 存内计算的前景如何
存内计算的前景如何

近日,有国内芯片推出来了一款比较前沿的芯片产品,它就是存算一体化芯片。
据媒体报道,知存科技这款芯片是全球首颗商用存内计算SoC,它的功耗低至1毫安,它就是WTM2101芯片,是全球首颗商用存内计算SoC。
知存科技介绍,WTM2101可使用sub-mW级功耗完成大规模深度学习运算,特别适合可穿戴设备中的智能语音和智能健康服务。
一、这款芯片的优势:
1.基于存算一体技术,实现NN VAD和上百条语音命令词识别
2.超低功耗实现NN环境降噪算法、健康监测与分析算法
3.典型应用场景下,工作功耗均在微瓦级别
4.采用极小封装尺寸
据半导体芯情了解到,存内计算是一种新型架构的芯片,相比当前的计算芯片采用冯诺依曼架构不同,存内计算是计算与数据存储一体,可以解决内存墙的问题,该技术60年代就有提出,只是一直没有商业化。
据该公司创始人、CEO王绍迪介绍,这款芯片是知存科技首次尝试在低功耗场景下量产的存内计算芯片,一般运行功耗在1毫安至5毫安之间。
此前还有报道,除了WTM2101芯片,知存科技也针对更高性能的视频增强场景正在开发WTM8系列芯片,新一代架构可以在单核提升算力80倍,提升效率10倍,目前验证芯片已经回片,预计2023年正式发布。
二、为什么需要存内计算芯片?
芯片最核心的价值之一就是运算,那如何让它运算能力更牛呢?在摩尔定律的时代,我们可以用先进制程,更小体积,更多晶体管,算力增强。如果制程一样,先进封装也是可以提高产品性能(半导体芯情在这里不做阐述。)
但是,随着先进制程逼近1nm的物理极限,摩尔定律不可避免的放缓,即便是在日常生活中,人们也能感受到手机Soc、电脑的CPU的升级换代效果越来越差,从过去的每代提升40%性能迅速下降至20%甚至10%。

与之对应的是,当今社会对数据、算力、芯片性能的要求却越来越高,整个下游市场既然有庞大的需求出现,那么整个产业链的各方都在想方设法来提高芯片的性能,既然传统的在晶圆上改进工艺的方式进展缓慢,那么在更上层的计算机架构上动刀或许会有意想不到的收获。

今年以来,一些跳出传统计算机结构体系的设想正在转为研究成果出现在各大顶级期刊上,它就是“存内计算”。
存内计算,顾名思义就是把计算单元嵌入到内存当中。通常计算机运行的冯·诺依曼体系包括存储单元和计算单元两部分,计算机实施运算需要先把数据存入主存储器,再按顺序从主存储器中取出指令,一条一条的执行,数据需要在处理器与存储器之间进行频繁迁移,如果内存的传输速度跟不上CPU的性能,就会导致计算能力受到限制,即“内存墙”出现,例如,CPU处理运算一道指令的耗时假若为1ns,但内存读取传输该指令的耗时可能就已达到10ns,严重影响了CPU的运行处理速度。
三、存内计算芯片它解决了哪些问题,前景如何?

王绍迪指出,存内计算概念实际在上世纪60年代就被很早的提出,但一直以来都没有真正技术落地,直到最近10年间,业界开始在这条技术路径上做更多的研究,原因正是摩尔定律的极限已经越来越近。
在如今最先进的5纳米和3纳米芯片制造工艺之间,SRAM存储器的密度并没有提升。王绍迪称,从7纳米到5纳米演进时,其SRAM存储器密度提升也非常有限,尚不足20%。这也意味着,与芯片制造工艺中摩尔定律逐渐失效相比,存储器的发展速度更慢,芯片的算力越来越大、核数越来越多,但实际每个核能够使用的存储器资源越来越少,因为存储器的密度、带宽和存储速度都远低于计算芯片的算力提升,这便是业内称之为“内存墙”的问题。
关于内存墙,王绍迪指出:“在如今AI计算时代下,随着数据量爆炸式增长,计算中数据的搬运量也越来越多,而芯片计算中有超过80%的时间和95%的能耗都被消耗在数据搬运过程中。因此,内存墙的问题在最近十年中越来越严重,业内开始重新寄希望于用存内计算去解决内存墙的问题。”
-
cpu
+关注
关注
68文章
11378浏览量
226509 -
soc
+关注
关注
40文章
4663浏览量
230676 -
存内计算
+关注
关注
0文章
35浏览量
1684
原文标题:存内计算前景如何?能成为颠覆传统芯片的爆款吗?
文章出处:【微信号:ikuxing,微信公众号:半导体芯情】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
ISSCC 2026重磅:清华+华为+字节联合发布存内计算芯片,重塑推荐系统能效边界

安克与知存科技联合打造Thus存算一体AI音频芯片
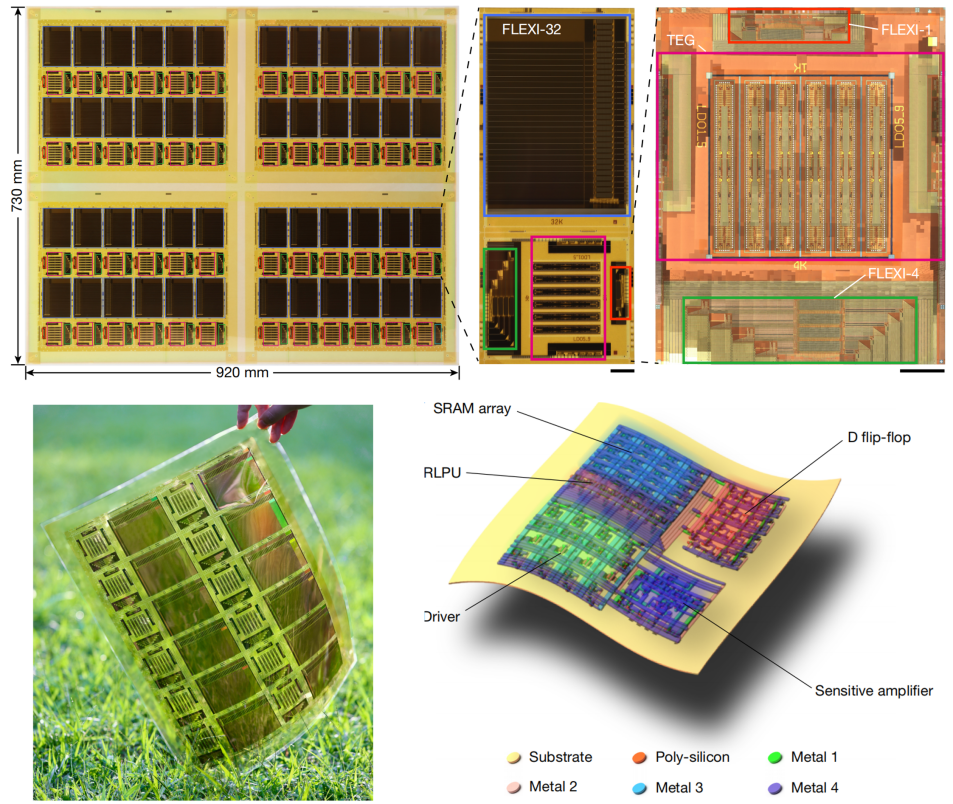
每片低至0.016美元!清华FLEXI芯片柔性+存内计算双突破
知存科技王绍迪:AI可穿戴需求爆发,存算一体成主流AI芯片架构

存内计算芯片,热度大增

知存科技荣获2025半导体市场创新表现奖
芯动科技与知存科技达成深度合作
一文看懂“存算一体”
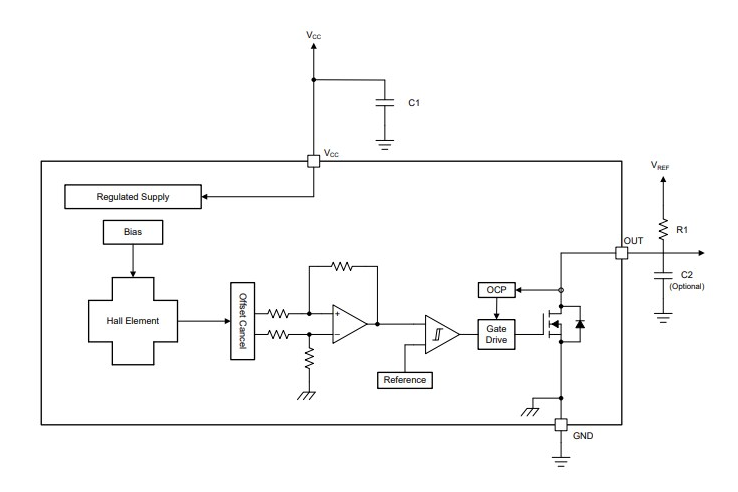
Texas Instruments TMAG5213霍尔效应锁存器数据手册
知存科技助力北京大学校友论坛圆满落幕
知存科技邀您相约第二十一届全国容错计算学术会议
缓解高性能存算一体芯片IR-drop问题的软硬件协同设计
“算存平衡”有多重要?
高性能计算集群在AI领域的应用前景



评论