被谷歌一锅端了。。。
———————End———————
RT-Thread线下入门培训
如果你愿意在所在城市协调组织活动(包括寻找合适场地或主持或宣传),请扫码填写以下合作信息,我们将尽快联系你;
如果你愿意在所在城市为活动提供场地的支持(场地需要有投影等设备),请扫码填写以下合作信息,我们将尽快联系你;
如果你愿意为活动提供礼品/板卡赞助,请扫码填写以下合作信息,我们将尽快联系你;

巡回城市:青岛、北京、西安、成都、武汉、郑州、杭州、深圳
你可以添加微信:rtthread2020 为好友,注明:公司+姓名,拉进RT-Thread官方微信交流群!
你也可以把文章转给学校老师、公司领导等相关人员,让RT-Thread可以惠及更多的开发者
-
RT-Thread
+关注
关注
32文章
1640浏览量
45210 -
大模型
+关注
关注
2文章
3771浏览量
5273
原文标题:【AI简报20230310】知存科技再推存算一体芯片、微软:多模态大模型GPT-4就在下周
文章出处:【微信号:RTThread,微信公众号:RTThread物联网操作系统】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
安克创新发布Thus™芯片:存算一体架构重塑AI音频新生态


存算一体架构赋能AI眼镜革新:S300芯片定义多模态智能终端新思路

存算一体AI芯片公司九天睿芯完成超亿元B轮融资
后摩尔定律时代,3D-CIM+RISC-V打造国产存算一体新范式

米尔RK3576部署端侧多模态多轮对话,6TOPS算力驱动30亿参数LLM
知存科技荣获2025半导体市场创新表现奖
芯动科技与知存科技达成深度合作

存算一体技术加持!后摩智能 160TOPS 端边大模型AI芯片正式发布

缓解高性能存算一体芯片IR-drop问题的软硬件协同设计
苹芯科技 N300 存算一体 NPU,开启端侧 AI 新征程



评论