 全社会性自动驾驶重构计算模型
全社会性自动驾驶重构计算模型

元宇宙是人类社会网络化和虚拟化,通过对实体对象对应生成数字”智能体”来构建一个人机共存的新社会形态。元宇宙去中心化+AI化+虚拟化的底层网络融合架构,是当前在萌芽中的下一代互联网web3.0的社会实践。
元宇宙零距离社会里的社会计算,是一种数据经济行为的计算,即通过区块链的智能合约来构建数字经济中的数据资产,对于隐私数据存储提供可信计算和高可信度服务,借助数据交易和权益计算来产生经济效益,Web3的布局与发展预计将超过当前边缘地域政治的影响,可能会彻底颠覆全球经济次序。 对于自动驾驶ADS行业,我们也可以将其核心演进趋势定义为群体智能的社会计算,简单表述为,用NPU大算力和去中心化计算来虚拟化驾驶环境,通过数字化智能体(自动驾驶车辆AV)的多模感知交互(社交)决策,以及车车协同,车路协同,车云协同,通过跨模数据融合、高清地图重建、云端远程智驾等可信计算来构建元宇宙中ADS的社会计算能力。
群体智能:多智能体间的社交决策
在真实的交通场景里,一个理性的人类司机在复杂的和拥挤的行驶场景里,通过与周围环境的有效协商,包括挥手给其它行驶车辆让路,设置转向灯或闪灯来表达自己的意图,来做出一个个有社交共识的合理决策。而这种基于交通规则+常识的动态交互,可以在多样化的社交/交互驾驶行为分析中,通过对第三方驾驶者行为和反应的合理期望,来有效预测场景中动态目标的未来状态。这也是设计智能车辆AV安全行驶算法的理论基础,即通过构建多维感知+行为预测+运动规划的算法能力来实现决策安全的目的。而会影响到车辆在交互中的决策控制的驾驶行为包括驾驶者(人或AV)的社会层面交互和场景的物理层面交互两个方面:
社会层面交互:案例包括行驶车辆在并道、换道、或让道时的合理决策控制,主车道车辆在了解其它车辆的意图后自我调速,给需要并换道的车辆合理让路来避免可能的冲突和危险。
物理层面交互:案例包括静态物理障碍(静态停车车辆,道路可行驶的边界,路面障碍物体)和动态物理线索(交通标识,交通灯和实时状态显示,行人和运动目标)。
ADS群体智能的社会计算,对这种交互/社交行为,可以在通常的定义上扩展,也就是道路使用者或者行驶车辆之间的社交/交往,即通过彼此间的信息交换、协同或者博弈,实现各自利益最大化和获取最低成本,这一般包括三个属性(Wang 2022):
动态Dynamics:个体之间和个体与环境之间的闭环反馈(State,Action, Reward),驾驶人/智能体AV对总体环境动态做出贡献,也会被总体环境动态所影响。
度量Measurement: 信息交换,包括跨模数据发布与共享,驾驶人/智能体AV对道路使用者传递各自的社交线索和收集识别外部线索。
决策Decision: 利益/利用最大化,理性来说道路使用者追求的多是个体的最大利益。
显然,交通规则是不会完全规定和覆盖所有驾驶行为的,其它方面可以通过个体之间的社交/交互来补充。人类司机总体来说也不会严格遵守交通规则,类似案例包括黄灯初期加速通过路口,让路时占用部分其它道路空间来减少等待时间等等。ADS通过对这类社会行为的收集、学习与理解,可以部分模仿和社会兼容,通过Social-Aware和Safety-Assured决策,避免过度保守决策,同时提供算法模型的可解释性、安全性能和控制效率。具体实现来说,可以采用类似人类司机的做法,依据驾驶任务的不同,使用环境中不同的关注区域ROI和关注时间点,以及直接或间接的社交/交互,采用类似概率图模型和消息传递等机制来建模。社交影响因子的度量,即在给定驾驶环境状态x下,个体如何采取action a,一般有两种思路(Wang 2022) :
基于模型驱动的方法
模型参数多采用个体间物理距离和速度加速度等传感信息。
基于利用率Utility-based的模型:将个体之间交互作为一个优化问题来考虑
案例:换道并道操作,目标是保持理想的速度(径向控制)下如何使侧向路径跟踪误差最小化(侧向控制)
概率生成模型:采用贝叶斯网络的条件概率分布或条件行为预测来评估
案例:导航,通过对周围个体行为的概率预测,并结合安全风险特征进行逆优化
基于风险的模型:将交通规则域知识与驾驶场景的背景嵌入到可解释可学习的势或能量函数中
问题:基于相对距离的测量不能反映真实场景的物理约束,例如高速公路的分道杆几乎与行驶车辆没有交互。
社会认知模型:
案例:类似心理学的读心术来模仿个体的驾驶行为。
基于数据驱动的方法
驾驶环境的虚拟化,即在图模型中将环境中的隐含信息(图节点和关系)用低维标量或者向量(embedding)来表征。
DNN:
采用Autoencoder、Transformer或GAN来建模,通过CONV/RNN层将多传感信息映射成低维向量。
GNN with Social Pooling:
GNN:
○可以将结构化信息嵌入embedding来做为模型输入。
○或将社交关系用特定图边的可学习的参数来量化,即weighted graph edges。
Social Pooling:
○ 可以独立地将信息嵌入时间空间维度下的latent状态。
拓扑模型:
将个体间交互编码成一个代数几何的紧凑表征。
对单智能体而言,上述群体智能的社会计算表述,有一个典型的优势是,人类驾驶的社会关联特性和超强驾驶模仿特性,可以在算法设计中采用关联强化的reward函数来学习人类的这种社会群体跟随特性。而人类群体对隐含场景的社会感知,可以更好地提高对环境遮挡的认知理解和进行不确定性的概率预测。
优化建模与学习方法
ADS的一个最常见的交互场景是在城市和高速公路上的日常交通行为,包括车辆跟随,车辆换道,主路辅路并道等。上述所表述的Utility-based的理性模型,采用的是基于目标函数进行优化的模型,需要定义一个目标,例如在前行方向的车辆之间有一个可用的空闲空间。一种设计思路是假定人类驾驶行为基本上就是一个游戏理论问题,存在着多智能体的互相耦合连续决策。这种交互或社交,可以用动态Markov游戏来建模,单体之间通过合作或竞争来完成任务,即所谓的多智能体强化学习Multi-AgentReinforcement Learning(MARL),将环境定义为Markov决策过程(MDP)或者是部分可观察的POMDP。解决的思路的引入下述的方法来摹拟交互过程中的决策控制:
游戏理论方法:包括强化学习RL,逆强化学习IRL和模仿学习IL等。
控制理论方法:模型预测控制MPC,线性二次元高斯控制LQGC等。
上述将将社交行为转化成递归优化问题,对目标个体而言,对其它智能体的角色和整体效果的定位,如图1所示,可以有三种:
障碍Obstacles关系:基于对其它运动目标的行为和运动预测来规划个体自身,视预测不可更改,这种单向社交,在部分场景会导致目标个体过度保守、困于僵局或有不安全行为。
理性跟随者Rational Follower关系: 这种定义假定其它个体基于自身利用率进行优化决策,对目标个体的行为没有预判和响应,会导致目标个体的动作/响应难以取得最优解。
相互依赖群体关系:这种假定可以通过战略和战术规划来实现,战略规划可以建模成一个闭环的动态游戏,战术规划可以建模成一个开环的轨迹规划与优化。或者通过多智能体的同步游戏来捕获动态的交互依赖,解决冲突问题。对目标个体而言,可以只考虑局部邻近个体,通过个体间通信可以减少所有关联个体存在的类似同时减速或者同时停车让路等算法陷阱问题。
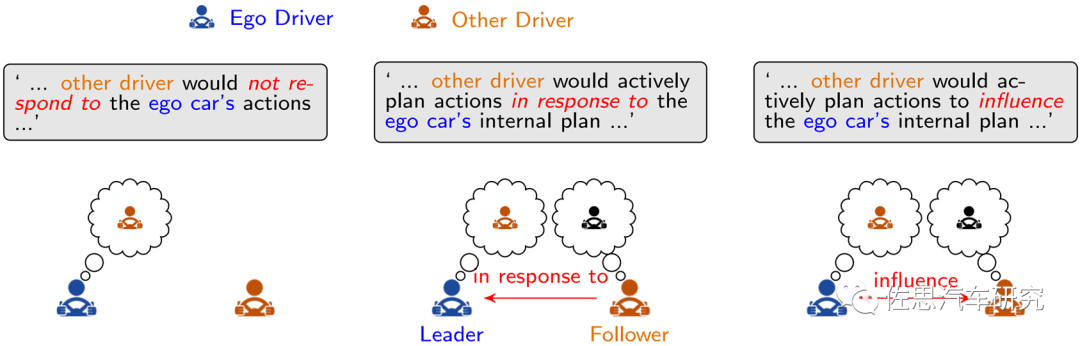
图1 多智能体社交关系案例分析(Wang 2022) 显然在ADS中直接引入游戏理论框架,可解释性强,但随着参与交互的个体数目和场景复杂度增加,计算复杂度也会指数比例增加,工程实现会比较困难。 人类驾驶者可以通过奖励强化机制来与环境进行安全交互。这种机制推动了ADS行业采用游戏理论中强化学习方案,通过同步或者异步处理模式,来获取个体间的交互。一种可行的方法将递归的政策Policy学习任务定义为单智能体的single-agent RL学习问题,者涉及到states, actions, reward和动态环境参数。异步实现的算法包括DeepQ-Learning (DQN),D3QN等,这种单体RL方案由于假定其它个体的战略行为不变性,很容易导致不稳定的控制政策,难以解决不安全行驶风险。而同步实现方案,环境状态的进化和激励来自群体交互和联合行动,每个智能体都视为MDP-based Agent,共同进行多智能体强化学习MARL。同步实现的算法目前受限于有限的交通场景,个体间的社会特性都是预定义的,解决这个问题的一个可行思路是采用课程学习的策略,从简单场景开始来一步步来进行深化学习。
在ADS中引入游戏理论框架的另外一个风险是环境信息的不完全性(部分可观察),假定驾驶者都是理性的,每个驾驶者的意图都能够被第三方获取。在实际交通环境中,信息获取的不对称性比比皆是。同时对于非理性的驾驶行为,如果在保证有安全保障的决策控制的前提下,一定程度的同情心或者同理心是非常有必要的。一种思路是引入一对社会参数(β, λ)来对道路上驾驶者的理性水平和角色,通过贝叶斯规则观察进行参数更新。
上述的讨论分析,可以将驾驶者的决策过程,转化为对部分可观察环境虚拟化或参数化,同时对个体间社交选择的偏爱进行参数化,嵌入到价值函数中去,通过基于优化的状态反馈策略,寻求驾驶群体利益最大化问题的最优解。一个通常的解决思路是,将其它个体的奖励函数表征为当前状态的线性结构化的加权特征,对应的权值向量,可以通过逆最优控制理论(例如IRL )来进行学习估计,IRL的目的是从人类驾驶演示的驾驶偏向中学习底层的目标函数,通过将IRL编码的人类驾驶行为集成到AV的目标函数中来构建能够社会性兼容的行驶控制。
在ADS动态和不确定性的场景中,环境需要建模成部分可观察的MDP即POMDP,为了降低计算复杂度,一般都选择离散化空间或者部分连续空间来解决POMDP问题。对不确定性信息评估的一种常用的做法是对当前状态进行概率分布进行构建,得到一个置信(belief)状态,这种形态可以通过离线或者在线构建。离线计算意味着,不是针对当前状态,而是对所有可能的置信状态的最可能的行为,在线计算意味着需要在精度和效率之间做权衡。 上述提到的将驾驶环境视为一个Markov决策过程MDP,一个设计思路是Q-Learning(DQN, D2QN, D3QN)算法,它属于Single-AgentMDP方法,即将其它道路使用者视为稳态环境的一部分。自体(ego agent)通过与环境的交互/社交来寻求关联累计奖励a的最优方案,即在一个固定时间窗T范围内,在环境状态s下policy政策π的价值函数优化问题 ADS的交互性决策控制,是一个典型的多目标问题,包括行驶的安全保证、整体效率和舒适体验。D2QN和D3QN的优势在Q函数值表达中引入了防止碰撞的思路,但学习效率和最终性能仍然低于应用预期。一种设计思路是将模仿学习IL与RL 相结合(IRL)。IL有两种学习模式:
行为克隆方法Behaviour Cloning:直接学习从观察到行动actions的映射关系,寻求目标的似然函数最大化或者误差最小化,需要有足够的训练数据为前提,但在复杂的交互场景下的域自适应能力表现不佳。
利用率重建 Utility Recovering: 这种IRL学习方法,非直接利用数据通过观察来获取奖励函数,从而使规划车辆的社交行为能够近可能的摹拟演示效果。这种假设与人类驾驶行为非常接近,尤其是如何在不同类型的新场景下如何安全有效地与其它驾驶者的进行交互。IRL的目的是通过摹拟自体的驾驶行为从数据中学习自体奖励函数。
总上所述,在动态场景中,由于理性的人类驾驶行为是所有可能的解决方案中,最接近最优的决策输出,这种观察可以将人类驾驶交互用计算可表达优化模型来公式化。这种基于优化的方法从分析角度来说可解释,数学上可证明,可以添加各种约束条件来避免碰撞,但如何降低复杂度来满足计算性能是非常有挑战的。
DNN-based模型
基于DNN模型的方法,是一种在数据充分的条件下,通过少量的人力投入就可以提供非常有力的设计表达。尤其是针对社交关系建模与推理来解决ADS中预测与规划问题,通过监督和自监督学习的方式,单独或者联合建模的方式,以及IL和RL的学习流程。交互建模的输入来自车辆状态,包括定位信息,速度,加速度,角速度,车辆朝向等。端到端的DL-based方法通常直接通过卷积处理原始传感数据(RGB图像和点云),计算简洁但会损失弱的或者隐含的交互推理的内容表达。如图2所示,深度学习模型中的不同构建模块,是可以对多智能体的交互推理进行有效建模和表达的,其中
(a)全连接FC层:又称多层感知器MLP,其中所有输入通过连接可以与输出交互并对输出做出贡献。
(b)卷积CONV层:卷积层采用局部感知场,所以每层的连接会比较稀疏,通常假定合适用来捕获空间关系,最初的底层卷积层一般提取类似边缘纹理类的信息,越接近顶层也偏语义特征。
(c)递归Recurrent层 :通常用来处理时间维度的数据序列,多用来捕获时间关系。
(d)图Graph层:典型的图包括节点、边(用来描述节点间关系)、和上下文全局属性,通常用来捕获图结构表征中显性关系推理,与FC层和RNN层一个不同之处是输入的先后次序不会影响结构,图结构还可以处理不同数目的个体,比较适合多个体的ADS环境。
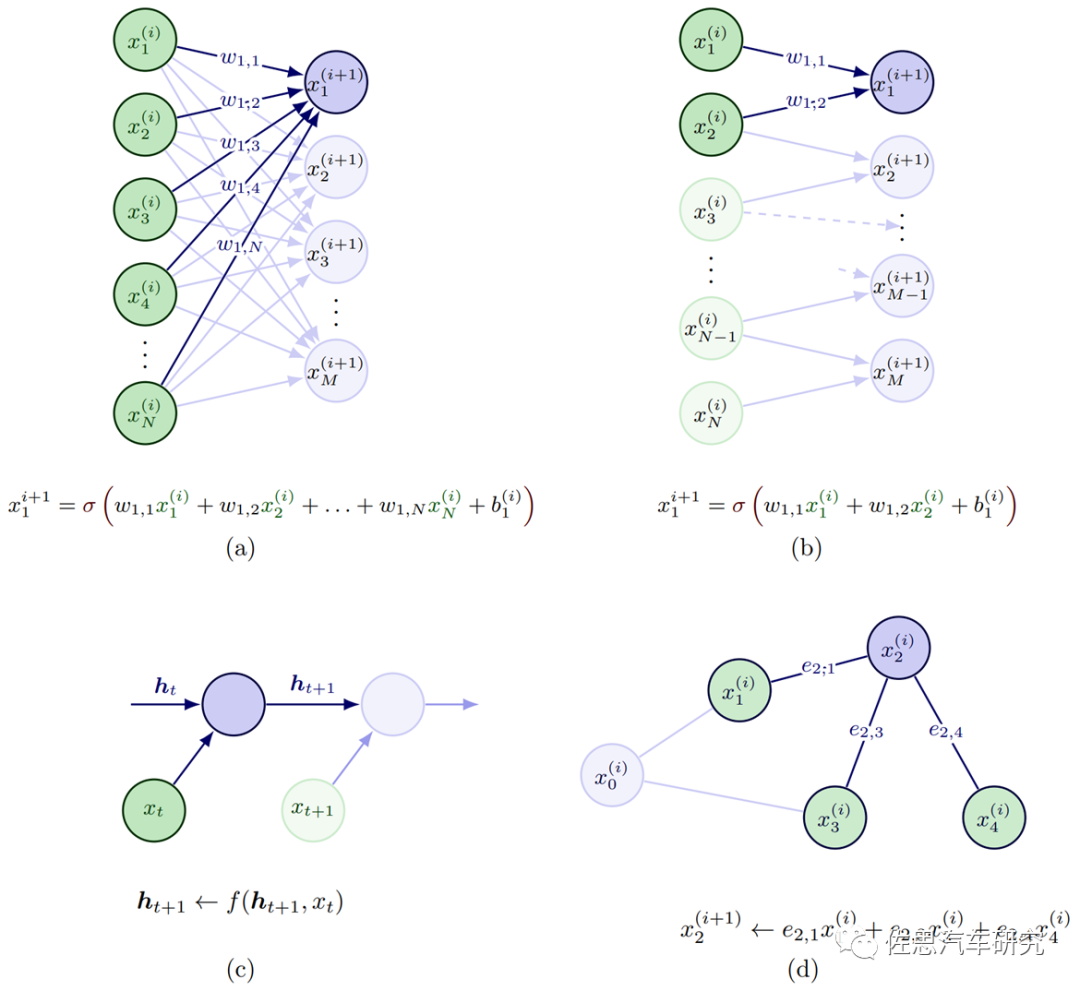
图2 DNN模块对多智能体交互的建模案例(Wang 2022)
对于ADS中社交特征表征,常用的有空间时间状态特征矢量,空间占用方格和图区域动态插入等方式。空时状态特征矢量比较难以定义,尤其是个体数量变化和有效时间步长的不同,另外一个限制是依赖于个体插入的次序。所以一个常用的设计思路是采用占用方格地图Occupancy Grid Map (OGM)来解决上述的两个问题。OGM是以本体ego agent为中心来构建空间方格图,可以处理ROI区域不同数目的智能体。OGM通常采用原始状态(定位,速度,加速度)或者采用FC层来进行状态编码,如果FC层隐层包括个体的历史轨迹信息,可以同时捕获空间时间信息。OGM的分辨率对计算性能影响比较大。
相对而言,图网络GNN可以通过动态插入区域DIA抽取来更好地构建空间时间交互图关系,图的类型可以基于个体(车辆,行人,机动车等),也可以基于区域area,后者主要聚焦对车辆意图(车道保持,换道并道,左拐右拐)的表征,这里DIA指的是可驾驶场景中空闲空隔。如图3所示,DIA的优势在于对环境中静态元素(道路拓扑,类似stop道路标志牌等)和动态元素(行驶车辆)非常灵活,可以认为是动态环境的统一表征或者也可以叫做环境的虚拟化。所有时间地平线的DIAs可以用来构建空间时间语义图。

图3 动态插入区域抽取和场景语义图 构建案例(Wang 2022)
如图2所示,群体智能的社会计算,其中的社交关系,可以采用不同的深度学习层来进行交互建模和编码:
FC层交互编码:采用将不同个体的特征进行拉平,拼接成一个向量。多用来对单体single agent进行运动和意图建模,很少用于multiple agent。
CONV层交互编码:将空间时间特征(状态特征张量)或占用方格地图做为CNN输入来进行交互编码。
Recurrent层交互编码:多采用LSTM来进行时间维度推理,编码产生的embedding张量可以捕获时间空间的交互信息。
Graph层交互编码:对多智能体之间的关系采用节点之间的无向或者有向边来表征,可以用消息传递机制来进行交互学习,每个节点通过聚集邻近节点的特征来更新自身的属性特征。
在实际设计中,多将Recurrent层和Graph层相结合,可以很好地处理时间信息。而注意力attention机制编码可以更好地量化一个特征如何影响其它特征。人类司机会在交互场景中有选择地选取其它个体来进行关注,包括其过去现在的信息和未来的预判。所以注意力机制编码可以基于时间域(短期的和长期的)和空间域(本地的和偏远的),在上述方法中通过加权方案分别进行应用。对个体的注意力建模,可以采用基于距离的方法,这意味着其它个体越近,关注度也越高。 综上所述,DL-based方法由于模块化的设计和海量数据贡献,性能占优,但如何能够提供安全能力和大规模部署,需要解决几个挑战:在保证性能基础上改善可解释性;在不同的驾驶个体,场景和态势下继续增强模型的推广能力。
审核编辑 :李倩
-
贝叶斯网络
+关注
关注
0文章
24浏览量
8457 -
智能体
+关注
关注
1文章
386浏览量
11518 -
自动驾驶
+关注
关注
791文章
14667浏览量
176374
原文标题:全社会性自动驾驶重构计算模型
文章出处:【微信号:阿宝1990,微信公众号:阿宝1990】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
大模型中常提的快慢思考会对自动驾驶产生什么影响?


西井科技端到端自动驾驶模型获得国际认可
如何确保自动驾驶汽车感知的准确性?

为什么自动驾驶端到端大模型有黑盒特性?

卡车、矿车的自动驾驶和乘用车的自动驾驶在技术要求上有何不同?
自动驾驶中常提的世界模型是个啥?
浅析4D-bev标注技术在自动驾驶领域的重要性
新能源车软件单元测试深度解析:自动驾驶系统视角

大模型如何推动自动驾驶技术革新?
自动驾驶大模型中常提的Token是个啥?对自动驾驶有何影响?
NVIDIA Halos自动驾驶汽车安全系统发布
从《自动驾驶地图数据规范》聊高精地图在自动驾驶中的重要性
自动驾驶中常提的鲁棒性是个啥?





 工商网监
工商网监
评论