 看看RDMA让网络实现低时延的绝招
看看RDMA让网络实现低时延的绝招

数据中心现状
随着“新基建”将5G、人工智能、工业互联网列为新型基础领域,机器学习、智能语音交互、自动驾驶等一大批基于高性能计算的应用层出不穷,这些应用带来了数据的爆炸式增长,给数据中心的处理能力带来了很大的挑战。
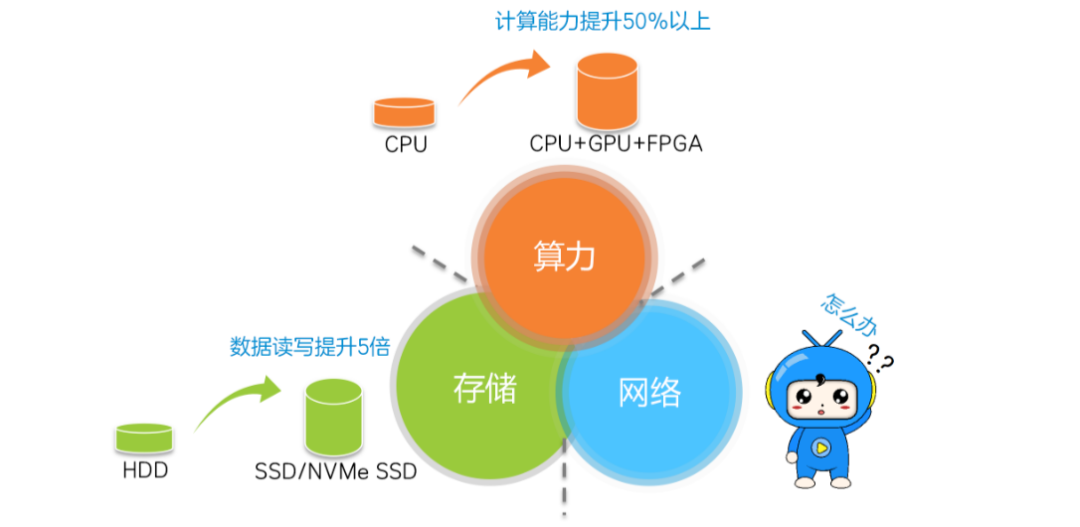
计算、存储和网络是推动数据中心发展的三驾马车。计算随着CPU、GPU和FPGA的发展,算力得到了极大的提升。存储随着闪存盘(SSD)的引入,数据存取时延已大幅降低。但是网络的发展明显滞后,传输时延高,逐渐成为了数据中心高性能的瓶颈。
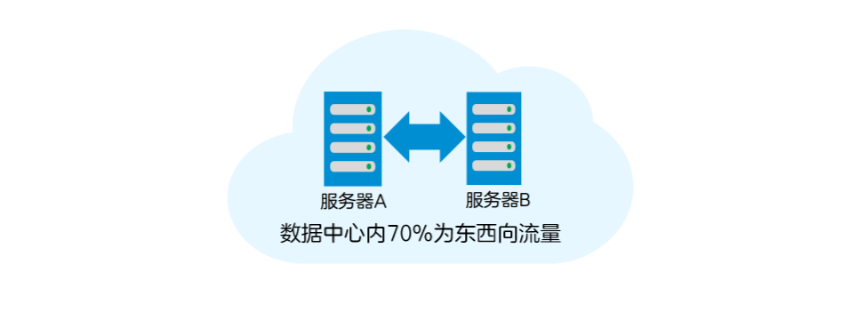
在数据中心内,70%的流量为东西向流量(服务器之间的流量),这些流量一般为数据中心进行高性能分布式并行计算时的过程数据流,通过TCP/IP网络传输。如果服务器之间的TCP/IP 传输速率提升了,数据中心的性能自然也会跟着提升。
下面我们就来看看服务器之间数据TCP/IP 传输的过程,了解下“时间都去哪了”,才好“对症下药”。
服务器间的TCP/IP传输
在数据中心,服务器A向服务器B发送数据的过程如下:
1、CPU控制数据由A的APP Buffer拷贝到操作系统Buffer。
2、CPU控制数据在操作系统(OS)Buffer中添加TCP、IP报文头。
3、添加TCP、IP报文头后的数据传送到网卡(NIC),添加以太网报文头。
4、报文由网卡发送,通过以太网络传输到服务器B网卡。
5、服务器B网卡卸载报文的以太网报文头后,将其传输到操作系统Buffer。
6、CPU控制操作系统Buffer中的报文卸载TCP、IP报文头。
7、CPU控制卸载后的数据传输到APP Buffer中。
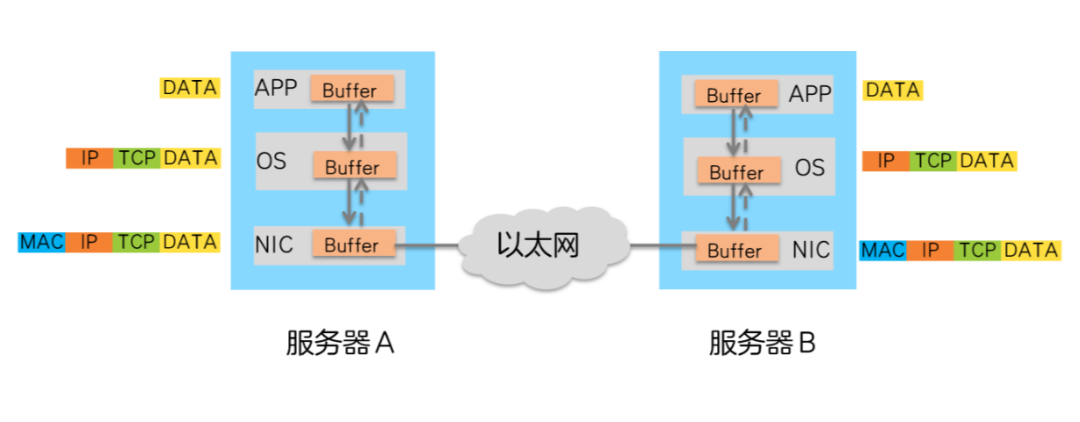
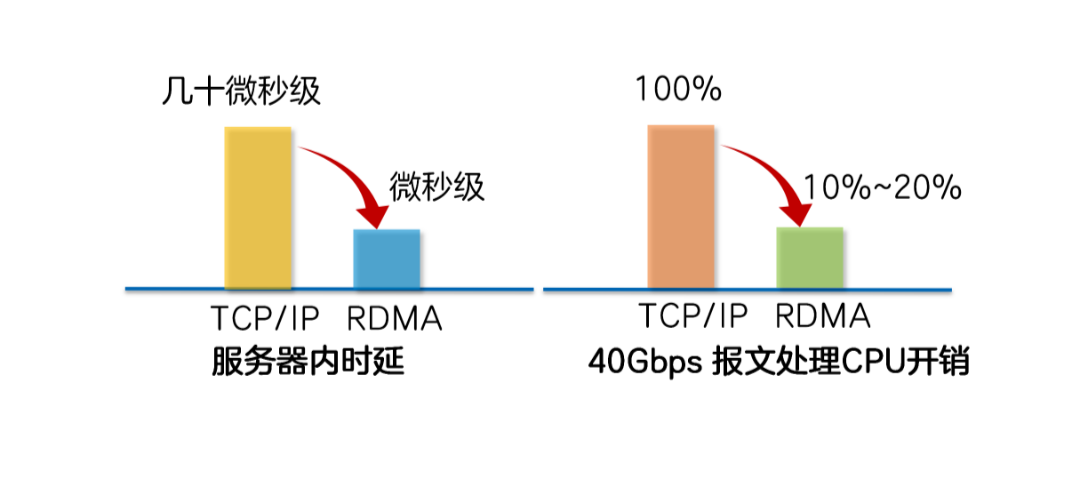
从数据传输的过程可以看出,数据在服务器的Buffer内多次拷贝,在操作系统中需要添加/卸载TCP、IP报文头,这些操作既增加了数据传输时延,又消耗了大量的CPU资源,无法很好得满足高性能计算的需求。
那么,如何构造高吞吐量、超低时延和低CPU开销的高性能数据中心网络呢?RDMA技术可以做到。
什么是RDMA
RDMA( Remote Direct Memory Access,远程直接地址访问技术 )是一种新的内存访问技术,可以让服务器直接高速读写其他服务器的内存数据,而不需要经过操作系统/CPU耗时的处理。
RDMA不算是一项新技术,已经广泛应用于高性能(HPC)科学计算中。随着数据中心高带宽、低时延的发展需求,RDMA也开始逐渐应用于某些要求数据中心具备高性能的场景中。
举个例子,2021年某大型网上商城的双十一交易额再创新高,达到5000多亿,比2020年又增长了近10%。如此巨大的交易额背后是海量的数据处理,该网上商城采用了RDMA技术来支撑高性能网络,保障了双十一的顺畅购物。
下面我们一起来看看RDMA让网络实现低时延的绝招吧。
RDMA将服务器应用数据直接由内存传输到智能网卡(固化RDMA协议),由智能网卡硬件完成RDMA传输报文封装,解放了操作系统和CPU。
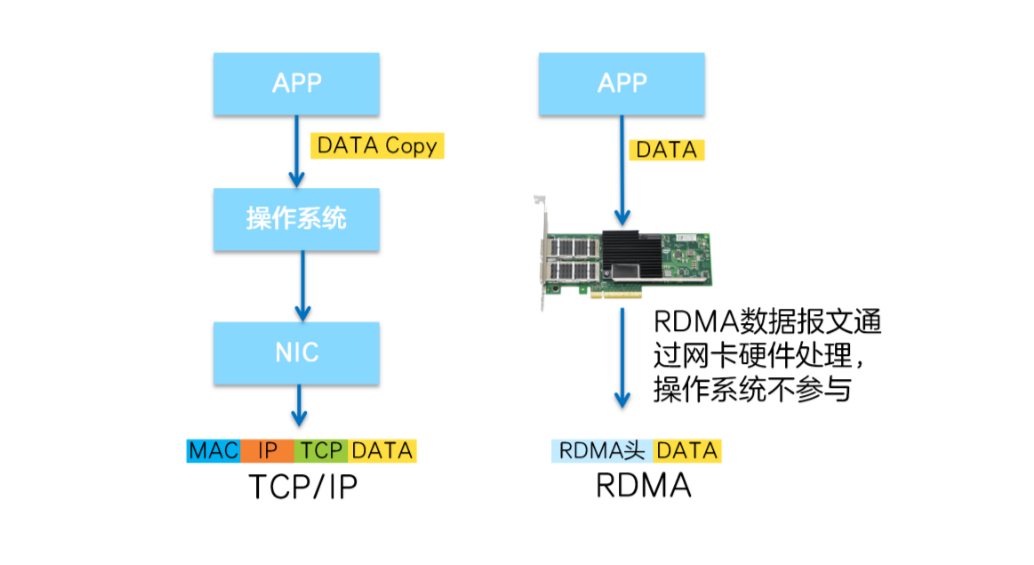
这使得RDMA具有两大优势:
Zero Copy(零拷贝):无需将数据拷贝到操作系统内核态并处理数据包头部的过程,传输延迟会显著减小。
Kernel Bypass(内核旁路)和Protocol Offload(协议卸载):不需要操作系统内核参与,数据通路中没有繁琐的处理报头逻辑,不仅会使延迟降低,而且也大大节省了CPU的资源。
三大RDMA网络
目前,大致有三类RDMA网络,分别是InfiniBand、RoCE(RDMA over Converged Ethernet,RDMA过融合以太网)和iWARP(RDMA over TCP,互联网广域RDMA协议)。RDMA最早专属于Infiniband网络架构,从硬件级别保证可靠传输,而RoCE 和 iWARP都是基于以太网的RDMA技术。
InfiniBand
InfiniBand是一种专为RDMA设计的网络。
采用Cut-Through转发模式(直通转发模式),减少转发时延。
基于Credit的流控机制(基于信用的流控机制),保证无丢包。
要求InfiniBand专用的网卡、交换机和路由器,建网成本最高。
RoCE
传输层为InfiniBand协议。
RoCE有两个版本:RoCEv1基于以太网链路层实现,只能在L2层传输;RoCEv2基于UDP承载RDMA,可部署于三层网络。
需要支持RDMA专用智能网卡,不需要专用交换机和路由器(支持ECN/PFC等技术,降低丢包率),建网成本最低。
iWARP
传输层为iWARP协议。
iWARP是以太网TCP/IP协议中TCP层实现,支持L2/L3层传输,大型组网TCP连接会消耗大量CPU,所以应用很少。
iWARP只要求网卡支持RDMA,不需要专用交换机和路由器,建网成本介于InfiniBand和RoCE之间。
Infiniband技术先进,但是价格高昂,应用局限在HPC高性能计算领域,随着RoCE和iWARPC的出现,降低了RDMA的使用成本,推动了RDMA技术普及。
在高性能存储、计算数据中心中采用这三类RDMA网络,都可以大幅度降低数据传输时延,并为应用程序提供更高的CPU资源可用性。其中InfiniBand网络为数据中心带来极致的性能,传输时延低至百纳秒,比以太网设备延时要低一个量级。
RoCE和iWARP网络为数据中心带来超高性价比,基于以太网承载RDMA,充分利用了RDMA的高性能和低CPU使用率等优势,同时网络建设成本也不高。
基于UDP协议的RoCE比基于TCP协议的iWARP性能更好,结合无损以太网的流控技术,解决了丢包敏感的问题,RoCE网络已广泛应用于各行业高性能数据中心中。
结语
随着5G、人工智能、工业互联网等新型领域的发展,RDMA技术的应用会越来越普及,RDMA将成为助力数据中心高性能的一大功臣。
审核编辑:刘清
-
FPGA
+关注
关注
1665文章
22587浏览量
641145 -
SSD
+关注
关注
21文章
3167浏览量
122754 -
RDMA
+关注
关注
0文章
103浏览量
9701
原文标题:RDMA能给数据中心带来什么
文章出处:【微信号:ztedoc,微信公众号:中兴文档】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
爱立信与软银联合打造低时延高可靠的通信网络
RDMA设计50: 如何验证网络嗅探功能?
重大突破!中科曙光scaleFabric国产原生RDMA高速网络首发

破解RDMA网络“黑盒”:轻量化会话追踪工具

高性能网络存储设计:NVMe-oF IP的实现探讨
RDMA设计6:IP架构2
RDMA设计1:开发必要性1之设计考虑
光交换机:纳秒速率、低时延与高密度端口重构AI算力网络
解析DCQCN:RDMA在数据中心网络的关键拥塞控制协议



评论