 AI、游戏与通用计算,国产GPU的定位
AI、游戏与通用计算,国产GPU的定位

电子发烧友网报道(文/周凯扬)从去年国产GPU开始陆续冒尖后,今年各大厂商的动作明显更大了一些,新品频繁面世。但从这些新品的规格和技术来看,其实每家公司对于自己GPU产品的定位都是不同的,我们就选几家国产GPU厂商来分析一下他们的产品定位以及未来技术趋势。
摩尔线程
作为近期刚发布了新品的国产GPU厂商,摩尔线程确实收获了不少关注,他们最新的显卡MTT S80也一度成了热点话题。MTT S80作为一张游戏显卡,搭载了MT-春晓芯片核心,功耗最高250W,单精度浮点算力高达14.4TFLOPS。
不仅如此,MTT S80也是业内首个PCIe 5.0的显卡,支持双向128GB/s的传输带宽。更重要的是,哪怕标榜的是游戏显卡,MTT S80依然支持3D图形渲染、智能多媒体、物理仿真及科学计算和AI计算加速的全功能应用。

MTT S3000 / 摩尔线程
除了MTT S80以外,春晓这一芯片也为摩尔线程带来了面向服务器GPU市场的新产品,MTT S3000。单从芯片规格上来看,MTT S3000与MTT S80都用的是完整的MT-春晓芯片,都内置了4096个MUSA流处理单元,但前者将主频提高到了1.9GHz,FP32也因此提升到了15.2TFLOPS。
为了让MTT S3000更适用于服务器市场,摩尔线程也将其显存提升至了32GB,并增加了对虚拟化的支持,可对GPU弹性切分,MTT S3000也从MTT S80的主动散热改为了被动散热。
到了AI上,摩尔线程的MUSA架构和软件栈为MTT S3000提供了训推一体的支持。除了训练支持TensorFlow、PyTorch、飞桨等常见框架外,摩尔线程还在推理上打造了自研AI推理引擎TensorX,甚至推出了兼容CUDA源码的方案。
可以看出,摩尔线程不仅已经在游戏GPU市场有了弥足珍贵的进展,同样想在服务器市场实现突破,甚至是通过兼容CUDA来吸引更多的客户,这其实也是英伟达这样的GPU巨头主攻的两大方向。但兼容或对标CUDA一法,AMD、英特尔这样的国际大厂也都在推进,却也都是各自为战,考虑到其中涉及的开发投入和难度之大,或许在软件生态上走合作之路会更适合。
芯动科技
在使用GPU这类产品的过程中,支持不同的图形与计算API对于开发者来说尤为重要。而芯动科技的风华GPU在这API上的支持尤为亮眼,目前已经完美支持到OpenGL 4.3、OpenGL ES 3.2、Vulkan 1.2和OpenCL 3.0,这也为风华GPU的开发生态奠定了基础。
虽然其产品性能本身已经足够亮眼,但风华GPU真正最大的优势在于芯动自研高性能接口IP上,包括高带宽内存(GDDR6x、HBM3)、高速SerDes(PCIe 5.0、CXL 2.0)和高清多媒体(HDMI 2.1、eDP 1.4)等等,同时这些IP也实现了对先进工艺的覆盖。而且芯动科技已经在最近推出了跨工艺、跨封装的Chiplet互联解决方案Innolink Chiplet,同时兼容UCIe Chiplet。
对于高性能GPU来说,如果说核心IP决定了性能上限的话,那么这些接口IP就决定了GPU能发挥出多少实力,以及是否能在未来的服务器市场大放异彩。目前看来,风华2号的定位是一款低功耗的GPU产品,更适合用于智能座舱之类的应用中,而风华1号则是面向服务器市场,尤其是像云游戏、云手机之类的场景。
可从规格来看,这两款一年以内发布的产品其实都还没有用到PCIe 5.0之类的新接口技术。芯动科技已经在8月公开表示,风华3号也已经基本完成研发,还支持光线追踪技术,据了解该产品和风华1号一样也是面向服务器/数据中心市场的,但或许还是会侧重在云游戏等商用场景上,相信我们会在未来的发布上看到风华3号更强大的性能表现。
壁仞科技
虽然壁仞科技最近遇上了一些麻烦,但不可否认的是,其BR100系列通用GPU芯片确实在性能上达到了极高的水准。与上面提到的两个GPU不同,BR100虽然是通用计算GPU,但明显更适合于AI和科学计算这样的高性能计算场景,所以BR100并没有去做DirectX和Vulkan这样的图形API支持。
这点从BR100的芯片设计上也能看出,单个BR100由16个流处理簇构成,每个都采用了16个执行单元的设计,而每个执行单元包含16个流处理核心(V-core)和一个向量引擎(T-Core)。V-Core作为SIMT处理器,支持到FP32、FP16、INT32、INT16,用于通用计算。
而T-core在SPC级别的2.5D GEMM架构下,可以极大加速常见的AI运算,诸如MMA矩阵乘加和卷积等。T-Core不仅支持FP32、TF32这些主流数据精度外,还原创定义了TF32+数据精度,相较TF32在实现更高精度的同时,也提高了吞吐性能。
从软件平台上看,壁仞科技的BIRENSUPA不仅支持PyTorch之类的主流框架,也有壁仞自研的推理加速引擎。从BIRENSUPA平台框图中的应用定位来看,壁仞科技的主要发力方向看来还是多媒体、自动驾驶和推荐系统等重AI的场景。

壁仞100P OAM模组 / 壁仞科技
壁仞科技也是在一众国产PCIe产品中,唯一推出了OAM模组的厂商,壁仞科技也和浪潮合作推出了“海玄”这种OAM服务器,实现了8PFLLOPS的峰值算力。不过也正是因为实现了如此高的性能,似乎招致了一些恶意阻碍,但这也恰恰说明了他们走的方向是对的,如果他们能走出这一困境的话,无疑能在服务器市场大有作为。
摩尔线程
作为近期刚发布了新品的国产GPU厂商,摩尔线程确实收获了不少关注,他们最新的显卡MTT S80也一度成了热点话题。MTT S80作为一张游戏显卡,搭载了MT-春晓芯片核心,功耗最高250W,单精度浮点算力高达14.4TFLOPS。
不仅如此,MTT S80也是业内首个PCIe 5.0的显卡,支持双向128GB/s的传输带宽。更重要的是,哪怕标榜的是游戏显卡,MTT S80依然支持3D图形渲染、智能多媒体、物理仿真及科学计算和AI计算加速的全功能应用。
MTT S3000 / 摩尔线程
除了MTT S80以外,春晓这一芯片也为摩尔线程带来了面向服务器GPU市场的新产品,MTT S3000。单从芯片规格上来看,MTT S3000与MTT S80都用的是完整的MT-春晓芯片,都内置了4096个MUSA流处理单元,但前者将主频提高到了1.9GHz,FP32也因此提升到了15.2TFLOPS。
为了让MTT S3000更适用于服务器市场,摩尔线程也将其显存提升至了32GB,并增加了对虚拟化的支持,可对GPU弹性切分,MTT S3000也从MTT S80的主动散热改为了被动散热。
到了AI上,摩尔线程的MUSA架构和软件栈为MTT S3000提供了训推一体的支持。除了训练支持TensorFlow、PyTorch、飞桨等常见框架外,摩尔线程还在推理上打造了自研AI推理引擎TensorX,甚至推出了兼容CUDA源码的方案。
可以看出,摩尔线程不仅已经在游戏GPU市场有了弥足珍贵的进展,同样想在服务器市场实现突破,甚至是通过兼容CUDA来吸引更多的客户,这其实也是英伟达这样的GPU巨头主攻的两大方向。但兼容或对标CUDA一法,AMD、英特尔这样的国际大厂也都在推进,却也都是各自为战,考虑到其中涉及的开发投入和难度之大,或许在软件生态上走合作之路会更适合。
芯动科技
在使用GPU这类产品的过程中,支持不同的图形与计算API对于开发者来说尤为重要。而芯动科技的风华GPU在这API上的支持尤为亮眼,目前已经完美支持到OpenGL 4.3、OpenGL ES 3.2、Vulkan 1.2和OpenCL 3.0,这也为风华GPU的开发生态奠定了基础。

虽然其产品性能本身已经足够亮眼,但风华GPU真正最大的优势在于芯动自研高性能接口IP上,包括高带宽内存(GDDR6x、HBM3)、高速SerDes(PCIe 5.0、CXL 2.0)和高清多媒体(HDMI 2.1、eDP 1.4)等等,同时这些IP也实现了对先进工艺的覆盖。而且芯动科技已经在最近推出了跨工艺、跨封装的Chiplet互联解决方案Innolink Chiplet,同时兼容UCIe Chiplet。
对于高性能GPU来说,如果说核心IP决定了性能上限的话,那么这些接口IP就决定了GPU能发挥出多少实力,以及是否能在未来的服务器市场大放异彩。目前看来,风华2号的定位是一款低功耗的GPU产品,更适合用于智能座舱之类的应用中,而风华1号则是面向服务器市场,尤其是像云游戏、云手机之类的场景。
可从规格来看,这两款一年以内发布的产品其实都还没有用到PCIe 5.0之类的新接口技术。芯动科技已经在8月公开表示,风华3号也已经基本完成研发,还支持光线追踪技术,据了解该产品和风华1号一样也是面向服务器/数据中心市场的,但或许还是会侧重在云游戏等商用场景上,相信我们会在未来的发布上看到风华3号更强大的性能表现。
壁仞科技
虽然壁仞科技最近遇上了一些麻烦,但不可否认的是,其BR100系列通用GPU芯片确实在性能上达到了极高的水准。与上面提到的两个GPU不同,BR100虽然是通用计算GPU,但明显更适合于AI和科学计算这样的高性能计算场景,所以BR100并没有去做DirectX和Vulkan这样的图形API支持。
这点从BR100的芯片设计上也能看出,单个BR100由16个流处理簇构成,每个都采用了16个执行单元的设计,而每个执行单元包含16个流处理核心(V-core)和一个向量引擎(T-Core)。V-Core作为SIMT处理器,支持到FP32、FP16、INT32、INT16,用于通用计算。
而T-core在SPC级别的2.5D GEMM架构下,可以极大加速常见的AI运算,诸如MMA矩阵乘加和卷积等。T-Core不仅支持FP32、TF32这些主流数据精度外,还原创定义了TF32+数据精度,相较TF32在实现更高精度的同时,也提高了吞吐性能。
从软件平台上看,壁仞科技的BIRENSUPA不仅支持PyTorch之类的主流框架,也有壁仞自研的推理加速引擎。从BIRENSUPA平台框图中的应用定位来看,壁仞科技的主要发力方向看来还是多媒体、自动驾驶和推荐系统等重AI的场景。
壁仞100P OAM模组 / 壁仞科技
壁仞科技也是在一众国产PCIe产品中,唯一推出了OAM模组的厂商,壁仞科技也和浪潮合作推出了“海玄”这种OAM服务器,实现了8PFLLOPS的峰值算力。不过也正是因为实现了如此高的性能,似乎招致了一些恶意阻碍,但这也恰恰说明了他们走的方向是对的,如果他们能走出这一困境的话,无疑能在服务器市场大有作为。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
gpu
+关注
关注
28文章
5099浏览量
134431 -
AI
+关注
关注
89文章
38085浏览量
296372
发布评论请先 登录
相关推荐
热点推荐
Imagination中国区董事长兼亚太区总裁白农:通用计算GPU驱动端侧AI发展
,通用计算GPU正成为驱动端侧AI发展的重要引擎。当前,端侧AI算力迎来爆发式增长,端侧芯片需承载感知数据处理、图像渲染、AI大模型

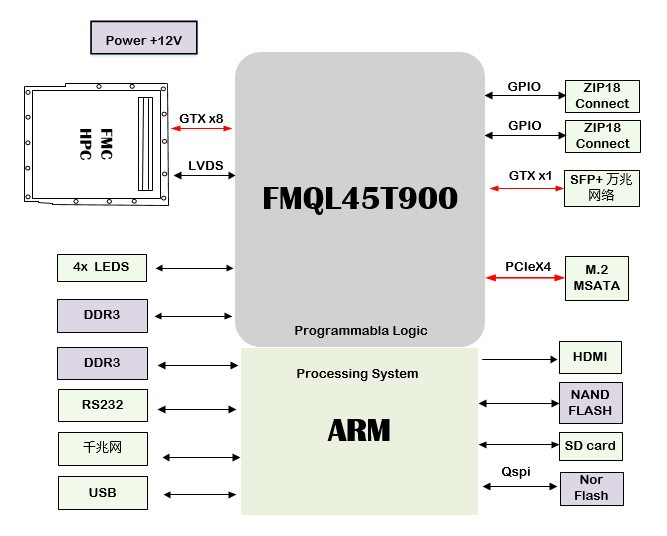
国产化FMC接口通用计算平台设计原理图:2367-基于FMQL45T900 FMC接口通用计算平台
, 数字信号处理卡, FMC接口通用计算平台, FMQL45T900I, 前端信号处理
GPU架构深度解析
GPU架构深度解析从图形处理到通用计算的进化之路图形处理单元(GPU),作为现代计算机中不可或缺的一部分,已经从最初的图形渲染专用处理器,发展成为强大的并行
Imagination与澎峰科技携手推动GPU+AI解决方案,共拓计算生态
的深度融合展开合作。双方将结合 Imagination 领先的 GPU IP 技术与澎峰科技在 AI 模型压缩与性能优化方面的软硬协同能力,共同开拓面向 AI 行业应用的计算解决方案
发表于 05-21 09:40
•1107次阅读
Imagination与澎峰科技携手推动GPU+AI解决方案,共拓计算生态
近日,ImaginationTechnologies与国内领先的异构计算软件与智算混合云服务提供商澎峰科技(PerfXLab)正式签署合作备忘录(MoU),围绕GPU与AI的深度融合展开合作。双方将
黑芝麻A2000#高阶智能驾驶与通用AI计算芯片详细解析
、产品定位与核心目标 A2000家族是黑芝麻智能华山系列的最新产品, 定位于高阶智能驾驶与通用AI计算 ,目标是通过高算力、高能效的芯片设计

AI演进的核心哲学:使用通用方法,然后Scale Up!
,得到一个AI发展的重要历史教训:利用计算能力的通用方法最终是最有效的,而且优势明显”。核心原因是摩尔定律,即单位计算成本持续指数级下降。大多数 A
沐曦曦云C500通用计算GPU与百度飞桨完成Ⅱ级兼容性测试
近日,沐曦曦云C500通用计算GPU与百度飞桨已完成Ⅱ级兼容性测试。测试结果显示,双方兼容性表现良好,整体运行稳定。这是沐曦加入飞桨“硬件生态共创计划”后的阶段性成果。
摩尔线程GPU原生FP8计算助力AI训练
并行训练和推理,显著提升了训练效率与稳定性。摩尔线程是国内率先原生支持FP8计算精度的国产GPU企业,此次开源不仅为AI训练和推理提供了全新的国产

AI推理带火的ASIC,开发成败在此一举!
的应用性价比远超GPU,加上博通财报AI业务同比大增220%,掀起了AI推理端的ASIC热潮。 那么ASIC跟传统的GPU有哪些区别,开发上又有哪些流程上的不同? ASIC和

GPU加速计算平台的优势
传统的CPU虽然在日常计算任务中表现出色,但在面对大规模并行计算需求时,其性能往往捉襟见肘。而GPU加速计算平台凭借其独特的优势,吸引了行业内人士的广泛关注和应用。下面,
云骥智行借助NVIDIA Jetson打造“域脑”通用计算平台
本案例中,云骥智行(Pegasus Technology)借助 NVIDIA Jetson 打造“域脑”通用计算平台,实现了在人形机器人、智能新终端等具身智能场景的部署应用,满足多场景算力需求,保障系统安全稳定运行并推动功能拓展。
GPU云计算服务怎么样
在当今数字化快速发展的时代,高性能计算需求日益增长。为满足这些需求,GPU云计算服务应运而生。那么,GPU云计算服务怎么样呢?接下来,
澎峰科技计算软件栈与沐曦GPU完成适配和互认证
近期,澎峰科技与沐曦完成了对PerfXLM(推理引擎)、PerfXCloud(大模型服务平台)与沐曦的曦云系列通用计算GPU的联合测试,测试结果表明PerfXLM、PerfXCloud软件与沐曦GPU产品实现了全面兼容。
GPU是如何训练AI大模型的
在AI模型的训练过程中,大量的计算工作集中在矩阵乘法、向量加法和激活函数等运算上。这些运算正是GPU所擅长的。接下来,AI部落小编带您了解GPU





 工商网监
工商网监
评论