 Google的深度学习框架TensorFlow的优势分析
Google的深度学习框架TensorFlow的优势分析

1、Scalar、Vector、Marix、Tensor,点线面体一个都不少
我们先从点线面体的视角形象理解一下。点,标量(scalar);线,向量(vector);面,矩阵(matrix);体,张量(tensor)。我们再详细看一下他们的定义
Scalar定义:标量是只有大小、没有方向的“量”。一个具体的数值就能表征,如重量、温度、长度等。
Vector定义:向量是即有大小、又有方向的“量”。由大小和方向共同决定,如力、速度等。
Matrix定义:矩阵是一个“按照长方阵列排列”的数组,而行数与列数都等于N的矩阵称为N阶矩阵,在卷积核中我们常用3x3或5x5矩阵。
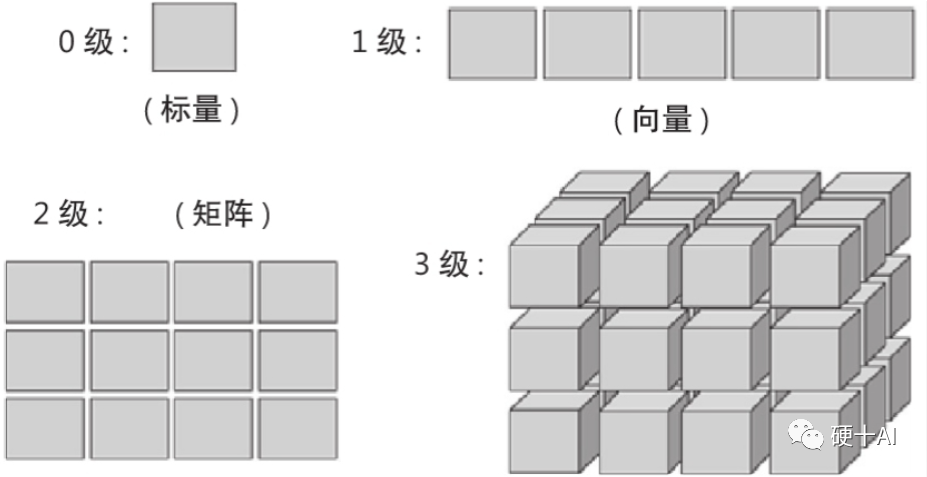
Tensor定义:张量是一个“维度很多”的数组,它创造出了更高维度的矩阵、向量,在深度学习知识域的术语中张量也可解释为数学意义的标量、向量和矩阵等的抽象。即标量定义为0级张量,向量定义为1级张量,矩阵定义为2级张量,将在三维堆叠的矩阵定义为3级张量,参考下图。
2、深度学习依赖Tensor运算,GPU解决了算力瓶颈(1)卷积网络神经中有海量的矩阵运算,包括矩阵乘法和矩阵加法 参考机器学习中的函数(4) - 全连接限制发展,卷积网络闪亮登场卷积神经网络(CNN)作为是实现深度学习的重要方法之一,整个网络第一步就是应用卷积进行特征提取,通过几轮反复后获得优质数据,达成改善数据品质的目标,我们一起复习一下卷积层工作的这两个关键步骤。
首先,进行图像转换:先把我们眼中的“图像”变成计算机眼中的“图像”。

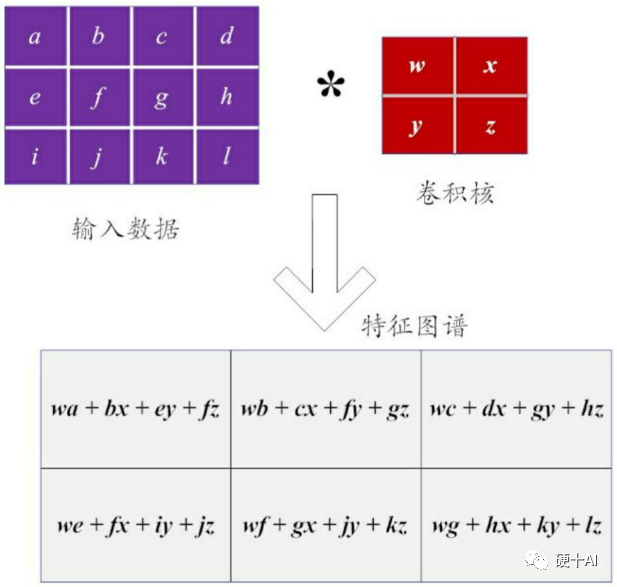
下一步,选择一个卷积核进行“滤波”:假设以一个2×2的小型矩阵作为卷积核,这样的矩阵也被称为“滤波器”。如果把卷积核分别应用到输入的图像数据矩阵上(如上图计算机眼中的猫),执行卷积运算得到这个图像的特征图谱(Feature Map)。从下图体现看到,图像的特性提取本质上就是一个线性运算,这样的卷积操作也被称为线性滤波。
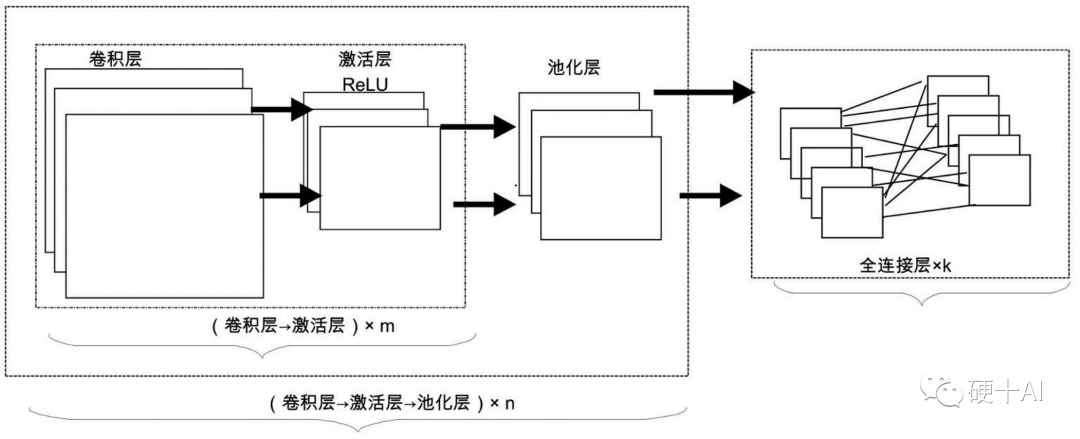
2012年,辛顿(Hinton)和他的博士生(Alex Krizhevsky)等提出了经典的Alexnet,它强化了典型CNN的架构,这个网络中卷积层更深更宽,通过大量的”卷积层->激活层->池化层”的执行过程提纯数据,因此在这个网络中有海量的矩阵运算,包括矩阵乘法和矩阵加法。
(2)应用GPU解决算力瓶颈,Tensor是最基础的运算单元
Alexnet之所以是经典中的经典,除了它强化了典型CNN的架构外,还有其它创新点,如首次在CNN中应用了ReLU激活函数、Dropout机制,最大池化(Max pooling)等技术等。还有一点特别重要,Alexnet成功使用GPU加速训练过程(还开源了CUDA代码),上世纪90年代限制Yann LeCun等人工智能科学家的计算机硬件“算力瓶颈”被逐步打开。
深度学习为什么需要GPU呢?因为只有GPU能够提供“暴力计算”能力,降低训练时间。大家都知道,GPU处理器拥有丰富的计算单元ALU,它相对于CPU处理器架构的优势就在于能执行“并行运算”,参考下图中的一个简单的矩阵乘法就是矩阵某一行的每一个数字,分别和向量的每一个数字相乘之后再相加,这就是并行运算。
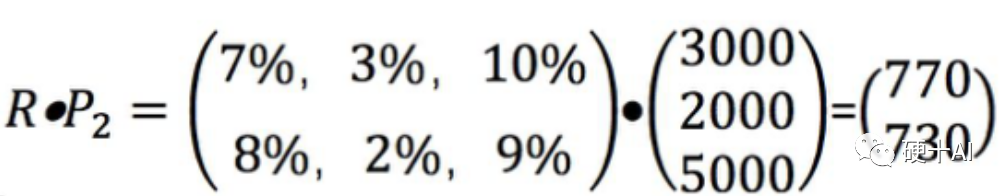
而如刚才讨论的深度学习中的运算大部分都是矩阵运算,让计算从“单个的”变成“批处理的”,充分利用GPU的资源。而Tensor是专门针对GPU来设计的,Tensor作为一个可以运行在GPU上的多维数据,加速运算速度,提升运算效率。参考深度学习靠框架,期待国产展雄风中的讨论,在一个框架中,必须有“张量对象”和“对张量的计算”作基础,TensorFlow、PyTorch等等主流框架中,张量Tensor都是最基础的运算单元。
3、提升Tensor效率,大家各显神通 现在主要的GPU厂家为了能够提高芯片在AI、HPC等应用场景下的加速能力,都在芯片计算单元的设计上花大力气,不断创新优化。比如AMD的CDNA架构中计算是通过Compute Unit来实现的,在Compute unit中就有Scalar、Vector、Matrix等不同的计算功能模块,针对不同的计算需求各司其职。Nvidia的计算是通过SM来实现的,SM中计算从Cuda Core发展到Tensor Core,针对Tensor的计算效率越来越高,到今年三月份发布的H100系列中,Tensor Core已经发展到了第四代。而Google干脆就把自己的芯片定义为TPU(Tensor processing Unit),充分发挥Tensor加速能力,其中主要的模块就是海量的矩阵乘法单元。(1)英伟达的Tensor Core 今年3月份黄教主穿着皮衣发布了H100(Hopper系列),Nvidia每一代GPU都是用一个大神的名字命名,这个系列是向Grace Hopper致敬,她被誉为计算机软件工程***、编译语言COBOL之母。她也被誉为是计算机史上第一个发现Bug的人,有这样一个故事,1947年9月9日当人们测试Mark II计算机时,它突然发生了故障。经过几个小时的检查后,工作人员发现了一只飞蛾被打死在面板F的第70号继电器中,飞蛾取出后,机器便恢复了正常。当时为Mark II计算机工作的女计算机科学家Hopper将这只飞蛾粘帖到当天的工作手册中,并在上面加了一行注释,时间是15:45。随着这个故事传开,更多的人开始使用Bug一词来指代计算机中的设计错误,而Hopper登记的那只飞蛾看作是计算机里上第一个被记录在文档中的Bug,以后debug(除虫)变成了排除故障的计算机术语。

让我们回到英伟达GPU的计算单元设计,Nvidia的9代GPU中计算单元架构演进过程如下,Tesla2.0(初代)-> Fermi(Cuda core提升算力)-> Kepler(core数量大量增长)-> Maxwell(Cuda core结构优化)-> Pascal(算力提升)-> Volta(第一代Tensor core提出,优化对深度学习的能力) -> Turning(第二代Tensor core)-> Ampere(第三代Tensor core)-> Hopper(第四代Tensor core),其中从Volta开始,每一代Tensor Core的升级都能带来算力X倍的提升。Tensor core专门为深度学习矩阵运算设计,和前几代的“全能型”的浮点运算单元CUDA core相比,Tensor core运算场景更有针对性,算力能力更强,下图就是NV一个计算单元SM中各种模块的组成,各种类型的计算模块配置齐全。
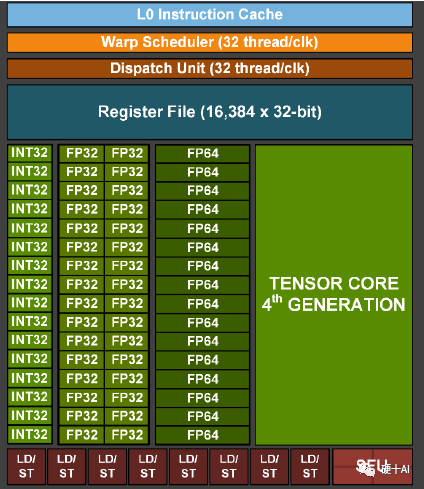
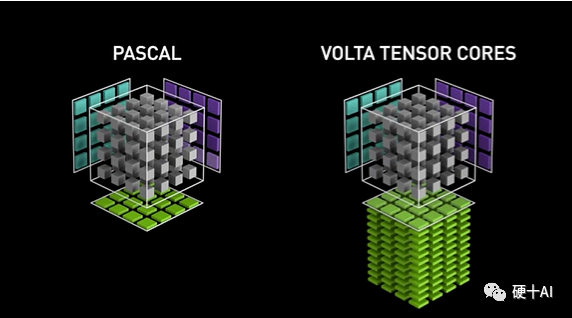
再详细讨论一下Tensor Core,Tensor Core是专为执行张量或矩阵运算而设计的专用执行单元,每个时钟执行一次矩阵乘法,包含批次的混合精度乘法操作(区别于Cuda core每个时钟执行单次混合精度的乘加操作),矩阵乘法(GEMM)运算是神经网络训练和推理的核心,Tenore Core更加高效。参考下图(蓝色和紫色为输入,绿色是计算结果,中心的灰色部分就是计算单元),第一代Tencor Core加入Votal后,以4x4 矩阵乘法运算时为例,参考英伟达白皮书上的数据,优化后与前一代的Pascal相比,用于训练的算力峰值提升了 12 倍,用于推理的算力峰值提升了6 倍。
(2)Google的TPU
2013年,Google意识到数据中心快速增长的算力需求方向,从神经网络兴起开始矩阵乘加成为重要的计算loading,同时商用GPU很贵,也为了降低成本,Google选择了撸起袖子自己干,定制了Tensor Processing Unit(TPU)专用芯片,发展到现在已经经历了4代了。
TPU V1:2014年推出,主要用于推理,第一代TPU指令很少,能够支持矩阵乘法(MatrixMultiple / Convole) 和特定的激活功能(activation)。
TPU V2:2017年推出,可用于训练,这一代芯片指令集丰富了;提升计算能力,可以支持反向传播了;内存应用了高带宽的HBM;针对集群方案提供了芯片扩展能力。
TPU V3:2018年推出,在V2的结构上进一步优化,对各个功能模块的性能都做了提升。
TPU V4:2022年推出,算力继续大幅度提升,尤其是集群能力不断优化后,TPU成为谷歌云平台上很关键的一环。
相信Google会在Tensor processing unit的路径上继续加速,对于云大厂来说,这是业务底座。
4、只有硬件是不够的,TensorFlow让Tenor流动起来 我们看到了各个厂家在硬件上的不懈努力和快速进步,当然,只有硬件是远远不够的,一个好的Deep Learning Framework才能发挥这些硬件的能力,我们还是从最出名的框架TensorFlow说起。
2011年,Google公司开发了它的第一代分布式机器学习系统DistBelief。著名计算机科学家杰夫·迪恩(Jeff Dean)和深度学习专家吴恩达(Andrew )都是这个项目的成员。通过杰夫·迪恩等人设计的DistBelief,Google可利用它自己数据中心数以万计的CPU核,建立深度神经网络。借助DistBelief,Google的语音识别正确率比之前提升了25%。除此之外,DistBelief在图像识别上也大显神威。2012年6月,《纽约时报》报道了Google通过向DistBelief提供数百万份YouTube视频,来让该系统学习猫的关键特征,DistBelief展示了他的自学习能力。DistBelief作为谷歌X-实验室的“黑科技”开始是是闭源的,Google在2015年11月,Google将它的升级版实现正式开源(遵循Apache 2.0)。而这个升级版的DistBelief,也有了一个我们熟悉的名字,它就是未来深度学习框架的主角“TensorFlow”。
TensorFlow命名源于其运行原理,即“让张量(Tensor)流动起来(Flow)”,这是深度学习处理数据的核心特征。TensorFlow显示了张量从数据流图的一端流动到另一端的整个计算过程,生动形象地描述了复杂数据结构在人工神经网络中的流动、传输、分析和处理模式。
Google的深度学习框架TensorFlow的有三大优点
形象直观:TensorFlow有一个非常直观的构架,它有一个“张量流”,用户可以借助它的工具(如TensorBoard)很容易地、可视化地看到张量流动的每一个环节。
部署简单:TensorFlow可轻松地在各种处理器上部署,进行分布式计算,为大数据分析提供计算能力的支撑。
平台兼容:TensorFlow跨平台性好,不仅可在Linux、Mac和Windows系统中运行,还可在移动终端下工作。
审核编辑:郭婷
-
Google
+关注
关注
5文章
1819浏览量
60693 -
深度学习
+关注
关注
73文章
5614浏览量
124750
原文标题:【AI】深度学习框架(1)
文章出处:【微信号:Hardware_10W,微信公众号:硬件十万个为什么】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
深度学习为什么还是无法处理边缘场景?

人工智能-Python深度学习进阶与应用技术:工程师高培解读

【智能检测】基于AI深度学习与飞拍技术的影像测量系统:实现高效精准的全自动光学检测与智能制造数据闭环
人工智能与机器学习在这些行业的深度应用
如何在TensorFlow Lite Micro中添加自定义操作符(1)
【团购】独家全套珍藏!龙哥LabVIEW视觉深度学习实战课(11大系列课程,共5000+分钟)
【团购】独家全套珍藏!龙哥LabVIEW视觉深度学习实战课程(11大系列课程,共5000+分钟)
如何深度学习机器视觉的应用场景
人工智能AI必备的5款开源软件推荐!

【新启航】深度学习在玻璃晶圆 TTV 厚度数据智能分析中的应用




评论