 2分钟看懂快速排序的算法
2分钟看懂快速排序的算法

之前有同学提出想要复习一下排序算法,那我们今天就挑一个难度中等的,快速排序。
先搞清楚快速排序原理,然后再写代码。
快速排序的原理不难,先找到一个数字,我们把它称作基准,然后通过一系列的比较交换,能让基准达到一个合适的位置,保证基准前面的数字都比他小,后面的数字都比他大。
这个过程需要两个指针 x 和 y,其实就是数组的下标,x指向数组第一个数字,y指向数组最后一个数字。
为了操作方便,我们一般以第一个数字为基准。
先把他记下来。
然后从 y 开始,4比3大,不用管,y 向前移动。
2比 3 小,比基准小的数字应该放在左边,所以把 2 移动到前面,同时 x 向后移动。
6比 3 大,放在后面,y 向前移动。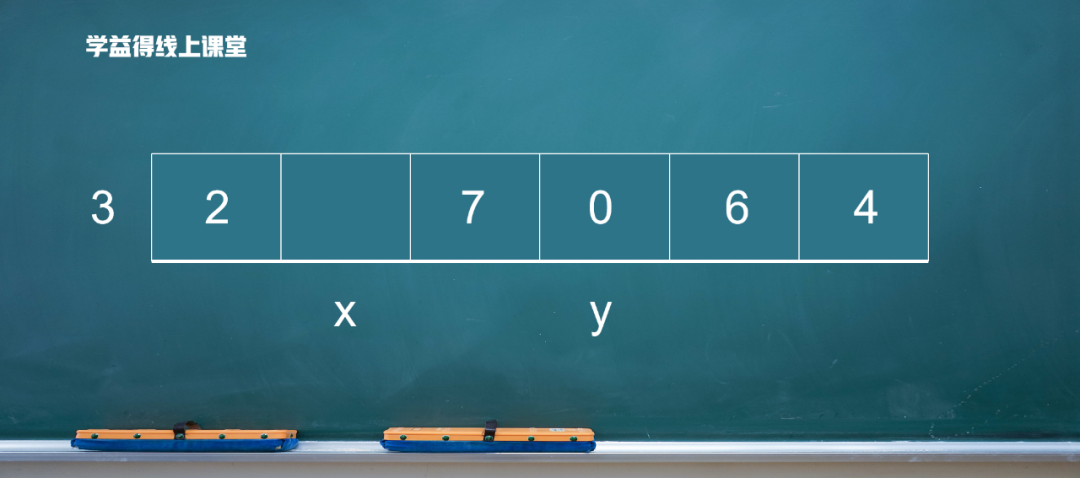
0比3小,放在前面,x向后移动。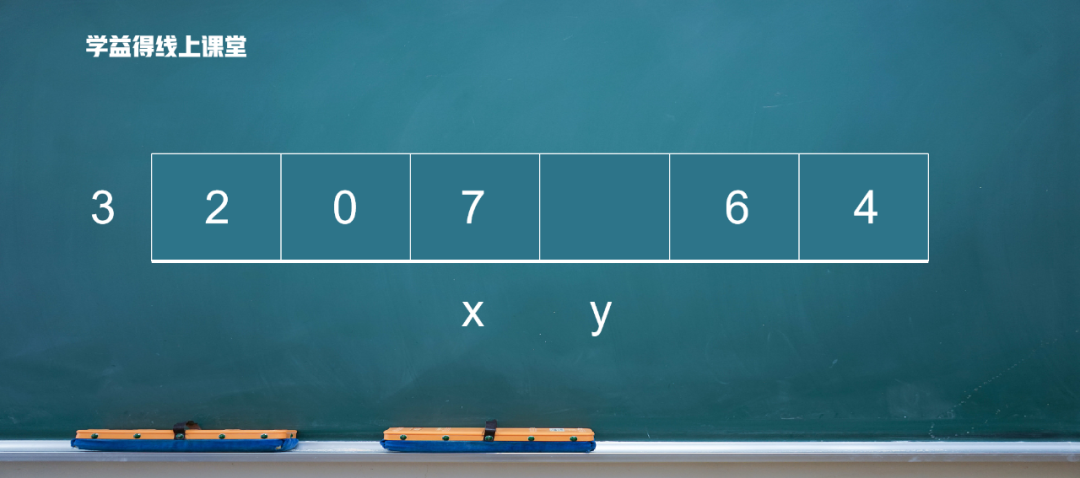
7比3大,放在后面,y 向前移动。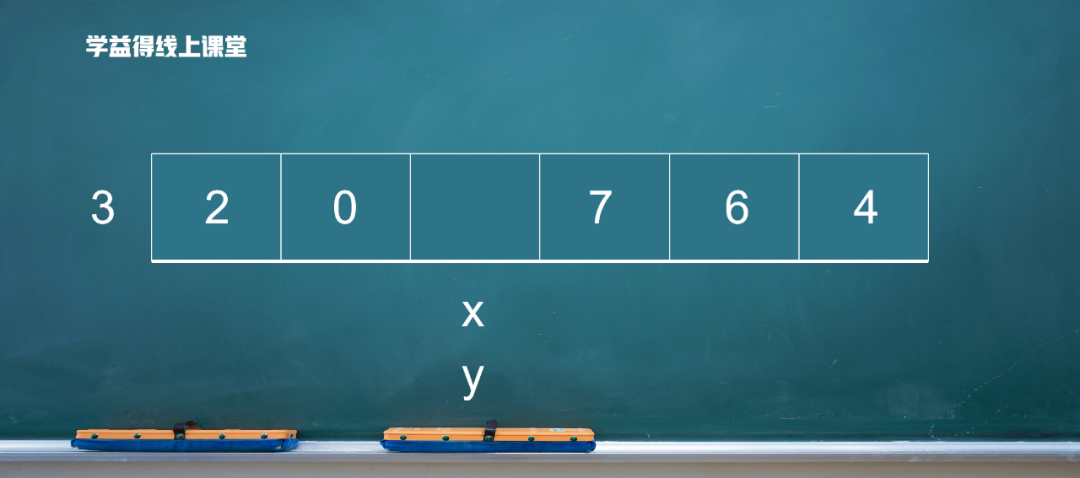
最后,x 和 y 相等,把3放到这个位置上。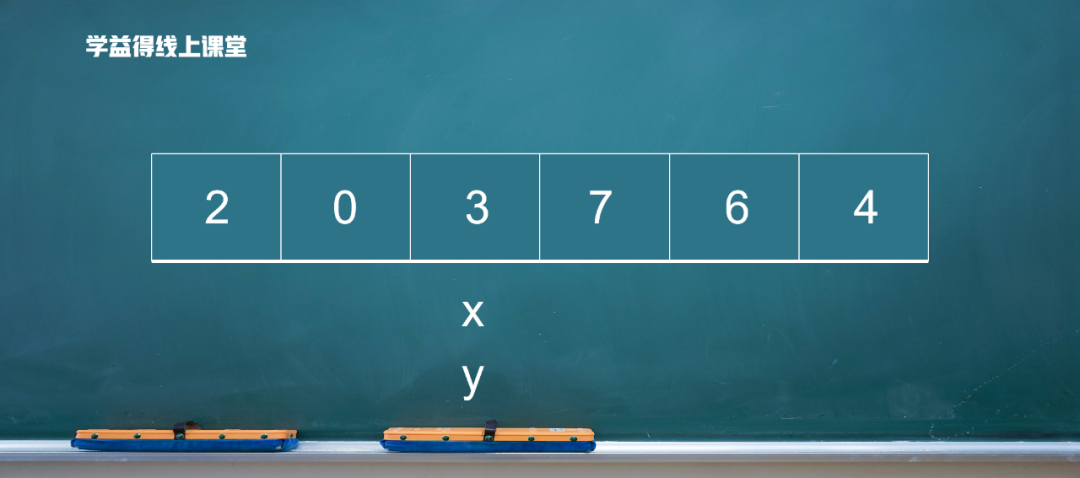
第一轮移动结束。现象就是,3的前面都是比3小的,3的后面都是比3大的。
接下来就是对3的前面和3的后面做同样的操作,我们应该立马能想到递归。
搞清楚了原理还不够,作为求职者把代码写出来才是王道。
#include快速排序是不是真的很快? 我们可以和冒泡排序做个对比,修改下代码,随机产生5万个数据,使用冒泡排序和快速排序,时间上的差别确实很大。void quick_sort(int *a, int start, int end) { if (start >= end) return; int x = start; int y = end; int base = a[start]; while (x < y) { while (a[y] > base && x < y) { y--; } if (x < y) { a[x++] = a[y]; } while (a[x] < base && x < y) { x++; } if (x < y) { a[y--] = a[x]; } } a[x] = base; quick_sort(a, start, x - 1); quick_sort(a, x + 1, end); } int main() { int array[] = {3, 6, 7, 0, 2, 4}; quick_sort(array, 0, 6); for (int i = 0; i < 6; i++) { printf("%d ", array[i]); } return 0; }
冒泡排序:
real 0m8.255s user 0m8.098s sys 0m0.008s快速排序:
real 0m0.078s user 0m0.010s sys 0m0.000s要说原因的话,冒泡排序只能相邻位置上比较移动,但是快速排序却可以跳着来,所以大部分情况下,快速排序效率都要高于冒泡排序。
审核编辑:刘清
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
排序算法
+关注
关注
0文章
53浏览量
10482 -
Array
+关注
关注
103文章
19浏览量
20004
原文标题:2分钟看懂快速排序
文章出处:【微信号:学益得智能硬件,微信公众号:学益得智能硬件】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
热点推荐
matlab快速排序算法实现
待排的记录分割成独立的两部分,%其中前一部分的 记录的关键字均比另一部分记录的关键字小,%再分别对两组记录进行递归分割,达到排序的目的%平均时间复杂度为O(log2(n))functi
发表于 02-29 15:58
嵌入式stm32实用的排序算法 - 交换排序
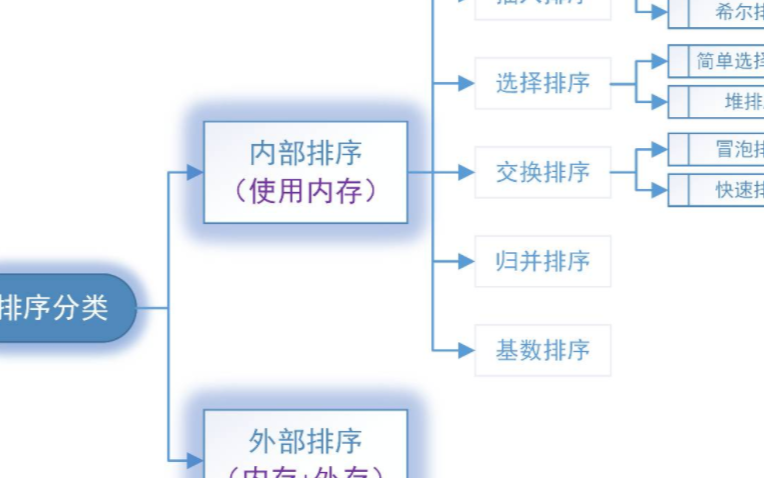
合很多,我这里就不再一一举例说明,掌握排序的基本算法,到时候遇到就有用武之地。Ⅱ、排序算法分类1.按存储分类:内部排序和外部
发表于 04-12 13:14
基于Hadoop的几种排序算法研究
如何高效排序是在对大数据进行快速有效的分析与处理时的一个重要问题。首先对基于Hadoop平台的几种高效的排序算法(Quicksort,Heapsort和Mergesort
发表于 11-08 17:25
•15次下载

C语言排序中快速排序的技巧
快速排序是由东尼·霍尔所发展的一种排序算法。在平均状况下,排序 n 个项目要Ο(n log n)次比较。在最坏状况下则需要Ο(n

排序算法有哪些
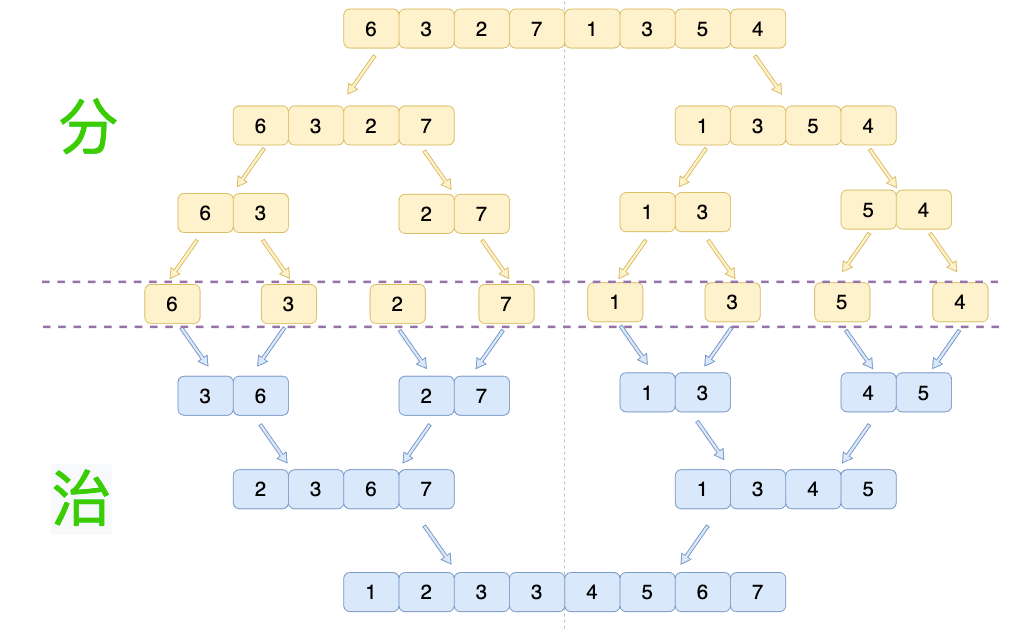
合并 我们来具体看看例子,假设我们现在给定一个数组:[6,3,2,7,1,3,5,4],我们需要使用归并算法对其排序,其大致过程如下图所示: 分 阶段可以理解为就是 递归拆分子序列 的




评论