 帮助弱者让你变得更强:利用多任务学习提升非自回归翻译质量
帮助弱者让你变得更强:利用多任务学习提升非自回归翻译质量

01
研究动机
目前最先进的神经机器翻译模型主要是自回归(autoregressive, AR)[1][2]模型,即在解码时从左向右依次生成目标端单词。尽管具有很强的性能,但这种顺序解码会导致较高的解码时延,在效率方面不令人满意。相比之下,非自回归(non-autoregressive, NAR)模型[3]使用更加高效的并行解码,在解码时同时生成所有的目标端单词。为此,NAR模型需要对目标端引入条件独立假设。然而,这一假设无法在概率上准确地描述人类语言数据中的多模态现象(或多样性现象,即一条源端句存在多个正确的翻译结果)。这为NAR模型带来了严峻的挑战,因为条件独立假设与传统的极大似然估计(Maximum Likelihood Estimate, MLE)训练方式无法为NAR模型提供足够信息量的学习信号和梯度。因此,NAR模型经常产生较差的神经表示,尤其是在解码器(Decoder)部分。而由于解码器部分直接控制生成,从而导致了NAR模型显著的性能下降。为了提升NAR模型的性能,大多数先前的研究旨在使用更多的条件信息来改进目标端依赖关系的建模(GLAT[4], CMLM[5])。我们认为,这些研究工作相当于在不改变NAR模型概率框架的前提下提供更好的替代学习信号。并且,这些工作中的大部分需要对模型结构进行特定的修改。
沿着这个思路,我们希望能够为NAR模型提供更具信息量的学习信号,以便更好地捕获目标端依赖。同时,最好可以无需对模型结构进行特定的修改,适配多种不同的NAR模型。因此,在本文中我们提出了一种简单且有效的多任务学习框架。我们引入了一系列解码能力较弱的AR Decoder来辅助NAR模型训练。随着弱AR Decoder的训练,NAR模型的隐层表示中将包含更多的上下文和依赖信息,继而提高了NAR模型的解码性能。同时,我们的方法是即插即用的,且对NAR模型的结构没有特定的要求。并且我们引入的AR Decoder仅在训练阶段使用,因此没有带来额外的解码开销。
02
贡献
1、我们提出了一个简单有效的多任务学习框架,使NAR模型隐层表示包含更丰富的上下文和依赖信息。并且我们的方法无需对模型结构进行特定的修改,适配多种NAR模型。
2、一系列AR Decoder的引入带来了较大的训练开销。为此我们提出了两种降低训练开销的方案,在几乎不损失性能的前提下显著降低了参数量和训练时间。
3、在多个数据集上的实验结果表明,我们的方法能够为不同的NAR模型带来显著的提升。当使用束搜索解码时,我们的模型在所有数据集上均优于强大的Transformer模型,同时不引入额外的解码开销。
03
解决方案
3.1、模型结构
我们的模型结构如图1所示。对于每个NAR Decoder层,我们都引入了一个辅助的弱AR Decoder(每个AR Decoder仅包含1层Transformer Layer)。我们令这些AR Decoder基于对应的NAR隐层表示进行解码,即令NAR隐层表示作为AR Decoder Cross-Attention的Key和Value。由于AR Decoder的解码能力较弱,因此很难自行捕捉目标句的依赖关系。只有当其对应的NAR隐层表示中的信息足够充分,AR Decoder才能够正确地解码。因此,AR Decoder为NAR模型带来了新的训练信号,迫使NAR Decoder变得更强,在隐层表示中包含更多的上下文和依赖信息来支持AR Decoder的解码。在这个过程中,NAR提升了自己的表示能力,从而在实际解码时获得了更好的表现。
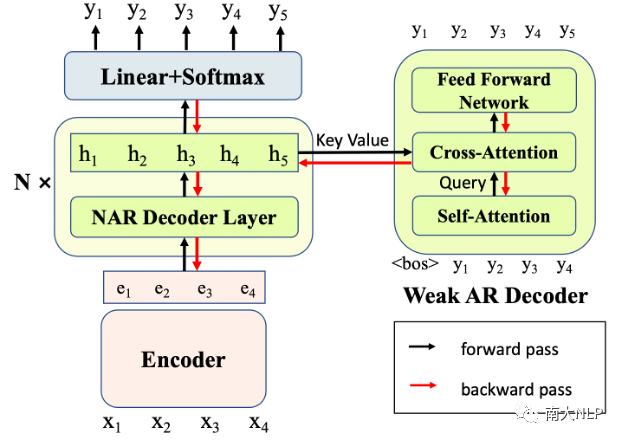
图1:我们的方法示意图
3.2、训练目标
我们的训练目标如下式所示
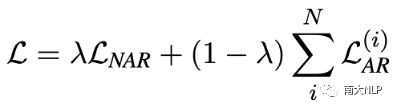
对于NAR部分,我们保持NAR模型的原始训练目标不变。如对于CTC模型,我们使用CTC Loss作为NAR的损失函数。对于AR部分,我们使用交叉熵损失进行训练,并将所有AR Decoder的损失相加。最终的损失函数是两部分的加权和,权重是超参数。
3.3、Glancing Training训练策略
Glancing Training是一种有效提升NAR模型性能的训练策略[4]。我们在我们的方法中应用了Glancing Training。具体来说,在训练时根据模型当前的解码质量,随机采样参考句中的token作为NAR Decoder的输入。模型当前解码质量越差则采样越多,反之亦然。然后令AR Decoder基于NAR隐层表示进行解码。
3.4、降低解码开销
我们为每层NAR Decoder都配置了一个AR Decoder,这可能会带来较大的训练开销。为此,我们从模型参数量和训练时间的角度,提出了两种降低训练开销的方案。
Parameter Sharing:令所有的AR Decoder之间共享参数,降低参数量;
Layer Dropout:每个训练步随机选择一半数量的AR Decoder进行训练,降低训练时间。
3.5、解码过程
在解码时,我们不使用AR Decoder,仅使用NAR模型自身进行解码。因此,我们的方法没有引入额外的解码开销。
04
实验
我们在机器翻译领域目前最广泛使用的数据集上进行了实验:WMT14英德(4.5M语言对)、WMT16英罗(610K语言对)、IWSLT14德英(160K语言对)。我们遵循Gu和Kong[6]的工作中的数据预处理方式,并且使用了BLEU[9]指标作为机器翻译质量评价指标。为了缓解数据集中多模态现象导致的训练困难,我们对所有数据集使用了知识蒸馏技术进行处理[3]。
4.1、实验结果
我们的方法可以对不同类型的NAR模型带来提升。
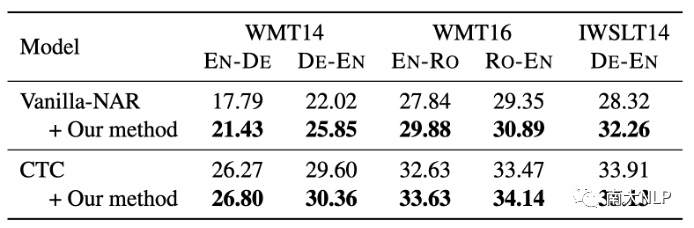
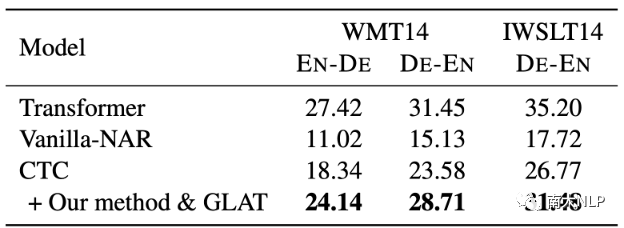
我们使用了Vanilla-NAR[3]和CTC[7]作为我们的基线模型,并在基线模型上应用我们的方法,实验结果如表1所示。可以看到,我们的方法一致且显著地提高了每个基线模型在每个语言对上的翻译质量。这说明了我们方法的通用性。
表1:对不同的基线模型应用我们的方法
与其他的NAR模型相比,我们的方法获得了更好的结果。
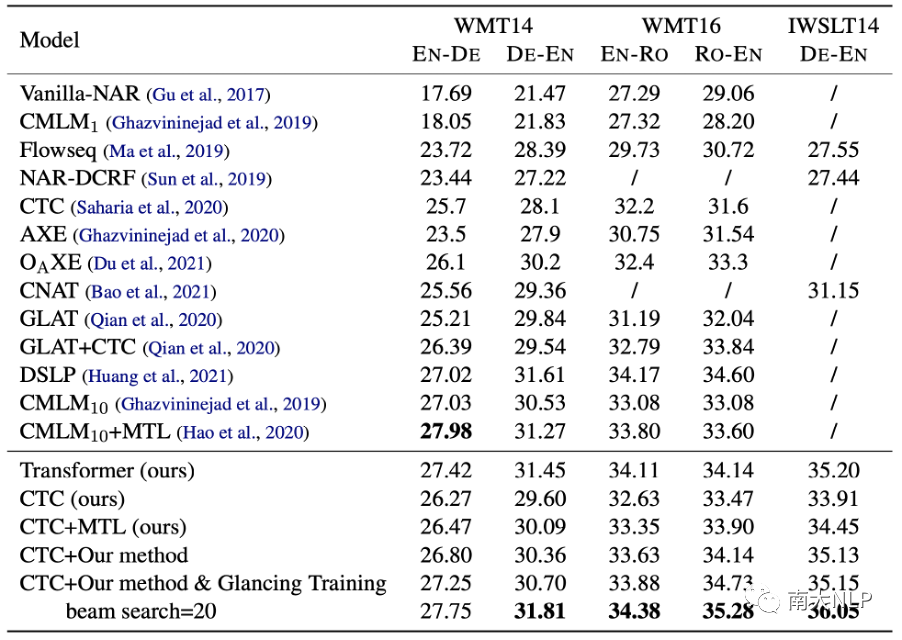
我们选用CTC模型应用我们的方法作为我们的模型,并与其他强大的NAR模型进行比较,实验结果如表2所示。可以看到,我们的方法显著提高了翻译质量,并优于其他强大的基线模型。此外,当应用Glancing Training技术后,我们的方法可以带来更大程度的提升。
与采取迭代解码的模型(CMLM)相比,我们的方法仅使用单步解码,具备更快的解码速度,并在除了WMT14英德之外的所有语言对上获得了更好的性能。
Hao等人[8]的工作与我们的工作相关,都使用了多任务学习框架。我们在CTC模型上复现了他们的方法(CTC+MTL)。实验结果表明我们的方法可以为模型带来更明显的提升。
表2:与其他强大的NAR模型比较。 代表使用k轮迭代解码
代表使用k轮迭代解码
4.2、实验分析
较弱的AR Decoder是否有必要?
在我们的方法中,AR Decoder的解码能力需要足够弱,由此强迫NAR Decoder变得更强。我们对这一点进行了验证。我们使用不同层数的AR Decoder进行实验(1、3、6层),实验结果如图2所示。每种深度的AR Decoder都可以为NAR模型带来增益,但是随着AR Decoder层数的增加,AR Decoder解码能力增强,为NAR模型带来的增益也在逐渐降低。这也验证了我们的动机:一个较弱的AR Decoder能够使NAR Decoder包含更多有用的信息。
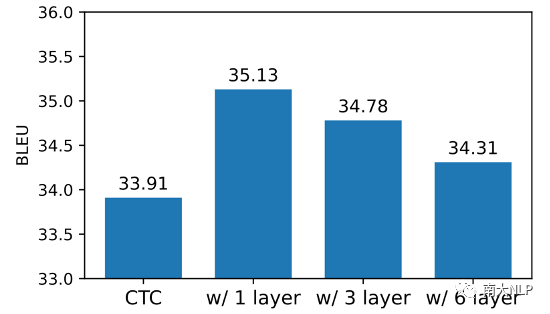
图2:不同层数的AR Decoder为模型带来了不同程度的增益
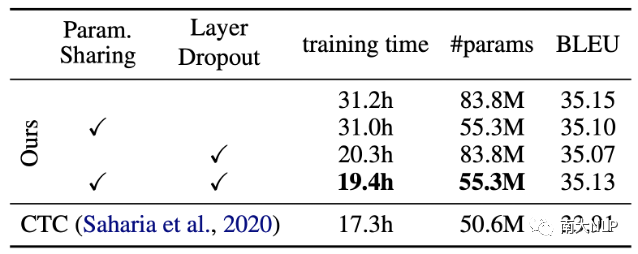
关于训练开销的消融实验。
我们在IWSLT14德英数据集上评估了我们提出的降低训练开销策略的效果。如表3所示,在使用了Param Sharing和Layer Dropout两种策略后,参数量(83.8M vs 55.3M)和训练时间(31.2h vs 19.4h)均得到了显著的降低,同时保持模型性能几乎没有变化
表3:两种降低训练开销策略的效果评估
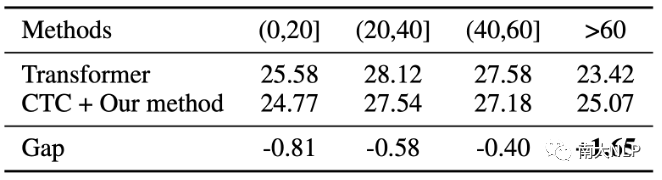
我们的方法使模型能够更好地解码长句。
为了进一步分析NAR模型在生成不同长度目标端句时的表现差异,我们在WMT14英德数据集的测试集上进行了实验,将目标端句按照长度分成不同的区间。如表4所示,随着句子长度的增加,我们的模型和Transformer之间的差距在逐渐降低。当目标端句长度大于60时,我们的模型能够超过Transformer的解码性能。在解码更长的句子时,模型需要处理更复杂的上下文关联。我们推测我们提出的多任务学习方法显著改善了NAR隐藏状态下包含的上下文和依赖信息,因此在长句子翻译中具有更好的性能。
表4:生成不同长度目标端句时的性能差异
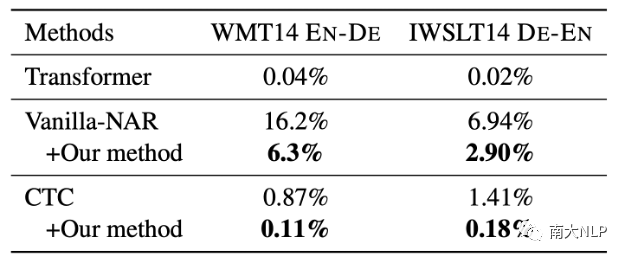
我们的方法使模型减少了重复生成。
由于数据集中的多模态现象,NAR模型会出现重复生成的翻译错误。表5展示了在应用我们的方法前后,NAR模型出现重复生成现象的比率。可以看到,我们的方法显著降低了重复单词的出现频率,使NAR模型的生成质量更好。值得注意的是,尽管CTC模型本身已经能够产生很少的重复生成,我们的方法依然可以进一步降低重复生成的比率。
表5:重复生成的比率
不使用知识蒸馏技术时的性能表现。
尽管知识蒸馏是一种常用的约减多模态现象的手段,但它限制了NAR模型在AR教师模型下的性能,同时构建教师模型也需要额外的开销。为了验证我们的方法在原始数据场景中的有效性,我们在WMT14和IWSLT14数据集上进行了实验。如表6所示,我们的方法可以为基线模型(CTC)带来非常显著的提升,进一步缩小了与Transformer模型的差距。
表6:不使用知识蒸馏的实验结果
我们的方法相对于其他多任务学习方法的优势。
Hao等人[8]的工作也使用了多任务学习框架,但我们的方法能够为NAR模型带来更显著的提升。我们认为我们的方法在多任务学习模块(即AR Decoder)的位置和容量上更有优势。
对于AR Decoder的位置,我们认为Decoder决定生成过程,因此将AR Decoder部署于NAR Decoder上能够更直接和显式地改善NAR的生成过程,而Hao等人的工作是部署于NAR Encoder上的。
对于AR Decoder的容量,我们认为AR Decoder应尽可能弱,这样AR Decoder无法自行对目标端句进行建模,从而迫使NAR Decoder隐层表示包含更多的上下文和依赖信息。而Hao等人的工作使用的标准AR Decoder,对NAR隐层表示的要求更低,因此为NAR带来的提升更少。
05
总结
在本文中,我们为NAR模型提出了一个多任务学习框架,引入了一系列弱AR解码器辅助训练NAR模型。随着弱AR解码器的训练,NAR隐藏状态将包含更多的上下文和依赖信息,从而提高NAR模型的性能。在多个数据集上的实验表明,我们的方法可以显著且一致地提高翻译质量。当使用束搜索解码时,我们基于CTC的NAR模型在所有基准测试上都优于强大的Transformer,同时不引入额外的解码开销。
审核编辑 :李倩
-
解码器
+关注
关注
9文章
1202浏览量
42857 -
Ar
+关注
关注
25文章
5236浏览量
175453 -
模型
+关注
关注
1文章
3648浏览量
51702
原文标题:EMNLP'22 | 帮助弱者让你变得更强:利用多任务学习提升非自回归翻译质量
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
学习RTOS的意义?
一句话,多个命令同时执行,AI语音模组也能多任务处理?
爱普科技PSRAM加速wisun无线模块多任务处理

NFC读写器助力标签质量检测,提升应用优势!

揭秘LuatOS Task:多任务管理的“智能中枢”

电控系统的 “功率翻译官”:车规电容如何让能源利用效率提升 10%?
快速入门——LuatOS:sys库多任务管理实战攻略!
工业通信的“超级翻译官”Modbus转Profinet如何让称重设备实现语言自由
自媒体别乱推!用好DeepSeek,让你的内容“稳稳的”!
AI助力实时翻译耳机

自锁电路与非自锁电路的比较
【「基于大模型的RAG应用开发与优化」阅读体验】+大模型微调技术解读
基于移动自回归的时序扩散预测模型





 工商网监
工商网监
评论