 python序列化对象
python序列化对象

1.1 python序列化对象
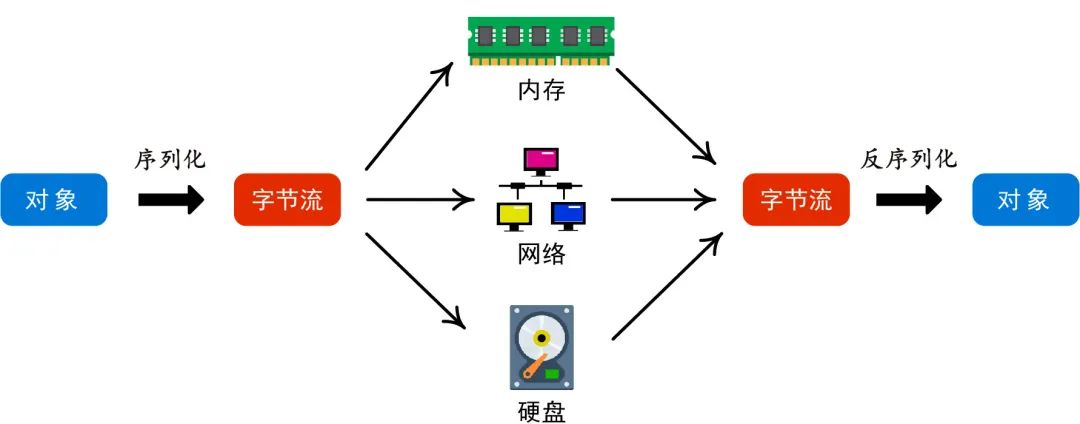
序列化对象:将对象转换为可以存储或传输的形式。
(1) 用于存储:将对象的字节序列存储到文件中,程序退出后不会消失,便于后续使用。
(2) 用于传输:发送方把对象转换为字节序列,接收方字节序列恢复为对象。
反序列化:将存储或传输的字节序列恢复为对象。
| NO | 模块 | 描述 |
|---|---|---|
| 1 | pickle | python对象和字节串间的序列化 |
| 2 | dbm | 通过键访问文件,用于存储字符串 |
| 3 | shelve | 使用pickle和dbm按照键将python对象存储到文件 |
python的pickle模块是对象格式化和解格式化工具。
对象格式化:将对象转换为字节串。
解格式化:用字节串创建原始对象。
把对象转为pickle字符串,存储在文件中,进行持久化保存。
从文件载入pickle字符串,通过unpickle操作,创建原始对象。
shelve将pickle字符串,按键值模式,存储在dbm文件中。
shelve从dbm文件按键获取pickle字符串,创建原始对象。
shelve通过键存储和获取本地python对象,到达跨程序运行和持久化的效果。
python通过shelve模块将python对象存储到本地文件,以及从本地文件恢复python对象。
1.2 shelve存储python对象
用法
import shelve
db=shelve.open(filename, flag='c', protocol=None, writeback=False)
db['k']=value
db.close
with shelve.open(filename, flag='c', protocol=None, writeback=False) as db:
db['k']=value
pass
描述
import shelve:导入shelve模块
filename:文件名,生成shelve文件时的名字
flag:
| NO | flag值 | 描述 |
|---|---|---|
| 1 | r | 只读模式打开文件 |
| 2 | w | 读写模式打开文件 |
| 3 | c | 读写模式打开文件,文件不存在则新建 |
| 4 | n | 创建一个新的、空数据的文件 |
protocol:序列化模式,1或2表示二进制形式
writeback:缓存回写。True,表示在close的时候,将缓存中的全部对象重新写入到shelve文件。
db**[ 'k' ]=**value:字典方式赋值向shelve文件写数据
db**.**close:关闭文件连接
生成.bak,.dat,.dir文件。
示例
>>> import os
>>> os.chdir(r'E:\\documents\\F盘')
>>> from myperson import MyPerson,MyManager
>>> import shelve
>>> mp1 = MyPerson('mp1')
>>> mp2 = MyPerson('mp2','c++开发',20000)
>>> mm1 = MyManager('mm1','开发经理',50000)
# 普通open()
>>> sdb = shelve.open('mypersondb')
>>> for obj in (mp1,mp2,mm1):
sdb[obj.name] = obj
>>> sdb.close()
>>> import glob
>>> glob.glob('myperson*')
# 生成 .bak,.dat,.dir 文件
['myperson.py', 'mypersondb.bak', 'mypersondb.dat', 'mypersondb.dir']
# with shelve.open()
>>> with shelve.open('withopendb') as wdb:
for obj in (mp1,mp2,mm1):
wdb[obj.name] = obj
>>> glob.glob('withopen*')
['withopendb.bak', 'withopendb.dat', 'withopendb.dir']
1.3 读取shelve文件
打开shelve文件后,跟使用字典一样访问数据。
可以用[]或get读取数据。
>>> rdb = shelve.open('mypersondb')
>>> len(rdb)
3
>>> list(rdb.keys())
['mp1', 'mp2', 'mm1']
>>> for k in rdb:
print(k,'->',rdb[k])#[]获取字典数据
mp1 -> MyPerson:job=None,name=mp1,pay=0
mp2 -> MyPerson:job=c++开发,name=mp2,pay=20000
mm1 -> MyManager:job=开发经理,name=mm1,pay=50000
rdb.close()
>>> with shelve.open('mypersondb') as srdb:
for k in srdb:
print(k,'->',srdb.get(k))#get 获取字典数据
mp1 -> MyPerson:job=None,name=mp1,pay=0
mp2 -> MyPerson:job=c++开发,name=mp2,pay=20000
mm1 -> MyManager:job=开发经理,name=mm1,pay=50000
1.4 更新shelve文件
可以调用shelve文件存储的python对象所有的方法更新对象数据。
| NO | writebacke | 描述 |
|---|---|---|
| 1 | False | 通过中间变量存放对象并进行更新,之后再指向中间变量,close后进行保存。 |
| 2 | True | 可以不用中间变量,close的时候会自动将缓存中全部对象重新写到shelve文件。 |
>>> rdb = shelve.open('mypersondb')
# 从shelve文件获取对象,用中变量存放
>>> mm1=rdb['mm1']
>>> print(mm1)
MyManager:job=开发经理,name=mm1,pay=50000
>>> type(mm1)
# 调用对象方法更新数据
>>> mm1.payraise(0.1)
# 更新shelve对象指向最新的对象
>>> rdb['mm1']=mm1
# close()后保存shelve文件
>>> rdb.close()
>>> rdb = shelve.open('mypersondb')
>>> print(rdb['mm1'])
# 获取的对象为更新后的对象
MyManager:job=开发经理,name=mm1,pay=60000
>>> rdb.close()
# writebacke=True,close时自动将缓存数据重新写到shelve文件。
>>> rdb = shelve.open('mypersondb',writeback=True)
>>> print(rdb['mm1'])
MyManager:job=开发经理,name=mm1,pay=60000
>>> rdb['mm1'].payraise(0.1)
>>> rdb.close()
>>> rdb = shelve.open('mypersondb')
>>> print(rdb['mm1'])
MyManager:job=开发经理,name=mm1,pay=72000
>>> rdb.close()
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
存储
+关注
关注
13文章
4693浏览量
89567 -
python
+关注
关注
57文章
4857浏览量
89569
发布评论请先 登录
相关推荐
热点推荐
如何使用Serde进行序列化和反序列化
Serde 是一个用于序列化和反序列化 Rust 数据结构的库。它支持 JSON、BSON、YAML 等多种格式,并且可以自定义序列化和反序列化方式。Serde 的特点是代码简洁、易于
Java序列化的机制和原理
本文讲解了Java序列化的机制和原理。从文中你可以了解如何序列化一个对象,什么时候需要序列化以及Java序列化的算法。AD:WOT2014课
发表于 07-10 07:27
c语言序列化和反序列化有何区别
这里写自定义目录标题c语言序列化和反序列化tplut.htplut.c测试代码参考c语言序列化和反序列化网络调用,数据传输都需要把数据序列化
发表于 07-14 07:32
SpringMVC JSON框架的自定义序列化与反序列化
的JSON请求反序列化为对象时,就会出现String类型的值,前后有空格,现需要一个统一的处理方法,对接收的String类型属性执行trim方法。解决方案SpringMVC默认的JSON框架为jackson
发表于 10-10 16:02
Java对象序列化您不知道的5件事
本文是本系列的第一篇文章,这个系列专门揭示关于 Java 平台的一些有用 的小知识 — 这些小知识不易理解,但对于解决 Java 编程挑战迟早有用。
将 Java 对象序列化 API 作为
发表于 11-23 17:53
•20次下载
分享一个最新的的Python对象序列化方式
许多Python标准库都有一些未被赏识的精华。其中之一是允许简单优雅的基于参数类型的函数分发。这一特性对于任意对象的序列化而言是非常完美的——例如对于web API的JSON或结构化日

蚂蚁集团开源高性能多语言序列化框架Fury解读
Fury 是一个基于 JIT 动态编译和零拷贝的多语言序列化框架,支持 Java/Python/Golang/JavaScript/C++ 等语言,提供全自动的对象多语言 / 跨语言序列化

什么是序列化 为什么要序列化
什么是序列化? “序列化”(Serialization )的意思是将一个对象转化为字节流。 这里说的对象可以理解为“面向对象”里的那个
如何用C语言进行json的序列化和反序列化
json是目前最为流行的文本数据传输格式,特别是在网络通信上广泛应用,随着物联网的兴起,在嵌入式设备上,也需要开始使用json进行数据传输,那么,如何快速简洁地用C语言进行json的序列化和反序列化
Java序列化怎么使用
转换方式就叫做序列化。将文件或者网络传输中得到的 byte[] 数组转换为 java 对象就叫做反序列化。 怎么使用 如果一个 Java 对象要能被
什么时候需要Boost序列化
() const { return m_strName;} private :std::string m_strName;}; 然后我们想把这个类的一个对象保存到文件中或者通过网络发出去,怎么办呢?答案就是:把这个对象序列化





 工商网监
工商网监
评论