 一种新型的双流注意力增强型BERT来提高捕捉句子对中细微差异的能力
一种新型的双流注意力增强型BERT来提高捕捉句子对中细微差异的能力

1. Abstract
这篇paper主要是针对于传统的预训练语言模型捕捉细微差异能力不足的问题,像添加和删除单词、修改句子等微小的噪音就可能会导致模型预测错误
因此,该论文提出一种新型的双流注意力增强型bert(DABERT,Dual Attention Enhanced BERT ),用来提高捕捉句子对中细微差异的能力,包括两个模块,
(1)双流注意力模块,通过引入新的双通道对齐机制来测量软词匹配,来建模相似注意力和差异注意力
(2)自适应融合模块,使用注意力机制来学习差异和相似特征的聚合,并生成一个描述句对匹配细节的向量
2. Motivation
之前的研究提出的方法在区分字面上相似但语义不同的句子对方面表现不佳,这可能是因为self-attention机制是利用上下文来理解token的语义,但这样忽略了句子对之间的语义差异,因此为了更好的整合句子对之间的更加细粒度的差别,将difference向量和affinity向量放在一起建模
difference vector为差异向量
affinity vector为相似向量,即普通的attention得到的向量表示

字面意义相似但语义不同的例句,S1和S2是一对句子
2.1 Two questions
有了上面的思路之后,就自然而然的产生了两个关键问题
Q1:如何使普通的注意力机制能够对句子对之间细微差别的语义进行建模?
Vanilla attention,或称为affinity attention,并不太关注句子对之间的细微差别,要提升这个能力,一个直观的解决方案是在表示向量之间做减法,以捕获它们的语义差异。论文中提出了一个双注意力模块,包括差异注意力和普通注意力。差异注意力使用基于减法的cross-attention来聚合词和短语层面的交互差异。同时,为了充分利用差异信息,使用双通道将差异信息注入Transformer中的multi-head attention,以获得描述相似和差异的语义表示。
Q2:如何将两类语义表示融合为一个统一的表示?
通过额外的结构对两种信号进行硬融合可能会破坏预训练模型的表示能力,如何将这些信息更柔和地注入到预训练的模型中仍然是一个难题。论文中提出了一个自适应融合模块,使用额外的注意力来学习差异和相似特征,以产生描述句子匹配细节的向量。
它首先通过不同的注意力将两个信号相互对齐以捕获语义交互,然后使用门控来自适应地融合差异特征。这些生成的向量通过另一个 fuse-gate 进一步缩放,以减少差异信息对预训练模型的损害,输出的最终向量可以更好地描述句子对的匹配细节。
3. Main contributions
明确地对句子对之间的细粒度差异语义进行建模,进而有效地提升句子语义匹配任务的效果,并且提出了一种基于BERT的新型双流注意力增强机制
提出的DABERT模型使用双流注意力来分别关注句子对中的相似性和差异性特征,并采用soft-integrated的调节机制来自适应地聚合这两个特征,使得生成的向量可以更好地描述句子对的匹配细节
4. Semantic Sentence Matching
先介绍一下句子语义匹配任务(SSM, Semantic Sentence Matching),其目标是比较两个句子并识别它们的语义关系。
在转述识别中,SSM用来确定两个句子是否是转述关系;在自然语言推理任务中,SSM用来判断一个假设句是否可以从一个前提句中推断出来;在QA任务中,SSM被用来评估问题-答案之间的相关性,并对所有候选回答进行排序。
处理句子语义匹配任务一般可分为两个主要的研究方向:
利用句子编码器将句子转换为潜在空间中的低维向量,并应用参数化的函数来学习二者之间的匹配分数
采用注意力机制来计算两个句子token之间的分数,然后将匹配分数汇总,做出句子级的决策
还有通过注入知识来解决该问题的尝试,如SemBERT,UER-BERT,Syntax-BERT等
5. Model architecture
DABERT是对原始 Transformer结构的修改,其结构如下所示
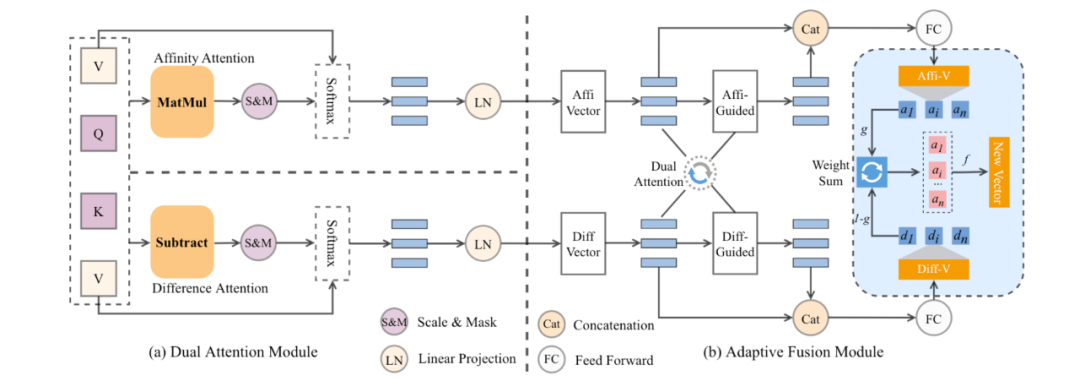
The overall architecture of Dual Attention Enhanced BERT (DABERT). The left side is the Dual attention module, and the right side is the Adaptive Fusion module
在这个新结构中包括两个子模块
(1)双注意力模块,它在多头注意力中使用双通道机制来匹配两个句子之间的单词,每个通道使用不同的注意力头,分别计算affinity 和 difference分数,得到两个表征,分别测量相似 和 差异信息。
(2)自适应融合模块,用于融合双流注意力得到的表征,首先使用guide-attention来对齐两个信号,然后使用多个门控模块来融合这两个信号,最终输出一个包括更细粒度的匹配细节的向量
5.1 Dual Attention Module
在这个模块中,使用两个不同的注意力函数,即常规注意力和差异注意力,来比较两个句子之间向量的相似度和差异度。双重注意力模块的输入是的三要素,其中是潜在维度,是序列长度。
双流注意力模块通过两个独立的注意力机制计算K、Q和V之间的潜在关系,以测量它们的相似度和差异度。因此该模块会产生两组注意力表征,后续由自适应融合模块处理。
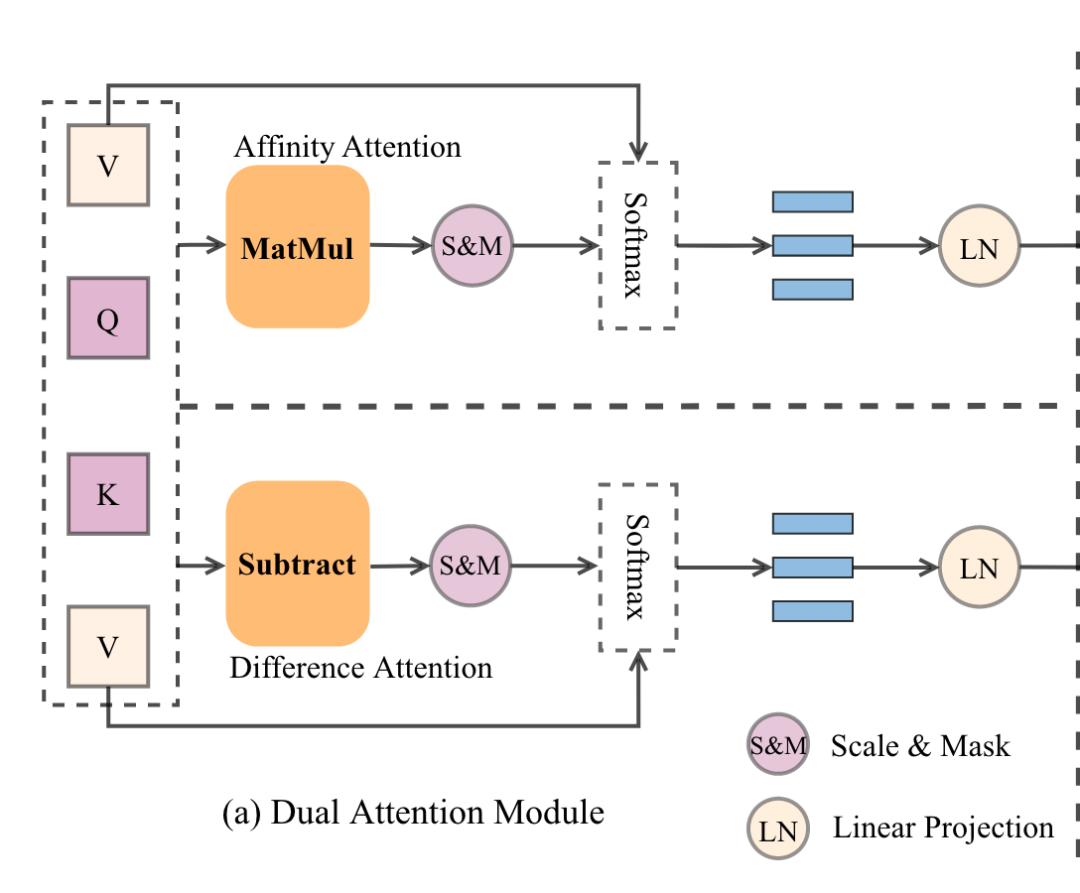
双流注意力模块
5.1.1 Affinity Attention
相似注意力是双流注意力的一部分,它是标准的点积注意力,按照Transformer的默认操作进行计算。该模块的输入包括query和维度为的key,以及维度为的value。
计算query与所有key的点积,将每个点积除以,并使用softmax函数来获得数值的权重,将输出的相似向量表示为
其中,表示描述由Transformer原始注意力模块生成的相似表达的向量。
5.1.2 Difference Attention
双流注意力的第二部分是差异注意力模块,用于捕捉和聚合句子对之间的差异信息,采用基于减法的cross-attention机制,它允许模型通过element-wise的减法来捕获句子对之间的差别,如
其中,是输入序列长度,
表示差异注意力模块所产生的表示。是一个Mask操作。相似注意力和差异注意力都被用来建模句子对之间的语义关系,并分别从相似和差异的角度获得相同维度的表征,这种双通道机制可以获得描述句子匹配的更详细的表征。
5.2 Adaptive Fusion Module
使用自适应融合模块来融合相似表示A和差异表示D,因为直接融合(即平均嵌入向量)可能会损害预训练模型的原始表示能力
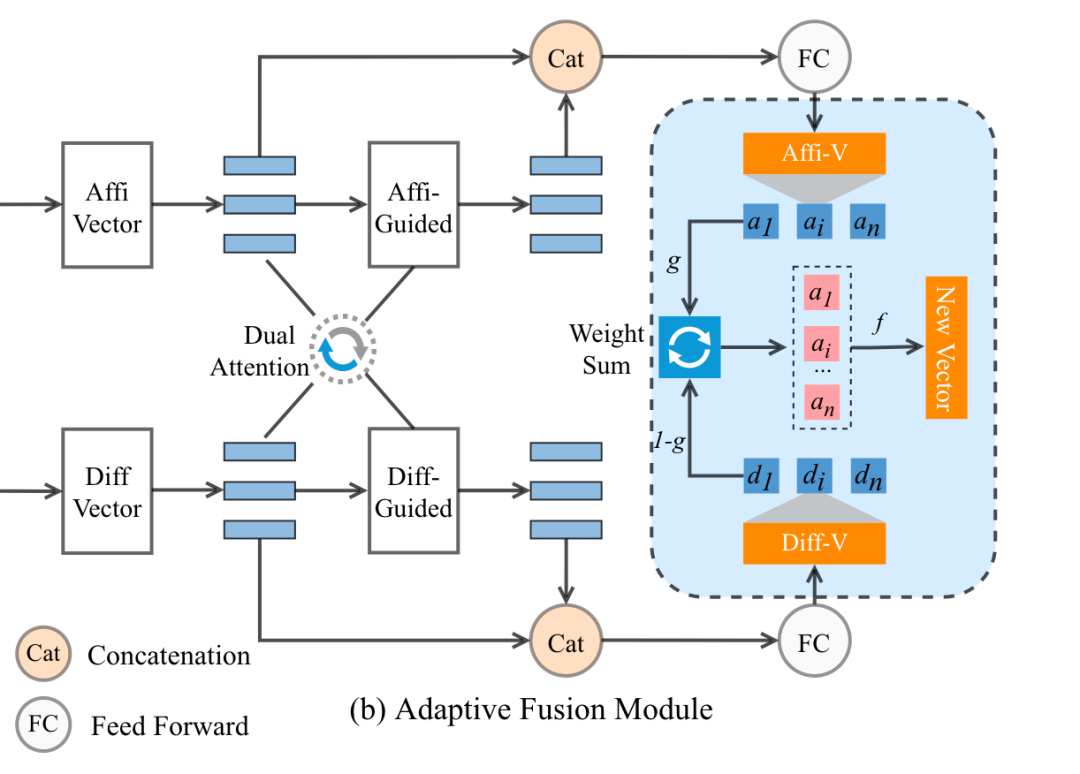
自适应融合模块
融合过程包括三个步骤
通过affinity-guided attention和difference-guided attention,灵活地与这两个表示进行互动和对齐
采用多个门控模块来选择性地提取交互语义信息
为了减轻差异表示对预训练模型的损害,我们利用filter gates来自适应地过滤掉噪声信息,最后生成更好描述句子匹配细节的向量


6. Experimental and Results analysis
6.1 Datasets
作者主要做了语义匹配和模型鲁棒性的实验,用到的数据集分别如下
Semantic Matching
GLUE的6个句对数据集:MRPC、QQP、STS-B、MNLI、RTE、QNLI
其他4个流行的数据集:SNLI、SICK、TwitterURL、Scitail
Robustness Test
利用TextFlint对多个数据集(Quora、SNLI、MNLI-m/mm)进行转化,包括特定任务的转化(SwapAnt、NumWord、AddSent)和一般转化(InsertAdv、Appendlrr、AddPunc、BackTrans、TwitterType、SwapNamedEnt、SwapSyn-WordNet)
TextFlint是一个自然语言处理模型的鲁棒性评估平台。它包括80多种模式来变形数据,包括插入标点符号,改变文本中的数字,替换同义词,修改副词,删除单词等,可以有效地评估模型的鲁棒性和泛化性
6.2 Baselines
BERT、SemBERT、SyntaxBERT、URBERT和其他多个PLM
此外,还选择了几个没有预训练的竞争模型作为基线,如ESIM,Transformer等
在鲁棒性实验中,比较了多个预训练模型和SemBERT,URBERT、Syntax-BERT
6.3 Results analysis
更具体的实验结果这里就不罗列了,只看一下论文作者对于一些结果的解释
模型表现优于SyntaxBERT,这是之前利用外部知识的最佳模型,基于BERT-large的平均相对改进为0.86%。在QQP数据集上,DABERT的准确性比SyntaxBERT明显提高了2.4%。造成这种结果的主要原因有两个
使用双流注意力来增强DABERT捕捉差异特征的能力,这使得DABERT能够获得更精细的交互匹配特征
对于外部结构引入的潜在噪声问题,自适应融合模块可以有选择地过滤掉不合适的信息,以抑制噪声的传播,而以前的工作似乎没有对这个问题给予足够的关注
SyntaxBERT仍在几个数据集上取得了稍好的准确性,作者认为这是句法和依存知识的内在关联性的结果
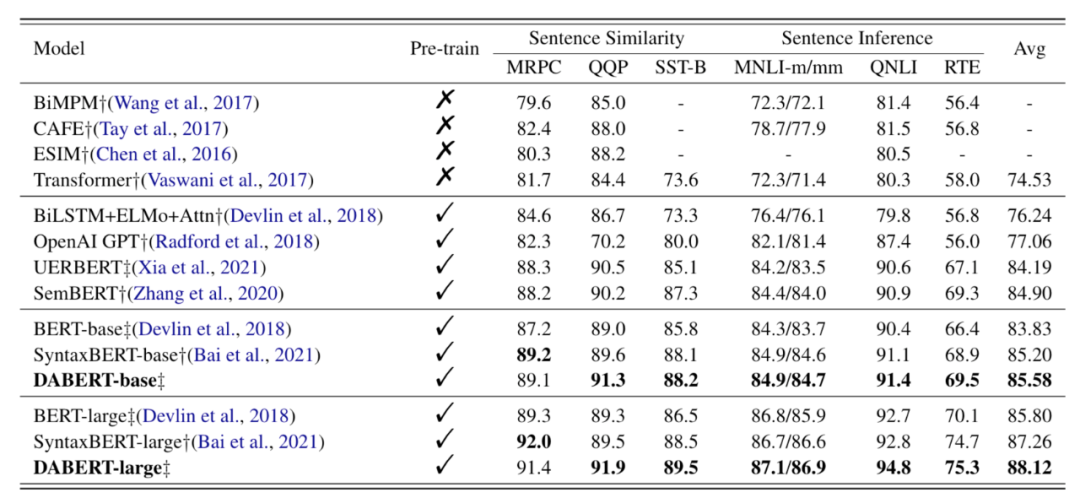
The performance comparison of DABERT with other methods. Accuracy × 100 on 6 GLUE datasets. Methods with † indicate the results from their papers, while methods with ‡ indicate our implementation
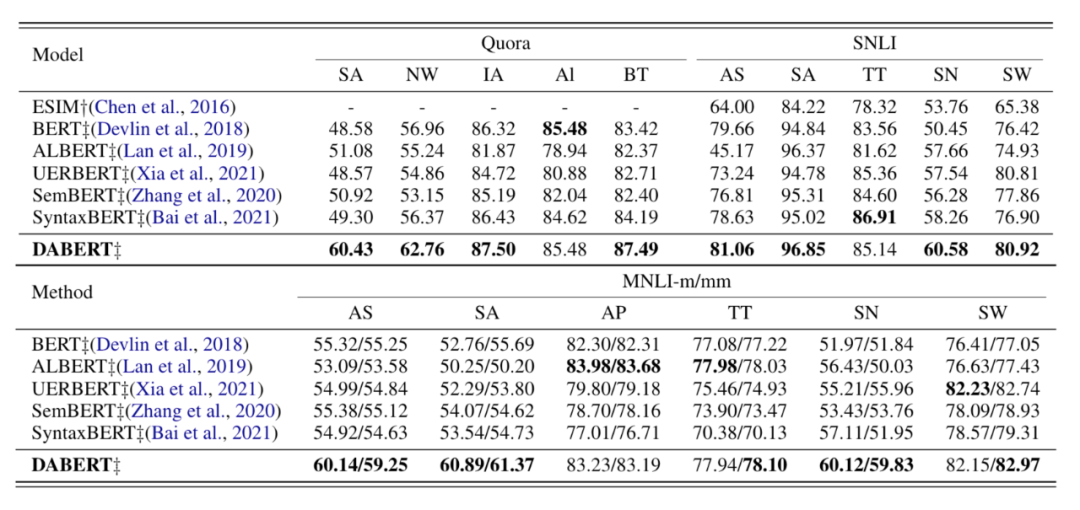
Robustness Test Performance
下表列出了DABERT和六个基线模型在三个数据集上的准确性。可以观察到,
SwapAnt的性能表现最差,而DABERT在SwapAnt(QQP)上优于最佳模型SemBert近10%,这表明DABERT比基线模型更能处理反义词引起的语义矛盾
NumWord转换,BERT模型性能下降到56.96%,而DABERT优于BERT近6%,因为它要求模型捕捉细微的数字差异,以进行正确的语言推理
SwapSyn变换,UERBERT明显优于其他基线模型,因为它明确使用同义词相似性矩阵来校准注意力分布,而DABERT在不添加外部知识的情况下仍能达到与UERBERT相当的性能
TwitterType和AddPunc,注入句法树的SyntaxBERT性能明显下降,这可能是因为将文本转换为twitter类型或添加标点符号破坏了句子的正常句法结构,而DABERT在这两种转换中仍然取得了不错的的性能
在其他情况下,DABERT也取得了更好的性能,因为它捕捉到了句子对的细微差别。同时,ESIM的表现最差,结果反映出预训练机制得益于丰富的外部资源,并提供了比从头训练的模型更好的泛化能力。
而改进后的预训练模型SyntaxBERT比原来的BERT模型表现更好,这反映出足够的预训练语料和合适的外部知识融合策略有助于提高模型的泛化性能。
Robustness Test Performance
6.4 Ablation Study
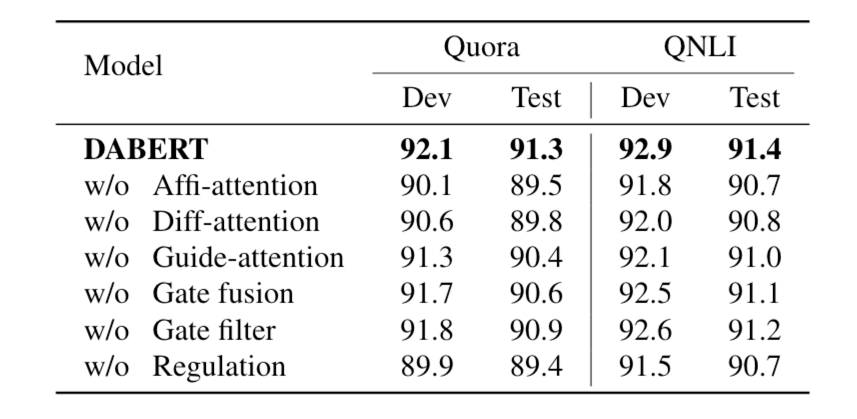
作者在QQP和QNLI数据集上进行了基于BERT的消融实验
去掉相似注意力后,模型在两个数据集上的性能分别下降了1.8%和0.7%。相似注意力可以捕捉到词对之间的动态对齐关系,这对SSM任务至关重要
去掉差异注意力后,两个数据集的性能分别下降了1.5%和0.6%。差异信息可以进一步描述词与词之间的相互作用,并且可以为预训练的模型提供更精细的比较信息,从而使模型获得更好的表现
上述实验表明,去除子模块后,性能急剧下降,这表明了双流注意力模块内部组件的有效性
自适应融合模块中,作者也进行了几次实验来验证相似和差异向量的融合效果。在QQP数据集上,
删除引导注意力模块(guide attention),性能下降到90.4%。因为引导注意力可以捕捉到两种表示之间的相互作用,这种相互作用信息对于融合两个不同的信息至关重要
去掉fusion gate后,只通过简单的平均来整合两个表示,准确率下降到91.4%,表明根据不同的权重动态地合并相似和差异向量可以提高模型的性能
移出filter gate后,准确率下降了0.4%,表明没有filter gate,模型抑制噪声的能力被削弱了
用简单的平均代替整体聚合和调节模块,性能急剧下降到89.4%。虽然差异信息对判断句对关系至关重要,但将差异信息硬性整合到PLM中会破坏其预存的知识,而更柔和的聚合和处理可以更好地利用差异信息
总的来说,通过各个部分的有效组合,DABERT可以自适应地将差异特征融合到预训练的模型中,并利用其强大的上下文表示法来更好地推断语义
Results of component ablation experiment
6.5 Case Study
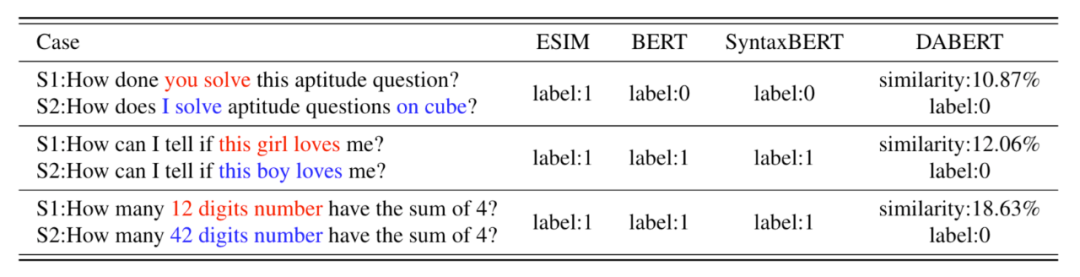
为了直观地了解DABERT的工作情况,作者使用下表中的三个案例进行定性分析。
在第一种情况下,非预训练的语言模型ESIM很难捕捉到由差异词引起的语义冲突。因此,ESIM在案例1中给出了错误的预测结果。
BERT在案例1中可以借助于上下文来识别语义差异,但在案例3中,BERT不能捕捉到数字 "12 "和 "24 "之间的差异,并给出了错误的预测。
SyntaxBERT通过引入句法树来加强文本理解,由于案例2和案例3具有相同的句法结构,SyntaxBERT也给出了错误的预测
总的来说,这几种不同的情况,上述三种模型都有其处理不了的原因,反观DABERT在上述所有的情况下都做出了正确的预测。
由于DABERT通过差异注意力明确地关注句子对中的不同部分,并在自适应融合模块中自适应地聚合相似和差异信息,它可以识别由句子对内的细微差异引起的语义差异
Example sentence pairs, Red and Blue are difference phrases in sentence pair.
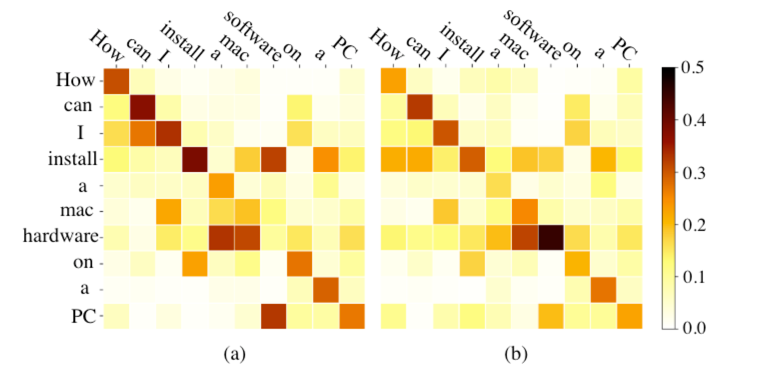
Attention Distribution
为了验证基于减法的注意力对差异信息的融合效果,作者还在下图中展示了BERT和DABERT的权重分布并进行比较。
可以看出,双流注意力得到的注意力矩阵分布变得更加合理,尤其是 "hardware "和 "software"之间的注意力权重明显增加,这表明DABERT给句子对的差异之处给予了更多的关注
Distribution of BERT (a) and DABERT (b)
7. Conclusion
总结一下,这篇论文是通过改变传统Transformer中的注意力结构来达到优化注意力权重分布的效果,进而让模型可以将句子对之间的向量表示有差别的地方凸显出来,而相似的地方更加靠近。
在保持原始预训练语言模型不被影响到情况下,增强模型的表示能力,并且做了大量的实验来证明,比之前的工作得到了更好的效果。
审核编辑:刘清
-
ssm
+关注
关注
0文章
21浏览量
12753 -
MRPC
+关注
关注
0文章
2浏览量
1421
原文标题:清华&美团提出:DABERT — 双流注意力增强型BERT,自适应融合提升模型效果 | COLING'22
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
Bondout、增强型Hooks芯片和标准产品芯片
DeepMind为视觉问题回答提出了一种新的硬注意力机制
北大研究者创建了一种注意力生成对抗网络
一种通过引入硬注意力机制来引导学习视觉回答任务的研究
深度分析NLP中的注意力机制
注意力机制的诞生、方法及几种常见模型
一种自监督同变注意力机制,利用自监督方法来弥补监督信号差异
一种全新的多阶段注意力答案选取模型

一种注意力增强的自然语言推理模型aESIM

一种上下文感知与层级注意力网络的文档分类方法

计算机视觉中的注意力机制

一种新的深度注意力算法
一种基于因果路径的层次图卷积注意力网络




评论