 文本分割技术的应用场景
文本分割技术的应用场景

写在前面
之前看了一篇很不错的外文博客,结合自己查阅学习的一些论文和资料,加上自己的理解,整理了一些内容,准备来跟大家分享关于文本分割任务的相关内容。
文本分割任务的目的是将文本划分为若干有意义的文本块,不同的分割目的有不同的分割粒度,比如:词、句子或者主题。
今天我们将要分享的文本分割任务的分割粒度聚焦在主题上,这类文本分割任务也称为主题分割:识别文本主题的过渡从而将长文本划分若干具有不同主题的文本块。
1. 不同的文本形式
文本分割非常实用。在日常生活学习中,我们会接触到各种各样的文本:
- 书面文本,如:博客、文章、新闻等
-
各种转录文本(即记录文本):
- 电视新闻的转录
- 播客的转录
- 电话的转录
- 在线会议的转录
这些文本通常都非常长,需要利用文本分割技术来处理这些文本,将它们按照主题的转移或变化划分为若干主题段落,每个主题段落内部所表达的主题一致且连贯,不同主题段落间则描述不同的主题。
当然,针对不同的文本,“主题”定义不同。比如:新闻文本分割中,主题可能是指一则新闻故事(Story);在线会议转录文本分割中,主题可能指的是不同的会议议题。无论“主题”代表的是什么,利用文本分割技术划分长文本最直接的目的都是增加文本的可读性。
当然以上这些文本中可能含有各种会影响文本分割结果的噪声,最常见的就是错别字。当然在英文场景下还可能有拼写错误、语法错误,在自动转录的情况下出现使用不当的单词。
转录需要自动识别语音并将所说的内容转录成等效的书面格式(依赖ASR技术),所以通常来说相对于书面文本,转录文本中含有更多的噪声,尤其是在线会议的转录文本。这点很容易理解,因为在线会议中,参会人有各种各样的口音、网络连接质量也常常不太稳定、参会人使用的介质(麦克风)的质量也参差不齐。
2. 文本分割技术的应用场景
通过前面的介绍,我们已经了解了文本分割(主题分割)任务是什么以及它所处理的文本的各种形式,现在我们一起来看看文本分割的应用场景。
2.1 增加可读性
现在给你两篇文章:一篇没有任何章节名称、没有任何段落,就只是长长的文本字符串;另一篇分段合理,每个自然段落过渡合理,逻辑自洽。
你愿意读哪一篇?不用想,当然是第二篇。文本分割最基础的作用就是将冗长的文本划分为读者更易阅读的一个个文本块,也就是把形如第一篇的文章变成第二篇。
2.2 更全面的摘要
文本摘要技术是用于总结提炼文章的。通常我们在阅读文章前,可以先通过文章的摘要了解内容概况,如果感兴趣再逐字逐句进行精读。就跟我们挑选要去电影院看的电影一样,先看简介,看看是不是自己的菜,免得浪费电影票和自己的时间。
但是,多数文本摘要模型在处理多主题的文章上效果还没那么好,生成的摘要通常很难囊括文章所涵盖的所有主题。
在处理多主题文章时,一个很直接且有效的解决方案就是,先利用文本分割模型将文章分成若干个具有不同主题的文本块,再利用摘要模型为每个文本块生成摘要,在进行进一步的组织和编排。
2.3 视频转文章
融合媒体时代,新闻报道需要以不同的形式(如:视频、文章、博客等)分发至不同的渠道(如:短视频app、微信、微博等)。借助ASR技术,我们可以将新闻视频中的语音文本提取出来并转化成书面格式。为增加可读性,再利用文本分割技术将转换的书面文本划分成有意义的段落,组织成更适合阅读的形式。
当然文本分割技术在信息检索、写作助手、对话建模等等其他NLP下游任务上也有其相应的应用。
3. 文本分割任务的评价指标
文本分割任务是识别文本主题的过渡从而将长文本划分若干具有不同主题的文本块。所以,如下图所示文本分割模型实际上就是在对文本中的每个句子进行二分类,判断每个句子是否是分割边界(也就是文本块的最后一句)。

在这样一个任务上,比较常用的评价指标有:Precision&Recall(也就是我们在《二分类任务评价指标(中)》介绍过的查准率和查全率)、Pk、WindowDiff。
3.1 Precision & Recall
3.1 Precision & Recall的含义
既然文本分割(主题分割)本质上是在句子级的二分类任务,那么自然可以使用Precision与Recall,对应的含义如下:
- Precision(查准率):衡量了“被判别为分割边界的句子中有多少比例是真正的边界” ;
- Recall(查全率):衡量了“所有真正的分割边界中有多少比例被模型识别出来了” ;
3.2 Precision & Recall 的问题
然而,Precision&Recall这两个指标对“near miss”不敏感。

在上图中,Ref 是 ground truth,每个块代表一个句子,垂直线表示真实的分割边界。A-0 与 A-1 是两个文本分割模型。
从图中可以清楚地看到,模型 A-0 预测的分割边界非常接近 ground truth,这就是所谓的“near miss”,即预测结果与真实结果偏离得很少,大概一两句话。另一方面,模型 A-1 预测的分割边界与ground truth 就差得远了。
也就是说,虽然两个模型都没有预测正确,但从“near miss”角度来看,模型 A-0 相对优于模型 A-1。但是,Precision&Recall指标可不会考虑这些,它们不在乎预测边界与真实边界的相对距离,只管预测正确与否,所以 A-0 与 A-1 从Precision、Recall值来看效果是相当的。
3.2 Pk 指标
3.2.1 Pk 指标定义
针对 “near miss”, Beeferemen 等人提出了Pk指标。

Pk是基于滑动窗口计算的,窗口大小可以自行指定,如果没有指定一般就取真实文本段平均长度的的一半。在滑动窗口的同时,判断窗口的两端的节点是否属于同一文本段,并比较真实结果与模型预测的结果是否一致,最后将不一致的数量除以滑动次数即可得到Pk值。所以模型的Pk值越低,说明模型预测得越好。
Pk指标在nltk中有相应实现,可以直接调用(nltk.pk[1]):
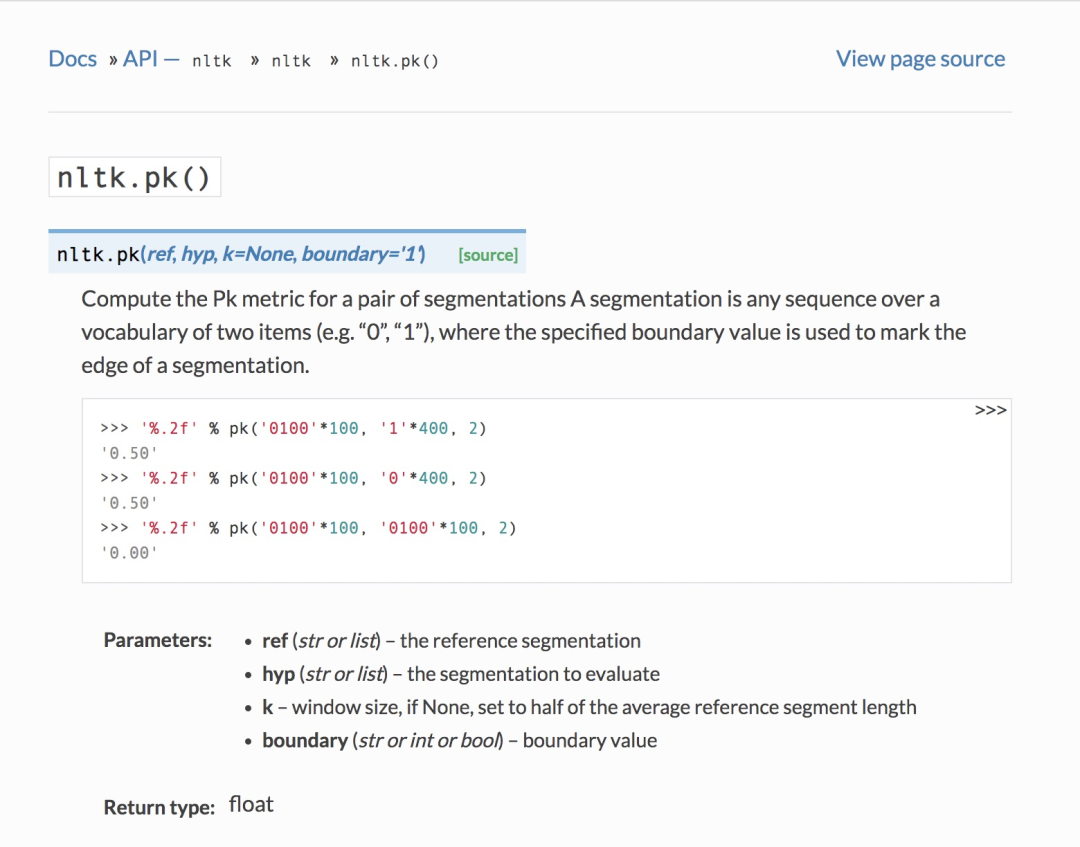
下面是Pk的实现源码(为了便于大家结合定义看代码实现,小喵已经在下面的源代码中添加了相应注释):
#Beeferman'sPktextsegmentationevaluationmetric
[docs]defpk(ref,hyp,k=None,boundary='1'):
"""
ComputethePkmetricforapairofsegmentationsAsegmentation
isanysequenceoveravocabularyoftwoitems(e.g."0","1"),
wherethespecifiedboundaryvalueisusedtomarktheedgeofa
segmentation.
>>>'%.2f'%pk('0100'*100,'1'*400,2)
'0.50'
>>>'%.2f'%pk('0100'*100,'0'*400,2)
'0.50'
>>>'%.2f'%pk('0100'*100,'0100'*100,2)
'0.00'
:paramref:thereferencesegmentation
:typeref:strorlist
:paramhyp:thesegmentationtoevaluate
:typehyp:strorlist
:paramk:windowsize,ifNone,settohalfoftheaveragereferencesegmentlength
:typeboundary:strorintorbool
:paramboundary:boundaryvalue
:typeboundary:strorintorbool
float
"""
#若k未指定,则k设置为真实分割结果中文本段平均长度的一半
ifkisNone:
k=int(round(len(ref)/(ref.count(boundary)*2.)))
#不匹配计数
err=0
#滑动
foriinxrange(len(ref)-k+1):
#判断是否属于同一文本段,只需要判断窗口内是否出现了分割边界,若出现了就不属于同一文本段
r=ref[i:i+k].count(boundary)>0
h=hyp[i:i+k].count(boundary)>0
ifr!=h:
err+=1
#pk值为不匹配次数除以总的滑动次数
returnerr/(len(ref)-k+1.)
3.2.2 Pk 指标问题
Pk指标也存在一些问题:
- 对文本块大小过于敏感
- 没有考虑分割边界数量
- 假负例比假正例更易受到惩罚
- 对于“near miss”处罚太多
对Pk指标存在的问题感兴趣的读者可以细读相关论文。小喵在这里仅针对“假负例比假正例更易受到惩罚”展开提一下。
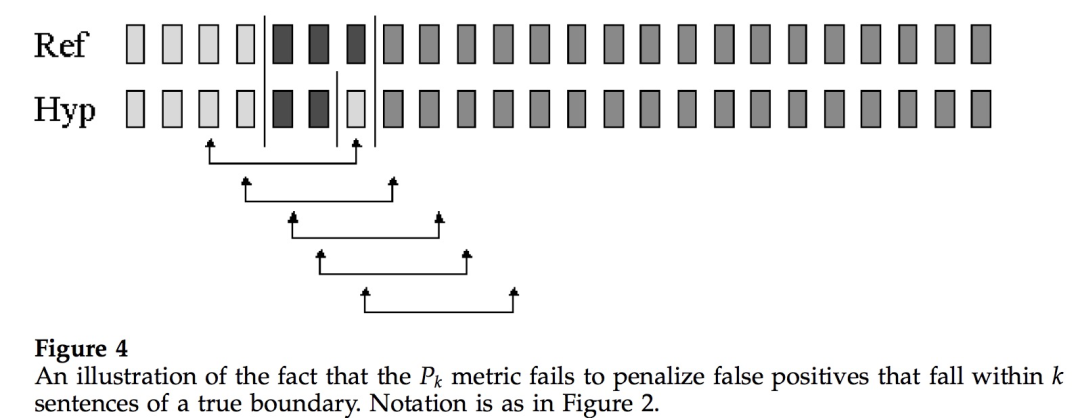
我们来看上面这幅图,图中滑动窗口大小为4 (表示在窗口两端点内潜在的分割边界数为4)。模型将两个真实的分割边界都预测了出来,同时也多预测了一个(即假正例,本来不是分割边界的被预测为分割边界)。
但是从Pk的定义来看,在每一个窗口内,模型预测与真实结果都是一致的,即窗口两端情况都是一样的,要么都是在同一文本段内,要么都在不同文本段内。也就是说只要窗口两端情况一致,不管窗口内部情况如何,Pk都认为模型做对了,这样“假正例”逃脱了惩罚。
3.3 WindowDiff 指标
针对Pk指标存在的问题,WindowDiff指标被提了出来(《A Critique and Improvement of an Evaluation Metric for Text Segmentation》[2])。
WindowDiff指标也是基于滑动窗口计算。不同的是,WindowDiff指标直接判别在窗口内部真实结果与预测结果分割边界数量的异同。
也就是说Pk与WindowDiff的计算类似,都是在分割结果上每次移动一个固定大小的窗口,并在窗口内计算模型预测结果与真实结果不匹配情况,最终求平均。不同之处在于,Pk是从“窗口两端的句子是否位于同一个文本”的角度来判断,而WindowDiff则是根据“窗口内所包含的分割边界个数”来判断。
同样地,模型的WindowDiff值越低,说明模型预测的分割边界与真实的分割边界越接近,模型预测得越好。
WindowDiff在nltk中也有相应的实现(nltk.windowdiff()[3]):
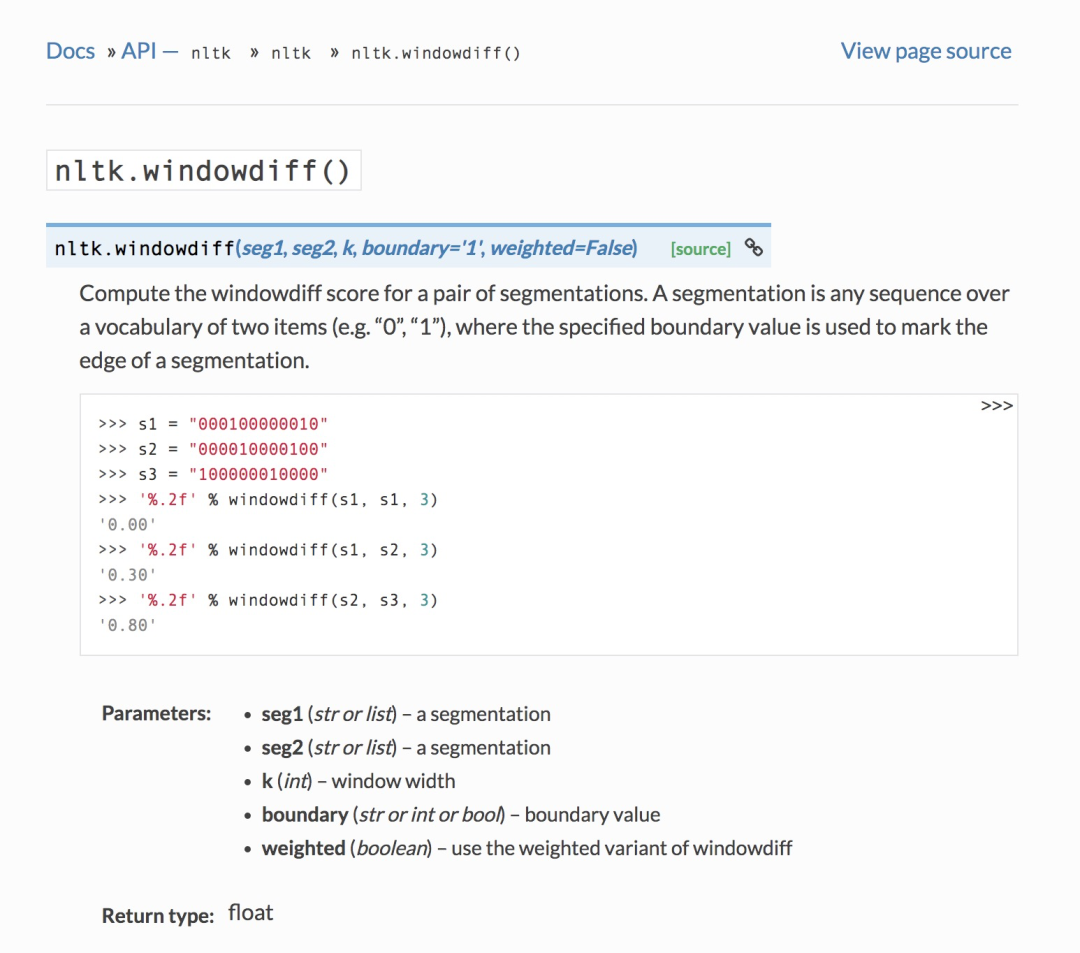
下面是WindowDiff的实现源码(小喵也在代码中添加了相应注释):
defwindowdiff(seg1,seg2,k,boundary="1",weighted=False):
"""
Computethewindowdiffscoreforapairofsegmentations.A
segmentationisanysequenceoveravocabularyoftwoitems
(e.g."0","1"),wherethespecifiedboundaryvalueisusedto
marktheedgeofasegmentation.
>>>s1="000100000010"
>>>s2="000010000100"
>>>s3="100000010000"
>>>'%.2f'%windowdiff(s1,s1,3)
'0.00'
>>>'%.2f'%windowdiff(s1,s2,3)
'0.30'
>>>'%.2f'%windowdiff(s2,s3,3)
'0.80'
:paramseg1:asegmentation
:typeseg1:strorlist
:paramseg2:asegmentation
:typeseg2:strorlist
:paramk:windowwidth
:typek:int
:paramboundary:boundaryvalue
:typeboundary:strorintorbool
:paramweighted:usetheweightedvariantofwindowdiff
:typeweighted:boolean
float
"""
#句子数相同
iflen(seg1)!=len(seg2):
raiseValueError("Segmentationshaveunequallength")
ifk>len(seg1):
raiseValueError("Windowwidthkshouldbesmallerorequalthansegmentationlengths")
#不匹配计数
wd=0
#滑动
foriinrange(len(seg1)-k+1):
#预测结果与真实结果在窗口内的分割边界数的差值
ndiff=abs(seg1[i:i+k].count(boundary)-seg2[i:i+k].count(boundary))
ifweighted:
wd+=ndiff
else:
#分割边界不相同,即边界数差值不为人零时,不匹配计数加1
wd+=min(1,ndiff)
#不匹配次数除以总的滑动次数
returnwd/(len(seg1)-k+1.)
总结
在今天的文章中,小喵跟大家一起学习了什么是文本分割(主题分割)、文本分割任务的应用场景以及文本分割任务的相关评价指标,如:Precision&Recall、Pk、WindowDiff。
希望大家通过本文能够对文本分割任务有一个基本的认识。在接下来的文章里,小喵将跟大家一起阅读文本分割的相关论文、学习文本分割的相关模型。
审核编辑 :李倩
-
自动识别
+关注
关注
3文章
241浏览量
23992 -
文本
+关注
关注
0文章
120浏览量
17941
原文标题:总结
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
防护器件类型与应用场景干货手册
Neway电机方案在电机控制的应用场景
Switch的应用场景
蓝牙网关是什么?都有哪些功能?应用场景有哪些?
物联网RFID物流追踪技术是什么?其技术原理和应用场景
淘宝API接口的技术应用场景介绍




评论