 如何理解高性能服务器的高性能、高并发?
如何理解高性能服务器的高性能、高并发?

线程 | 同步 | 异步 | 异构
协程 | 进程 | 同构 | 线程池
当前,随着“东数西算”政策的落地,算力时代正在全面开启。 随着机器学习、深度学习的快速发展,人们对高性能服务器这一概念不再陌生。 伴随着数据分析、数据挖掘数目的不断增大,传统的风冷散热方式已经不足以满足散热需要,这就需要新兴的液冷散热技术以此满足节能减排、静音高效的需求。
作为国内品牌服务器厂商,蓝海大脑液冷GPU服务器拥有大规模并行处理能力和无与伦比的灵活性。 它主要用于为计算密集型应用程序提供足够的处理能力。 GPU的优势在于可以由CPU运行应用程序代码,同时图形处理单元(GPU)可以处理大规模并行架构的计算密集型任务。 GPU服务器是遥感测绘、医药研发、生命科学和高性能计算的理想选择。
本文将为大家全面介绍高性能GPU服务器所涉及技术以及如何搭建。
线程与线程池
下面将从CPU开始路来到常用的线程池,从底层到上层、从硬件到软件。
一、CPU
对此大家可能会有疑问,讲多线程为什么要从CPU开始? 实际上CPU并没有线程、进程之类的概念。 CPU所作的就是从内存中取出指令——执行指令,然后回到1。
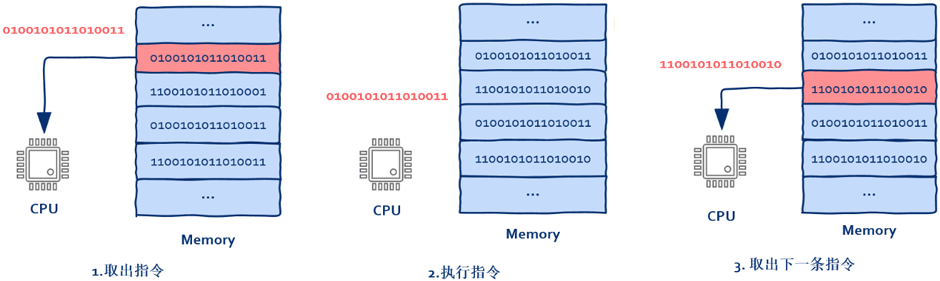
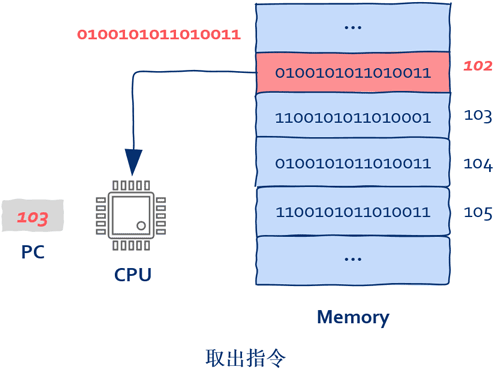
1、CPU从哪里取出指令
就是我们熟知的程序计数器,在这里大家不要把寄存器想的太神秘,可以简单的将寄存器理解为内存,只不过存取速度更快而已。
2、PC寄存器中存放的是什么?
指令(CPU将要执行的下一条指令)在内存中的地址
3、谁来改变PC寄存器中的指令地址?
由于大部分情况下CPU都是一条接一条顺序执行,所以
之前PC寄存器中的地址默认是自动加1。 但
当遇到if、else时,这种顺序执行就被打破了,为了正确的跳转到需要执行的指令,CPU在执行这类指令时会根据计算结果来动态改变PC寄存器中的值。
4、PC中的初始值是怎么被设置的?
CPU执行的指令来自内存,内存中的指令来自于磁盘中保存的可执行程序加载,磁盘中可执行程序是由编译器生成的,编译器从定义的函数生成的机器指令。
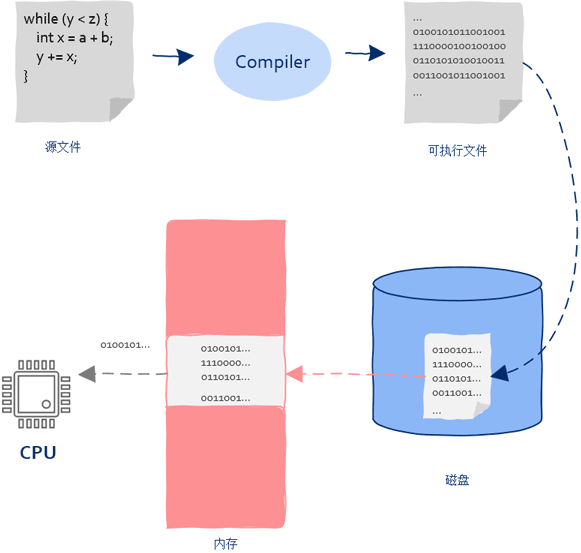
二、从CPU到操作系统
从上面我们明白了CPU的工作原理,如果想让CPU执行某个函数,只需把函数对应的第一条机器执行装入PC寄存器就可以了,这样即使没有操作系统也可以让CPU执行程序,虽然可行但这是一个非常繁琐的过程(1、在内存中找到一块大小合适的区域装入程序;2、找到函数入口,设置好PC寄存器让CPU开始执行程序)。
机器指令由于需加载到内存中执行所以需要记录下内存的起始地址和长度;同时要找到函数的入口地址并写到PC寄存器中。
数据结构大致如下:
三、从单核到多核,如何充分利用多核
如果一个程序需要充分利用多核就会遇到以下问题:
1、进程是需要占用内存空间的(从上一节到这一节),如果多个进程基于同一个可执行程序,那么这些进程其内存区域中的内容几乎完全相同,显然会造成内存浪费;
2、当计算机处理的任务比较复杂时就会涉及到进程间通信,但是由于各个进程处于不同的内存地址空间,而进程间通信需要借助操作系统,在增大编程难度的同时也增加了系统开销。
四、从进程到线程
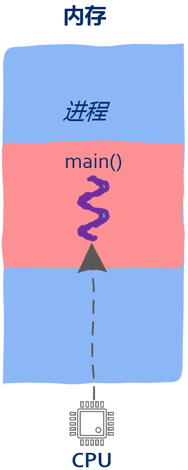
进程到线程即内存中的一段区域,该区域保存了CPU执行的机器指令以及函数运行时的堆栈信息。要想让进程运行,就把main函数的第一条机器指令地址写入PC寄存器。
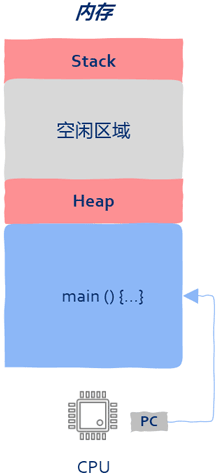
进程的缺点在于只有一个入口函数(main函数),进程中的机器指令只能被一个CPU执行,那么有没有办法让多个CPU来执行同一个进程中的机器指令呢?可以将main函数的第一条指令地址写入PC寄存器。
main函数和
其它函数没什么区别,其特殊之处无非在于是CPU执行的第一个函数。
当把PC寄存器指向非main函数时,线程就诞生了。
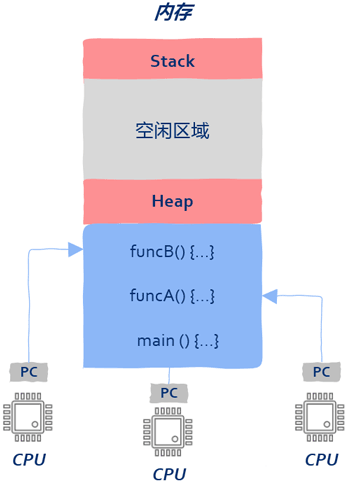
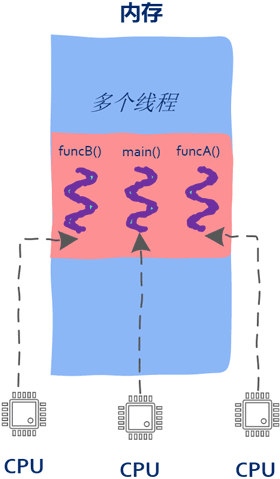
至此一个进程内可以有多个入口函数,也就是说属于同一个进程中的机器指令可以被多个CPU同时执行。
多个CPU可以在同一个屋檐下(进程占用的内存区域)同时执行属于该进程的多个入口函数。操作系统为每个进程维护一堆信息,用来记录进程所处的内存空间等,这堆信息记为数据集A。同样的,操作系统也为线程维护一堆信息,用来记录线程的入口函数或者栈信息等,这堆数据记为数据集B。
显然数据集B要比数据A的量要少,由于线程是运行在所处进程的地址空间在程序启动时已经创建完毕,同时线程是程序在运行期间创建的(进程启动后),所以当线程开始运行的时候这块地址空间就已经存在了,线程可以直接使用。
值得一提的是,有了线程这个概念后,只需要进程开启后创建多个线程就可以让所有CPU都忙起来,这就是所谓高性能、高并发的根本所在。
另外值得注意的一点是:由于各个线程共享进程的内存地址空间,所以线程之间的通信无需借助操作系统,这给工作人员带来了便利同时也有不足之处。多线程遇到的多数问题都出自于线程间通信太方便以至于非常容易出错。出错的根源在于CPU执行指令时没有线程的概念,多线程编程面临的互斥与同步问题需要解决。
最后需要注意的是:虽然前面关于线程讲解使用的图中用了多个CPU,但并不一定要有多核才能使用多线程,在单核的情况下一样可以创建出多个线程,主要是由于线程是操作系统层面的实现,和有多少个核心是没有关系的,CPU在执行机器指令时也意识不到执行的机器指令属于哪个线程。即使在只有一个CPU的情况下,操作系统也可以通过线程调度让各个线程“同时”向前推进,即将CPU的时间片在各个线程之间来回分配,这样多个线程看起来就是“同时”运行了,但实际上任意时刻还是只有一个线程在运行。
五、线程与内存
前面介绍了线程和CPU的关系,也就是把CPU的PC寄存器指向线程的入口函数,这样线程就可以运行起来了。
无论使用任何编程语言,创建一个线程大体相同:
函数在被执行的时产生的数据包括:函数参数、局部变量、返回地址等信息。这些信息保存在栈中,线程这个概念还没有出现时进程中只有一个执行流,因此只有一个栈,这个栈的栈底就是进程的入口函数,也就是main函数。
假设main函数调用了funA,funcA又调用了funcB,如图所示:
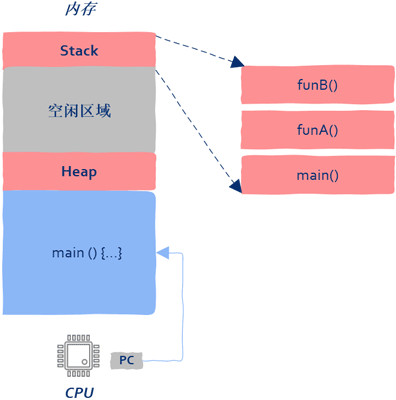
有了线程以后一个进程中就存在多个执行入口,即同时存在多个执行流,只有一个执行流的进程需要一个栈来保存运行时信息,显然有多个执行流时就需要有多个栈来保存各个执行流的信息,也就是说操作系统要为每个线程在进程的地址空间中分配一个栈,即每个线程都有独属于自己的栈,能意识到这一点是极其关键的。同时创建线程是要消耗进程内存空间的。
六、线程的使用
从生命周期的角度讲,线程要处理的任务有两类:长任务和短任务。
1、长任务(long-lived tasks)
顾名思义,就是任务存活的时间长。以常用的word为例,在word中编辑的文字需要保存在磁盘上,往磁盘上写数据就是一个任务,这时一个比较好的方法就是专门创建一个写磁盘的线程,该线程的生命周期和word进程是一样的,只要打开word就要创建出该线程,当用户关闭word时该线程才会被销毁,这就是长任务。长任务非常适合创建专用的线程来处理某些特定任务。
2、短任务(short-lived tasks)
即任务的处理时间短,如一次网络请求、一次数据库查询等。这种任务可以在短时间内快速处理完成。因此短任务多见于各种Server,像web server、database server、file server、mail server等。该场景有任务处理所需时间短和任务数量巨大的两个特点。
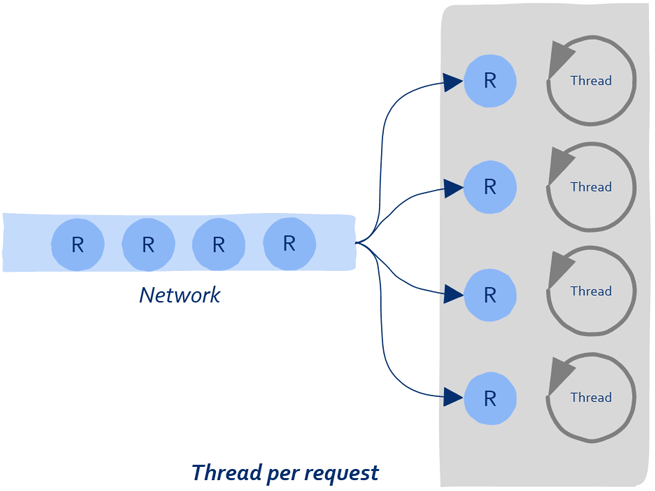
这种工作方法可对长任务来说很好,但是对于大量的短任务来说虽然实现简单但却有其缺点:
1)线程是操作系统中的概念,因此创建线程需要借助操作系统来完成,操作系统创建和销毁线程是需要消耗时间的;
2)每个线程需要有自己独立的栈,因此当创建大量线程时会消耗过多的内存等系统资源。
这就好比一个工厂老板手里有很多订单,每来一批订单就要招一批工人,生产的产品非常简单,工人们很快就能处理完,处理完这批订单后就把这些工人辞掉,当有新的订单时再招一遍工人,干活儿5分钟招人10小时,如果你不是励志要让企业倒闭的话大概是不会这么做到的。因此一个更好的策略就是招一批人后就地养着,有订单时处理订单,没有订单时大家可以待着。
这就是线程池的由来。
七、从多线程到线程池
线程池的无非就是创建一批线程之后就不再释放,有任务就提交给线程处理,因此无需频繁的创建、销毁线程,同时由于线程池中的线程个数通常是固定的,也不会消耗过多的内存。
八、线程池是如何工作的?
一般来说提交给线程池的任务包含需要被处理的数据和处理数据的函数两部分。
伪码描述一下:
线程池中的线程会阻塞在队列上,当工作人员向队列中写入数据后,线程池中的某个线程会被唤醒,该线程从队列中取出上述结构体(或者对象),以结构体(或者对象)中的数据为参数并调用处理函数。
伪码如下:
八、线程池中线程的数量
众所周知线程池的线程过少就不能充分利用CPU,线程创建的过多反而会造成系统性能下降,内存占用过多,线程切换造成的消耗等等。因此线程的数量既不能太多也不能太少,到底该是多少呢?
从处理任务所需要的资源角度看有CPU密集型和I/O密集型两种类型。
1、CPU密集型
所谓CPU密集型是指说理任务不需要依赖外部I/O,比如科学计算、矩阵运算等。在这种情况下只要线程的数量和核数基本相同就可以充分利用CPU资源。
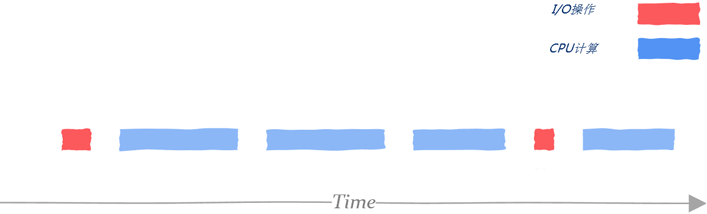
2、I/O密集型
这一类任务可能计算部分所占用时间不多,大部分时间都用在磁盘I/O、网络I/O等方面。
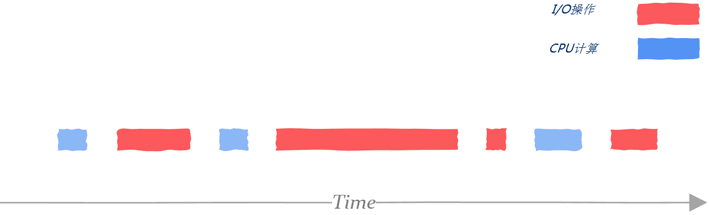
工作人员需要利用性能测试工具评估出用在I/O等待上的时间,这里记为WT(wait time),以及CPU计算所需要的时间,这里记为CT(computing time),那么对于一个N核的系统,合适的线程数大概是 N * (1 + WT/CT) ,假设I/O等待时间和计算时间相同,那么大概需要2N个线程才能充分利用CPU资源,注意这只是一个理论值,具体设置多少需要根据真实的业务场景进行测试。
当然充分利用CPU不是唯一需要考虑的点,随着线程数量的增多,内存占用、系统调度、打开的文件数量、打开的socker数量以及打开的数据库链接等等是都需要考虑的。所以没有万能公式,要具体情况具体分析。
九、使用线程前需要考虑的因素
1、充分理解任务是长任务还是短任务、是CPU密集型还是I/O密集型,如果两种都有,那么一种可能更好的办法是把这两类任务放到不同的线程池。
2、如果线程池中的任务有I/O操作,那么务必对此任务设置超时,否则处理该任务的线程可能会一直阻塞下去;
4、线程池中的任务不要同步等待其它任务的结果。
I/O与零拷贝技术
一、什么是I/O?
I/O就是简单的数据Copy,如果数据从外部设备copy到内存中就是Input。如果数据是内存copy到外部设备则是Output。内存与外部设备之间不嫌麻烦的来回copy数据就是Input and Output,简称I/O(Input/Output)。
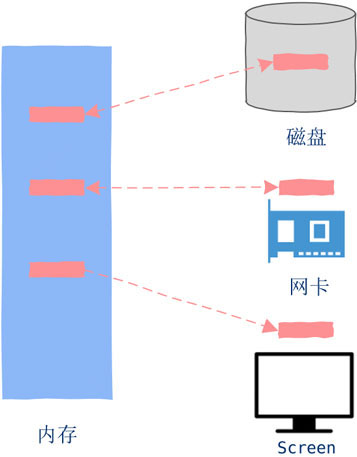
二、I/O与CPU
简单来说:CPU执行机器指令的速度是纳秒级别的,而通常的I/O比如磁盘操作,一次磁盘seek大概在毫秒级别,因此如果我们把CPU的速度比作战斗机的话,那么I/O操作的速度就是肯德鸡。
也就是说当程序跑起来时(CPU执行机器指令),其速度是要远远快于I/O速度。那么接下来的问题就是二者速度相差这么大,该如何设计、更加合理的高效利用系统资源呢?
既然有速度差异,进程在执行完I/O操作前不能继续向前推进,那就只有等待(wait)。
三、执行I/O时底层都发生了什么
在支持线程的操作系统中,实际上被调度的是线程而不是进程,为了更加清晰的理解I/O过程,暂时假设操作系统只有进程这样的概念,先不去考虑线程。
如下图所示,现在内存中有两个进程,进程A和进程B,当前进程A正在运行。如下图所示:
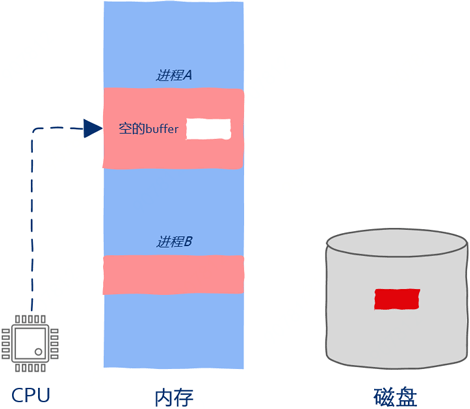
进程A中有一段读取文件的代码,不管在什么语言中通常定义一个用来装数据的buff,然后调用read之类的函数。
注意:与CPU执行指令的速度相比,I/O操作操作是非常慢的,因此操作系统是不可能把宝贵的CPU计算资源浪费在无谓的等待上的。由于外部设备执行I/O操作是相当慢的,所以在I/O操作完成之前进程是无法继续向前推进的,这就是所谓的阻塞,即block。
只需记录下当前进程的运行状态并把CPU的PC寄存器指向其它进程的指令就
操作系统检测到进程向I/O设备发起请求后就暂停进程的运行
。进程有暂停就会有继续执行,因此操作系统必须保存被暂停的进程以备后续继续执行,显然我们可以用队列来保存被暂停执行的进程。
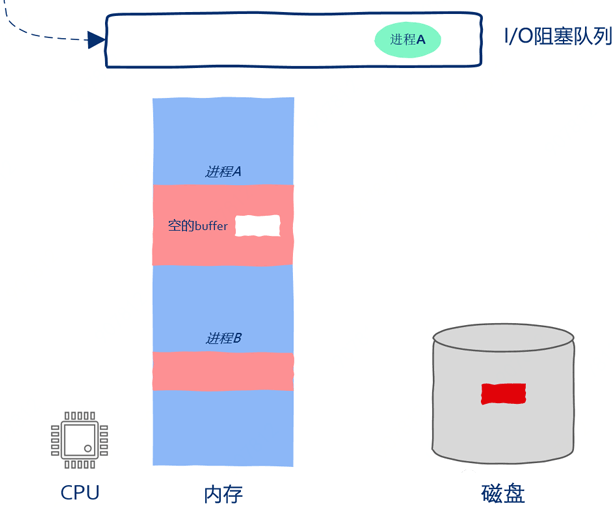
如上图所示,操作系统已经向磁盘发送I/O请求,因此磁盘driver开始将磁盘中的数据copy到进程A的buff中。虽然这时进程A已经被暂停执行了,但这并不妨碍磁盘向内存中copy数据。过程如下图所示:
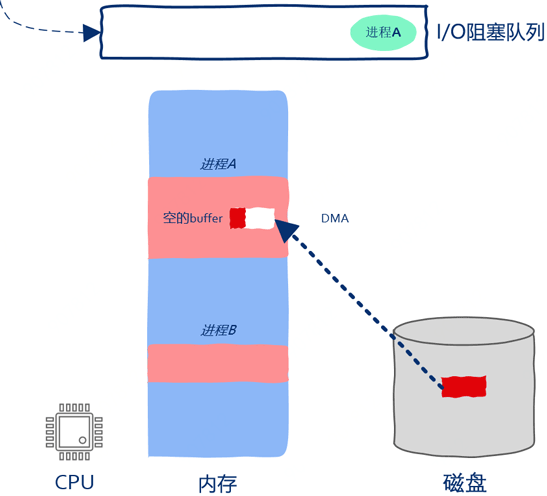
操作系统中除了有阻塞队列之外也有就绪队列,所谓就绪队列是指队列里的进程准备就绪可以被CPU执行了。在即使只有1个核的机器上也可以创建出成千上万个进程,CPU不可能同时执行这么多的进程,因此必然存在这样的进程,即使其一切准备就绪也不能被分配到计算资源,这样的进程就被放到了就绪队列。
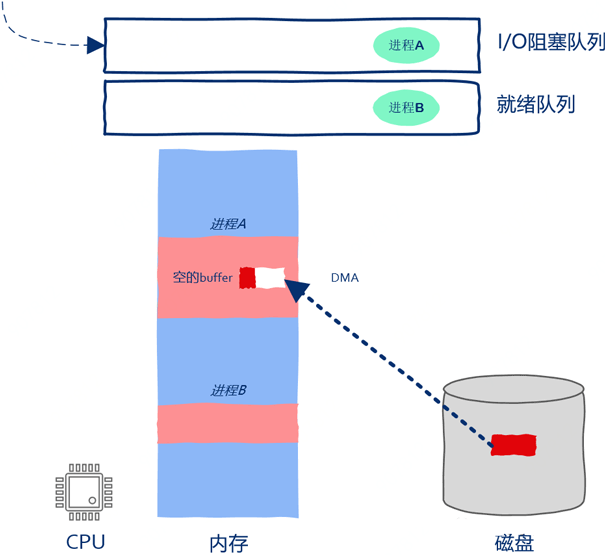
由于就绪队列中还有嗷嗷待哺的进程B,所以当进程A被暂停执行后CPU是不可以闲下来的。这时操作系统开始在就绪队列中找下一个可以执行的进程,也就是这里的进程B。此时操作系统将进程B从就绪队列中取出,找出进程B被暂停时执行到的机器指令的位置,然后将CPU的PC寄存器指向该位置,这样进程B就开始运行啦。
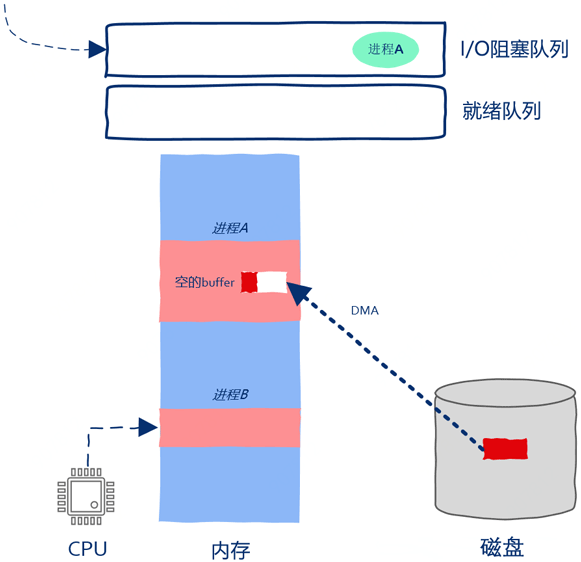
如上图所示,进程B在被CPU执行,磁盘在向进程A的内存空间中copy数据,数据copy和指令执行在同时进行,在操作系统的调度下,CPU、磁盘都得到了充分的利用。此后磁盘将全部数据都copy到了进程A的内存中,操作系统接收到磁盘中断后发现数据copy完毕,进程A重新获得继续运行的资格,操作系统把进程A从阻塞队列放到了就绪队列当中。
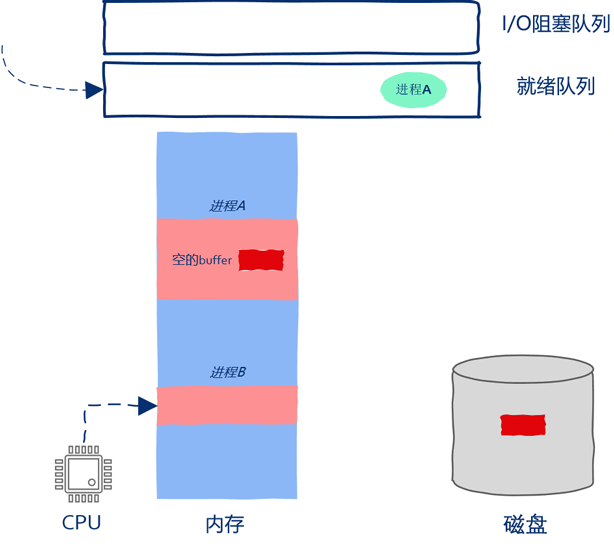
此后进程B继续执行,进程A继续等待,进程B执行了一会儿后操作系统认为进程B执行的时间够长了,因此把进程B放到就绪队列,把进程A取出并继续执行。操作系统把进程B放到的是就绪队列,因此进程B被暂停运行仅仅是因为时间片到了而不是因为发起I/O请求被阻塞。
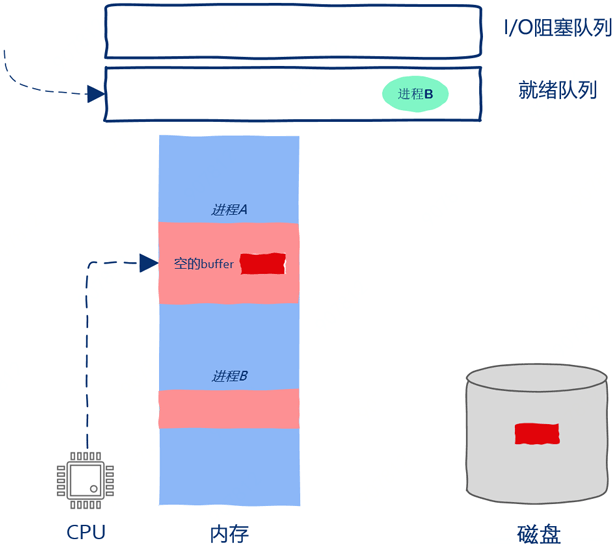
四、零拷贝(Zero-copy)
值得注意的一点是:上面的讲解中直接把磁盘数据copy到了进程空间中,但实际上一般情况下I/O数据是要首先copy到操作系统内部,然后操作系统再copy到进程空间中。性能要求很高的场景其实也是可以绕过操作系统直接进行数据copy,这种绕过操作系统直接进行数据copy的技术被称为零拷贝(Zero-copy)。
I/O多路复用
本文我们详细讲解什么是I/O多路复用以及使用方法,这其中以epoll为代表的I/O多路复用(基于事件驱动)技术使用非常广泛,实际上你会发现但凡涉及到高并发、高性能的场景基本上都能见到事件驱动的编程方法。
一、什么是文件?
在Linux世界中文件是一个很简单的概念,只需要将其理解为一个N byte的序列就可以了:
b1, b2, b3, b4, ....... bN
实际上所有的I/O设备都被抽象了,一切皆文件(Everything is File),磁盘、网络数据、终端,甚至进程间通信工具管道pipe等都被当做文件对待。

常用的I/O操作接口一般有以下几类:
1、打开文件,open;
2、改变读写位置,seek;
3、文件读写,read、write;
4、关闭文件,close。
二、什么是文件描述符?
在上文中我们讲到:要想进行I/O读操作,像磁盘数据,需要指定一个buff用来装入数据。在Linux世界要想使用文件,需要借助一个号码,根据“弄不懂原则”,这个号码就被称为了文件描述符(file descriptors),在Linux世界中鼎鼎大名,其道理和上面那个排队号码一样。文件描述仅仅就是一个数字而已,但是通过这个数字我们可以操作一个打开的文件。
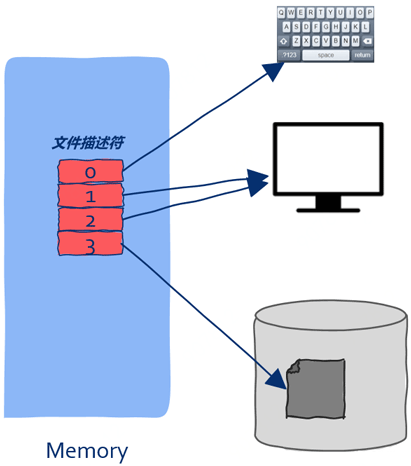
有了文件描述符,进程可以对文件一无所知,比如文件在磁盘的什么位置、加载到内存中又是怎样管理的等等,这些信息统统交由操作系统打理,进程无需关心,操作系统只需要给进程一个文件描述符就足够了。
三、文件描述符太多了怎么办?
从上文中我们知道,所有I/O操作都可以通过文件样的概念来进行,这当然包括网络通信。
如果你有一个IM服务器,当三次握手建议长连接成功以后,我们会调用accept来获取一个链接,调用该函数我们同样会得到一个文件描述符,通过这个文件描述符就可以处理客户端发送的聊天消息并且把消息转发给接收者。
也就是说,通过这个描述符就可以和客户端进行通信了:
// 通过accept获取客户端的文件描述符
int conn_fd = accept(...);
Server端的处理逻辑通常是接收客户端消息数据,然后执行转发(给接收者)逻辑:
if(read(conn_fd, msg_buff) > 0) {
do_transfer(msg_buff);
}
既然主题是高并发,那么Server端就不可能只和一个客户端通信,而是可能会同时和成千上万个客户端进行通信。这时需要处理不再是一个描述符这么简单,而是有可能要处理成千上万个描述符。为了不让问题一上来就过于复杂先简单化,假设只同时处理两个客户端的请求。
有的同学可能会说,这还不简单,这样写不就行了:
if(read(socket_fd1, buff) > 0) { // 处理第一个
do_transfer();
}
if(read(socket_fd2, buff) > 0) { // 处理第二个
do_transfer();
如果此时没有数据可读那么进程会被阻塞而暂停运行。这时我们就无法处理第二个请求了,即使第二个请求的数据已经就位,这也就意味着处理某一个客户端时由于进程被阻塞导致剩下的所有其它客户端必须等待,在同时处理几万客户端的server上。这显然是不能容忍的。
聪明的你一定会想到使用多线程:为每个客户端请求开启一个线程,这样一个客户端被阻塞就不会影响到处理其它客户端的线程了。注意:既然是高并发,那么我们要为成千上万个请求开启成千上万个线程吗,大量创建销毁线程会严重影响系统性能。
那么这个问题该怎么解决呢?
这里的关键点在于:我们事先并不知道一个文件描述对应的I/O设备是否是可读的、是否是可写的,在外设的不可读或不可写的状态下进行I/O只会导致进程阻塞被暂停运行。
三、I/O多路复用(I/O multiplexing)
multiplexing一词多用于通信领域,为了充分利用通信线路,希望在一个信道中传输多路信号,要想在一个信道中传输多路信号就需要把这多路信号结合为一路,将多路信号组合成一个信号的设备被称为Multiplexer(多路复用器),显然接收方接收到这一路组合后的信号后要恢复原先的多路信号,这个设备被称为Demultiplexer(多路分用器)。
如下图所示:
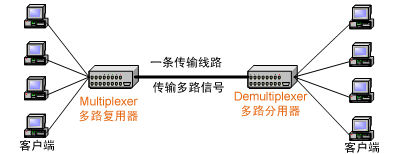
所谓I/O多路复用指的是这样一个过程:
1、拿到一堆文件描述符(不管是网络相关的、还是磁盘文件相关等等,任何文件描述符都可以);
2、通过调用某个函数告诉内核:“这个函数你先不要返回,你替我监视着这些描述符,当这堆文件描述符中有可以进行I/O读写操作的时候你再返回”;
3、当调用的这个函数返回后就能知道哪些文件描述符可以进行I/O操作了。
**
三、I/O多路复用三剑客**
由于调用这些I/O多路复用函数时如果任何一个需要监视的文件描述符都不可读或者可写那么进程会被阻塞暂停执行,直到有文件描述符可读或者可写才继续运行。所以Linux上的select、poll、epoll都是阻塞式I/O,也就是同步I/O。
1、select:初出茅庐
在select I/O多路复用机制下,需要把想监控的文件描述集合通过函数参数的形式告诉select,然后select将这些文件描述符集合拷贝到内核中。为了减少这种数据拷贝带来的性能损耗,Linux内核对集合的大小做了限制,并规定用户监控的文件描述集合不能超过1024个,同时当select返回后,仅仅能知道有些文件描述符可以读写了。
select的特点
1、能照看的文件描述符数量有限,不能超过1024个;
2、用户给文件描述符需要拷贝的内核中;
3、只能告诉有文件描述符满足要求但不知道是哪个。
2、poll:小有所成
poll和select是非常相似,相对于select的优化仅仅在于解决文件描述符不能超过1024个的限制,select和poll都会随着监控的文件描述数量增加而性能下降,因此不适合高并发场景。
3、epoll:独步天下
在select面临的三个问题中,文件描述数量限制已经在poll中解决了,剩下的两个问题呢?
针对拷贝问题
epoll使用的策略是各个击破与共享内存。文件描述符集合的变化频率比较低,select和poll频繁的拷贝整个集合,epoll通过引入epoll_ctl很体贴的做到了只操作那些有变化的文件描述符。同时epoll和内核还成为了好朋友,共享了同一块内存,这块内存中保存的就是那些已经可读或者可写的的文件描述符集合,这样就减少了内核和程序的拷贝开销。
针对需要遍历文件描述符才能知道哪个可读可写的问题,epoll使用的策略是在select和poll机制下:进程要亲自下场去各个文件描述符上等待,任何一个文件描述可读或者可写就唤醒进程,但是进程被唤醒后也是一脸懵逼并不知道到底是哪个文件描述符可读或可写,还要再从头到尾检查一遍。在epoll机制下进程不需要亲自下场了,进程只要等待在epoll上,epoll代替进程去各个文件描述符上等待,当哪个文件描述符可读或者可写的时候就告诉epoll,由epoll记录。
在epoll这种机制下,实际上利用的就是“不要打电话给我,有需要我会打给你”这种策略,进程不需要一遍一遍麻烦的问各个文件描述符,而是翻身做主人了——“你们这些文件描述符有哪个可读或者可写了主动报上来”。
同步与异步
**
一、同步与异步场景:打电话与发邮件**
1、同步
通常打电话时都是一个人在说另一个人听,一个人在说的时候另一个人等待,等另一个人说完后再接着说,因此在这个场景中你可以看到,“依赖”、“关联”、“等待”这些关键词出现了,因此打电话这种沟通方式就是所谓的同步。
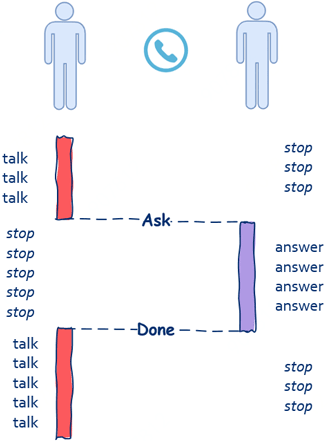
2、异步
另一种常用的沟通方式是邮件,因为没有人傻等着你写邮件什么都不做,因此你可以慢慢悠悠的写,当你在写邮件时收件人可以去做一些像摸摸鱼啊、上个厕所、和同时抱怨一下为什么十一假期不放两周之类有意义的事情。同时当你写完邮件发出去后也不需要干巴巴的等着对方回复什么都不做,你也可以做一些像摸鱼之类这样有意义的事情。
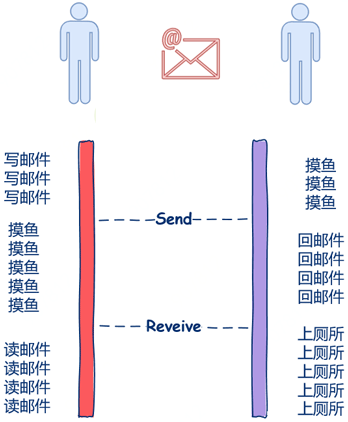
在这里,你写邮件别人摸鱼,这两件事又在同时进行,收件人和发件人都不需要相互等待,发件人写完邮件的时候简单的点个发送就可以了,收件人收到后就可以阅读啦,收件人和发件人不需要相互依赖、不需要相互等待。因此邮件这种沟通方式就是异步的。
二、编程中的同步调用
一般的函数调用都是同步的,就像这样:
funcA调用funcB,那么在funcB执行完前,funcA中的后续代码都不会被执行,也就是说funcA必须等待funcB执行完成,如下图所示。
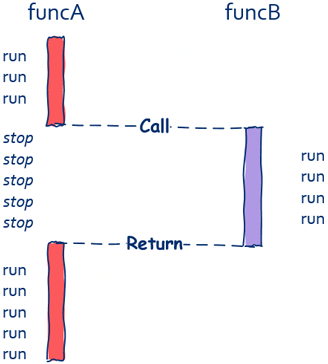
从上图中可以看出,在funcB运行期间funcA什么都做不了,这就是典型的同步。一般来说,像这种同步调用,funcA和funcB是运行在同一个线程中的,但值得注意的是即使运行在两个不能线程中的函数也可以进行同步调用,像我们进行IO操作时实际上底层是通过系统调用的方式向操作系统发出请求。
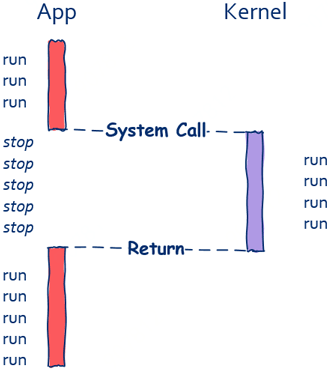
如上图所示,只有当read函数返回后程序才可以被继续执行。和上面的同步调用不同的是,函数和被调函数运行在不同的线程中。由此我们可以得出结论,同步调用和函数与被调函数是否运行在同一个线程是没有关系的。在这里需要再次强调同步方式下函数和被调函数无法同时进行。
三、编程中的异步调用
有同步调用就有异步调用。一般来说异步调用总是和I/O操作等耗时较高的任务如影随形,像磁盘文件读写、网络数据的收发、数据库操作等。
在这里以磁盘文件读取为例,在read函数的同步调用方式下,文件读取完之前调用方是无法继续向前推进的,但如果read函数可以异步调用情况就不一样了。假如read函数可以异步调用的话,即使文件还没有读取完成,read函数也可以立即返回。
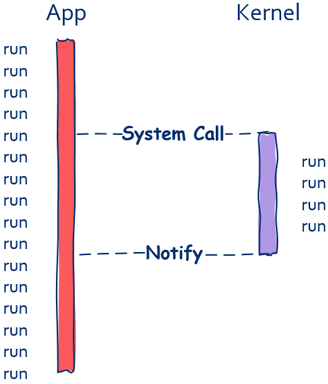
如上图所示,在异步调用方式下,调用方不会被阻塞,函数调用完成后可以立即执行接下来的程序。这时异步的重点在于调用方接下来的程序执行可以和文件读取同时进行。值得注意的是异步调用对于程序员来说在理解上是一种负担,代码编写上更是一种负担,总的来说,上帝在为你打开一扇门的时候会适当的关上一扇窗户。
有的同学可能会问,在同步调用下,调用方不再继续执行而是暂停等待,被调函数执行完后很自然的就是调用方继续执行,那么异步调用下调用方怎知道被调函数是否执行完成呢?这就分为调用方根本就不关心执行结果和调用方需要知道执行结果两种情况。
第一种情况比较简单,无需讨论。
第二种情况下就比较有趣了,通常有两种实现方式:
1、通知机制
当任务执行完成后发送信号来通知调用方任务完成(这里的信号有很多实现方式:Linux中的signal,或使用信号量等机制都可实现);
2、回调机制:
也就是常说的callback。
四、具体的编程例子中理解同步和异步
以常见Web服务为例来说明这个问题。一般来说Web Server接收到用户请求后会有一些典型的处理逻辑,最常见的就是数据库查询(当然,你也可以把这里的数据库查询换成其它I/O操作,比如磁盘读取、网络通信等),在这里假定处理一次用户请求需要经过步骤A、B、C,然后读取数据库,数据库读取完成后需要经过步骤D、E、F。
其中步骤A、B、C和D、E、F不需要任何I/O,也就是说这六个步骤不需要读取文件、网络通信等,涉及到I/O操作的只有数据库查询这一步。一般来说Web Server有主线程和数据库处理线程两个典型的线程。
首先我们来看下最简单的实现方式,也就是同步。
这种方式最为自然也最为容易理解:
主线程在发出数据库查询请求后就会被阻塞而暂停运行,直到数据库查询完毕后面的D、E、F才可以继续运行,这就是最为典型的同步方法。
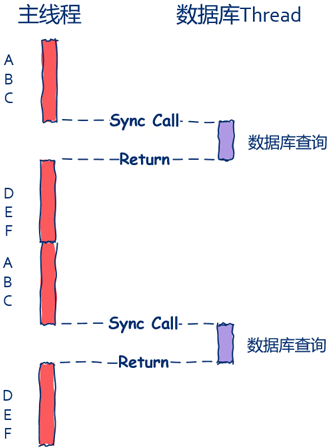
如上图所示,主线程中会有“空隙”,这个空隙就是主线程的“休闲时光”,主线程在这段休闲时光中需要等待数据库查询完成才能继续后续处理流程。在这里主线程就好比监工的老板,数据库线程就好比苦逼搬砖的程序员,在搬完砖前老板什么都不做只是紧紧的盯着你,等你搬完砖后才去忙其它事情。
1、异步情况:主线程不关心数据库操作结果
如下图所示,主线程根本就不关心数据库是否查询完毕,数据库查询完毕后自行处理接下来的D、E、F三个步骤。
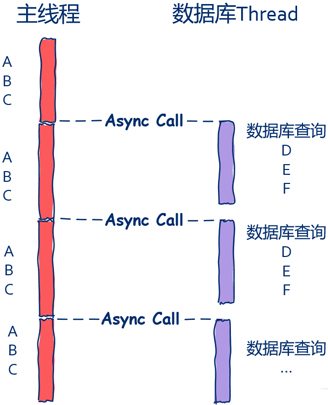
一个请求通常需要经过七个步骤,其中前三个是在主线程中完成的,后四个是在数据库线程中完成的,数据库线程通过回调函数查完数据库后处理D、E、F几个步骤。
伪码如下:
主线程处理请求和数据库处理查询请求可以同时进行,从系统性能上看能更加充分的利用系统资源,更加快速的处理请求;从用户的角度看,系统的响应也会更加迅速。这就是异步的高效之处。但可以看出,异步编程并不如同步来的容易理解,系统可维护性上也不如同步模式。
2、异步情况:主线程关心数据库操作结果
如下图所示,数据库线程需要将查询结果利用通知机制发送给主线程,主线程在接收到消息后继续处理上一个请求的后半部分。
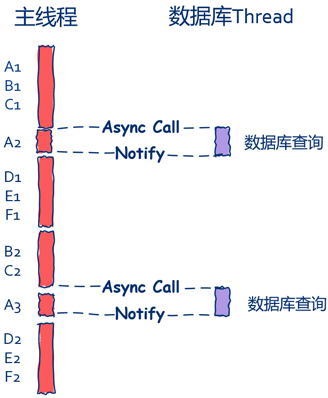
由此我们可以看到:ABCDEF几个步骤全部在主线中处理,同时主线程同样也没有了“休闲时光”,只不过在这种情况下数据库线程是比较清闲的,从这里并没有上一种方法高效,但是依然要比同步模式下要高效。但是要注意的是并不是所有的情况下异步都一定比同步高效,还需要结合具体业务以及IO的复杂度具体情况具体分析。
高并发中的协程
协程是高性能高并发编程中不可或缺的技术,包括即时通讯(IM系统)在内的互联网产品应用产品中应用广泛,比如号称支撑微信海量用户的后台框架就是基于协程打造的。而且越来越多的现代编程语言都将协程视为最重要的语言技术特征,已知的包括:Go、Python、Kotlin等。
一、从普通函数到协程
普通函数下,只有当执行完print("c")这句话后函数才会返回,但是在协程下当执行完print("a")后func就会因“暂停并返回”这段代码返回到调用函数。
我写一个return也能返回,就像这样:
直接写一个return语句确实也能返回,但这样写的话return后面的代码都不会被执行到了。
协程之所以神奇就神奇在当我们从协程返回后还能继续调用该协程,并且是从该协程的上一个返回点后继续执行。
就好比孙悟空说一声“定”,函数就被暂停了:
这时我们就可以返回到调用函数,当调用函数什么时候想起该协程后可以再次调用该协程,该协程会从上一个返回点继续执行。值得注意的是当普通函数返回后,进程的地址空间中不会再保存该函数运行时的任何信息,而协程返回后,函数的运行时信息是需要保存下来的。
二、“Talk is cheap,show me the code”
在python语言中,这个“定”字同样使用关键词yield。
这样我们的func函数就变成了:
这时我们的func就不再是简简单单的函数了,而是升级成为了协程,那么我们该怎么使用呢?
很简单:
虽然func函数没有return语句,也就是说虽然没有返回任何值,但是我们依然可以写co = func()这样的代码,意思是说co就是拿到的协程了。
接下来调用该协程,使用next(co),运行函数A看看执行到第3行的结果是什么:
显然,和预期一样协程func在print("a")后因执行yield而暂停并返回函数A。
接下来是第4行,这个毫无疑问,A函数在做一些自己的事情,因此会打印:
接下来是重点的一行,当执行第5行再次调用协程时该打印什么呢?
如果func是普通函数,那么会执行func的第一行代码,也就是打印a。
但func不是普通函数,而是协程,我们之前说过,协程会在上一个返回点继续运行,因此这里应该执行的是func函数第一个yield之后的代码,也就是 print("b")。
三、图形化解释
为了更加彻底的理解协程,我们使用图形化的方式再看一遍。
首先是普通的函数调用:
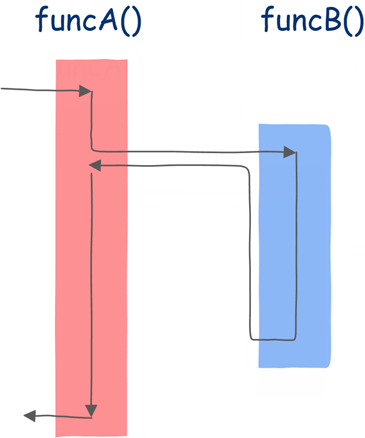
在该图中方框内表示该函数的指令序列,如果该函数不调用任何其它函数,那么应该从上到下依次执行,但函数中可以调用其它函数,因此其执行并不是简单的从上到下,箭头线表示执行流的方向。
从上图中可以看到:首先来到funcA函数,执行一段时间后发现调用了另一个函数funcB,这时控制转移到该函数,执行完成后回到main函数的调用点继续执行。这是普通的函数调用。
接下来是协程:
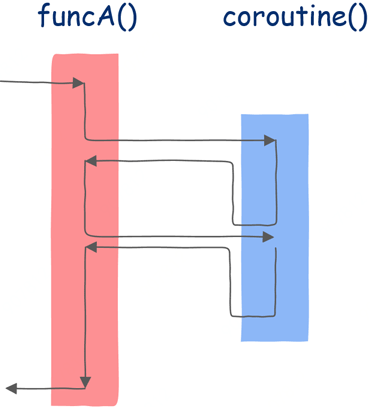
在这里依然首先在funcA函数中执行,运行一段时间后调用协程,协程开始执行,直到第一个挂起点,此后就像普通函数一样返回funcA函数,funcA函数执行一些代码后再次调用该协程。
三、函数只是协程的一种特例
和普通函数不同的是,协程能知道自己上一次执行到了哪里。协程会在函数被暂停运行时保存函数的运行状态,并可以从保存的状态中恢复并继续运行。
四、协程的历史
协程这种概念早在1958年就已经提出来了,要知道这时线程的概念都还没有提出来。到了1972年,终于有编程语言实现了这个概念,这两门编程语言就是Simula 67 以及Scheme。但协程这个概念始终没有流行起来,甚至在1993年还有人考古一样专门写论文挖出协程这种古老的技术。
因为这一时期还没有线程,如果你想在操作系统写出并发程序那么你将不得不使用类似协程这样的技术,后来线程开始出现,操作系统终于开始原生支持程序的并发执行,就这样,协程逐渐淡出了程序员的视线。 直到近些年,随着互联网的发展,尤其是移动互联网时代的到来,服务端对高并发的要求越来越高,协程再一次重回技术主流,各大编程语言都已经支持或计划开始支持协程。
五、协程到底如何实现?
让我们从问题的本质出发来思考这个问题协程的本质是什么呢? 协程之所以可以被暂停也可以继续,那么一定要记录下被暂停时的状态,也就是上下文,当继续运行的时候要恢复其上下文(状态)函数运行时所有的状态信息都位于函数运行时栈中。 如下图所示,函数运行时栈就是需要保存的状态,也就是所谓的上下文。
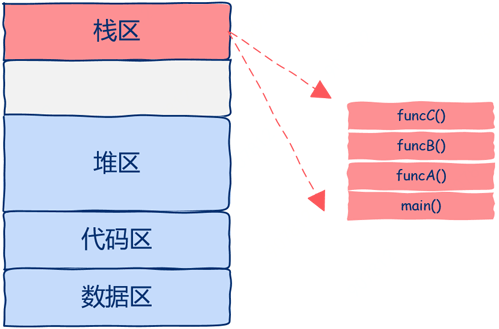
从上图中可以看出,该进程中只有一个线程,栈区中有四个栈帧,main函数调用A函数,A函数调用B函数,B函数调用C函数,当C函数在运行时整个进程的状态就如图所示。
再仔细想一想,为什么我们要这么麻烦的来回copy数据呢? 我们需要做的是直接把协程的运行需要的栈帧空间直接开辟在堆区中,这样都不用来回copy数据了,如下图所示。
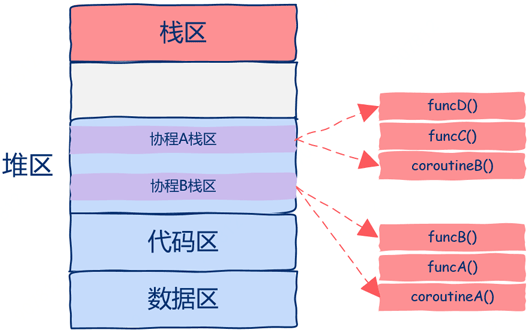
从上图中可以看到该程序中开启了两个协程,这两个协程的栈区都是在堆上分配的,这样我们就可以随时中断或者恢复协程的执行了。 进程地址空间最上层的栈区现在的作用是用来保存函数栈帧的,只不过这些函数并不是运行在协程而是普通线程中的。
在上图中实际上共有一个普通线程和两个协程3个执行流。 虽然有3个执行流但我们创建了几个线程呢? 答案是:一个线程。
使用协程理论上我们可以开启无数并发执行流,只要堆区空间足够,同时还没有创建线程的开销,所有协程的调度、切换都发生在用户态,这就是为什么协程也被称作用户态线程的原因所在。 所以即使创建了N多协程,但在操作系统看来依然只有一个线程,也就是说协程对操作系统来说是不可见的。
这也许是为什么协程这个概念比线程提出的要早的原因,可能是写普通应用的程序员比写操作系统的程序员最先遇到需要多个并行流的需求,那时可能都还没有操作系统的概念,或者操作系统没有并行这种需求,所以非操作系统程序员只能自己动手实现执行流,也就是协程。
六、协程技术概念小结
1、协程是比线程更小的执行单元
协程是比线程更小的一种执行单元可以认为是轻量级的线程。 之所以说轻的其中一方面的原因是协程所持有的栈比线程要小很多,java当中会为每个线程分配1M左右的栈空间,而协程可能只有几十或者几百K,栈主要用来保存函数参数、局部变量和返回地址等信息。
我们知道而线程的调度是在操作系统中进行的,而协程调度则是在用户空间进行的,是开发人员通过调用系统底层的执行上下文相关api来完成的。 有些语言,比如nodejs、go在语言层面支持了协程,而有些语言,比如C,需要使用第三方库才可以拥有协程的能力。
由于线程是操作系统的最小执行单元,因此也可以得出,协程是基于线程实现的,协程的创建、切换、销毁都是在某个线程中来进行的。 使用协程是因为线程的切换成本比较高,而协程在这方面很有优势。
2、协程的切换到底为什么很廉价?
关于这个问题,回顾一下线程切换的过程:
1)线程在进行切换的时候,需要将CPU中的寄存器的信息存储起来,然后读入另外一个线程的数据,这个会花费一些时间;
2)CPU的高速缓存中的数据,也可能失效,需要重新加载;
3)线程的切换会涉及到用户模式到内核模式的切换,据说每次模式切换都需要执行上千条指令,很耗时。
实际上协程的切换之所以快的原因主要是:
1)在切换的时候,寄存器需要保存和加载的数据量比较小;
2)高速缓存可以有效利用;
3)没有用户模式到内核模式的切换操作;
4)更有效率的调度,因为协程是非抢占式的,前一个协程执行完毕或者堵塞,才会让出CPU,而线程则一般使用了时间片的算法,会进行很多没有必要的切换。
高性能服务器到底是如何实现的?
当你在阅读文章的时候,有没有想过,服务器是怎么把这篇文章发送给你的呢? 说起来很简单不就是一个用户请求吗? 服务器根据请求从数据库中捞出这篇文章,然后通过网络发回去吗。 其实有点复杂服务器端到底是如何并行处理成千上万个用户请求的呢? 这里面又涉及到哪些技术呢?
一、多进程
历史上最早出现也是最简单的一种并行处理多个请求的方法就是利用多进程。 比如在Linux世界中,可以使用fork、exec等系统调用创建多个进程,可以在父进程中接收用户的连接请求,然后创建子进程去处理用户请求。
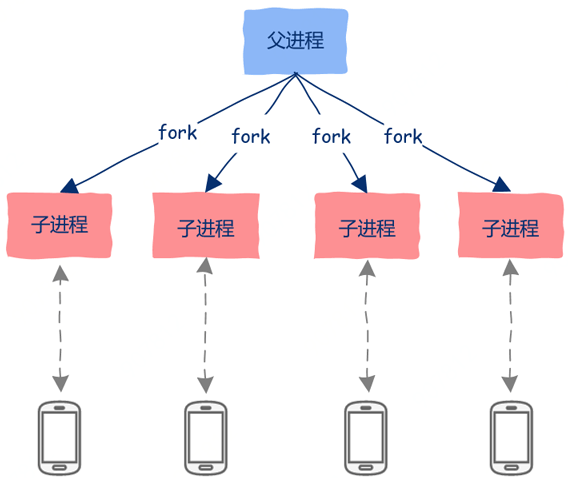
1、多进程并行处理的优点
1)编程简单,非常容易理解;
2)由于各个进程的地址空间是相互隔离的,因此一个进程崩溃后并不会影响其它进程;
3)充分利用多核资源。
2、多进程并行处理的缺点
1)各个进程地址空间相互隔离,这一优点也会变成缺点,那就是进程间要想通信就会变得比较困难,你需要借助进程间通信机制,想一想你现在知道哪些进程间通信机制,然后让你用代码实现呢? 显然,进程间通信编程相对复杂,而且性能也是一大问题;
2)创建进程开销是比线程要大的,频繁的创建销毁进程无疑会加重系统负担。
二、多线程
由于线程共享进程地址空间,因此线程间通信天然不需要借助任何通信机制,直接读取内存就好了。 线程创建销毁的开销也变小了,要知道线程就像寄居蟹一样,房子(地址空间)都是进程的,自己只是一个租客,因此非常的轻量级,创建销毁的开销也非常小。
我们可以为每个请求创建一个线程,即使一个线程因执行I/O操作——比如读取数据库等——被阻塞暂停运行也不会影响到其它线程。
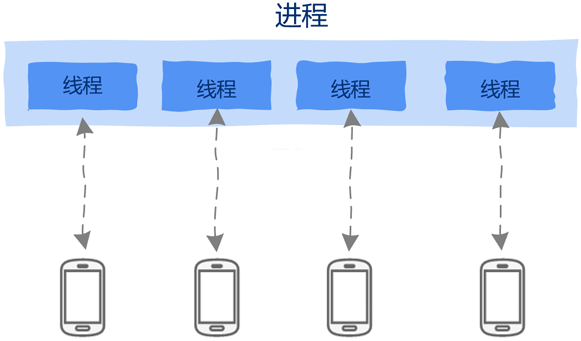
由于线程共享进程地址空间,这在为线程间通信带来便利的同时也带来了无尽的麻烦。 正是由于线程间共享地址空间,因此一个线程崩溃会导致整个进程崩溃退出,同时线程间通信简直太简单了,简单到线程间通信只需要直接读取内存就可以了,也简单到出现问题也极其容易,死锁、线程间的同步互斥、等等,这些极容易产生bug,无数程序员宝贵的时间就有相当一部分用来解决多线程带来的无尽问题。
虽然线程也有缺点,但是相比多进程来说,线程更有优势,但想单纯的利用多线程就能解决高并发问题也是不切实际的。因为虽然线程创建开销相比进程小,但依然也是有开销的,对于动辄数万数十万的链接的高并发服务器来说,创建数万个线程会有性能问题,这包括内存占用、线程间切换,也就是调度的开销。
三、事件驱动:Event Loop
到目前为止,提到“并行”二字就会想到进程、线程。但是并行编程只能依赖这两项技术吗?并不是这样的!还有另一项并行技术广泛应用在GUI编程以及服务器编程中,这就是近几年非常流行的事件驱动编程:event-based concurrency。
大家不要觉得这是一项很难懂的技术,实际上事件驱动编程原理上非常简单。
这一技术需要两种原料:
1)event;
2)处理event的函数,这一函数通常被称为event handler;
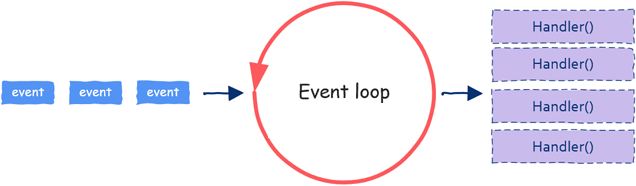
由于对于网络通信服务器来说,处理一个用户请求时大部分时间其实都用在了I/O操作上,像数据库读写、文件读写、网络读写等。当一个请求到来,简单处理之后可能就需要查询数据库等I/O操作,我们知道I/O是非常慢的,当发起I/O后我们大可以不用等待该I/O操作完成就可以继续处理接下来的用户请求。所以一个event loop可以同时处理多个请求。
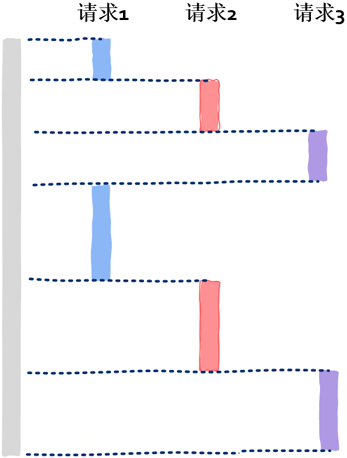
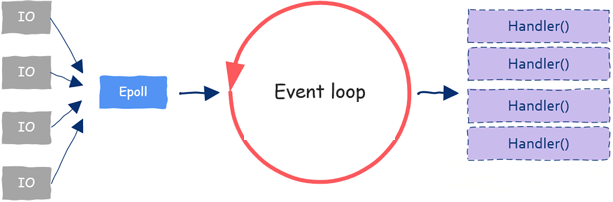
四、事件来源:IO多路复用
IO多路复用技术通过一次监控多个文件描述,当某个“文件”(实际可能是im网络通信中socket)可读或者可写的时候我们就能同时处理多个文件描述符啦。
这样IO多路复用技术就成了event loop的原材料供应商,源源不断的给我们提供各种event,这样关于event来源的问题就解决了。
五、问题:阻塞式IO
当我们进行IO操作,比如读取文件时,如果文件没有读取完成,那么我们的程序(线程)会被阻塞而暂停执行,这在多线程中不是问题,因为操作系统还可以调度其它线程。 但是在单线程的event loop中是有问题的,原因就在于当我们在event loop中执行阻塞式IO操作时整个线程(event loop)会被暂停运行,这时操作系统将没有其它线程可以调度,因为系统中只有一个event loop在处理用户请求,这样当event loop线程被阻塞暂停运行时所有用户请求都没有办法被处理。 你能想象当服务器在处理其它用户请求读取数据库导致你的请求被暂停吗?
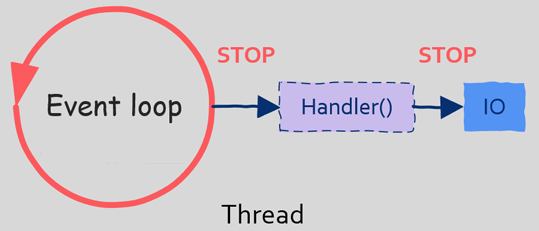
因此:在基于事件驱动编程时有一条注意事项,那就是不允许发起阻塞式IO。 有的同学可能会问,如果不能发起阻塞式IO的话,那么该怎样进行IO操作呢?
六、解决方法:非阻塞式IO
为克服阻塞式IO所带来的问题,现代操作系统开始提供一种新的发起IO请求的方法,这种方法就是异步IO。 对应的,阻塞式IO就是同步IO,关于同步和异步详见上文。
异步IO时,假设调用aio_read函数(具体的异步IO API请参考具体的操作系统平台),也就是异步读取,当我们调用该函数后可以立即返回,并继续其它事情,虽然此时该文件可能还没有被读取,这样就不会阻塞调用线程了。 此外,操作系统还会提供其它方法供调用线程来检测IO操作是否完成。
七、基于事件驱动并行编程的难点
虽然有异步IO来解决event loop可能被阻塞的问题,但是基于事件编程依然是困难的。
首先event loop是运行在一个线程中的,显然一个线程是没有办法充分利用多核资源的,有的同学可能会说那就创建多个event loop实例不就可以了,这样就有多个event loop线程了,但是这样一来多线程问题又会出现。
其次在于编程方面,异步编程需要结合回调函数(这种编程方式需要把处理逻辑分为两部分:一部分调用方自己处理,另一部分在回调函数中处理),这一编程方式的改变加重了程序员在理解上的负担,基于事件编程的项目后期会很难扩展以及维护。
八、更好的方法
有没有一种方法既能结合同步IO的简单理解又不会因同步调用导致线程被阻塞呢? 答案是肯定的,这就是用户态线程(user level thread),也就是大名鼎鼎的协程。
虽然基于事件编程有这样那样的缺点,但是在当今的高性能高并发服务器上基于事件编程方式依然非常流行,但已经不是纯粹的基于单一线程的事件驱动了,而是 event loop + multi thread + user level thread。
进程、线程、协程
一、什么是进程?
1、基本常识
计算机的核心是CPU,它承担了所有的计算任务; 操作系统是计算机的管理者,它负责任务的调度、资源的分配和管理,统领整个计算机硬件; 应用程序则是具有某种功能的程序,程序是运行于操作系统之上的。
进程是一个具有一定独立功能的程序在一个数据集上的一次动态执行的过程,是操作系统进行资源分配和调度的一个独立单位,是应用程序运行的载体。 进程是一种抽象的概念,从来没有统一的标准定义。
进程一般由程序、数据集合和进程控制块三部分组成:
程序用于描述进程要完成的功能,是控制进程执行的指令集;
数据集合是程序在执行时所需要的数据和工作区;
程序控制块(Program Control Block,简称PCB),包含进程的描述信息和控制信息,是进程存在的唯一标志。
进程的特点:
动态性:进程是程序的一次执行过程,是临时的,有生命期的,是动态产生,动态消亡的;
并发性:任何进程都可以同其他进程一起并发执行;
独立性:进程是系统进行资源分配和调度的一个独立单位;
结构性:进程由程序、数据和进程控制块三部分组成。
2、为什么要有多进程?
多进程目的是提高cpu的使用率。 假设只有一个进程(先不谈多线程),从操作系统的层面看,我们使用打印机的步骤有如下:
1)使用CPU执行程序,去硬盘读取需要打印的文件,然后CPU会长时间的等待,直到硬盘读写完成;
2)使用CPU执行程序,让打印机打印这些内容,然后CPU会长时间的等待,等待打印结束。
在这样的情况下:其实CPU的使用率其实非常的低。
打印一个文件从头到尾需要的时间可能是1分钟,而cpu使用的时间总和可能加起来只有几秒钟。 而后面如果单进程执行游戏的程序的时候,CPU也同样会有大量的空闲时间。
使用多进程后:
当CPU在等待硬盘读写文件,或者在等待打印机打印的时候,CPU可以去执行游戏的程序,这样CPU就能尽可能高的提高使用率。
再具体一点说,其实也提高了效率。 因为在等待打印机的时候,这时候显卡也是闲置的,如果用多进程并行的话,游戏进程完全可以并行使用显卡,并且与打印机之间也不会互相影响。
3、总结
进程直观点说是保存在硬盘上的程序运行以后,会在内存空间里形成一个独立的内存体,这个内存体有自己独立的地址空间,有自己的堆,上级挂靠单位是操作系统。 操作系统会进程为单位,分配系统资源(CPU时间片、内存等资源),进程是资源分配的最小单位。
二、什么是线程?
1、基本常识
早期操作系统中并没有线程的概念,进程是能拥有资源和独立运行的最小单位,也是程序执行的最小单位。 任务调度采用的是时间片轮转的抢占式调度方式,而进程是任务调度的最小单位,每个进程有各自独立的一块内存,使得各个进程之间内存地址相互隔离。 后来随着计算机的发展,对CPU的要求越来越高,进程之间的切换开销较大,已经无法满足越来越复杂的程序的要求了。 于是就发明了线程。
线程是程序执行中一个单一的顺序控制流程:
1)程序执行流的最小单元
2)处理器调度和分派的基本单位
一个进程可以有一个或多个线程,各个线程之间共享程序的内存空间(也就是所在进程的内存空间)。 一个标准的线程由线程ID、当前指令指针(PC)、寄存器和堆栈组成。 而进程由内存空间(代码、数据、进程空间、打开的文件)和一个或多个线程组成。
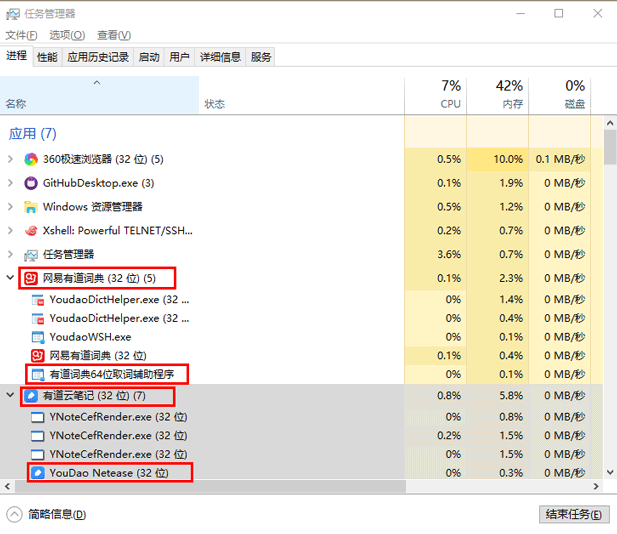
如上图所示,在任务管理器的进程一栏里,有道词典和有道云笔记就是进程,而在进程下又有着多个执行不同任务的线程。
2、任务调度
线程是什么? 要理解这个概念,需要先了解一下操作系统的一些相关概念。 大部分操作系统(如Windows、Linux)的任务调度是采用时间片轮转的抢占式调度方式。 在一个进程中:当一个线程任务执行几毫秒后,会由操作系统的内核(负责管理各个任务)进行调度,通过硬件的计数器中断处理器,让该线程强制暂停并将该线程的寄存器放入内存中,通过查看线程列表决定接下来执行哪一个线程,并从内存中恢复该线程的寄存器,最后恢复该线程的执行,从而去执行下一个任务。
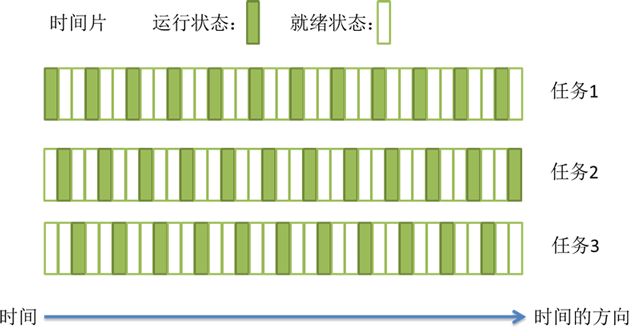
上述过程中任务执行的那一小段时间叫做时间片,任务正在执行时的状态叫运行状态,被暂停的线程任务状态叫做就绪状态,意为等待下一个属于它的时间片的到来。
这种方式保证了每个线程轮流执行,由于CPU的执行效率非常高,时间片非常短,在各个任务之间快速地切换,给人的感觉就是多个任务在“同时进行”,这也就是我们所说的并发(别觉得并发有多高深,它的实现很复杂,但它的概念很简单,就是一句话:多个任务同时执行)。
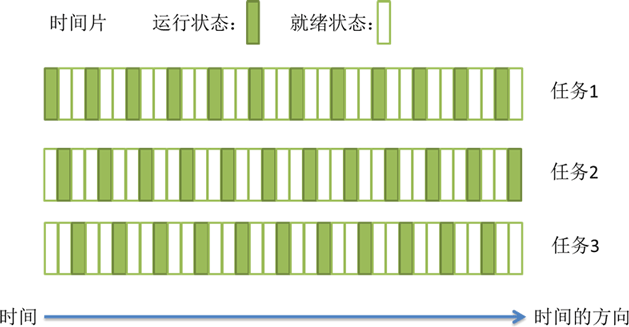
3、进程与线程的区别
进程与线程的关系
1)线程是程序执行的最小单位,而进程是操作系统分配资源的最小单位;
2)一个进程由一个或多个线程组成,线程是一个进程中代码的不同执行路线;
3)进程之间相互独立,但同一进程下的各个线程之间共享程序的内存空间(包括代码段、数据集、堆等)及一些进程级的资源(如打开文件和信号),某进程内的线程在其它进程不可见;
4)线程上下文切换比进程上下文切换要快得多。
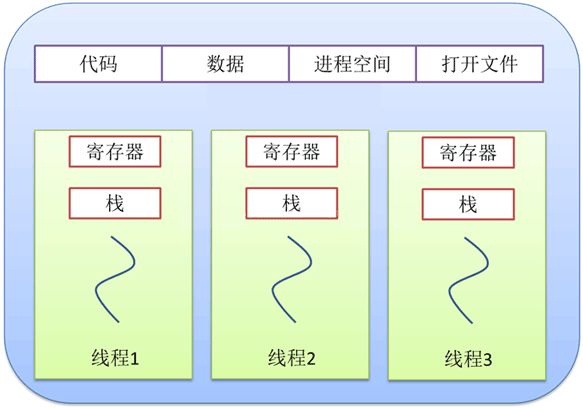
▲ 进程与线程的资源共享关系
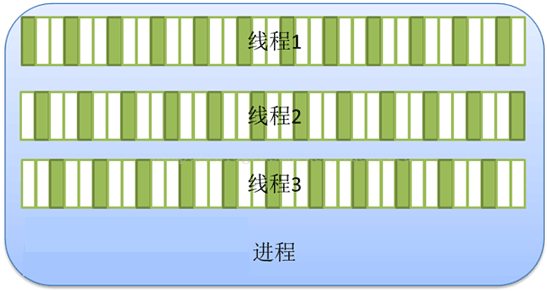
▲ 单线程与多线程的关系
总之线程和进程都是一种抽象的概念,线程是一种比进程更小的抽象,线程和进程都可用于实现并发。
在早期的操作系统中并没有线程的概念,进程是能拥有资源和独立运行的最小单位,也是程序执行的最小单位。 它相当于一个进程里只有一个线程,进程本身就是线程。 所以线程有时被称为轻量级进程。
后来随着计算机的发展,对多个任务之间上下文切换的效率要求越来越高,就抽象出一个更小的概念——线程,一般一个进程会有多个(也可以是一个)线程。
4、多线程与多核
上面提到的时间片轮转的调度方式说一个任务执行一小段时间后强制暂停去执行下一个任务,每个任务轮流执行。很多操作系统的书都说“同一时间点只有一个任务在执行”。其实“同一时间点只有一个任务在执行”这句话是不准确的,至少它是不全面的。那多核处理器的情况下,线程是怎样执行呢?这就需要了解内核线程。
多核(心)处理器是指在一个处理器上集成多个运算核心从而提高计算能力,也就是有多个真正并行计算的处理核心,每一个处理核心对应一个内核线程。内核线程(Kernel Thread,KLT)就是直接由操作系统内核支持的线程,这种线程由内核来完成线程切换,内核通过操作调度器对线程进行调度,并负责将线程的任务映射到各个处理器上。
一般一个处理核心对应一个内核线程,比如单核处理器对应一个内核线程,双核处理器对应两个内核线程,四核处理器对应四个内核线程。
现在的电脑一般是双核四线程、四核八线程,是采用超线程技术将一个物理处理核心模拟成两个逻辑处理核心,对应两个内核线程,所以在操作系统中看到的CPU数量是实际物理CPU数量的两倍,如你的电脑是双核四线程,打开“任务管理器 -> 性能”可以看到4个CPU的监视器,四核八线程可以看到8个CPU的监视器。
超线程技术就是利用特殊的硬件指令,把一个物理芯片模拟成两个逻辑处理核心,让单个处理器都能使用线程级并行计算,进而兼容多线程操作系统和软件,减少了CPU的闲置时间,提高的CPU的运行效率。这种超线程技术(如双核四线程)由处理器硬件的决定,同时也需要操作系统的支持才能在计算机中表现出来。
程序一般不会直接去使用内核线程,而是去使用内核线程的一种高级接口——轻量级进程(Lightweight Process,LWP),轻量级进程就是通常意义上所讲的线程,也被叫做用户线程。
由于每个轻量级进程都由一个内核线程支持,因此只有先支持内核线程,才能有轻量级进程。
用户线程与内核线程的对应关系有三种模型:
1)一对一模型;
2)多对一模型;
3)多对多模型。
5、一对一模型
对于一对一模型来说:一个用户线程就唯一地对应一个内核线程(反过来不一定成立,一个内核线程不一定有对应的用户线程)。 这样如果CPU没有采用超线程技术(如四核四线程的计算机),一个用户线程就唯一地映射到一个物理CPU的内核线程,线程之间的并发是真正的并发。
一对一模型优点
使用户线程具有与内核线程一样的优点一个线程因某种原因阻塞时其他线程的执行不受影响(此处,一对一模型也可以让多线程程序在多处理器的系统上有更好的表现)。
一对一模型缺点
1)许多操作系统限制了内核线程的数量,因此一对一模型会使用户线程的数量受到限制;
2)许多操作系统内核线程调度时,上下文切换的开销较大,导致用户线程的执行效率下降。
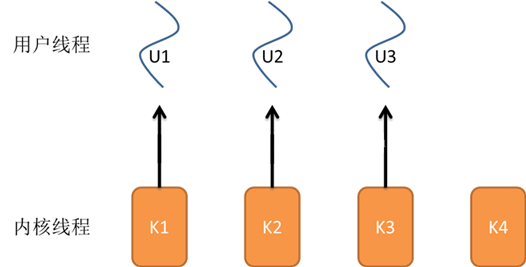
▲ 一对一模型
6、多对一模型
多对一模型将多个用户线程映射到一个内核线程上,线程之间的切换由用户态的代码来进行,系统内核感受不到线程的实现方式。 用户线程的建立、同步、销毁等都在用户态中完成,不需要内核的介入。
多对一模型优点
1)多对一模型的线程上下文切换速度要快许多;
2)多对一模型对用户线程的数量几乎无限制。
多对一模型缺点
1)如果其中一个用户线程阻塞,那么其它所有线程都将无法执行,因为此时内核线程也随之阻塞了;
2)在多处理器系统上,处理器数量的增加对多对一模型的线程性能不会有明显的增加,因为所有的用户线程都映射到一个处理器上了。
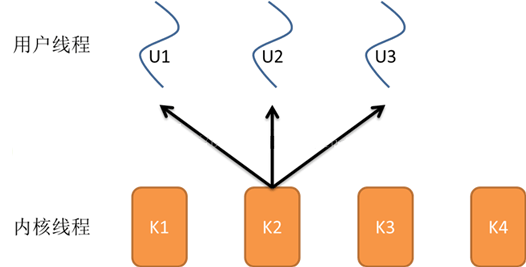
▲ 多对一模型
7、多对多模型
多对多模型结合了一对一模型和多对一模型的优点将多个用户线程映射到多个内核线程上,由线程库负责在可用的可调度实体上调度用户线程。
这使得线程的上下文切换非常快,因为它避免了系统调用。 但是增加了复杂性和优先级倒置的可能性,以及在用户态调度程序和内核调度程序之间没有广泛(且高昂)协调的次优调度。
多对多模型的优点
1)一个用户线程的阻塞不会导致所有线程的阻塞,因为此时还有别的内核线程被调度来执行;
2)多对多模型对用户线程的数量没有限制;
3)在多处理器的操作系统中,多对多模型的线程也能得到一定的性能提升,但提升的幅度不如一对一模型的高。
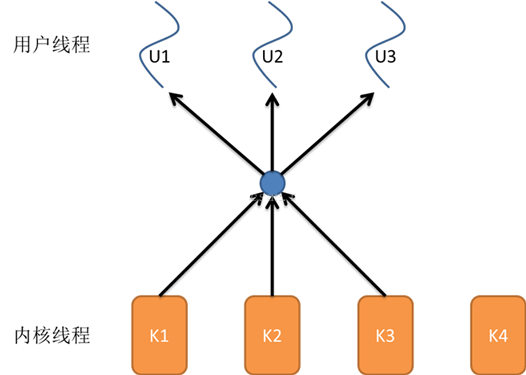
▲ 多对多模型
在现在流行的操作系统中,大都采用多对多的模型。
8、查看进程与线程
一个应用程序可能是多线程的,也可能是多进程的,如何查看呢?
在Windows下我们只须打开任务管理器就能查看一个应用程序的进程和线程数。 按“Ctrl+Alt+Del”或右键快捷工具栏打开任务管理器。
在“进程”选项卡下,我们可以看到一个应用程序包含的线程数。
如果一个应用程序有多个进程,我们能看到每一个进程,如在上图中,Google的Chrome浏览器就有多个进程。
同时,如果打开了一个应用程序的多个实例也会有多个进程,如上图中我打开了两个cmd窗口,就有两个cmd进程。 如果看不到线程数这一列,可以再点击“查看 -> 选择列”菜单,增加监听的列。
查看CPU和内存的使用率:在性能选项卡中,我们可以查看CPU和内存的使用率,根据CPU使用记录的监视器的个数还能看出逻辑处理核心的个数,如我的双核四线程的计算机就有四个监视器。
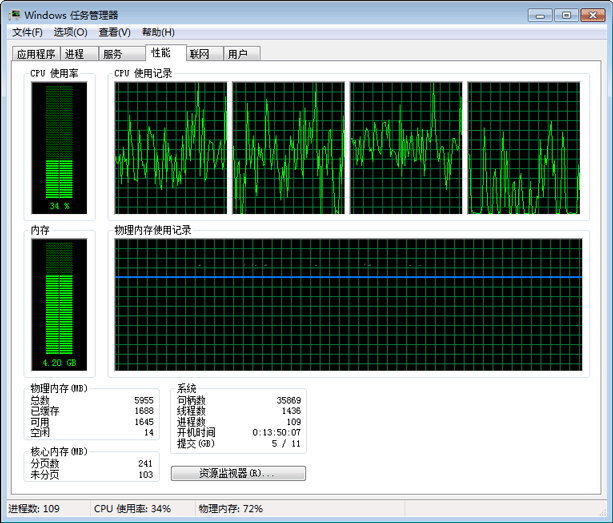
▲ 查看CPU和内存的使用率
9、线程的生命周期
当线程的数量小于处理器的数量时,线程的并发是真正的并发,不同的线程运行在不同的处理器上。 但当线程的数量大于处理器的数量时,线程的并发会受到一些阻碍,此时并不是真正的并发,因为此时至少有一个处理器会运行多个线程。
在单个处理器运行多个线程时,并发是一种模拟出来的状态。 操作系统采用时间片轮转的方式轮流执行每一个线程。 现在,几乎所有的现代操作系统采用的都是时间片轮转的抢占式调度方式,如我们熟悉的Unix、Linux、Windows及macOS等流行的操作系统。
我们知道线程是程序执行的最小单位,也是任务执行的最小单位。 在早期只有进程的操作系统中,进程有五种状态,创建、就绪、运行、阻塞(等待)、退出。 早期的进程相当于现在的只有单个线程的进程,那么现在的多线程也有五种状态,现在的多线程的生命周期与早期进程的生命周期类似。
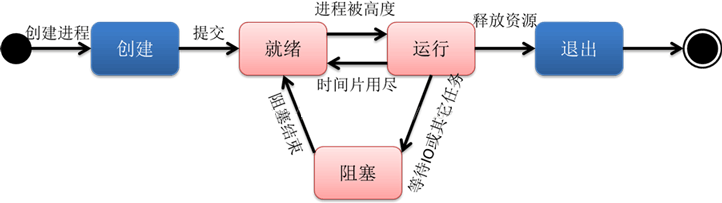
▲ 早期进程的生命周期
进程在运行过程有三种状态:就绪、运行、阻塞,创建和退出状态描述的是进程的创建过程和退出过程。
早期进程的生命周期:
创建:进程正在创建,还不能运行。操作系统在创建进程时要进行的工作包括分配和建立进程控制块表项、建立资源表格并分配资源、加载程序并建立地址空间;
就绪:时间片已用完,此线程被强制暂停,等待下一个属于它的时间片到来;
运行:此线程正在执行,正在占用时间片;
阻塞:也叫等待状态,等待某一事件(如IO或另一个线程)执行完;
退出:进程已结束,所以也称结束状态,释放操作系统分配的资源。
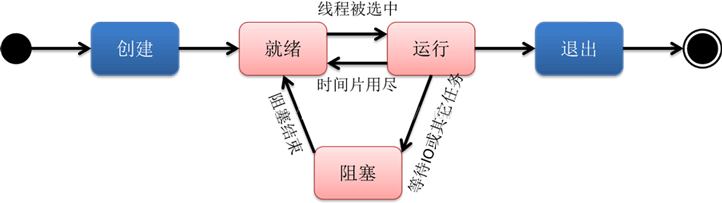
▲ 线程的生命周期
线程的生命周期跟进程很类似:
创建:一个新的线程被创建,等待该线程被调用执行;
就绪:时间片已用完,此线程被强制暂停,等待下一个属于它的时间片到来;
运行:此线程正在执行,正在占用时间片;
阻塞:也叫等待状态,等待某一事件(如IO或另一个线程)执行完;
退出:一个线程完成任务或者其他终止条件发生,该线程终止进入退出状态,退出状态释放该线程所分配的资源。
五、什么是协程?
1、基本常识
协程是一种基于线程之上,但又比线程更加轻量级的存在,这种由程序员自己写程序来管理的轻量级线程叫做“用户空间线程”,具有对内核来说不可见的特性。由于是自主开辟的异步任务,所以很多人也更喜欢叫它们纤程(Fiber),或者绿色线程(GreenThread)。正如一个进程可以拥有多个线程一样,一个线程也可以拥有多个协程。
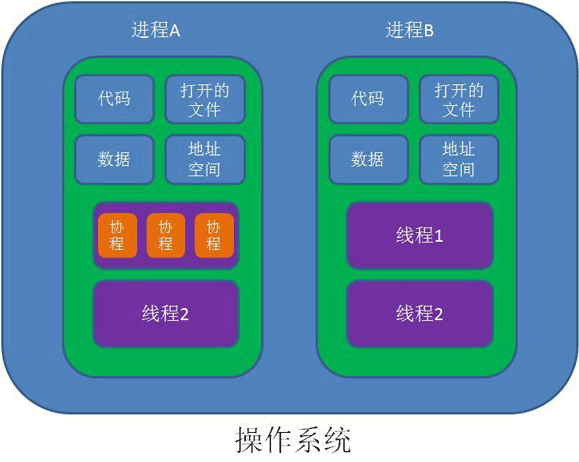
2、协程的目的
对于Java程序员来说,在传统的J2EE系统中都是基于每个请求占用一个线程去完成完整的业务逻辑(包括事务)。所以系统的吞吐能力取决于每个线程的操作耗时。
如果遇到很耗时的I/O行为,则整个系统的吞吐立刻下降,因为这个时候线程一直处于阻塞状态,如果线程很多的时候,会存在很多线程处于空闲状态(等待该线程执行完才能执行),造成了资源应用不彻底。
最常见的例子就是JDBC(它是同步阻塞的),这也是为什么很多人都说数据库是瓶颈的原因。这里的耗时其实是让CPU一直在等待I/O返回,说白了线程根本没有利用CPU去做运算,而是处于空转状态。而另外过多的线程,也会带来更多的ContextSwitch开销。
对于上述问题:现阶段行业里的比较流行的解决方案之一就是单线程加上异步回调。其代表派是 node.js 以及 Java 里的新秀 Vert.x 。
而协程的目的就是当出现长时间的I/O操作时,通过让出目前的协程调度,执行下一个任务的方式,来消除ContextSwitch上的开销。
3、协程的特点
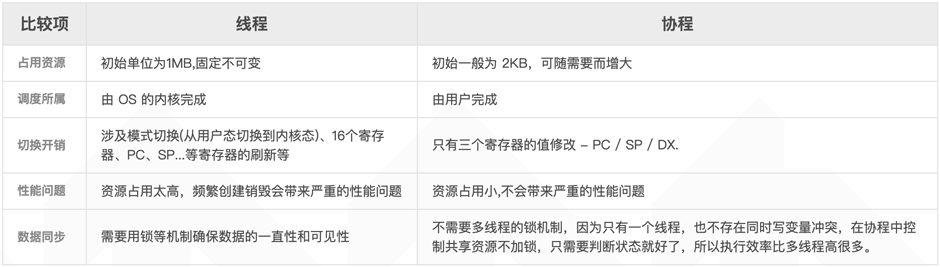
协程的特点总结一下就是:
1)线程的切换由操作系统负责调度,协程由用户自己进行调度,因此减少了上下文切换,提高了效率;
2)线程的默认Stack大小是1M,而协程更轻量,接近1K。 因此可以在相同的内存中开启更多的协程;
3)由于在同一个线程上,因此可以避免竞争关系而使用锁;
4)适用于被阻塞的,且需要大量并发的场景。 但不适用于大量计算的多线程,遇到此种情况,更好实用线程去解决。
4、协程的原理
当出现IO阻塞的时候,由协程的调度器进行调度,通过将数据流立刻yield掉(主动让出),并且记录当前栈上的数据,阻塞完后立刻再通过线程恢复栈,并把阻塞的结果放到这个线程上去跑。
这样看上去好像跟写同步代码没有任何差别,这整个流程可以称为coroutine,而跑在由coroutine负责调度的线程称为Fiber。 比如Golang里的 go关键字其实就是负责开启一个Fiber,让func逻辑跑在上面。
由于协程的暂停完全由程序控制,发生在用户态上; 而线程的阻塞状态是由操作系统内核来进行切换,发生在内核态上。 因此协程的开销远远小于线程的开销,也就没有了ContextSwitch上的开销。
5、协程和线程的比较
六、总结
1、进程和线程的区别
1)调度:线程作为调度和分配的基本单位,进程作为拥有资源的基本单位;
2)并发性:不仅进程之间可以并发执行,同一个进程的多个线程之间也可并发执行;
3)拥有资源:进程是拥有资源的一个独立单位,线程不拥有系统资源,但可以访问隶属于进程的资源;
4)系统开销:在创建或撤消进程时,由于系统都要为之分配和回收资源,导致系统的开销明显大于创建或撤消线程时的开销。
2、进程和线程的联系
1)一个线程只能属于一个进程,而一个进程可以有多个线程,但至少有一个线程;
2)资源分配给进程,同一进程的所有线程共享该进程的所有资源;
3)处理机分给线程,即真正在处理机上运行的是线程;
4)线程在执行过程中,需要协作同步。 不同进程的线程间要利用消息通信的办法实现同步。
开发者在每个线程中只做非常轻量的操作,比如访问一个极小的文件,下载一张极小的图片,加载一段极小的文本等。 但是,这样”轻量的操作“的量却非常多。
在有大量这样的轻量操作的场景下,即使可以通过使用线程池来避免创建与销毁的开销,但是线程切换的开销也会非常大,甚至于接近操作本身的开销。 对于这些场景,就非常需要一种可以减少这些开销的方式。 于是,协程就应景而出,非常适合这样的场景。
审核编辑:汤梓红
-
gpu
+关注
关注
28文章
5271浏览量
136070 -
服务器
+关注
关注
14文章
10359浏览量
91759 -
线程
+关注
关注
0文章
510浏览量
20871 -
进程
+关注
关注
0文章
211浏览量
14562
发布评论请先 登录



评论