 如何在英特尔独立显卡上训练TensorFlow模型的全流程
如何在英特尔独立显卡上训练TensorFlow模型的全流程

本文将基于蝰蛇峡谷(Serpent Canyon) 详细介绍如何在英特尔独立显卡上训练 TensorFlow 模型的全流程。
1.1 英特尔 锐炫 独立显卡简介
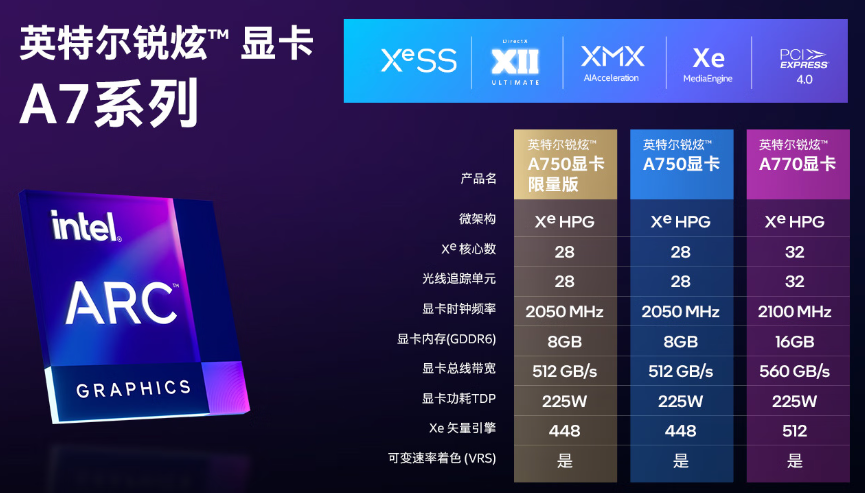
英特尔 锐炫 显卡基于 Xe-HPG 微架构,Xe HPG GPU 中的每个 Xe 内核都配置了一组 256 位矢量引擎,旨在加速传统图形和计算工作负载,以及新的 1024 位矩阵引擎或 Xe 矩阵扩展,旨在加速人工智能工作负载。
1.2 蝰蛇峡谷简介

蝰蛇峡谷(Serpent Canyon) 是一款性能强劲,并且体积小巧的高性能迷你主机,搭载全新一代混合架构的第 12 代智能英特尔 酷睿 处理器,并且内置了英特尔 锐炫 A770M 独立显卡。
搭建训练 TensorFlow 模型的开发环境
Windows 版本要求
训练 TensorFlow 所依赖的软件包 TensorFlow-DirectML-Plugin 包要求:
Windows 10的版本≥1709
Windows 11的版本≥21H2
用“Windows logo 键+ R键”启动“运行”窗口,然后输入命令“winver”可以查得Windows版本。

下载并安装最新的英特尔显卡驱动
到英特尔官网下载并安装最新的英特尔显卡驱动。驱动下载链接:
https://www.intel.cn/content/www/cn/zh/download/726609/intel-arc-iris-xe-graphics-whql-windows.html
下载并安装Anaconda
下载并安装 Python 虚拟环境和软件包管理工具Anaconda:
https://www.anaconda.com/
安装完毕后,用下面的命令创建并激活虚拟环境tf2_a770:
conda create --name tf2_a770 python=3.9 conda activate tf2_a770
向右滑动查看完整代码
安装TensorFlow2
在虚拟环境 tf2_a770 中安装 TensorFlow 2.10。需要注意的是:tensorflow-directml-plugin软件包当前只支持TensorFlow 2.10。
pip install tensorflow-cpu==2.10
向右滑动查看完整代码
安装 tensorflow-directml-plugin
在虚拟环境 tf2_a770 中安装 tensorflow-directml-plugin,这是一个在 Windows 平台上的机器学习训练加速软件包。
// @brief 加载推理数据
// @param input_node_name 输入节点名
// @param input_data 输入数据数组
public void load_input_data(string input_node_name, float[] input_data) {
ptr = NativeMethods.load_input_data(ptr, input_node_name, ref input_data[0]);
}
// @brief 加载图片推理数据
// @param input_node_name 输入节点名
// @param image_data 图片矩阵
// @param image_size 图片矩阵长度
public void load_input_data(string input_node_name, byte[] image_data, ulong image_size, int type) {
ptr = NativeMethods.load_image_input_data(ptr, input_node_name, ref image_data[0], image_size, type);
}
向右滑动查看完整代码
到此,在 Windows 平台上用英特尔独立显卡训练 TensorFlow 模型的开发环境配置完毕。
在英特尔独立显卡上训练 TensorFlow 模型
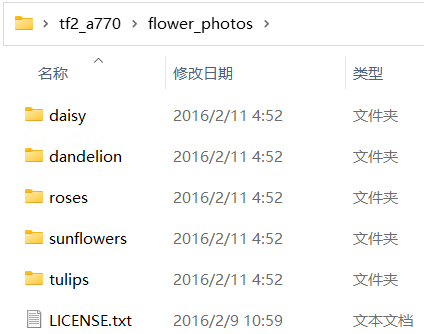
下载并解压 flower 数据集
用下载器(例如,迅雷)下载并解压 flower 数据集,下载链接:
https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz
下载训练代码启动训练
请下载 tf2_training_on_A770.py 并放入 flower_photos 同一个文件夹下运行。链接:
https://gitee.com/ppov-nuc/training_on_intel_GPU/blob/main/tf2_training_on_A770.py
from pathlib import Path
import tensorflow as tf
data_dir = Path("flower_photos")
image_count = len(list(data_dir.glob('*/*.jpg')))
print("Number of image files:", image_count)
# 导入Flower数据集
train_ds = tf.keras.utils.image_dataset_from_directory(data_dir, validation_split=0.2,
subset="training", seed=123, image_size=(180, 180), batch_size=32)
val_ds = tf.keras.utils.image_dataset_from_directory(data_dir, validation_split=0.2, subset="validation", seed=123, image_size=(180, 180), batch_size=32)
# 启动预取和数据缓存
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=tf.data.AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=tf.data.AUTOTUNE)
# 创建模型
model = tf.keras.Sequential([
tf.keras.layers.Rescaling(1./255),
tf.keras.layers.Conv2D(16, 3, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(32, 3, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(64, 3, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(5)
])
# 编译模型
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
#训练模型
model.fit(train_ds,validation_data=val_ds,epochs=20)
向右滑动查看完整代码
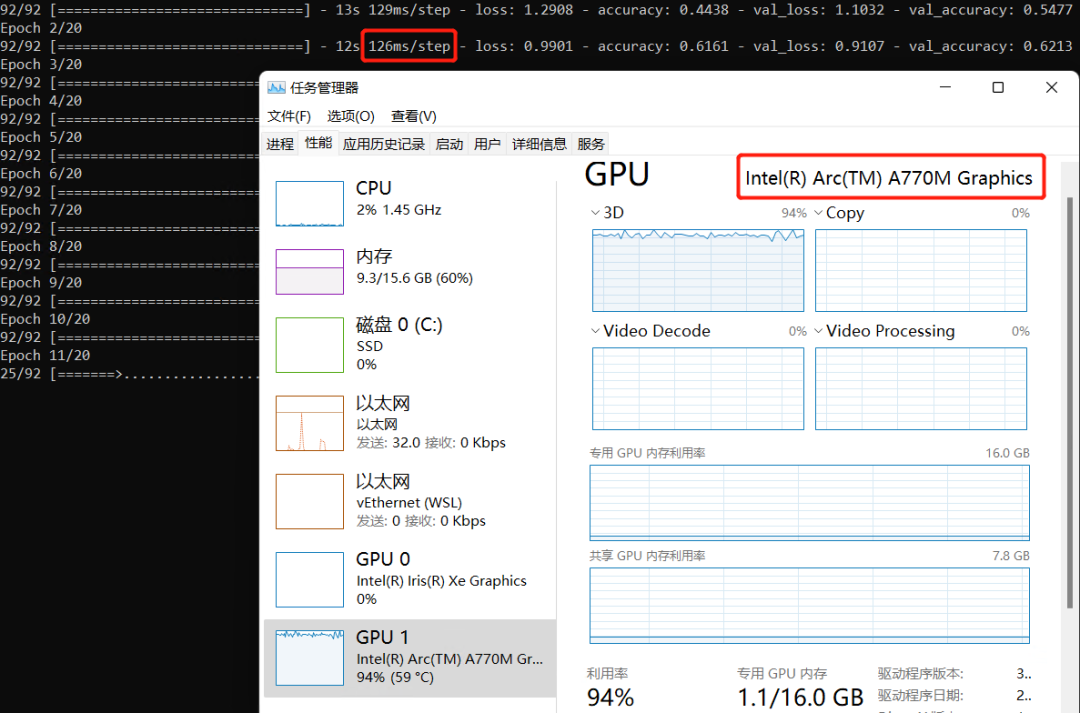
总结
英特尔独立显卡支持 TensorFlow 模型训练。下一篇文章,我们将介绍在英特尔独立显卡上训练 PyTorch 模型。
审核编辑 :李倩
-
英特尔
+关注
关注
61文章
10326浏览量
181122 -
模型
+关注
关注
1文章
3831浏览量
52285 -
tensorflow
+关注
关注
13文章
336浏览量
62392
原文标题:在英特尔独立显卡上训练TensorFlow模型 | 开发者实战
文章出处:【微信号:英特尔物联网,微信公众号:英特尔物联网】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
智能体PC时代来临,英特尔亮出哪些硬核实力

杰和科技亮相英特尔高峰论坛 以全栈智算方案助力产业智能升级

发力图形工作站和AI推理市场,英特尔大显存GPU亮相湾芯展

在Ubuntu20.04系统中训练神经网络模型的一些经验
英特尔Gaudi 2E AI加速器为DeepSeek-V3.1提供加速支持

硬件与应用同频共振,英特尔Day 0适配腾讯开源混元大模型
英特尔发布边缘AI控制器与边缘智算一体机,创造“AI新视界”

英特尔先进封装,新突破
新思科技与英特尔在EDA和IP领域展开深度合作
直击Computex 2025:英特尔重磅发布新一代GPU,图形和AI性能跃升3.4倍

直击Computex2025:英特尔重磅发布新一代GPU,图形和AI性能跃升3.4倍

英特尔发布全新GPU,AI和工作站迎来新选择
英特尔以系统级代工模式促进生态协同,助力客户创新
英特尔持续推进核心制程和先进封装技术创新,分享最新进展
如何在Ubuntu上安装NVIDIA显卡驱动?



评论