 自编码器 AE(AutoEncoder)程序
自编码器 AE(AutoEncoder)程序

1.程序讲解
(1)香草编码器
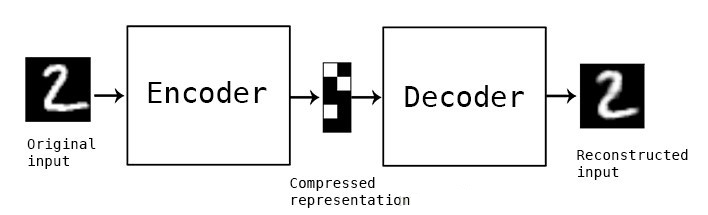
在这种自编码器的最简单结构中,只有三个网络层,即只有一个隐藏层的神经网络。它的输入和输出是相同的,可通过使用Adam优化器和均方误差损失函数,来学习如何重构输入。
在这里,如果 隐含层维数(64)小于输入维数(784 ),则称这个编码器是有损的。通过这个约束,来迫使神经网络来学习数据的压缩表征。
input_size = 784
hidden_size = 64
output_size = 784
x = Input(shape=(input_size,))
# Encoder
h = Dense(hidden_size, activation='relu')(x)
# Decoder
r = Dense(output_size, activation='sigmoid')(h)
autoencoder = Model(input=x, output=r)
autoencoder.compile(optimizer='adam', loss='mse')
Dense :Keras Dense层,keras.layers.core.Dense( units, activation=None)
units, #代表该层的输出维度
activation=None, #激活函数.但是默认 liner
Activation :激活层对一个层的输出施加激活函数
model.compile() :Model模型方法之一:compile
optimizer :优化器,为预定义优化器名或优化器对象,参考优化器
loss :损失函数,为预定义损失函数名或一个目标函数,参考损失函数
adam :adaptive moment estimation,是对RMSProp优化器的更新。利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。优点:每一次迭代学习率都有一个明确的范围,使得参数变化很平稳。
mse :mean_squared_error,均方误差
(2)多层自编码器
如果一个隐含层还不够,显然可以将自动编码器的隐含层数目进一步提高。
在这里,实现中使用了3个隐含层,而不是只有一个。 任意一个隐含层都可以作为特征表征 ,但是为了使网络对称,我们使用了最中间的网络层。
input_size = 784
hidden_size = 128
code_size = 64
x = Input(shape=(input_size,))
# Encoder
hidden_1 = Dense(hidden_size, activation='relu')(x)
h = Dense(code_size, activation='relu')(hidden_1)
# Decoder
hidden_2 = Dense(hidden_size, activation='relu')(h)
r = Dense(input_size, activation='sigmoid')(hidden_2)
autoencoder = Model(input=x, output=r)
autoencoder.compile(optimizer='adam', loss='mse')
(3)卷积自编码器
除了全连接层,自编码器也能应用到卷积层,原理是一样的,但是 要使用3D矢量(如图像)而不是展平后的一维矢量 。对输入图像进行 下采样 ,以提供较小维度的潜在表征,来迫使自编码器从压缩后的数据进行学习。
x = Input(shape=(28, 28,1))
# Encoder
conv1_1 = Conv2D(16, (3, 3), activation='relu', padding='same')(x)
pool1 = MaxPooling2D((2, 2), padding='same')(conv1_1)
conv1_2 = Conv2D(8, (3, 3), activation='relu', padding='same')(pool1)
pool2 = MaxPooling2D((2, 2), padding='same')(conv1_2)
conv1_3 = Conv2D(8, (3, 3), activation='relu', padding='same')(pool2)
h = MaxPooling2D((2, 2), padding='same')(conv1_3)
# Decoder
conv2_1 = Conv2D(8, (3, 3), activation='relu', padding='same')(h)
up1 = UpSampling2D((2, 2))(conv2_1)
conv2_2 = Conv2D(8, (3, 3), activation='relu', padding='same')(up1)
up2 = UpSampling2D((2, 2))(conv2_2)
conv2_3 = Conv2D(16, (3, 3), activation='relu')(up2)
up3 = UpSampling2D((2, 2))(conv2_3)
r = Conv2D(1, (3, 3), activation='sigmoid', padding='same')(up3)
autoencoder = Model(input=x, output=r)
autoencoder.compile(optimizer='adam', loss='mse')
conv2d :Conv2D(filters, kernel_size, strides=(1, 1), padding='valid')
filters:卷积核的数目(即输出的维度)。
kernel_size:卷积核的宽度和长度,单个整数或由两个整数构成的list/tuple。如为单个整数,则表示在各个空间维度的相同长度。
strides:卷积的步长,单个整数或由两个整数构成的list/tuple。如为单个整数,则表示在各个空间维度的相同步长。任何不为1的strides均与任何不为1的dilation_rate均不兼容。
padding:补0策略,有“valid”, “same” 两种。“valid”代表只进行有效的卷积,即对边界数据不处理。“same”代表保留边界处的卷积结果,通常会导致输出shape与输入shape相同。
MaxPooling2D :2D输入的最大池化层。MaxPooling2D(pool_size=(2, 2), strides=None, border_mode='valid')
pool_size:pool_size:长为2的整数tuple,代表在两个方向(竖直,水平)上的下采样因子,如取(2,2)将使图片在两个维度上均变为原长的一半。
strides:长为2的整数tuple,或者None,步长值。
padding:字符串,“valid”或者”same”。
UpSampling2D :上采样。UpSampling2D(size=(2, 2))
size:整数tuple,分别为行和列上采样因子。
(4)正则自编码器
除了施加一个比输入维度小的隐含层,一些其他方法也可用来约束自编码器重构,如正则自编码器。
正则自编码器不需要使用浅层的编码器和解码器以及小的编码维数来限制模型容量,而是使用损失函数来鼓励模型学习其他特性(除了将输入复制到输出)。这些特性包括稀疏表征、小导数表征、以及对噪声或输入缺失的鲁棒性。
即使模型容量大到足以学习一个无意义的恒等函数,非线性且过完备的正则自编码器仍然能够从数据中学到一些关于数据分布的有用信息。
在实际应用中,常用到两种正则自编码器,分别是稀疏自编码器和 降噪自编码器 。
(5)稀疏自编码器
一般用来学习特征,以便用于像分类这样的任务。稀疏正则化的自编码器必须反映训练数据集的独特统计特征,而不是简单地充当恒等函数。以这种方式训练,执行附带稀疏惩罚的复现任务可以得到能学习有用特征的模型。
还有一种用来约束自动编码器重构的方法,是对其损失函数施加约束。比如,可对 损失函数添加一个正则化约束 ,这样能使自编码器学习到数据的稀疏表征。
要注意,在隐含层中,我们还加入了 L1正则化,作为优化阶段中损失函数的惩罚项 。与香草自编码器相比,这样操作后的数据表征更为稀疏。
input_size = 784
hidden_size = 64
output_size = 784
x = Input(shape=(input_size,))
# Encoder
h = Dense(hidden_size, activation='relu', activity_regularizer=regularizers.l1(10e-5))(x)
#施加在输出上的L1正则项
# Decoder
r = Dense(output_size, activation='sigmoid')(h)
autoencoder = Model(input=x, output=r)
autoencoder.compile(optimizer='adam', loss='mse')
activity_regularizer :施加在输出上的正则项,为ActivityRegularizer对象
l1(l=0.01) :L1正则项,正则项通常用于对模型的训练施加某种约束,L1正则项即L1范数约束,该约束会使被约束矩阵/向量更稀疏。
(6)降噪自编码器
这里不是通过对损失函数施加惩罚项,而是 通过改变损失函数的重构误差项来学习一些有用信息 。
向训练数据加入噪声,并使自编码器学会去除这种噪声来获得没有被噪声污染过的真实输入。因此,这就迫使编码器学习提取最重要的特征并学习输入数据中更加鲁棒的表征,这也是它的泛化能力比一般编码器强的原因。
这种结构可以通过梯度下降算法来训练。
x = Input(shape=(28, 28, 1))
# Encoder
conv1_1 = Conv2D(32, (3, 3), activation='relu', padding='same')(x)
pool1 = MaxPooling2D((2, 2), padding='same')(conv1_1)
conv1_2 = Conv2D(32, (3, 3), activation='relu', padding='same')(pool1)
h = MaxPooling2D((2, 2), padding='same')(conv1_2)
# Decoder
conv2_1 = Conv2D(32, (3, 3), activation='relu', padding='same')(h)
up1 = UpSampling2D((2, 2))(conv2_1)
conv2_2 = Conv2D(32, (3, 3), activation='relu', padding='same')(up1)
up2 = UpSampling2D((2, 2))(conv2_2)
r = Conv2D(1, (3, 3), activation='sigmoid', padding='same')(up2)
autoencoder = Model(input=x, output=r)
autoencoder.compile(optimizer='adam', loss='mse')
2.程序实例:
(1)单层自编码器
from keras.layers import Input, Dense
from keras.models import Model
from keras.datasets import mnist
import numpy as np
import matplotlib.pyplot as plt
(x_train, _), (x_test, _) = mnist.load_data()
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
x_train = x_train.reshape((len(x_train), np.prod(x_train.shape[1:])))
x_test = x_test.reshape((len(x_test), np.prod(x_test.shape[1:])))
print(x_train.shape)
print(x_test.shape)
#单层自编码器
encoding_dim = 32
input_img = Input(shape=(784,))
encoded = Dense(encoding_dim, activation='relu')(input_img)
decoded = Dense(784, activation='sigmoid')(encoded)
autoencoder = Model(inputs=input_img, outputs=decoded)
encoder = Model(inputs=input_img, outputs=encoded)
encoded_input = Input(shape=(encoding_dim,))
decoder_layer = autoencoder.layers[-1]
decoder = Model(inputs=encoded_input, outputs=decoder_layer(encoded_input))
autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy')
autoencoder.fit(x_train, x_train, epochs=50, batch_size=256,
shuffle=True, validation_data=(x_test, x_test))
encoded_imgs = encoder.predict(x_test)
decoded_imgs = decoder.predict(encoded_imgs)
#输出图像
n = 10 # how many digits we will display
plt.figure(figsize=(20, 4))
for i in range(n):
ax = plt.subplot(2, n, i + 1)
plt.imshow(x_test[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
ax = plt.subplot(2, n, i + 1 + n)
plt.imshow(decoded_imgs[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
(2)卷积自编码器
from keras.layers import Input, Convolution2D, MaxPooling2D, UpSampling2D
from keras.models import Model
from keras.datasets import mnist
import numpy as np
import matplotlib.pyplot as plt
from keras.callbacks import TensorBoard
(x_train, _), (x_test, _) = mnist.load_data()
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
x_train = np.reshape(x_train, (len(x_train), 28, 28, 1))
x_test = np.reshape(x_test, (len(x_test), 28, 28, 1))
noise_factor = 0.5
x_train_noisy = x_train + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=x_train.shape)
x_test_noisy = x_test + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=x_test.shape)
x_train_noisy = np.clip(x_train_noisy, 0., 1.)
x_test_noisy = np.clip(x_test_noisy, 0., 1.)
print(x_train.shape)
print(x_test.shape)
#卷积自编码器
input_img = Input(shape=(28, 28, 1))
x = Convolution2D(16, (3, 3), activation='relu', padding='same')(input_img)
x = MaxPooling2D((2, 2), padding='same')(x)
x = Convolution2D(8, (3, 3), activation='relu', padding='same')(x)
x = MaxPooling2D((2, 2), padding='same')(x)
x = Convolution2D(8, (3, 3), activation='relu', padding='same')(x)
encoded = MaxPooling2D((2, 2), padding='same')(x)
x = Convolution2D(8, (3, 3), activation='relu', padding='same')(encoded)
x = UpSampling2D((2, 2))(x)
x = Convolution2D(8, (3, 3), activation='relu', padding='same')(x)
x = UpSampling2D((2, 2))(x)
x = Convolution2D(16, (3, 3), activation='relu')(x)
x = UpSampling2D((2, 2))(x)
decoded = Convolution2D(1, (3, 3), activation='sigmoid', padding='same')(x)
autoencoder = Model(inputs=input_img, outputs=decoded)
autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy')
# 打开一个终端并启动TensorBoard,终端中输入 tensorboard --logdir=/autoencoder
autoencoder.fit(x_train, x_train, epochs=50, batch_size=256,
shuffle=True, validation_data=(x_test, x_test),
callbacks=[TensorBoard(log_dir='autoencoder')])
decoded_imgs = autoencoder.predict(x_test)
#输出图像
n = 10 # how many digits we will display
plt.figure(figsize=(20, 4))
for i in range(n):
ax = plt.subplot(2, n, i + 1)
plt.imshow(x_test[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
ax = plt.subplot(2, n, i + 1 + n)
plt.imshow(decoded_imgs[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
(3)深度自编码器
from keras.layers import Input, Dense
from keras.models import Model
from keras.datasets import mnist
import numpy as np
import matplotlib.pyplot as plt
(x_train, _), (x_test, _) = mnist.load_data()
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
x_train = x_train.reshape((len(x_train), np.prod(x_train.shape[1:])))
x_test = x_test.reshape((len(x_test), np.prod(x_test.shape[1:])))
print(x_train.shape)
print(x_test.shape)
#深度自编码器
input_img = Input(shape=(784,))
encoded = Dense(128, activation='relu')(input_img)
encoded = Dense(64, activation='relu')(encoded)
decoded_input = Dense(32, activation='relu')(encoded)
decoded = Dense(64, activation='relu')(decoded_input)
decoded = Dense(128, activation='relu')(decoded)
decoded = Dense(784, activation='sigmoid')(encoded)
autoencoder = Model(inputs=input_img, outputs=decoded)
encoder = Model(inputs=input_img, outputs=decoded_input)
autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy')
autoencoder.fit(x_train, x_train, epochs=50, batch_size=256,
shuffle=True, validation_data=(x_test, x_test))
encoded_imgs = encoder.predict(x_test)
decoded_imgs = autoencoder.predict(x_test)
#输出图像
n = 10 # how many digits we will display
plt.figure(figsize=(20, 4))
for i in range(n):
ax = plt.subplot(2, n, i + 1)
plt.imshow(x_test[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
ax = plt.subplot(2, n, i + 1 + n)
plt.imshow(decoded_imgs[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
(4)降噪自编码器
from keras.layers import Input, Convolution2D, MaxPooling2D, UpSampling2D
from keras.models import Model
from keras.datasets import mnist
import numpy as np
import matplotlib.pyplot as plt
from keras.callbacks import TensorBoard
(x_train, _), (x_test, _) = mnist.load_data()
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
x_train = np.reshape(x_train, (len(x_train), 28, 28, 1))
x_test = np.reshape(x_test, (len(x_test), 28, 28, 1))
noise_factor = 0.5
x_train_noisy = x_train + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=x_train.shape)
x_test_noisy = x_test + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=x_test.shape)
x_train_noisy = np.clip(x_train_noisy, 0., 1.)
x_test_noisy = np.clip(x_test_noisy, 0., 1.)
print(x_train.shape)
print(x_test.shape)
input_img = Input(shape=(28, 28, 1))
x = Convolution2D(32, (3, 3), activation='relu', padding='same')(input_img)
x = MaxPooling2D((2, 2), padding='same')(x)
x = Convolution2D(32, (3, 3), activation='relu', padding='same')(x)
encoded = MaxPooling2D((2, 2), padding='same')(x)
x = Convolution2D(32, (3, 3), activation='relu', padding='same')(encoded)
x = UpSampling2D((2, 2))(x)
x = Convolution2D(32, (3, 3), activation='relu', padding='same')(x)
x = UpSampling2D((2, 2))(x)
decoded = Convolution2D(1, (3, 3), activation='sigmoid', padding='same')(x)
autoencoder = Model(inputs=input_img, outputs=decoded)
autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy')
# 打开一个终端并启动TensorBoard,终端中输入 tensorboard --logdir=/autoencoder
autoencoder.fit(x_train_noisy, x_train, epochs=10, batch_size=256,
shuffle=True, validation_data=(x_test_noisy, x_test),
callbacks=[TensorBoard(log_dir='autoencoder', write_graph=False)])
decoded_imgs = autoencoder.predict(x_test_noisy)
n = 10
plt.figure(figsize=(30, 6))
for i in range(n):
ax = plt.subplot(3, n, i + 1)
plt.imshow(x_test[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
ax = plt.subplot(3, n, i + 1 + n)
plt.imshow(x_test_noisy[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
ax = plt.subplot(3, n, i + 1 + 2*n)
plt.imshow(decoded_imgs[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
学习更多编程知识,请关注我的公众号:

-
编码器
+关注
关注
45文章
4022浏览量
143737 -
神经网络
+关注
关注
42文章
4845浏览量
108377 -
编程
+关注
关注
90文章
3725浏览量
97527 -
程序
+关注
关注
117文章
3849浏览量
85588 -
AutoEncoder
+关注
关注
0文章
2浏览量
757
发布评论请先 登录
基于变分自编码器的异常小区检测
是什么让变分自编码器成为如此成功的多媒体生成工具呢?

自编码器介绍
稀疏自编码器及TensorFlow实现详解
基于稀疏自编码器的属性网络嵌入算法SAANE
基于变分自编码器的海面舰船轨迹预测算法
自编码器基础理论与实现方法、应用综述
可实现骨骼运动重定向的通用双向循环自编码器

一种基于变分自编码器的人脸图像修复方法

自编码器神经网络应用及实验综述
基于交叉熵损失函欻的深度自编码器诊断模型
堆叠降噪自动编码器(SDAE)



评论